Es ist unwahrscheinlich, dass Sie die ganze Idee der Sharing Economy verpasst haben – ob Sie es mögen oder nicht. Beliebt bei Unternehmen wie Airbnb, Uber, Lyft und vielen anderen, ermöglicht es Menschen, etwas Geld zu verdienen, indem sie ihre ungenutzten Sachen vermieten. Sehen wir uns das Datenmodell hinter einer solchen Anwendung an.
Haben Sie ein freies Zimmer? Melde dich bei Airbnb an und verdiene zusätzliches Geld, indem du es vermietest. Haben Sie ein Auto und etwas Freizeit? Werde Uber-Fahrer. Und so geht es weiter – die Idee hinter diesen Unternehmen und vielen anderen wie ihnen ist fast dieselbe. Es geht darum, eine Ressource mit (meistens) Fremden zu teilen, mit einem Vorteil für beide Seiten. Der Eigentümer bekommt Geld für seine ungenutzte Immobilie, während der Kunde normalerweise ein gutes Geschäft macht; Dies sollte eine Win-Win-Situation sein.
Natürlich brauchen wir eine Plattform, um Eigentümer mit Kunden zu verbinden und wichtige Details im Auge zu behalten. Heute stellen wir ein Datenmodell vor, das diese Aufgabe bewältigen könnte. Lehnen Sie sich in Ihrem Stuhl zurück und genießen Sie die Fahrt durch das Datenmodell der Sharing Economy.
Was brauchen wir in unserem Datenmodell?
Die Idee, Immobilien zu vermieten, wenn wir sie nicht nutzen, erscheint sehr klug. Erstens wird das Eigentum für den beabsichtigten Zweck verwendet; Zweitens generiert die Miete eine Art zusätzliches Einkommen. Das kann Bargeld sein, aber auch ein Austausch (z. B. jemand in New York tauscht für eine Woche die Wohnung mit jemandem in Paris).
Bargeldlose Modelle sind richtig cool und setzen meist auf gegenseitiges Verständnis, Wohlwollen und Ehrlichkeit. Dieser Artikel konzentriert sich jedoch auf kostenpflichtige Sharing-Economy-Modelle. Es ist nicht so romantisch wie bargeldlose Modelle, aber das Zahlungsmodell ist ziemlich effektiv.
Wir brauchen einen sehr einfachen Weg, wie viele Immobilienbesitzer viele interessierte Kunden erreichen und umgekehrt. Dies ist die erste Anforderung an unser Datenmodell. Wir werden Benutzerkonten und mindestens zwei unterschiedliche Rollen haben – Eigentümer und Kunde.
Das nächste, was wir brauchen, ist, dass unsere App alle verfügbaren Immobilien auflistet. Für Airbnb wären das Wohnungen; Für Uber wären das Autos. Dieser Artikel konzentriert sich mehr auf die Vermietung von Wohnungen (ein Airbnb-ähnliches Datenmodell), aber ich werde das Modell so allgemein halten, dass es leicht in jeden anderen gewünschten Sharing-Economy-Dienst umgewandelt werden kann.
Für jeden Immobilieneigentümer müssen wir den Standort definieren, an dem er tätig ist. Bei Wohnungen ist dies ziemlich offensichtlich (die Stadt, in der sich die Wohnung befindet). Bei Transportdiensten hängt dies vom aktuellen Standort des Autos und/oder seines Besitzers ab.
Für jede Eigenschaft oder Ressource müssen wir die Nutzungszeiten und Anfragen/Reservierungen nachverfolgen. Dies ermöglicht es uns, verfügbare Immobilien zu finden, wenn eine neue Anfrage gestellt wird, und die Auslastung und den Preis zu berechnen. Wir können auch andere Programme verwenden, um diese Daten zu analysieren und andere Statistiken zu erstellen.
Das Datenmodell
Das Datenmodell besteht aus fünf Themenbereichen:
Countries & citiesUsers & rolesServices & documentsRequestsProvided services
Wir stellen jeden Themenbereich in der gleichen Reihenfolge vor, in der er aufgelistet ist.
