Paginierung ist überall ein häufiger Anwendungsfall in Client- und Webanwendungen. Google zeigt Ihnen 10 Ergebnisse gleichzeitig an, Ihre Online-Bank kann 20 Rechnungen pro Seite anzeigen und Software zur Fehlerverfolgung und Quellcodeverwaltung zeigt möglicherweise 50 Elemente auf dem Bildschirm an.
Ich wollte mir den gängigen Paginierungsansatz auf SQL Server 2012 ansehen – OFFSET / FETCH (ein Standardäquivalent zur prioprietären LIMIT-Klausel von MySQL) – und eine Variation vorschlagen, die zu einer lineareren Paging-Leistung über den gesamten Satz führt, anstatt nur optimal zu sein am Anfang. Das ist leider alles, was viele Geschäfte testen werden.
Was ist Paginierung in SQL Server?
Basierend auf der Indizierung der Tabelle, den benötigten Spalten und der gewählten Sortiermethode kann die Paginierung relativ einfach sein. Wenn Sie nach den "ersten" 20 Kunden suchen und der gruppierte Index diese Sortierung unterstützt (z. B. ein gruppierter Index für eine IDENTITY-Spalte oder eine DateCreated-Spalte), ist die Abfrage relativ effizient. Wenn Sie eine Sortierung unterstützen müssen, die nicht gruppierte Indizes erfordert, und insbesondere wenn Sie Spalten für die Ausgabe benötigen, die nicht vom Index abgedeckt werden (egal, ob es keinen unterstützenden Index gibt), können die Abfragen teurer werden. Und selbst die gleiche Abfrage (mit einem anderen @PageNumber-Parameter) kann viel teurer werden, wenn die @PageNumber höher wird – da möglicherweise mehr Lesevorgänge erforderlich sind, um zu diesem „Slice“ der Daten zu gelangen.
Einige werden sagen, dass Sie gegen Ende des Satzes fortschreiten können, indem Sie mehr Speicher auf das Problem werfen (so dass Sie alle physischen E / A eliminieren) und / oder Caching auf Anwendungsebene verwenden (also werden Sie es nicht tun die Datenbank überhaupt). Nehmen wir für die Zwecke dieses Beitrags an, dass mehr Speicher nicht immer möglich ist, da nicht jeder Kunde einem Server RAM hinzufügen kann, der keine Speichersteckplätze mehr hat oder nicht unter seiner Kontrolle steht, oder einfach mit den Fingern schnippen und neuere, größere Server bereithalten kann gehen. Vor allem, da einige Kunden die Standard Edition verwenden, also auf 64 GB (SQL Server 2012) oder 128 GB (SQL Server 2014) begrenzt sind, oder noch eingeschränktere Editionen wie Express (1 GB) oder eines der vielen Cloud-Angebote verwenden.
Daher wollte ich mir den gängigen Paging-Ansatz auf SQL Server 2012 – OFFSET / FETCH – ansehen und eine Variante vorschlagen, die zu einer lineareren Paging-Leistung über den gesamten Satz führt, anstatt nur am Anfang optimal zu sein. Das ist leider alles, was viele Geschäfte testen werden.
Einrichtung der Paginierungsdaten / Beispiel
Ich werde von einem anderen Beitrag, Badhabits :Focusing only on disk space when selected keys, ausleihen, wo ich die folgende Tabelle mit 1.000.000 Zeilen zufälliger (aber nicht ganz realistischer) Kundendaten gefüllt habe:
CREATE TABLE [dbo].[Customers_I] ( [CustomerID] [int] IDENTITY(1,1) NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT ((1)), [Created] [datetime] NOT NULL DEFAULT (sysdatetime()), [Updated] [datetime] NULL, CONSTRAINT [C_PK_Customers_I] PRIMARY KEY CLUSTERED ([CustomerID] ASC) ); GO CREATE NONCLUSTERED INDEX [C_Active_Customers_I] ON [dbo].[Customers_I] ([FirstName] ASC, [LastName] ASC, [EMail] ASC) WHERE ([Active] = 1); GO CREATE UNIQUE NONCLUSTERED INDEX [C_Email_Customers_I] ON [dbo].[Customers_I] ([EMail] ASC); GO CREATE NONCLUSTERED INDEX [C_Name_Customers_I] ON [dbo].[Customers_I] ([LastName] ASC, [FirstName] ASC) INCLUDE ([EMail]); GO
Da ich wusste, dass ich hier E/A testen würde und sowohl aus einem warmen als auch aus einem kalten Cache testen würde, habe ich den Test zumindest ein wenig fairer gemacht, indem ich alle Indizes neu erstellt habe, um die Fragmentierung zu minimieren (da weniger getan werden würde störend, aber regelmäßig, auf den meisten ausgelasteten Systemen, die irgendeine Art von Indexwartung durchführen):
ALTER INDEX ALL ON dbo.Customers_I REBUILD WITH (ONLINE = ON);
Nach dem Neuaufbau liegt die Fragmentierung jetzt bei 0,05 % – 0,17 % für alle Indizes (Indexebene =0), die Seiten sind zu über 99 % gefüllt und die Zeilenanzahl/Seitenanzahl für die Indizes sind wie folgt:
| Index | Seitenzahl | Zeilenzahl |
|---|---|---|
| C_PK_Customers_I (geclusterter Index) | 19.210 | 1.000.000 |
| C_Email_Customers_I | 7.344 | 1.000.000 |
| C_Active_Customers_I (gefilterter Index) | 13.648 | 815.235 |
| C_Name_Kunden_I | 16.824 | 1.000.000 |
Indizes, Seitenzahlen, Zeilenzahlen
Dies ist offensichtlich kein superbreiter Tisch, und ich habe diesmal die Komprimierung aus dem Bild gelassen. Vielleicht werde ich in einem zukünftigen Test weitere Konfigurationen untersuchen.
