Das SQL Server-Abfrageausführungsmodul verfügt über zwei Möglichkeiten zum Implementieren eines logischen „Union All“-Vorgangs unter Verwendung der physischen Operatoren Concatenation und Merge Join Concatenation. Während die logische Operation dieselbe ist, gibt es wichtige Unterschiede zwischen den beiden physikalischen Operatoren, die einen enormen Unterschied in der Effizienz Ihrer Ausführungspläne machen können.
Der Abfrageoptimierer leistet in vielen Fällen eine vernünftige Arbeit bei der Auswahl zwischen den beiden Optionen, aber er ist in diesem Bereich weit davon entfernt, perfekt zu sein. Dieser Artikel beschreibt die Möglichkeiten zur Abfrageoptimierung, die Merge Join Concatenation bietet, und beschreibt die internen Verhaltensweisen und Überlegungen, die Sie beachten müssen, um das Beste daraus zu machen.
Verkettung

Der Concatenation-Operator ist relativ einfach:Seine Ausgabe ist das Ergebnis des vollständigen Lesens von jeder seiner Eingaben nacheinander. Der Concatenation-Operator ist ein n-stelliges physischer Operator, was bedeutet, dass er '2…n' Eingänge haben kann. Sehen wir uns zur Veranschaulichung noch einmal das auf AdventureWorks basierende Beispiel aus meinem vorherigen Artikel „Umschreiben von Abfragen zur Leistungsverbesserung“ an:
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
Die folgende Abfrage listet Produkt- und Transaktions-IDs für sechs bestimmte Produkte auf:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711;
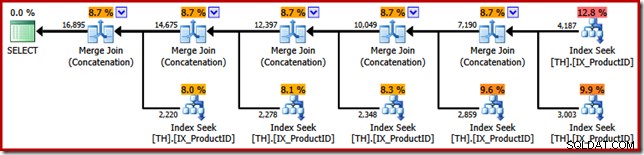
Es erzeugt einen Ausführungsplan mit einem Verkettungsoperator mit sechs Eingaben, wie im SQL Sentry Plan Explorer zu sehen:
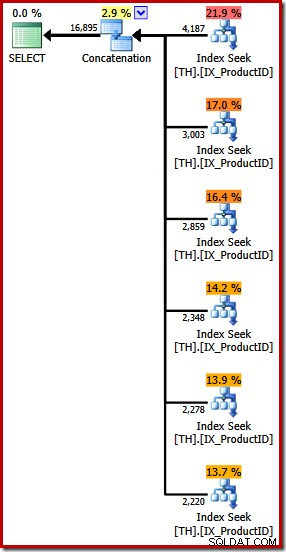
Der obige Plan enthält eine separate Indexsuche für jede aufgelistete Produkt-ID in derselben Reihenfolge wie in der Abfrage angegeben (von oben nach unten gelesen). Die oberste Indexsuche ist für Produkt 870, die nächste darunter für Produkt 873, dann 921 und so weiter. Nichts davon ist natürlich ein garantiertes Verhalten, es ist nur etwas Interessantes zu beobachten.
Ich habe bereits erwähnt, dass der Concatenation-Operator seine Ausgabe bildet, indem er nacheinander aus seinen Eingaben liest. Wenn dieser Plan ausgeführt wird, besteht eine gute Chance, dass die Ergebnismenge zuerst Zeilen für Produkt 870, dann 873, 921, 712, 707 und schließlich Produkt 711 anzeigt. Auch dies ist nicht garantiert, da wir keine ORDER angegeben haben BY-Klausel, aber sie zeigt, wie Concatenation intern funktioniert.
