In meinen diesjährigen Posts habe ich die spontanen Reaktionen auf verschiedene Wartetypen diskutiert, und in diesem Post werde ich mit dem Thema Wartestatistiken fortfahren und den PAGEIOLATCH_XX besprechen warte ab. Ich sage "warten", aber es gibt wirklich mehrere Arten von PAGEIOLATCH wartet, was ich mit dem XX am Ende angedeutet habe. Die häufigsten Beispiele sind:
PAGEIOLATCH_SH– (SH warten darauf, dass eine Datendateiseite von der Festplatte in den Pufferpool gebracht wird, damit ihr Inhalt gelesen werden kannPAGEIOLATCH_EXoderPAGEIOLATCH_UP– (Bsp. inclusive oder UP Datum) und wartet darauf, dass eine Datendateiseite von der Festplatte in den Pufferpool gebracht wird, damit ihr Inhalt geändert werden kann
Der bei weitem häufigste Typ ist PAGEIOLATCH_SH .
Wenn dieser Wartetyp auf einem Server am weitesten verbreitet ist, lautet die reflexartige Reaktion, dass das E/A-Subsystem ein Problem haben muss und sich die Untersuchungen daher darauf konzentrieren sollten.
Als erstes müssen Sie den PAGEIOLATCH_SH vergleichen Wartezeitanzahl und -dauer gegenüber Ihrer Baseline. Wenn das Volumen der Wartezeiten mehr oder weniger gleich ist, aber die Dauer der einzelnen Lesewartezeiten viel länger geworden ist, würde ich mir Sorgen um ein E/A-Subsystemproblem machen, wie zum Beispiel:
- Eine Fehlkonfiguration/Fehlfunktion auf der E/A-Subsystemebene
- Netzwerklatenz
- Eine weitere E/A-Arbeitslast, die Konflikte mit unserer Arbeitslast verursacht
- Konfiguration der synchronen Replikation/Spiegelung des I/O-Subsystems
Meiner Erfahrung nach ist das Muster oft das der Zahl PAGEIOLATCH_SH Wartezeiten hat sich gegenüber der Grundlinie (normal) erheblich erhöht, und die Wartezeit hat sich ebenfalls erhöht (d. h. die Zeit für eine Lese-E/A hat zugenommen), da die große Anzahl von Lesevorgängen das E/A-Subsystem überlastet. Dies ist kein E/A-Subsystemproblem – dies ist SQL Server, der mehr E/A-Vorgänge auslöst, als es sein sollte. Der Fokus muss nun auf SQL Server wechseln, um die Ursache für die zusätzlichen I/Os zu identifizieren.
Ursachen für viele Lese-I/Os
SQL Server hat zwei Arten von Lesevorgängen:logische I/Os und physische I/Os. Wenn der Zugriffsmethoden-Teil der Speicher-Engine auf eine Seite zugreifen muss, fragt es den Buffer Pool nach einem Zeiger auf die Seite im Speicher (als logische E/A bezeichnet) und der Buffer Pool überprüft seine Metadaten, um festzustellen, ob diese Seite vorhanden ist bereits im Gedächtnis.
Wenn sich die Seite im Speicher befindet, gibt der Pufferpool den Zugriffsmethoden den Zeiger, und die E/A bleibt eine logische E/A. Wenn sich die Seite nicht im Arbeitsspeicher befindet, gibt der Buffer Pool eine „echte“ E/A (als physische E/A bezeichnet) aus und der Thread muss warten, bis sie abgeschlossen ist – was zu einem PAGEIOLATCH_XX führt warte ab. Sobald die E/A abgeschlossen ist und der Zeiger verfügbar ist, wird der Thread benachrichtigt und kann weiter ausgeführt werden.
In einer idealen Welt würde Ihre gesamte Arbeitslast in den Speicher passen, und sobald der Pufferpool „aufgewärmt“ ist und die gesamte Arbeitslast enthält, sind keine Lesevorgänge mehr erforderlich, sondern nur noch Schreibvorgänge von aktualisierten Daten. Es ist jedoch keine ideale Welt, und die meisten von Ihnen haben diesen Luxus nicht, daher sind einige Lesevorgänge unvermeidlich. Solange die Anzahl der Lesevorgänge in etwa Ihrer Basismenge bleibt, gibt es kein Problem.
Wenn plötzlich und unerwartet eine große Anzahl von Lesevorgängen erforderlich ist, ist dies ein Zeichen dafür, dass sich entweder die Arbeitslast, die Menge des verfügbaren Pufferpoolspeichers zum Speichern von In-Memory-Kopien von Seiten oder beides erheblich geändert hat.
