Die steigende Nachfrage nach hochverfügbaren Systemen und engen SLAs treibt uns dazu, manuelle Verfahren durch automatisierte Lösungen zu ersetzen. Aber haben Sie die Zeit und die notwendigen Ressourcen, um die Komplexität von Failover-Vorgängen selbst zu bewältigen? Werden Sie die Ausfallzeit der Produktionsdatenbank opfern, um es auf die harte Tour zu lernen?
ClusterControl bietet erweiterte Unterstützung für die Fehlererkennung und -behandlung. Es wird von vielen Unternehmensorganisationen verwendet und hält die kritischsten Produktionssysteme rund um die Uhr am Laufen.
Diese Datenbankmanagementlösung unterstützt Sie auch bei der Bereitstellung verschiedener Lastproxys. Diese Proxys spielen eine Schlüsselrolle im HA-Stack, sodass keine Anwendungsverbindungszeichenfolge oder DNS-Einträge angepasst werden müssen, um Anwendungsverbindungen auf den neuen Master-Knoten umzuleiten.
Wenn ein Ausfall erkannt wird, erledigt ClusterControl die gesamte Hintergrundarbeit, um einen neuen Master zu wählen, Failover-Slave-Server bereitzustellen und Load Balancer zu konfigurieren. In diesem Blog erfahren Sie, wie Sie ein automatisches Failover von TimescaleDB in Ihren Produktionssystemen erreichen.
Bereitstellung vollständiger Replikationstopologien
Ab ClusterControl 1.7.2 können Sie ein vollständiges TimescaleDB-Replikations-Setup auf die gleiche Weise bereitstellen, wie Sie PostgreSQL bereitstellen würden:Sie können das Menü „Cluster bereitstellen“ verwenden, um einen primären und einen oder mehrere TimescaleDB-Standby-Server bereitzustellen. Mal sehen, wie es aussieht.
Zuerst müssen Sie Zugriffsdetails definieren, wenn Sie neue Cluster mithilfe von ClusterControl bereitstellen. Es erfordert Root- oder Sudo-Passwortzugriff auf alle Knoten, auf denen Ihr neuer Cluster bereitgestellt wird.
 ClusterControl:Neuen Cluster bereitstellen
ClusterControl:Neuen Cluster bereitstellen Als nächstes müssen wir den Benutzer und das Passwort für den TimescaleDB-Benutzer definieren.
 ClusterControl:Datenbank-Cluster bereitstellen