Ein SSIS-"Ausführungsplan"
Aus Gründen, die in Kürze sinnvoll werden, überlegen Sie, wie wir ein SSIS-Paket entwerfen könnten, um die gleiche Aufgabe auszuführen. Wir könnten das Ganze sicherlich auch als einzelne T-SQL-Anweisung in SSIS schreiben, aber die interessantere Option ist, für jedes Produkt eine separate Datenquelle zu erstellen und anstelle der SQL Server-Verkettung eine SSIS-Komponente „Union All“ zu verwenden Betreiber:
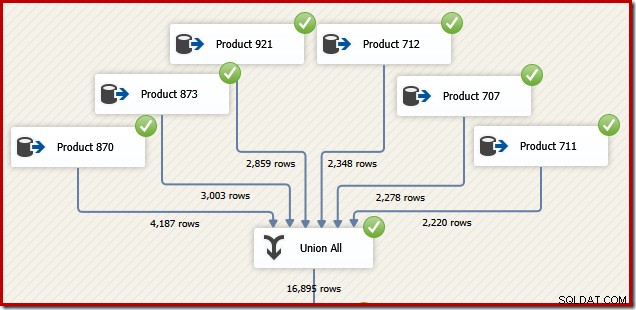
Stellen Sie sich nun vor, wir benötigen die endgültige Ausgabe dieses Datenflusses in der Reihenfolge der Transaktions-IDs. Eine Option wäre das Hinzufügen einer expliziten Sort-Komponente nach Union All:
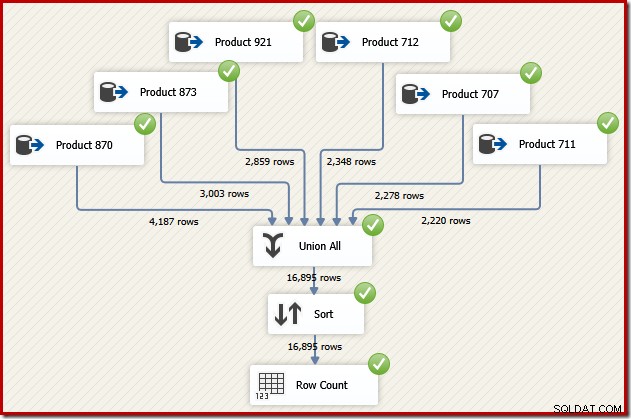
Das würde sicherlich funktionieren, aber ein geschickter und erfahrener SSIS-Designer würde erkennen, dass es eine bessere Option gibt:Lesen Sie die Quelldaten für jedes Produkt in der Reihenfolge der Transaktions-IDs (unter Verwendung des Index) und verwenden Sie dann eine reihenfolgeerhaltende Operation, um die Sätze zu kombinieren .
In SSIS heißt die Komponente, die Zeilen aus zwei sortierten Datenflüssen zu einem einzigen sortierten Datenfluss kombiniert, „Merge“. Ein neu gestalteter SSIS-Datenfluss, der Merge verwendet, um die gewünschten Zeilen in der Reihenfolge der Transaktions-IDs zurückzugeben, folgt:
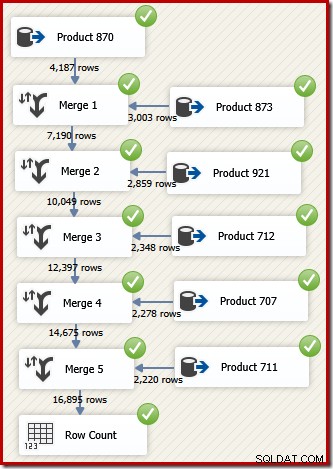
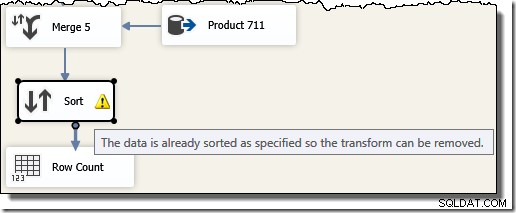
Beachten Sie, dass wir fünf separate Merge-Komponenten benötigen, da Merge im Gegensatz zur SSIS-Komponente "Union All", die n-ary war, eine binäre Komponente ist . Der neue Merge-Flow erzeugt Ergebnisse in der Reihenfolge der Transaktions-IDs, ohne dass eine teure (und blockierende) Sort-Komponente erforderlich ist. Wenn wir nach der endgültigen Zusammenführung versuchen, eine Sortierung nach Transaktions-ID hinzuzufügen, zeigt SSIS eine Warnung an, um uns mitzuteilen, dass der Stream bereits in der gewünschten Weise sortiert ist:
Der Punkt des SSIS-Beispiels kann nun offenbart werden. Sehen Sie sich den vom SQL Server-Abfrageoptimierer ausgewählten Ausführungsplan an, wenn wir ihn auffordern, die ursprünglichen T-SQL-Abfrageergebnisse in der Reihenfolge der Transaktions-IDs zurückzugeben (durch Hinzufügen einer ORDER BY-Klausel):
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
Die Ähnlichkeiten zum SSIS-Merge-Paket sind frappierend; sogar bis hin zur Notwendigkeit von fünf binären „Merge“-Operatoren. Der einzige wichtige Unterschied besteht darin, dass SSIS separate Komponenten für "Merge Join" und "Merge" hat, während SQL Server für beide denselben Kernoperator verwendet.