Wie man eine SQL-Abfrage effektiv paginiert
Das Konzept der Paginierung – dem Benutzer jeweils nur Zeilen anzuzeigen – ist einfacher zu visualisieren als zu erklären. Denken Sie an den Index eines physischen Buches, das möglicherweise mehrere Seiten mit Verweisen auf Punkte innerhalb des Buches enthält, aber alphabetisch geordnet ist. Nehmen wir der Einfachheit halber an, dass zehn Elemente auf jede Seite des Index passen. Das könnte so aussehen:
Nun, wenn ich bereits die Seiten 1 und 2 des Index gelesen habe, weiß ich, dass ich 2 Seiten überspringen muss, um auf Seite 3 zu gelangen. Aber da ich weiß, dass es 10 Elemente auf jeder Seite gibt, kann ich mir das auch so vorstellen, dass 2 x 10 Elemente übersprungen werden und mit dem 21. Element begonnen wird. Oder anders ausgedrückt, ich muss die ersten (10*(3-1)) Elemente überspringen. Um dies allgemeiner zu machen, kann ich sagen, dass ich, um auf Seite n zu beginnen, die ersten (10 * (n-1)) Elemente überspringen muss. Um zur ersten Seite zu gelangen, überspringe ich 10*(1-1) Punkte, um bei Punkt 1 zu enden. Um zur zweiten Seite zu gelangen, überspringe ich 10*(2-1) Punkte, um bei Punkt 11 zu enden. Und so ein.
Mit diesen Informationen formulieren Benutzer eine Paging-Abfrage wie diese, da die in SQL Server 2012 hinzugefügten OFFSET / FETCH-Klauseln speziell dafür entwickelt wurden, so viele Zeilen zu überspringen:
SELECT [a_bunch_of_columns] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY;
Wie ich oben erwähnt habe, funktioniert dies gut, wenn es einen Index gibt, der ORDER BY unterstützt und alle Spalten in der SELECT-Klausel abdeckt (und bei komplexeren Abfragen die WHERE- und JOIN-Klauseln). Ohne unterstützenden Index können die Sortierkosten jedoch überwältigend sein, und wenn die Ausgabespalten nicht abgedeckt sind, erhalten Sie entweder eine ganze Reihe von Schlüsselsuchvorgängen oder in einigen Szenarien sogar einen Tabellenscan.
Best Practices für die Sortierung von SQL-Paginierung
Angesichts der obigen Tabelle und Indizes wollte ich diese Szenarien testen, in denen wir 100 Zeilen pro Seite anzeigen und alle Spalten in der Tabelle ausgeben möchten:
- Standard –
ORDER BY CustomerID(Cluster-Index). Dies ist die bequemste Sortierung für die Datenbankleute, da keine zusätzliche Sortierung erforderlich ist und alle Daten aus dieser Tabelle, die möglicherweise für die Anzeige benötigt werden, enthalten sind. Andererseits ist dies möglicherweise nicht der effizienteste Index, wenn Sie eine Teilmenge der Tabelle anzeigen. Die Bestellung ist für Endbenutzer möglicherweise auch nicht sinnvoll, insbesondere wenn die Kunden-ID eine Ersatzkennung ohne externe Bedeutung ist. - Telefonbuch –
ORDER BY LastName, FirstName(unterstützt nicht gruppierten Index). Dies ist die intuitivste Sortierung für Benutzer, würde jedoch einen nicht gruppierten Index erfordern, um sowohl das Sortieren als auch die Abdeckung zu unterstützen. Ohne einen unterstützenden Index müsste die gesamte Tabelle gescannt werden. - Benutzerdefiniert –
ORDER BY FirstName DESC, EMail(kein unterstützender Index). Dies stellt die Möglichkeit für den Benutzer dar, jede gewünschte Sortierreihenfolge zu wählen, ein Muster, vor dem Michael J. Swart in "UI Design Patterns That Don't Scale" warnt.