ClusterControl:Datenbank-Cluster bereitstellen Schließlich möchten Sie die Topologie definieren – welcher Host soll der primäre sein und welche Hosts sollen als Standby konfiguriert werden. Während Sie Hosts in der Topologie definieren, prüft ClusterControl, ob der ssh-Zugriff wie erwartet funktioniert – so können Sie Verbindungsprobleme frühzeitig erkennen. Auf dem letzten Bildschirm werden Sie nach der Art der Replikation synchron oder asynchron gefragt.
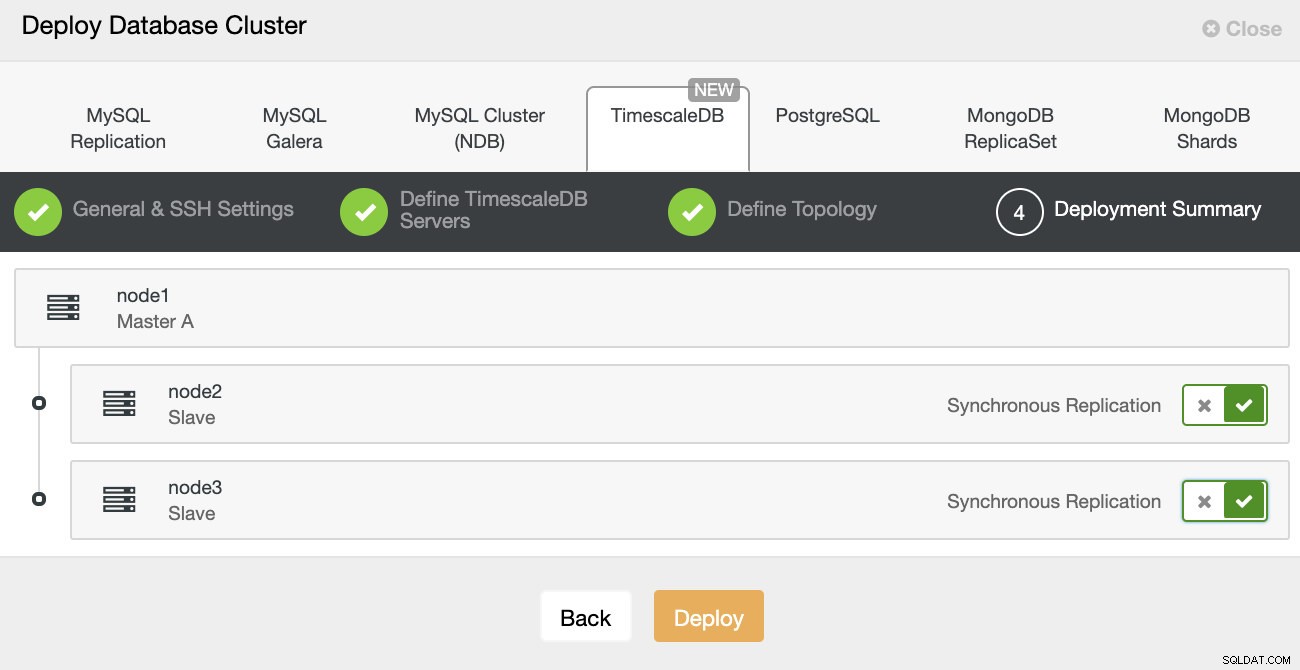 ClusterControl-Bereitstellung
ClusterControl-Bereitstellung Das war’s, dann geht es an den Start des Deployments. Ein Job wird in ClusterControl erstellt und Sie können den Fortschritt verfolgen.
 ClusterControl:Topologie für TimescleDb-Cluster definieren
ClusterControl:Topologie für TimescleDb-Cluster definieren Sobald Sie fertig sind, sehen Sie das Topologie-Setup mit Rollen im Cluster. Beachten Sie, dass wir auch einen Load Balancer (HAProxy) vor den Datenbankinstanzen hinzugefügt haben, damit das automatische Failover keine Änderungen in den Datenbankverbindungseinstellungen erfordert.
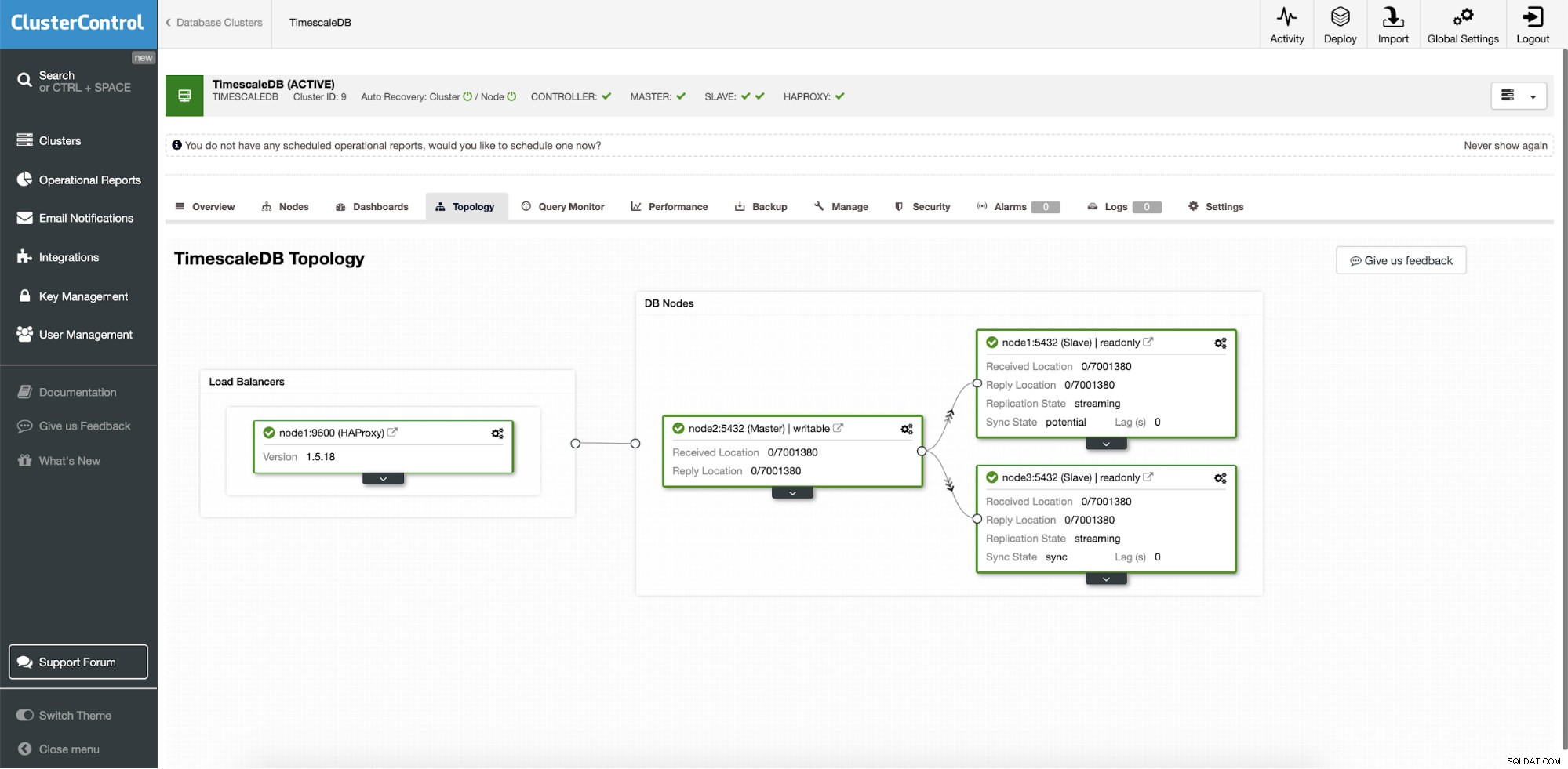 ClusterControl:Topologie
ClusterControl:Topologie Wenn Timescale von ClusterControl bereitgestellt wird, ist die automatische Wiederherstellung standardmäßig aktiviert. Der Status kann in der Clusterleiste überprüft werden.
 ClusterControl:Cluster- und Knotenzustand der automatischen Wiederherstellung
ClusterControl:Cluster- und Knotenzustand der automatischen Wiederherstellung Failover-Konfiguration
Sobald das Replikations-Setup bereitgestellt ist, kann ClusterControl das Setup überwachen und ausgefallene Server automatisch wiederherstellen. Es kann auch Änderungen in der Topologie orchestrieren.
Das automatische ClusterControl-Failover wurde nach den folgenden Prinzipien entwickelt:
- Stellen Sie sicher, dass der Master wirklich tot ist, bevor Sie ein Failover durchführen
- Failover nur einmal
- Führen Sie kein Failover zu einem inkonsistenten Slave durch