Um es klar zu sagen, die Merge Join (Concatenation)-Operatoren im SQL Server-Ausführungsplan sind nicht Durchführen eines Joins; Die Engine verwendet lediglich denselben physischen Operator, um die ordnungserhaltende Vereinigung all zu implementieren.
Schreiben von Ausführungsplänen in SQL Server
SSIS verfügt weder über eine Datenflussspezifikationssprache noch über einen Optimierer, um eine solche Spezifikation in eine ausführbare Datenflussaufgabe umzuwandeln. Es ist Sache des SSIS-Paketdesigners, zu erkennen, dass eine reihenfolgeerhaltende Zusammenführung möglich ist, Komponenteneigenschaften (z. B. Sortierschlüssel) entsprechend festzulegen und dann die Leistung zu vergleichen. Dies erfordert mehr Aufwand (und Geschick) seitens des Designers, bietet aber ein sehr feines Maß an Kontrolle.
Die Situation in SQL Server ist umgekehrt:Wir schreiben eine Abfrage Spezifikation Verwenden Sie die T-SQL-Sprache, verlassen Sie sich dann auf den Abfrageoptimierer, um Implementierungsoptionen zu untersuchen und eine effiziente auszuwählen. Wir haben nicht die Möglichkeit, direkt einen Ausführungsplan zu erstellen. Meistens ist dies sehr wünschenswert:SQL Server wäre zweifellos eher weniger beliebt, wenn wir für jede Abfrage ein Paket im SSIS-Stil schreiben müssten.
Dennoch (wie in meinem vorherigen Beitrag erklärt) kann der vom Optimierer gewählte Plan empfindlich auf das T-SQL reagieren, das zur Beschreibung der gewünschten Ergebnisse verwendet wird. Wenn wir das Beispiel aus diesem Artikel wiederholen, hätten wir die ursprüngliche T-SQL-Abfrage auch mit einer alternativen Syntax schreiben können:
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
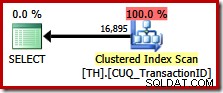
Diese Abfrage gibt genau dieselbe Ergebnismenge wie zuvor an, aber der Optimierer berücksichtigt keinen Plan, bei dem die Reihenfolge beibehalten wird (Merge-Verkettung), sondern wählt stattdessen den Clustered-Index (eine viel weniger effiziente Option):
Aufbewahrung von Bestellungen in SQL Server nutzen
Die Vermeidung unnötiger Sortierungen kann zu erheblichen Effizienzgewinnen führen, egal ob es sich um SSIS oder SQL Server handelt. Das Erreichen dieses Ziels kann in SQL Server komplizierter und schwieriger sein, da wir keine so detaillierte Kontrolle über den Ausführungsplan haben, aber es gibt immer noch Dinge, die wir tun können.
Insbesondere das Verständnis, wie der Merge Join Concatenation-Operator von SQL Server intern funktioniert, kann uns helfen, weiterhin klares, relationales T-SQL zu schreiben, während der Abfrageoptimierer ermutigt wird, gegebenenfalls Verarbeitungsoptionen zur Beibehaltung der Reihenfolge (Zusammenführung) in Betracht zu ziehen.
Wie Merge Join Concatenation funktioniert

Ein regulärer Merge-Join erfordert, dass beide Eingaben nach den Join-Schlüsseln sortiert werden. Merge Join Concatenation hingegen führt einfach zwei bereits geordnete Streams zu einem einzigen geordneten Stream zusammen – es gibt kein Join als solches.
Dies wirft die Frage auf:Was genau ist die „Ordnung“, die erhalten bleibt?
In SSIS müssen wir Sortierschlüsseleigenschaften für die Merge-Eingaben festlegen, um die Reihenfolge zu definieren. SQL Server hat kein Äquivalent dazu. Die Antwort auf die obige Frage ist etwas kompliziert, also gehen wir Schritt für Schritt vor.
