Alle meine Posts in diesem Jahr drehten sich um reflexartige Reaktionen auf Wartestatistiken, aber in diesem Post weiche ich von diesem Thema ab, um über einen bestimmten Käfer von mir zu sprechen:den Seitenlebenserwartungs-Leistungszähler (den ich PLE nennen werde ).
Was bedeutet PLE?
Es gibt im Internet alle möglichen falschen Aussagen über die Lebenserwartung von Seiten, und die ungeheuerlichsten sind diejenigen, die angeben, dass der Wert 300 der Schwellenwert ist, ab dem Sie sich Sorgen machen sollten.
Um zu verstehen, warum diese Aussage so irreführend ist, müssen Sie verstehen, was PLE eigentlich ist.
Die Definition von PLE ist die erwartete Zeit in Sekunden, die eine in den Pufferpool (den In-Memory-Cache der Datendateiseiten) eingelesene Datendateiseite im Speicher verbleibt, bevor sie aus dem Speicher verschoben wird, um Platz für andere Daten zu schaffen Datei Seite. Eine andere Art, sich PLE vorzustellen, ist ein sofortiges Maß für den Druck auf den Pufferpool, um freien Speicherplatz für Seiten zu schaffen, die von der Festplatte gelesen werden. Für beide Definitionen ist eine höhere Zahl besser.
Was ist ein guter PLE-Schwellenwert?
Ein PLE von 300 bedeutet, dass Ihr gesamter Pufferpool alle fünf Minuten effektiv geleert und erneut gelesen wird. Als Microsoft um 2005/2006 zum ersten Mal die Schwellenrichtlinie für PLE von 300 herausgab, war diese Zahl möglicherweise sinnvoller, da die durchschnittliche Speichermenge auf einem Server viel niedriger war.
Heutzutage, wo Server routinemäßig über 64 GB, 128 GB und mehr Arbeitsspeicher verfügen, wäre es wahrscheinlich die Ursache für ein lähmendes Leistungsproblem, wenn etwa alle fünf Minuten so viele Daten von der Festplatte gelesen werden.
In Wirklichkeit befindet sich Ihr Server zu dem Zeitpunkt, an dem PLE bei oder unter 300 schwebt, bereits in einer Notlage. Sie würden anfangen, sich Sorgen zu machen, lange bevor PLE so niedrig ist.
Was ist also der Schwellenwert, ab dem Sie sich Sorgen machen sollten?
Nun, das ist genau der Punkt. Ich kann Ihnen keinen Schwellenwert nennen, da diese Zahl für jeden unterschiedlich sein wird. Wenn Sie wirklich, wirklich eine Nummer verwenden möchten, hat mein Kollege Jonathan Kehayias eine Formel entwickelt:
( Pufferpoolspeicher in GB / 4 ) x 300Selbst diese Zahl ist etwas willkürlich und Ihr Kilometerstand wird variieren.
Ich möchte keine Zahlen empfehlen. Mein Rat ist, dass Sie Ihren PLE messen, wenn die Leistung auf dem gewünschten Niveau ist – das ist den Schwellenwert, den Sie verwenden.
Machen Sie sich also Sorgen, sobald PLE unter diese Schwelle fällt? Nein. Sie beginnen sich Sorgen zu machen, wenn PLE unter diesen Schwellenwert fällt und unter diesem Schwellenwert bleibt, oder wenn er steil abfällt und Sie nicht wissen warum.
Dies liegt daran, dass es einige Operationen gibt, die einen PLE-Drop verursachen (z. B. das Ausführen von DBCC CHECKDB oder Index-Neuaufbauten können dies manchmal tun) und sind kein Grund zur Besorgnis. Aber wenn Sie einen großen PLE-Abfall sehen und nicht wissen, was ihn verursacht, sollten Sie sich Sorgen machen.
Sie fragen sich vielleicht, wie DBCC CHECKDB kann einen PLE-Drop verursachen, wenn es ungünstig ist und versucht, das Leeren des Pufferpools mit den verwendeten Daten zu vermeiden (eine Erklärung finden Sie in diesem Blogbeitrag). Das liegt daran, dass die Arbeitsspeicherzuweisung für die Abfrageausführung für DBCC CHECKDB wird vom Abfrageoptimierer falsch berechnet und kann zu einer starken Verringerung der Größe des Pufferpools (der Speicher für die Gewährung wird aus dem Pufferpool gestohlen) und einem daraus resultierenden Rückgang von PLE führen.
Wie überwachen Sie PLE?
Das ist der knifflige Teil. Die meisten Leute gehen direkt zum Buffer Manager Leistungsobjekt in PerfMon und überwachen Sie die Page life expectancy Schalter. Ist das der richtige Ansatz? Höchstwahrscheinlich nicht.
Ich würde sagen, dass eine große Mehrheit der heutigen Server die NUMA-Architektur verwendet, und dies hat tiefgreifende Auswirkungen darauf, wie Sie PLE überwachen.
Wenn NUMA beteiligt ist, wird der Pufferpool in Pufferknoten aufgeteilt, mit einem Pufferknoten pro NUMA-Knoten, den SQL Server „sehen“ kann. Jeder Buffer-Knoten verfolgt PLE separat und die Buffer Manager:Page life expectancy Zähler ist der Durchschnitt der Pufferknoten-PLEs. Wenn Sie nur die gesamte Pufferpool-PLE überwachen, kann der Druck auf einen der Pufferknoten durch die Mittelwertbildung maskiert werden (ich bespreche dies in einem Blogbeitrag hier).