Hier sind einige mögliche Ursachen (keine vollständige Liste):
- Externer Windows-Speicherdruck auf SQL Server, der dazu führt, dass der Speichermanager die Größe des Pufferpools reduziert
- Planen Sie Cache-Bloat, wodurch zusätzlicher Speicher aus dem Pufferpool ausgeliehen wird
- Ein Abfrageplan, der einen Tabellen-/Clustered-Index-Scan durchführt (anstelle einer Indexsuche) aus folgendem Grund:
- eine Erhöhung des Workload-Volumens
- ein Parameter-Sniffing-Problem
- ein erforderlicher nicht gruppierter Index, der gelöscht oder geändert wurde
- eine implizite Konvertierung
Ein zu suchendes Muster würde darauf hindeuten, dass ein Tabellen-/Clustered-Index-Scan die Ursache dafür ist, dass auch eine große Anzahl von CXPACKET erkannt wird wartet zusammen mit dem PAGEIOLATCH_SH wartet. Dies ist ein allgemeines Muster, das darauf hinweist, dass große, parallele Tabellen-/Cluster-Index-Scans auftreten.
In allen Fällen können Sie sich ansehen, welcher Abfrageplan den PAGEIOLATCH_SH verursacht wartet mit sys.dm_os_waiting_tasks und andere DMVs, und Sie können den Code dazu in meinem Blogbeitrag hier erhalten. Wenn Sie ein Überwachungstool eines Drittanbieters zur Verfügung haben, kann es Ihnen möglicherweise helfen, den Schuldigen zu identifizieren, ohne sich die Hände schmutzig zu machen.
Beispielworkflow mit SQL Sentry und Plan Explorer
Nehmen wir in einem einfachen (offensichtlich erfundenen) Beispiel an, dass ich mich auf einem Client-System befinde und die Tool-Suite von SQL Sentry verwende und in der Dashboard-Ansicht von SQL Sentry eine Spitze bei den E/A-Wartezeiten sehe, wie unten gezeigt:
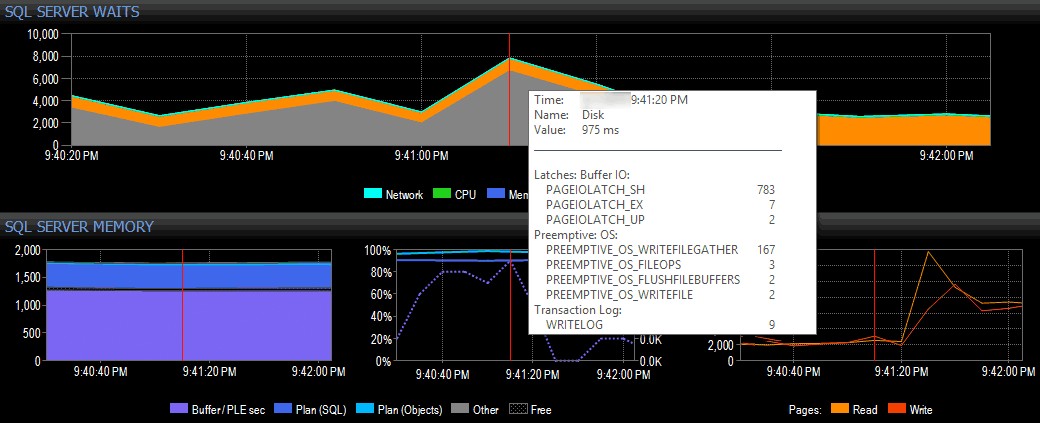
Erkennen einer Spitze bei E/A-Wartezeiten in SQL Sentry