Betrachten Sie das folgende Beispiel, das eine Zusammenführungsverkettung von zwei nicht indizierten Heap-Tabellen anfordert (der einfachste Fall):
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (MERGE UNION);
Diese beiden Tabellen haben keine Indizes, und es gibt keine ORDER BY-Klausel. Welche Reihenfolge wird die Merge-Join-Verkettung "bewahren"? Um Ihnen einen Moment Zeit zum Nachdenken zu geben, sehen wir uns zunächst den Ausführungsplan an, der für die obige Abfrage in SQL Server-Versionen vorher erstellt wurde 2012:
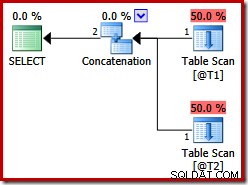
Trotz des Abfragehinweises gibt es keine Merge Join Concatenation:Vor SQL Server 2012 funktioniert dieser Hinweis nur mit UNION, nicht mit UNION ALL. Um einen Plan mit dem gewünschten Zusammenführungsoperator zu erhalten, müssen wir die Implementierung eines logischen UNION ALL (UNIA) mithilfe des physischen Operators Concatenation (CON) deaktivieren. Bitte beachten Sie, dass Folgendes nicht dokumentiert ist und nicht für die Verwendung in der Produktion unterstützt wird:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (QUERYRULEOFF UNIAtoCON);
Diese Abfrage erzeugt denselben Plan wie SQL Server 2012 und 2014 allein mit dem MERGE UNION-Abfragehinweis:
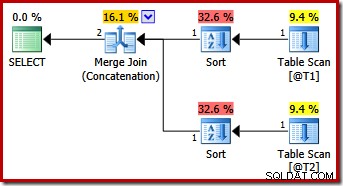
Vielleicht unerwartet enthält der Ausführungsplan explizite Sortierungen für beide Eingaben für die Zusammenführung. Die Sortiereigenschaften sind:
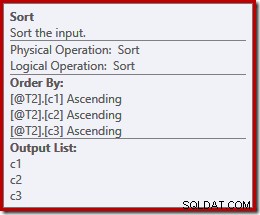
Es ist sinnvoll, dass eine reihenfolgeerhaltende Zusammenführung eine konsistente Eingabereihenfolge erfordert, aber warum wurde (c1, c2, c3) anstelle von beispielsweise (c3, c1, c2) oder (c2, c3, c1) gewählt? Als Ausgangspunkt werden Merge-Concatenation-Eingaben in der Ausgabeprojektionsliste sortiert. Der Auswahlstern in der Abfrage wird zu (c1, c2, c3) erweitert, so dass die gewählte Reihenfolge festgelegt ist.
Sortieren nach Ausgabeprojektionsliste zusammenführen
Um den Punkt weiter zu veranschaulichen, können wir den Auswahlstern selbst erweitern (wie wir sollten!), indem wir eine andere Reihenfolge wählen (c3, c2, c1), wenn wir schon dabei sind:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Die Sortierung ändert sich nun entsprechend (c3, c2, c1):
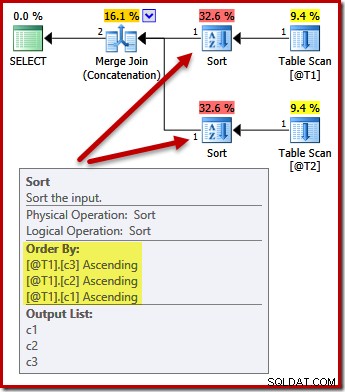
Wieder die Ausgabe der Abfrage order (vorausgesetzt, wir würden einige Daten zu den Tabellen hinzufügen) wird nicht garantiert wie gezeigt sortiert, da wir keine ORDER BY-Klausel haben. Diese Beispiele sollen lediglich zeigen, wie der Optimierer eine anfängliche Sortierreihenfolge für die Eingabe auswählt, wenn kein anderer Grund zum Sortieren vorhanden ist.
Widersprüchliche Sortierreihenfolgen
Überlegen Sie nun, was passiert, wenn wir die Projektionsliste als (c3, c2, c1) belassen und eine Anforderung hinzufügen, um die Abfrageergebnisse nach (c1, c2, c3) zu ordnen. Werden die Eingaben für die Zusammenführung immer noch nach (c3, c2, c1) sortiert, wenn nach der Zusammenführung nach (c1, c2, c3) sortiert wird, um ORDER BY zu erfüllen?
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 ORDER BY c1, c2, c3 OPTION (MERGE UNION);
Nein. Der Optimierer ist schlau genug, um doppeltes Sortieren zu vermeiden:
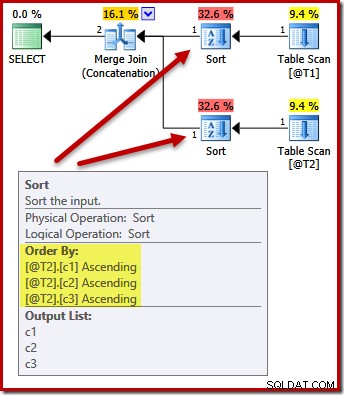
Das Sortieren beider Eingaben nach (c1, c2, c3) ist für die Zusammenführungsverkettung vollkommen akzeptabel, daher ist keine doppelte Sortierung erforderlich.