Abschnitt 1:Länder und Städte
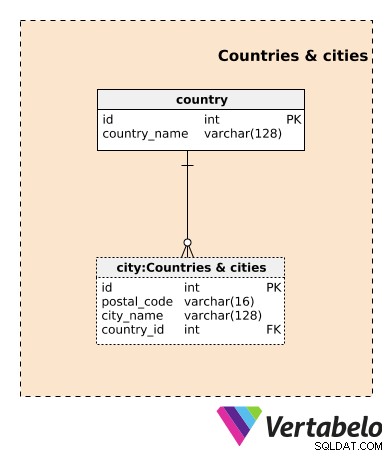
Wir beginnen mit den Countries & cities Fachbereich. Obwohl nicht spezifisch für dieses Datenmodell, sind diese Tabellen sehr wichtig. Immobilienbezogene Dienstleistungen sind in der Regel geografisch orientiert. Unser Modell ist eng mit dem Mieten einer Wohnung verbunden, daher ist der physische Standort hier entscheidend. Natürlich ändert sich dieser Standort normalerweise nicht. Es gibt einige sehr spezielle Fälle, die zu einer Standortänderung einer Immobilie führen könnten, aber ich würde diese Wohnung an ihrem neuen Standort als eine völlig neue Immobilie behandeln.
Für Auto- und/oder Fahrer-Apps wie Uber ist auch der aktuelle Standort des Autos und des Fahrers sehr wichtig. Im Gegensatz zu Mietwohnungen im Stil von Airbnb können sich diese Unterkunftsstandorte häufig ändern.
Das country Tabelle enthält eine Liste mit EINZIGARTIGEN Namen der Länder, in denen wir tätig sind. Die city Tabelle enthält eine Liste aller Städte, in denen wir tätig sind. Die EINZIGARTIGE Kombination für diese Tabelle ist die Kombination aus postal_code , city_name und country_id Attribute.
Diese beiden Tabellen könnten viele zusätzliche Attribute enthalten, aber ich habe sie absichtlich weggelassen, da sie diesem Modell keinen Mehrwert verleihen.
Abschnitt 2:Benutzer und Rollen
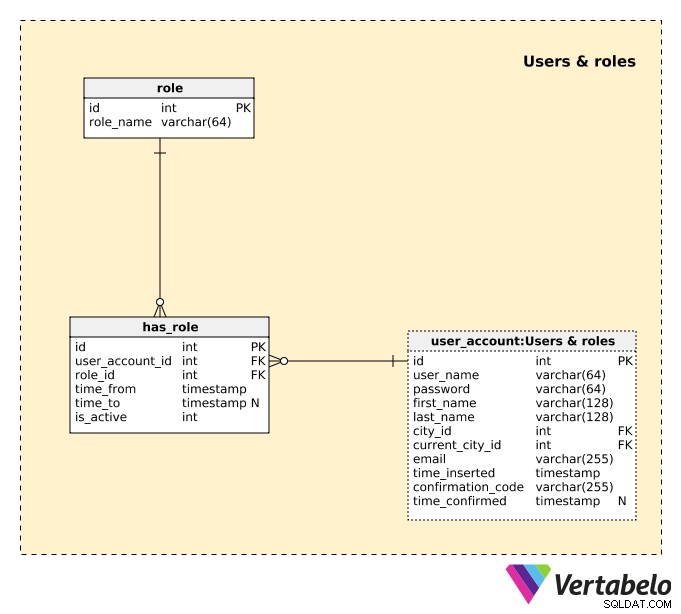
Als nächstes müssen wir Benutzer und ihre Verhaltensweisen oder Rollen in unserer Anwendung definieren. Dazu verwenden wir die drei Tabellen in Users & roles Fachgebiet.
Eine Liste aller Benutzer befindet sich im user_account Tisch. Für jeden Benutzer speichern wir die folgenden Details:
user_name– Der EINZIGARTIGE Name, den der Benutzer für den Zugriff auf unsere Anwendung gewählt hat.password– Ein Hashwert des vom Benutzer gewählten Passworts.first_nameundlast_name– Vor- und Nachname des Benutzers.city_id– Ein Verweis auf diecitywo sich der Benutzer normalerweise aufhält.current_city_id– Ein Verweis auf diecitywo sich der Benutzer gerade befindet.email– Die E-Mail-Adresse des Benutzers.time_inserted– Der Zeitstempel, wann dieser Datensatz in die Tabelle eingefügt wurde.confirmation_code– Ein Code, der während des Registrierungsprozesses generiert wird, um die E-Mail-Adresse des Benutzers zu bestätigen.time_confirmed– Der Zeitstempel, wann die E-Mail-Adresse bestätigt wurde. Dieses Attribut enthält einen NULL-Wert, bis die Bestätigung durchgeht.