- Nur an den Master schreiben
- Den ausgefallenen Master nicht automatisch wiederherstellen
Mit den integrierten Algorithmen kann ein Failover oft ziemlich schnell durchgeführt werden, sodass Sie die höchsten SLAs für Ihre Datenbankumgebung sicherstellen können.
Der Prozess ist konfigurierbar. Es enthält mehrere Parameter, mit denen Sie die Wiederherstellung an die Besonderheiten Ihrer Umgebung anpassen können.
| max_replication_lag | Maximal zulässige Replikationsverzögerung in Sekunden zuvor |
| replication_stop_on_error | Failover-/Umschaltvorgänge schlagen fehl, wenn Fehler auftreten, die zu Datenverlust führen können. Standardmäßig aktiviert. 0 bedeutet deaktivieren, |
| replication_auto_rebuild_slave | Wenn der SQL-THREAD gestoppt wird und der Fehlercode nicht Null ist, wird der Slave automatisch neu erstellt. 1 bedeutet aktiviert, 0 bedeutet deaktiviert (Standard). |
| replication_failover_blacklist | Komma-getrennte Liste von Hostname:Port-Paaren. Server auf der schwarzen Liste werden während des Failovers nicht als Kandidat berücksichtigt. replication_failover_blacklist wird ignoriert, wenn replication_failover_whitelist gesetzt ist. |
| replication_failover_whitelist | Komma-separierte Liste von Hostname:Port-Paaren. Beim Failover werden nur Server auf der Whitelist als Kandidat berücksichtigt. Wenn kein Server auf der Whitelist verfügbar (aktiv/verbunden) ist, schlägt das Failover fehl. replication_failover_blacklist wird ignoriert, wenn replication_failover_whitelist gesetzt ist. |
Failover-Handhabung
Wenn ein Master-Ausfall erkannt wird, wird eine Liste von Master-Kandidaten erstellt und einer von ihnen als neuer Master ausgewählt. Es ist möglich, eine Whitelist von Servern zu haben, die zum Primärserver heraufgestuft werden sollen, sowie eine Blacklist von Servern, die nicht zum Primärserver heraufgestuft werden können. Die verbleibenden Slaves werden nun von der neuen Primärdatenbank als Slave abgearbeitet, und die alte Primärdatenbank wird nicht neu gestartet.