Ich entscheide mich für eine Untersuchung, indem ich mit der rechten Maustaste auf ein ausgewähltes Zeitintervall um die Zeit der Spitze klicke und dann zur Top-SQL-Ansicht springe, die mir die teuersten Abfragen zeigt, die ausgeführt wurden:
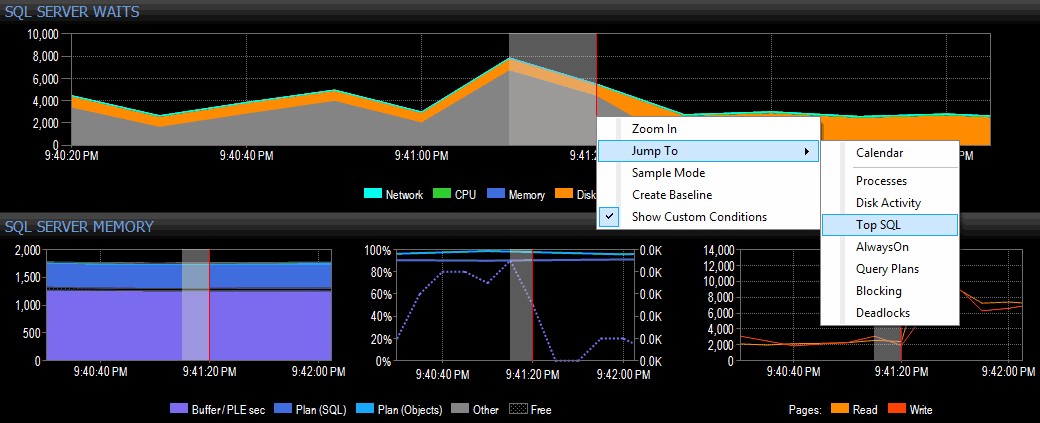
Hervorheben eines Zeitbereichs und Navigieren zu Top SQL
In dieser Ansicht kann ich sehen, welche Abfragen mit langer Laufzeit oder hohen E/A-Werten zu dem Zeitpunkt ausgeführt wurden, als die Spitze auftrat, und dann einen Drill-In zu ihren Abfrageplänen auswählen (in diesem Fall gibt es nur eine Abfrage mit langer Laufzeit, die fast eine Minute lang lief):
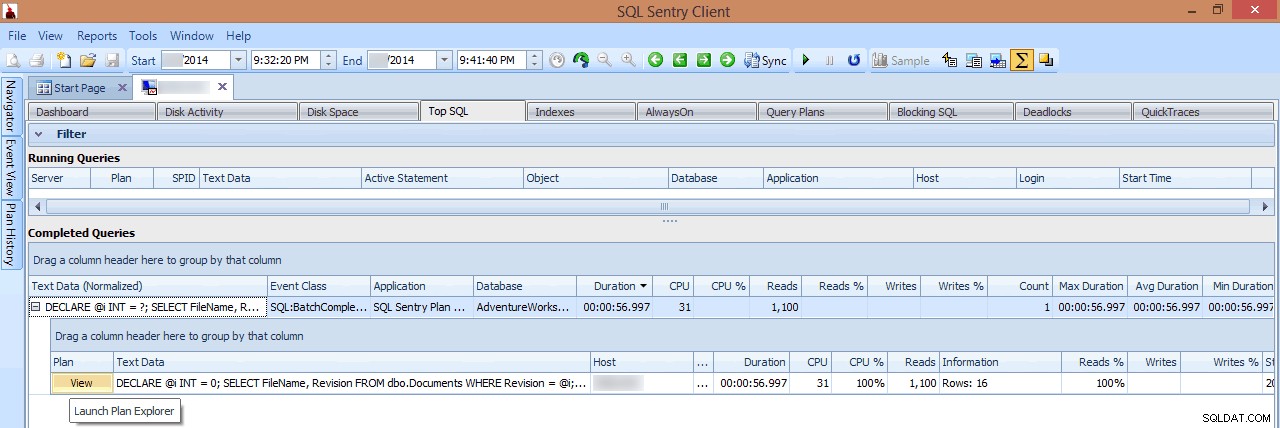
Überprüfen einer lange laufenden Abfrage in Top SQL
Wenn ich mir den Plan im SQL Sentry-Client ansehe oder ihn im SQL Sentry-Plan-Explorer öffne, sehe ich sofort mehrere Probleme. Die Anzahl der Lesevorgänge, die erforderlich sind, um 7 Zeilen zurückzugeben, scheint viel zu hoch zu sein, das Delta zwischen geschätzten und tatsächlichen Zeilen ist groß, und der Plan zeigt, dass ein Index-Scan dort stattfindet, wo ich eine Suche erwartet hätte:
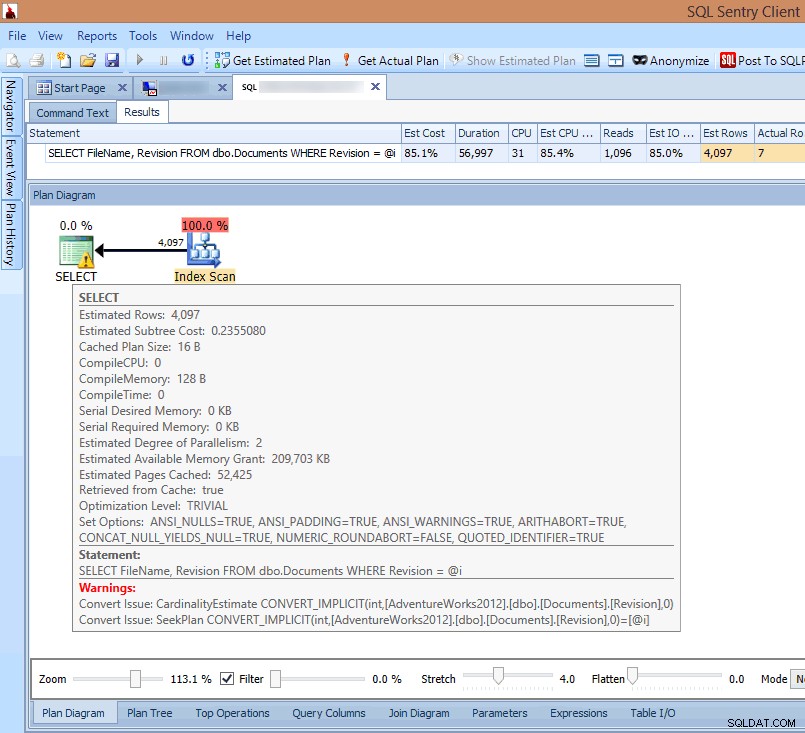
Implizite Konvertierungswarnungen im Abfrageplan anzeigen
Die Ursache für all dies wird in der Warnung auf dem SELECT hervorgehoben Operator:Es ist eine implizite Konvertierung!
Implizite Konvertierungen sind ein heimtückisches Problem, das durch eine Diskrepanz zwischen dem Datentyp des Suchprädikats und dem Datentyp der durchsuchten Spalte oder durch eine Berechnung verursacht wird, die für die Tabellenspalte statt für das Suchprädikat ausgeführt wird. In beiden Fällen kann SQL Server keine Indexsuche für die Tabellenspalte verwenden und muss stattdessen einen Scan verwenden.
Dies kann in scheinbar harmlosem Code auftauchen, und ein gängiges Beispiel ist die Verwendung einer Datumsberechnung. Wenn Sie eine Tabelle haben, die das Alter von Kunden speichert, und Sie eine Berechnung durchführen möchten, um zu sehen, wie viele heute 21 Jahre oder älter sind, könnten Sie Code wie diesen schreiben:
WHERE DATEADD (YEAR, 21, [MyTable].[BirthDate]) <= @today;
Mit diesem Code erfolgt die Berechnung in der Tabellenspalte, sodass keine Indexsuche verwendet werden kann, was zu einem nicht durchsuchbaren Ausdruck (technisch als nicht SARG-fähiger Ausdruck bekannt) und einem Tabellen-/Clustered-Index-Scan führt. Dies kann gelöst werden, indem die Berechnung auf die andere Seite des Operators verschoben wird:
WHERE [MyTable].[BirthDate] <= DATEADD (YEAR, -21, @today);
In Bezug darauf, wann ein einfacher Spaltenvergleich eine Datentypkonvertierung erfordert, die eine implizite Konvertierung verursachen kann, hat mein Kollege Jonathan Kehayias einen hervorragenden Blogbeitrag geschrieben, der jede Kombination von Datentypen vergleicht und angibt, wann eine implizite Konvertierung erforderlich ist.
Zusammenfassung
Tappen Sie nicht in die Falle, dieses übertriebene PAGEIOLATCH_XX zu denken Wartezeiten werden durch das E/A-Subsystem verursacht. Meiner Erfahrung nach werden sie normalerweise durch etwas mit SQL Server verursacht, und dort würde ich mit der Fehlersuche beginnen.
In Bezug auf allgemeine Wartestatistiken finden Sie weitere Informationen zu ihrer Verwendung für die Fehlerbehebung in:
- My SQLskills-Blogbeitragsserie, beginnend mit Wait-Statistiken, oder sagen Sie mir bitte, wo es weh tut
- Meine Wartetypen- und Latch-Klassen-Bibliothek hier
- Mein Pluralsight-Online-Schulungskurs SQL Server:Fehlerbehebung bei der Leistung mithilfe von Wartestatistiken
- SQL-Sentry
Im nächsten Artikel der Serie werde ich einen anderen Wartetyp besprechen, der eine häufige Ursache für reflexartige Reaktionen ist. Bis dahin viel Spaß bei der Fehlersuche!