Der Benutzer hat entsprechend seiner Rolle unterschiedliche Rechte in der Anwendung. Es ist auch möglich, dass ein Benutzer gleichzeitig mehr als eine aktive Rolle hat, z. Sie könnten Eigentümer einer Immobilie und Kunde einer anderen Immobilie sein. In diesem Fall verwendet der Benutzer die gleichen Anmeldedaten und hat die Möglichkeit, zwischen den Rollen zu wechseln. Jede Rolle hat einen eigenen Bildschirm in der App.
Eine Liste aller möglichen Rollen ist im role Wörterbuch. Jede Rolle wird EINZIGARTIG durch ihren role_name definiert . Der Einfachheit halber können wir nur mit zwei Rollen rechnen:„Eigentümer“ und „Kunde“.
Einem Benutzer kann dieselbe Rolle mehrmals in unterschiedlichen Zeiträumen zugewiesen werden. Ein solcher Fall wäre, wenn der Nutzer seine ungenutzte Wohnung vermietet und sich dann entscheidet, seine Wohnung nicht zu vermieten, weil er sie benötigt. Nach einigen Monaten entschied sich derselbe Nutzer jedoch, seine Wohnung erneut zu vermieten. In diesem Fall würden wir ihre Rolle deaktivieren und dann wieder aktivieren.
In has_role Tisch. Für jeden Datensatz in dieser Tabelle speichern wir:
user_account_id– Die ID des zugehörigenuser.role_id– Die ID der zugehörigenrole.time_from– Der Zeitstempel, wann diese Rolle in das System eingefügt wurde.time_to– Der Zeitstempel, wann diese Rolle deaktiviert wurde. Dieser enthält einen NULL-Wert, solange die Rolle noch aktiv ist.is_active– Wird auf False gesetzt, wenn die Rolle aus irgendeinem Grund deaktiviert wird.
Beim Einfügen eines neuen Datensatzes in diese Tabelle sollten wir auf überlappende Datensätze prüfen. Dadurch können wir vermeiden, dass dieselbe Rolle im selben Zeitraum zweimal gültig ist.
Abschnitt 3:Dienste und Dokumente
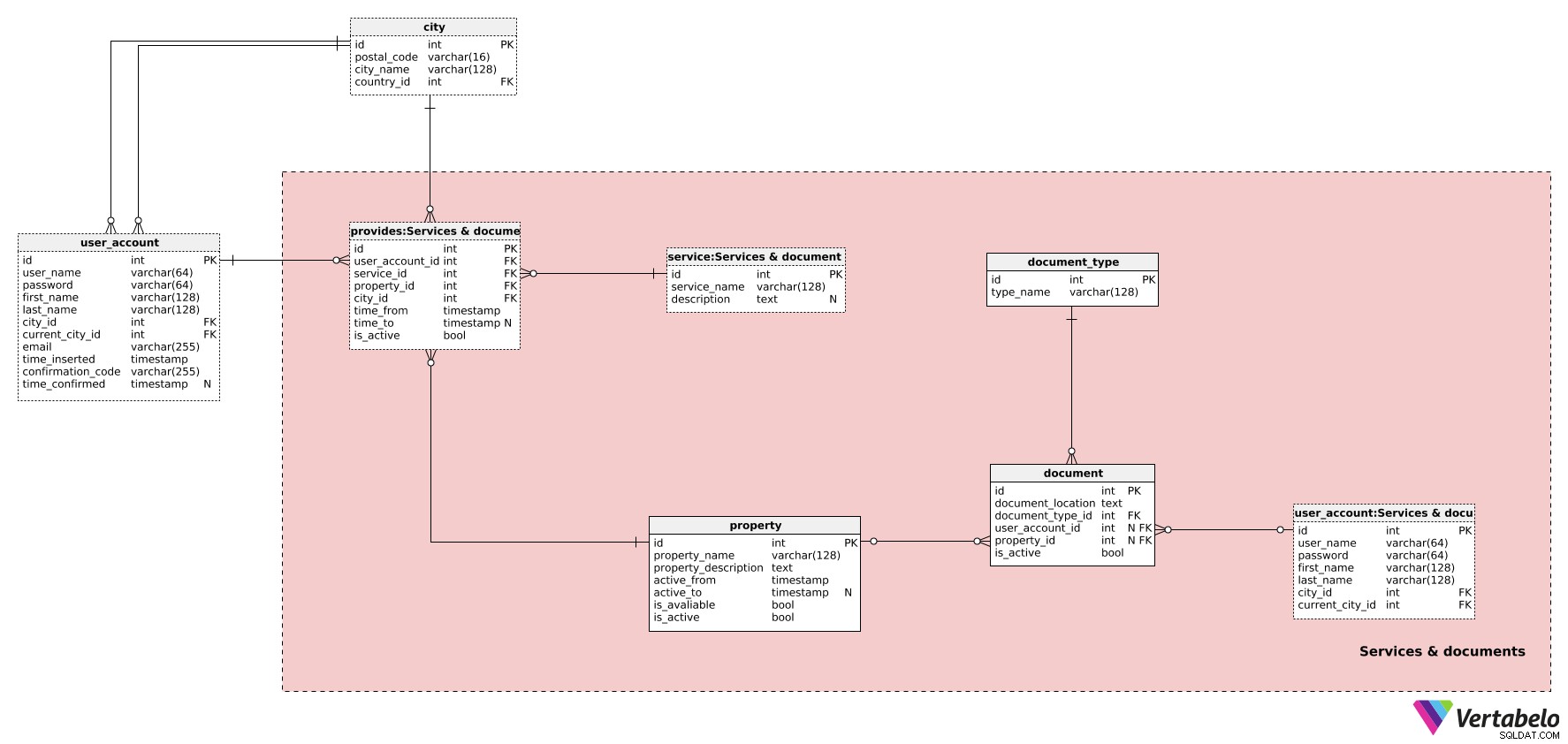