Unten sehen wir eine Simulation eines Knotenausfalls.
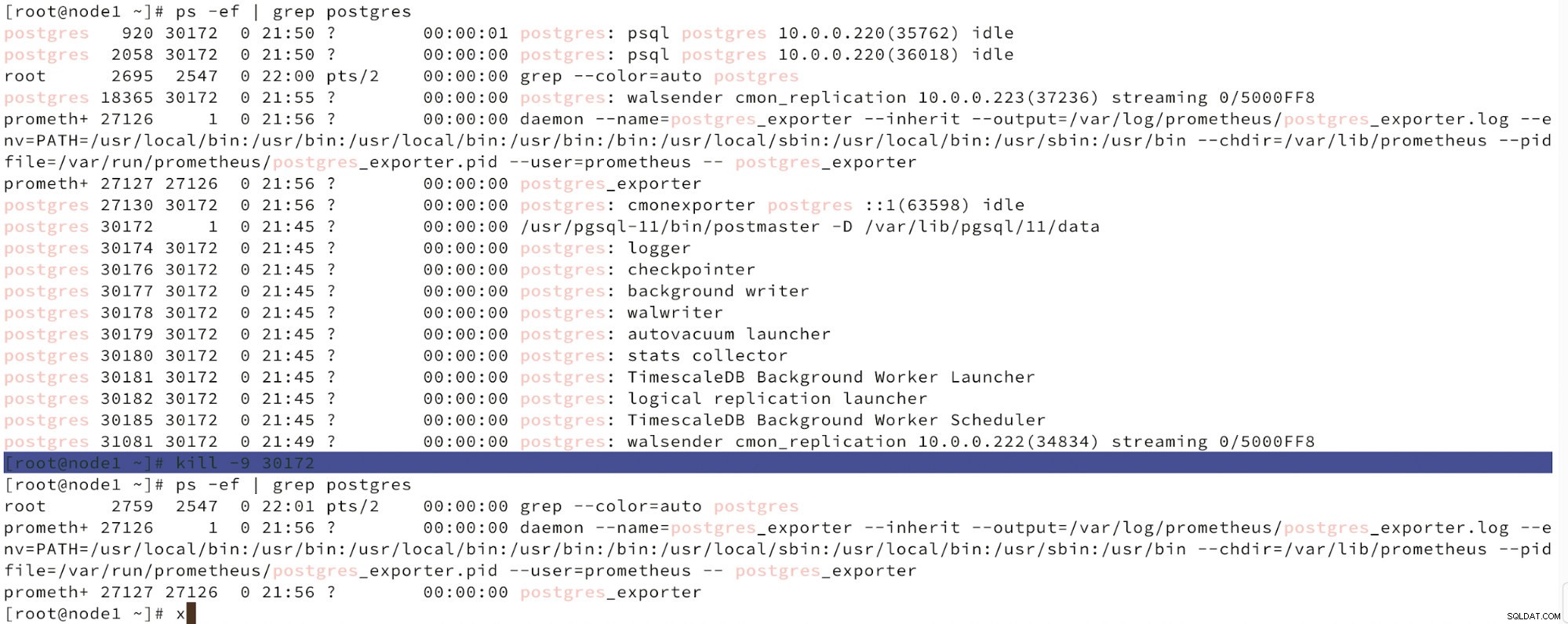 Simulieren Sie den Ausfall des Master-Knotens mit kill
Simulieren Sie den Ausfall des Master-Knotens mit kill Wenn eine Knotenfehlfunktion erkannt wird und eine automatische Wiederherstellung erkannt wird, löst ClusterControl einen Job aus, um ein Failover durchzuführen. Unten sehen wir Maßnahmen, die zur Wiederherstellung des Clusters ergriffen wurden.