Beachten Sie, dass dieser Plan es tut garantieren, dass die Reihenfolge der Ergebnisse (c1, c2, c3) ist. Der Plan sieht genauso aus wie die früheren Pläne ohne ORDER BY, aber nicht alle internen Details werden in für den Benutzer sichtbaren Ausführungsplänen dargestellt.
Der Effekt der Einzigartigkeit
Bei der Auswahl einer Sortierreihenfolge für die Zusammenführungseingaben wird der Optimierer auch von eventuell vorhandenen Eindeutigkeitsgarantien beeinflusst. Betrachten Sie das folgende Beispiel mit fünf Spalten, aber beachten Sie die unterschiedlichen Spaltenreihenfolgen in der Operation UNION ALL:
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Der Ausführungsplan enthält Sortierungen nach (c5, c1, c2, c4, c3) für Tabelle @T1 und (c5, c4, c3, c2, c1) für Tabelle @T2:
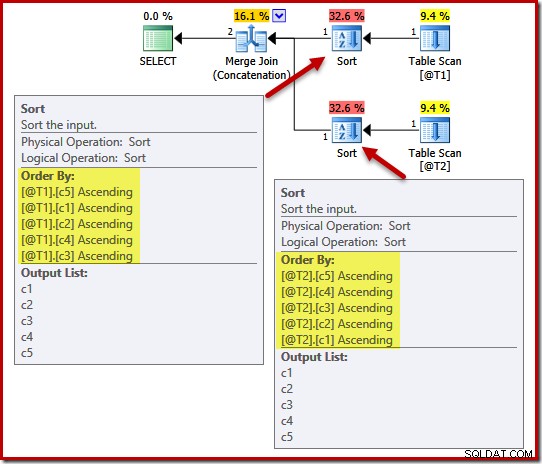
Um die Auswirkung der Eindeutigkeit auf diese Sortierungen zu demonstrieren, fügen wir Spalte c1 in Tabelle T1 und Spalte c4 in Tabelle T2 eine UNIQUE-Einschränkung hinzu:
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
Der Punkt bei der Eindeutigkeit ist, dass der Optimierer weiß, dass er mit dem Sortieren aufhören kann, sobald er auf eine garantiert eindeutige Spalte stößt. Das Sortieren nach zusätzlichen Spalten, nachdem ein eindeutiger Schlüssel gefunden wurde, wirkt sich definitionsgemäß nicht auf die endgültige Sortierreihenfolge aus.
Mit den UNIQUE-Einschränkungen kann der Optimierer die Sortierliste (c5, c1, c2, c4, c3) für T1 zu (c5, c1) vereinfachen, da c1 eindeutig ist. Ebenso wird die Sortierliste (c5, c4, c3, c2, c1) für T2 zu (c5, c4) vereinfacht, weil c4 ein Schlüssel ist:
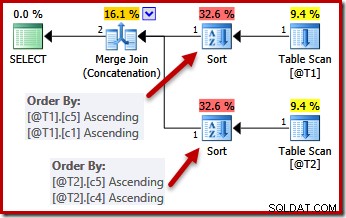
Parallelität
Die Vereinfachung durch einen eindeutigen Schlüssel ist nicht perfekt umgesetzt. In einem parallelen Plan werden die Streams so partitioniert, dass alle Zeilen für dieselbe Instanz der Zusammenführung auf demselben Thread landen. Diese Datensatzpartitionierung basiert auf den Zusammenführungsspalten und wird nicht durch das Vorhandensein eines Schlüssels vereinfacht.
Das folgende Skript verwendet das nicht unterstützte Trace-Flag 8649, um einen parallelen Plan für die vorherige Abfrage zu generieren (die ansonsten unverändert bleibt):
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION, QUERYTRACEON 8649);
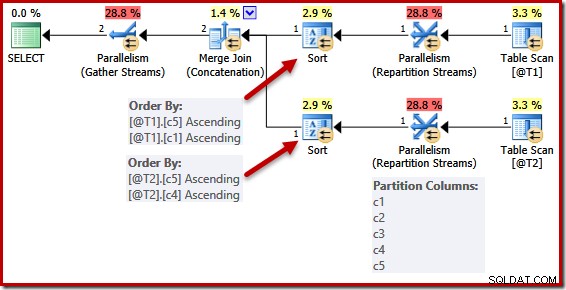
Die Sortierlisten werden wie zuvor vereinfacht, aber die Repartition Streams-Operatoren partitionieren immer noch über alle Spalten. Wenn diese Vereinfachung konsequent umgesetzt würde, würden die Repartitionierungsoperatoren auch allein auf (c5, c1) und (c5, c4) operieren.