Wenn Ihr Server also NUMA verwendet, müssen Sie die individuelle Buffer Node:Page life expectancy überwachen Zähler (für jeden NUMA-Knoten gibt es ein Buffer Node Performance-Objekt), andernfalls sollten Sie Buffer Manager:Page life expectancy gut überwachen Zähler.
Noch besser ist es, ein Überwachungstool wie SQL Sentry Performance Advisor zu verwenden, das diesen Zähler als Teil des Dashboards anzeigt, wobei die NUMA-Knoten auf dem Server berücksichtigt werden, und es Ihnen ermöglicht, Warnungen einfach zu konfigurieren.
Beispiele für die Verwendung des Leistungsberaters
Unten sehen Sie einen beispielhaften Teil einer Bildschirmaufnahme von Performance Advisor für ein System mit einem einzelnen NUMA-Knoten:
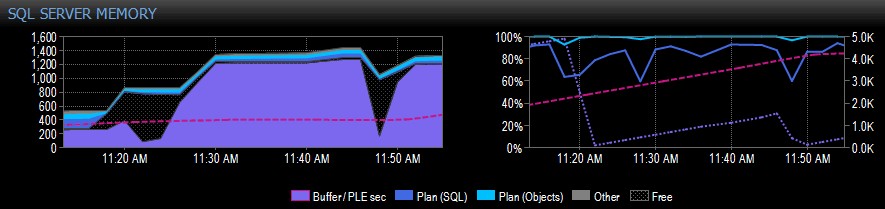
Auf der rechten Seite der Aufnahme ist die rosa-gestrichelte Linie die PLE zwischen 10:30 Uhr und etwa 11:20 Uhr – sie steigt stetig auf etwa 5.000 an, eine wirklich gesunde Zahl. Kurz vor 11.20 Uhr gibt es einen großen Abfall, und dann beginnt es wieder zu steigen, bis es um 11.45 Uhr wieder abfällt.
Dies würden Sie normalerweise sehen, wenn der Pufferpool voll ist und alle Seiten verwendet werden, und dann eine Abfrage ausgeführt wird, die dazu führt, dass eine große Menge unterschiedlicher Daten von der Festplatte gelesen wird, was einen Großteil dessen, was sich bereits im Speicher befindet, verdrängt und eine verursacht steiler Rückgang der PLE. Wenn Sie nicht wissen, was so etwas verursacht hat, sollten Sie es untersuchen, wie ich weiter unten beschreibe.
Als zweites Beispiel stammt die folgende Bildschirmaufnahme von einem unserer Remote-DBA-Clients, bei dem der Server zwei NUMA-Knoten hat (Sie können sehen, dass es zwei violette PLE-Zeilen gibt) und wo wir Performance Advisor ausgiebig verwenden:

Auf dem Server dieses Clients wird jeden Morgen gegen 5 Uhr morgens ein Job zur Indexwartung und Konsistenzprüfung gestartet, der dazu führt, dass der PLE in beiden Pufferknoten abfällt. Dies ist ein erwartetes Verhalten, daher besteht keine Notwendigkeit, es zu untersuchen, solange PLE im Laufe des Tages wieder ansteigt.
Was können Sie gegen PLE-Abfall tun?
Wenn die Ursache des PLE-Abfalls nicht bekannt ist, können Sie eine Reihe von Maßnahmen ergreifen:
- Wenn das Problem jetzt auftritt, untersuchen Sie, welche Abfragen Lesevorgänge verursachen, indem Sie die
sys.dm_os_waiting_tasksverwenden DMV, um zu sehen, welche Threads darauf warten, dass Seiten von der Festplatte gelesen werden (d. h. diejenigen, die aufPAGEIOLATCH_SHwarten ) und dann diese Abfragen korrigieren. - Wenn das Problem in der Vergangenheit aufgetreten ist, suchen Sie in der DMV sys.dm_exec_query_stats nach Abfragen mit einer hohen Anzahl physischer Lesevorgänge oder verwenden Sie ein Überwachungstool, das Ihnen diese Informationen liefern kann (z. B. die Top-SQL-Ansicht in Performance Advisor). Korrigieren Sie dann diese Abfragen.
- Korrelieren Sie den PLE-Drop mit geplanten Agent-Jobs, die die Datenbankwartung durchführen.
- Suchen Sie mithilfe von
sys.dm_exec_query_memory_grantsnach Abfragen mit sehr großen Arbeitsspeicherzuweisungen für die Abfrageausführung DMV, und beheben Sie dann diese Abfragen.
Mein vorheriger Beitrag hier erklärt mehr über Nr. 1 und Nr. 2, und ein Skript zum Untersuchen von Wartezeiten, die auf einem Server auftreten, und einen Link zu ihren Abfrageplänen finden Sie hier.
Das „Fixieren dieser Abfragen“ würde den Rahmen dieses Beitrags sprengen, also verschiebe ich das für ein anderes Mal oder als Übung für den Leser ☺
Zusammenfassung
Tappen Sie nicht in die Falle, irgendeinen empfohlenen PLE-Schwellenwert zu glauben, den Sie vielleicht online lesen. Der beste Weg, um auf PLE-Änderungen zu reagieren, ist, wenn PLE unter Ihren fällt Komfort ist und bleibt da – das ist der Hinweis auf ein Leistungsproblem, das Sie untersuchen sollten.
Im nächsten Artikel der Serie werde ich auf eine weitere häufige Ursache für ruckartiges Leistungstuning eingehen. Bis dahin viel Spaß bei der Fehlersuche!