Als nächstes müssen wir die von den Benutzern bereitgestellten Dienste definieren. Wir müssen auch alle zugehörigen Dokumente im Auge behalten. Dazu benötigen wir die Tabellen in den Services & documents Fachgebiet.
Beginnen wir mit der property Tisch. Immobilien sind, was auch immer die Objekte unseres Dienstes sind:Wohnungen, Autos, Fahrräder usw. Wir können erwarten, dass Benutzer sich um ihre eigenen Immobilien kümmern. Für jede Eigenschaft müssen wir Folgendes definieren:
property_name– Der vom Benutzer gewählte Bildschirmname für diese Eigenschaft. Dieser Name wird verwendet, wenn die Immobilie potenziellen Kunden in der App angezeigt wird. Es sollte kurz und beschreibend sein und diese Eigenschaft von anderen Eigenschaften abheben.property_description– Zusätzliche textuelle Beschreibung in unstrukturiertem Format. Hier können wir eine Reihe von Details erwarten – im Grunde alles von der Größe der Wohnung bis hin dazu, ob die Kunden bei ihrer Ankunft ein Begrüßungsgetränk erhalten. Begrüßungsgetränke in Transportdiensten sind viel seltener.active_fromundactive_to– Der Zeitraum, in dem diese Eigenschaft in unserem System aktiv war. Deractive_toDas Attribut enthält den NULL-Wert, bis die Eigenschaft deaktiviert wird.is_available– Ein Flag, das angibt, ob diese Eigenschaft zu einem bestimmten Zeitpunkt verfügbar ist oder nicht.is_active– Ein Flag, das angibt, ob diese Eigenschaft in unserem System noch aktiv ist. Der Wert dieses Attributs wird im selben Moment auf False gesetztactive_toeingestellt ist.
Wir wechseln jetzt zum service Wörterbuch. Hier definieren wir alle möglichen Leistungsarten, wie „Langzeitmiete“, „Kurzzeitmiete“, „Transport“ usw. Sie enthält den EINZIGARTIGEN Namen der Leistungsart und eine zusätzliche description , falls erforderlich.