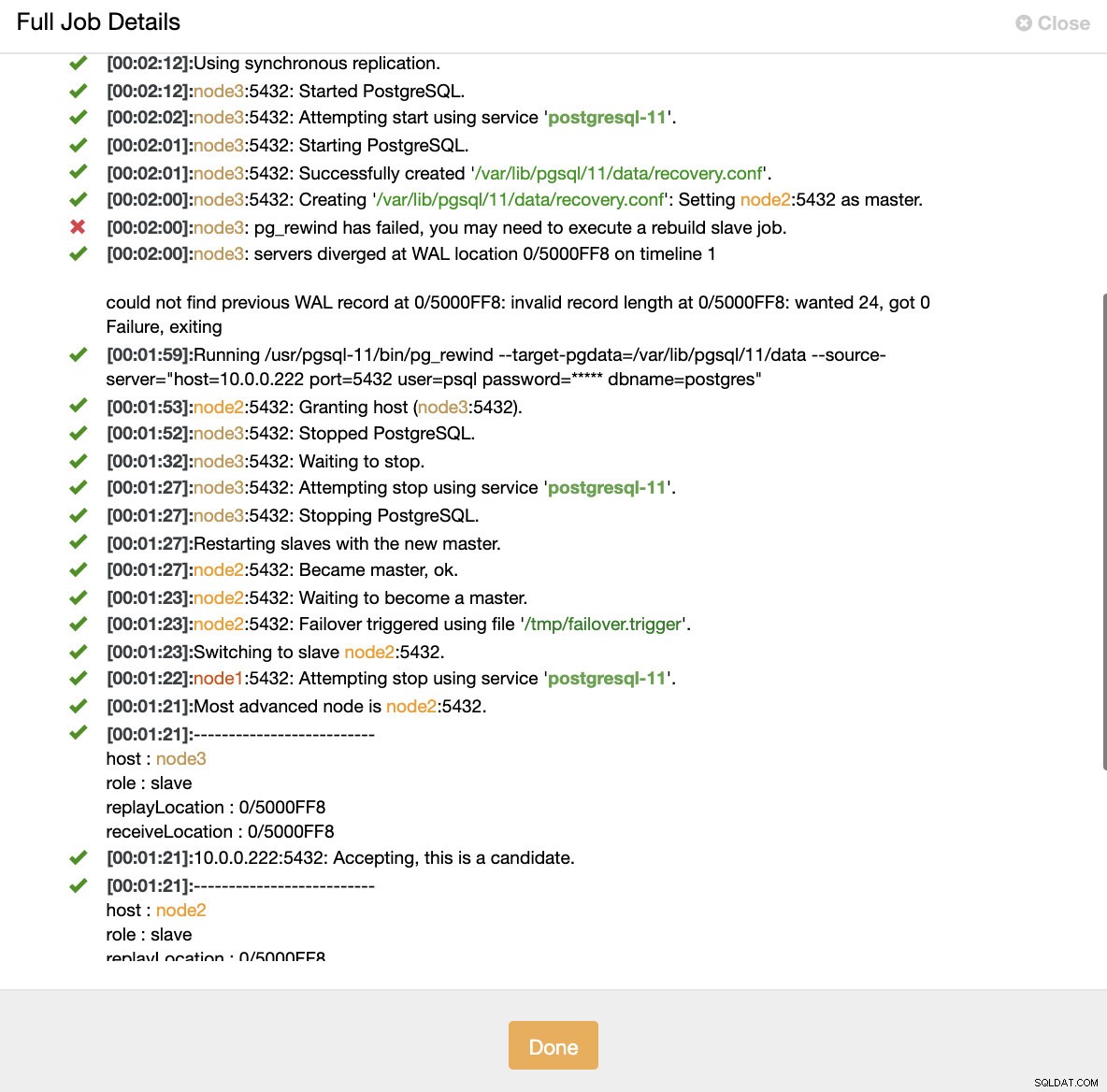 ClusterControl:Job ausgelöst, um den Cluster neu zu erstellen
ClusterControl:Job ausgelöst, um den Cluster neu zu erstellen ClusterControl hält den alten Primary bewusst offline, da es vorkommen kann, dass einige Daten nicht auf die Standby-Server übertragen wurden. In einem solchen Fall ist der primäre Host der einzige Host, der diese Daten enthält, und Sie möchten die fehlenden Daten möglicherweise manuell wiederherstellen. Für diejenigen, die den ausgefallenen Primärserver automatisch neu erstellen möchten, gibt es eine Option in der cmon-Konfigurationsdatei:replication_auto_rebuild_slave. Standardmäßig ist es deaktiviert, aber wenn der Benutzer es aktiviert, wird der ausgefallene Primärknoten als Slave des neuen Primärknotens wiederhergestellt. Wenn Daten fehlen, die nur auf dem ausgefallenen Primärserver vorhanden sind, gehen diese Daten natürlich verloren.