Probleme mit nicht eindeutigen Indizes
Die Art und Weise, wie der Optimierer über die Sortieranforderungen für die Zusammenführungsverkettung urteilt, kann zu unnötigen Sortierproblemen führen, wie das nächste Beispiel zeigt:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Wenn wir uns die Abfrage und die verfügbaren Indizes ansehen, würden wir einen Ausführungsplan erwarten, der einen geordneten Scan der geclusterten Indizes durchführt und eine Merge-Join-Verkettung verwendet, um die Notwendigkeit einer Sortierung zu vermeiden. Diese Erwartung ist vollkommen gerechtfertigt, da die Clustered-Indizes die in der ORDER BY-Klausel angegebene Reihenfolge bereitstellen. Leider enthält der Plan, den wir tatsächlich erhalten, zwei Arten:
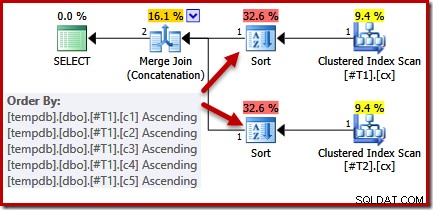
Es gibt keinen guten Grund für diese Sortierungen, sie erscheinen nur, weil die Logik des Abfrageoptimierers unvollkommen ist. Die Spaltenliste der Zusammenführungsausgabe (c1, c2, c3, c4, c5) ist eine Obermenge von ORDER BY, aber es gibt kein eindeutiges Schlüssel, um diese Liste zu vereinfachen. Als Ergebnis dieser Lücke in der Argumentation des Optimierers kommt er zu dem Schluss, dass die Zusammenführung seine nach (c1, c2, c3, c4, c5) sortierten Eingaben erfordert.
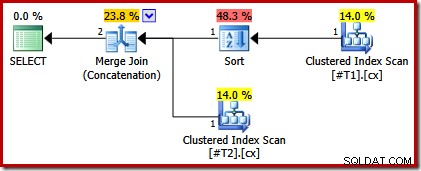
Wir können diese Analyse überprüfen, indem wir das Skript modifizieren, um einen der Clustered-Indizes eindeutig zu machen:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
Der Ausführungsplan hat jetzt nur noch eine Sortierung über der Tabelle mit dem nicht eindeutigen Index:
Wenn wir jetzt beides machen gruppierte Indizes eindeutig, es erscheinen keine Sortierungen:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE UNIQUE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1; DROP TABLE #T1, #T2;
Da beide Indizes eindeutig sind, können die anfänglichen Merge-Input-Sortierlisten auf Spalte c1 allein vereinfacht werden. Die vereinfachte Liste stimmt dann genau mit der ORDER BY-Klausel überein, sodass im endgültigen Plan keine Sortierungen erforderlich sind:
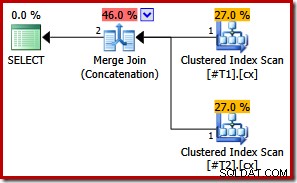
Beachten Sie, dass wir in diesem letzten Beispiel nicht einmal den Abfragehinweis benötigen, um den optimalen Ausführungsplan zu erhalten.
Abschließende Gedanken
Das Eliminieren von Sortierungen in einem Ausführungsplan kann schwierig sein. In einigen Fällen kann es so einfach sein, einen vorhandenen Index zu ändern (oder einen neuen bereitzustellen), um Zeilen in der erforderlichen Reihenfolge bereitzustellen. Der Abfrageoptimierer leistet insgesamt gute Arbeit, wenn geeignete Indizes verfügbar sind.
In (vielen) anderen Fällen kann das Vermeiden von Sortierungen jedoch ein viel tieferes Verständnis der Ausführungsengine, des Abfrageoptimierers und der Planoperatoren selbst erfordern. Das Vermeiden von Sortierungen ist zweifellos ein fortgeschrittenes Thema zur Optimierung von Abfragen, aber auch ein unglaublich lohnendes, wenn alles richtig läuft.