Wir behalten verwandte Eigenschaften, Dienste und Benutzer in den provides Tisch. Es speichert Zeiträume, in denen eine Eigenschaft verfügbar war. Im Falle des Transports würde uns dies sagen, wann ein Auto und ein Fahrer tatsächlich für unser Unternehmen arbeiteten. Im Falle von Mietwohnungen würde es uns mitteilen, wann eine Immobilie verfügbar ist. Für jeden Datensatz hier haben wir:
user_account_id– Die ID des Benutzers, der diesen Dienst bereitstellt.service_id– Die ID desserviceTyp angegeben.property_id– Verweist auf diepropertyverwendet.time_fromundtime_to– Wann diese Eigenschaft verwendet wurde, um diesen Dienst bereitzustellen. Dietime_toAttribut enthält einen NULL-Wert, bis dieser Datensatz deaktiviert wird.is_active– Wird auf False gesetzt, sobald diese Eigenschaft nicht mehr verwendet wird oder wenn dieser Benutzer diesen Dienst nicht mehr bereitstellt. Dies wird im selben Moment gesetzt, wenntime_toeingestellt ist.
Die verbleibenden zwei Tabellen in diesem Themenbereich beziehen sich auf Dokumente. (Die user_account-Tabelle ist nur eine Kopie des Originals, das hier verwendet wird, um eine Überschneidung der Beziehungen zu vermeiden.) Unser Unternehmen wird mit vielen Immobilieneigentümern zusammenarbeiten, und es wird fast keine Möglichkeit geben, alles persönlich zu überprüfen. Eine Möglichkeit, die Servicequalität sicherzustellen, besteht darin, alles gut zu dokumentieren.
Die erste Tabelle, die sich auf Dokumente bezieht, ist document_type Tisch. Dieses einfache Wörterbuch enthält eine Liste von UNIQUE type_name Werte. Wir können hier Werte wie „Immobilienbild“ und „Eigentümer-ID“ erwarten.
Eine Liste aller Dokumente wird im document Tisch. Diese Dokumente können sich auf Benutzerkonten, Eigenschaften oder beides beziehen. Für jedes Dokument speichern wir:
document_location– Der vollständige Pfad zu diesem Dokument.document_type_id– Ein Verweis auf dendocument_typeWörterbuch.user_account_id– Ein Verweis auf dasuser_accountTisch. Dieses Attribut enthält nur dann einen Wert, wenn das Dokument mit dem Benutzer oder verknüpft ist wenn das Dokument mit der Eigenschaft zusammenhängt, der Benutzer diese Eigenschaft aber auch besitzt.property_id– Ein Verweis auf die zugehörige Eigenschaft .is_active– Gibt an, ob dieses Dokument noch aktiv (gültig) ist oder nicht.