Neuaufbau von Standby-Servern
Eine andere Funktion ist der Job „Rebuild Replication Slave“, der für alle Slaves (oder Standby-Server) im Replikations-Setup verfügbar ist. Dies ist beispielsweise zu verwenden, wenn Sie die Daten auf dem Standby löschen und mit einer neuen Kopie der Daten des primären neu erstellen möchten. Dies kann von Vorteil sein, wenn ein Standby-Server aus irgendeinem Grund keine Verbindung zum primären Server herstellen und nicht replizieren kann.
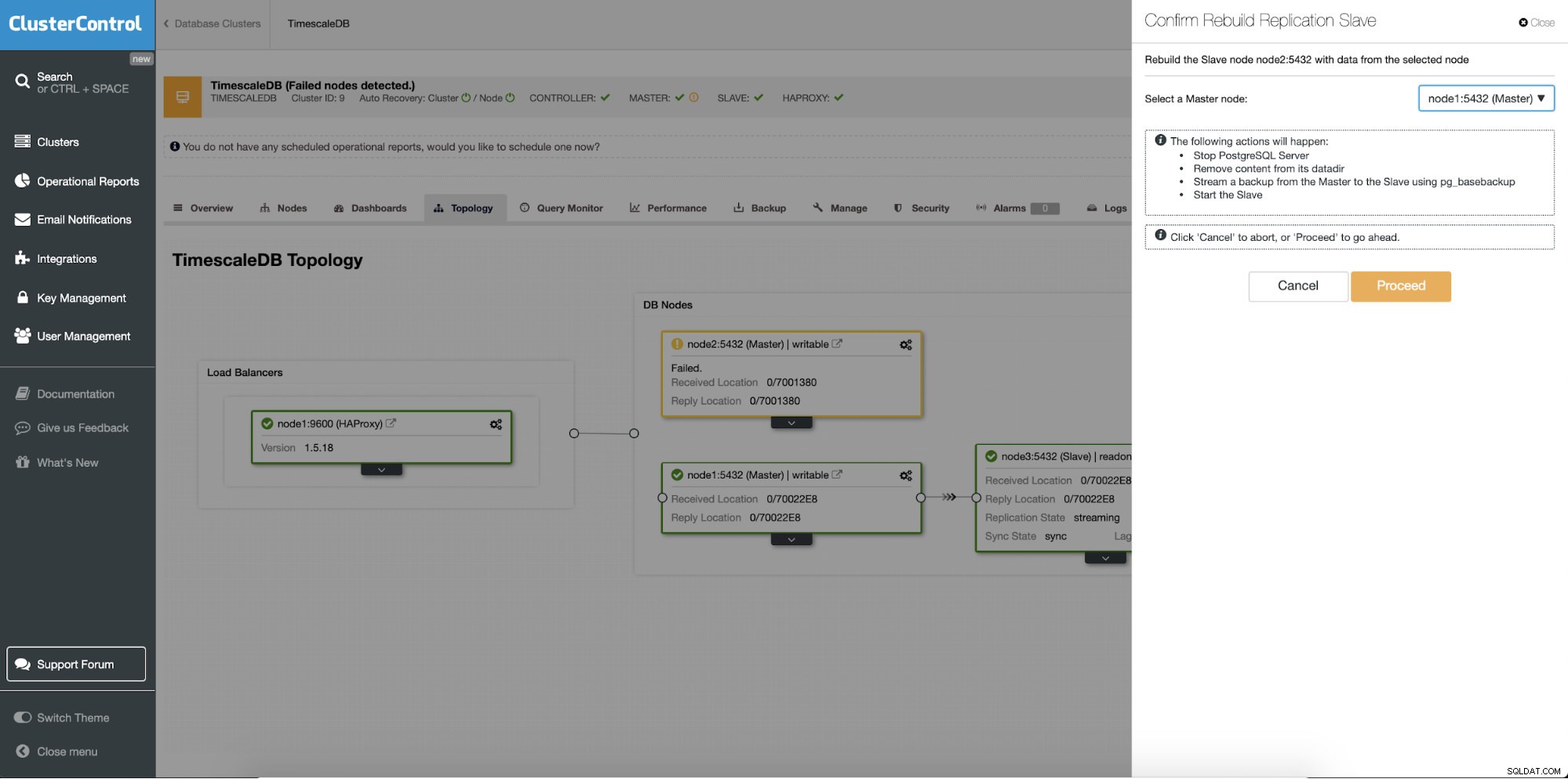 ClusterControl:Replikations-Slave neu aufbauen
ClusterControl:Replikations-Slave neu aufbauen  ClusterControl:Slave neu erstellen
ClusterControl:Slave neu erstellen