Abschnitt 4:Anfragen
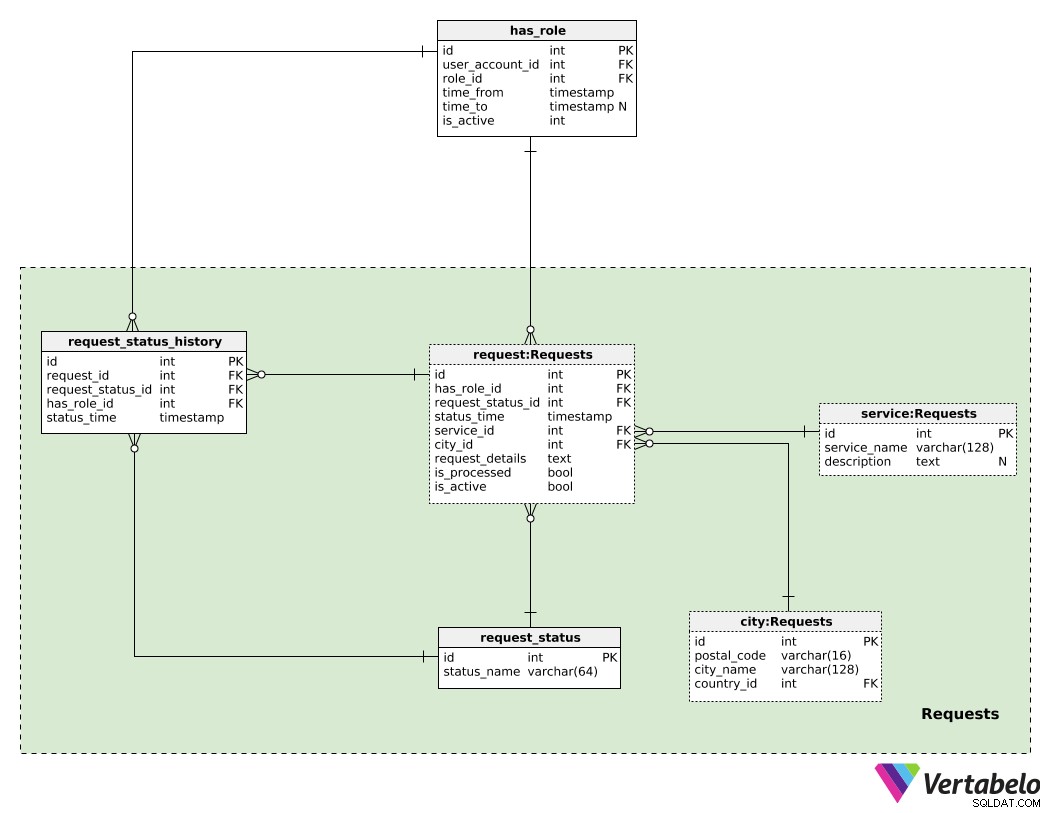
Bevor wir einen Dienst anbieten können, müssen wir einige Benutzeranfragen erhalten. Bei der Wohnungsvermietung stellt der Kunde seine Anfrage für das gewünschte Objekt, nachdem er die Inserate durchsucht und die gewünschte Wohnung gefunden hat. Bei Transportdiensten werden Anfragen von Kunden über eine mobile Anwendung gestellt (z. B. sie sind am Flughafen und benötigen eine Fahrt in 20 Minuten). Wir werden im nächsten Abschnitt darüber sprechen, wie wir Anfragen bearbeiten; Lassen Sie uns zunächst sehen, wie wir sie verwalten.
Die zentrale Tabelle in diesem Themenbereich ist der request Tisch. Für jede Anfrage speichern wir:
has_role_id– Ein Verweis auf den Benutzer (und seine aktuelle Rolle, über diehas_roleTabelle), der diese Anfrage gestellt hat.request_status_id– Ein Verweis auf den aktuellen Status dieser Anfrage.status_time– Der Zeitstempel, als dieser Status zugewiesen wurde.service_id– Die ID desservicemit dieser Anfrage erforderlich.city_id– Ein Verweis auf diecitywo dieser Service benötigt wird.request_details– Alle zusätzlichen Anfragedetails im unstrukturierten Textformat.is_processed– Ein Flag, das angibt, ob diese Anfrage verarbeitet wurde (d. h. dem Dienstanbieter zugewiesen wurde).is_active– Dieses Flag wird nur dann auf False gesetzt, wenn ein Kunde seine Anfrage storniert hat oder wenn die Anfrage aus irgendeinem Grund von der App storniert wurde.
Eine Liste aller möglichen Status ist im request_status Wörterbuch mit status_name als den EINZIGARTIGEN (und einzigen) Wert. Wir können Werte wie „Anfrage platziert“, „Eigentum reserviert“, „Fahrer zugewiesen“, „Fahrt läuft“ und „abgeschlossen“ erwarten.
Der request_status_history Tabelle speichert den Verlauf aller Status im Zusammenhang mit Anfragen. Für jeden Datensatz in dieser Tabelle speichern wir die ID der zugehörigen Anfrage (request_id ), die Status-ID (request_status_id ), die Benutzerkonto-ID und die Rolle, die der Benutzer hatte, als er diesen Status festlegte (has_role_id ). Wir zeichnen auch auf, wann jeder Status zugewiesen wurde (status_time ).
Abschnitt 5:Erbrachte Dienste
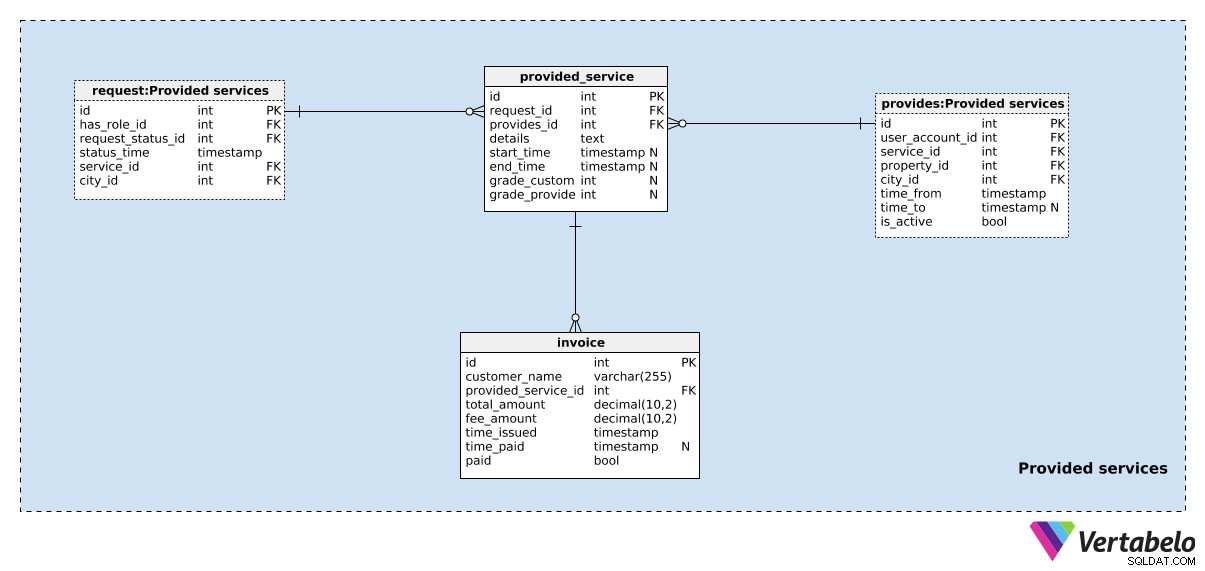
Nachdem die Anfrage gestellt wurde, müssen wir sie bearbeiten. Eine Anfrage wird entweder automatisch dem entsprechenden Dienstanbieter zugewiesen (basierend auf der angeforderten Dienstart, dem Standort usw.) oder sie wird manuell vom Dienstanbieter akzeptiert. Wir brauchen nur zwei weitere Tabellen, um dies zu handhaben.
Der erste ist der provided_service Tisch. Für jeden Datensatz fügen wir Folgendes hinzu:
request_id– Die ID der zugehörigenrequest.provides_idbereit – Ein Verweis auf denprovidesTabelle, die den Dienstanbieter und die Eigenschaft angibt, die in dieser Aktion enthalten sind.details– Alle weiteren Details in strukturiertem Textformat. Diese Struktur kann Tags und Werte enthalten, die Anforderungsdetails beschreiben. Bei einer Fahrt wären dies der Start- und Endpunkt, die zurückgelegte Strecke etc.start_timeundend_time– Der Zeitraum, in dem diese Dienstleistung erbracht wurde. Diese beiden Werte werden gesetzt, wenn der Dienst gerade gestartet und beendet wurde.grade_customerundgrade_provider– Noten, die der Kunde und der Dienstleister für diese Dienstleistung vergeben.
Die letzte Tabelle in unserem Modell ist die invoice Tisch. Wir berechnen Kunden (customer_name ) für die bereitgestellten Dienste (provided_service_id ). Für jede Rechnung müssen wir den total_amount kennen , alle gezahlten Gebühren (fee_amount ), wann die Rechnung ausgestellt wurde (time_issued ) und wann es bezahlt wurde (time_paid ) Das bezahlte Feld dient als Kennzeichen, das angibt, ob eine Rechnung bezahlt wurde.
Was halten Sie von unserem Datenmodell der Sharing Economy?
Heute haben wir über ein Datenmodell gesprochen, das von einem Unternehmen wie Airbnb oder Uber verwendet werden könnte. Das Rückgrat eines solchen Geschäftsmodells sind die Kunden und die Dienstleister. Es gibt eine Reihe von Details, die ich zu diesem Modell hinzufügen könnte. Trotzdem habe ich mich dagegen entschieden, weil das Modell schnell zu groß werden würde. Meinst du ich hätte etwas hinzufügen sollen? Wenn ja, teilen Sie es mir bitte in den Kommentaren unten mit.