Ich wollte diese Methoden testen und Pläne und Metriken vergleichen, wenn ich mir – sowohl unter Warm-Cache- als auch unter Cold-Cache-Szenarien – Seite 1, Seite 500, Seite 5.000 und Seite 9.999 anschaue. Ich habe diese Prozeduren erstellt (die sich nur durch die ORDER BY-Klausel unterscheiden):
CREATE PROCEDURE dbo.Pagination_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerID, FirstName, LastName,
EMail, Active, Created, Updated
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Pagination_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Pagination_Test_3 -- ORDER BY FirstName DESC, EMail In Wirklichkeit werden Sie wahrscheinlich nur eine Prozedur haben, die entweder dynamisches SQL (wie in meinem Beispiel „Küchenspüle“) oder einen CASE-Ausdruck verwendet, um die Reihenfolge vorzugeben.
In beiden Fällen erhalten Sie möglicherweise die besten Ergebnisse, wenn Sie OPTION (RECOMPILE) für die Abfrage verwenden, um die Wiederverwendung von Plänen zu vermeiden, die für eine Sortieroption, aber nicht für alle, optimal sind. Ich habe hier separate Prozeduren erstellt, um diese Variablen zu entfernen; Ich habe OPTION (RECOMPILE) für diese Tests hinzugefügt, um Parameter-Sniffing und andere Optimierungsprobleme zu vermeiden, ohne den gesamten Plan-Cache wiederholt zu leeren.
Ein alternativer Ansatz zur SQL Server-Paginierung für eine bessere Leistung
Ein etwas anderer Ansatz, den ich nicht sehr oft implementiert sehe, besteht darin, die "Seite", auf der wir uns gerade befinden, nur mit dem Clustering-Schlüssel zu lokalisieren und dieser dann beizutreten:
;WITH pg AS ( SELECT [key_column] FROM dbo.[some_table] ORDER BY [some_column_or_columns] OFFSET @PageSize * (@PageNumber - 1) ROWS FETCH NEXT @PageSize ROWS ONLY ) SELECT t.[bunch_of_columns] FROM dbo.[some_table] AS t INNER JOIN pg ON t.[key_column] = pg.[key_column] -- or EXISTS ORDER BY [some_column_or_columns];
Es ist natürlich ausführlicherer Code, aber hoffentlich ist klar, wozu SQL Server gezwungen werden kann:einen Scan zu vermeiden oder zumindest Suchen aufzuschieben, bis eine viel kleinere Ergebnismenge reduziert ist. Paul White (@SQL_Kiwi) untersuchte einen ähnlichen Ansatz im Jahr 2010, bevor OFFSET/FETCH in den frühen Beta-Versionen von SQL Server 2012 eingeführt wurde (ich habe später in diesem Jahr zum ersten Mal darüber gebloggt).
Angesichts der obigen Szenarien habe ich drei weitere Prozeduren erstellt, mit dem einzigen Unterschied zwischen den Spalten, die in den ORDER BY-Klauseln angegeben sind (wir brauchen jetzt zwei, eine für die Seite selbst und eine zum Sortieren des Ergebnisses):
CREATE PROCEDURE dbo.Alternate_Test_1 -- ORDER BY CustomerID
@PageNumber INT = 1,
@PageSize INT = 100
AS
BEGIN
SET NOCOUNT ON;
;WITH pg AS
(
SELECT CustomerID
FROM dbo.Customers_I
ORDER BY CustomerID
OFFSET @PageSize * (@PageNumber - 1) ROWS
FETCH NEXT @PageSize ROWS ONLY
)
SELECT c.CustomerID, c.FirstName, c.LastName,
c.EMail, c.Active, c.Created, c.Updated
FROM dbo.Customers_I AS c
WHERE EXISTS (SELECT 1 FROM pg WHERE pg.CustomerID = c.CustomerID)
ORDER BY c.CustomerID OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Alternate_Test_2 -- ORDER BY LastName, FirstName
CREATE PROCEDURE dbo.Alternate_Test_3 -- ORDER BY FirstName DESC, EMail Hinweis:Dies funktioniert möglicherweise nicht so gut, wenn Ihr Primärschlüssel nicht geclustert ist – ein Teil des Tricks, der dies besser macht, wenn ein unterstützender Index verwendet werden kann, besteht darin, dass der Clustering-Schlüssel bereits im Index ist, also a Nachschlagen wird oft vermieden.
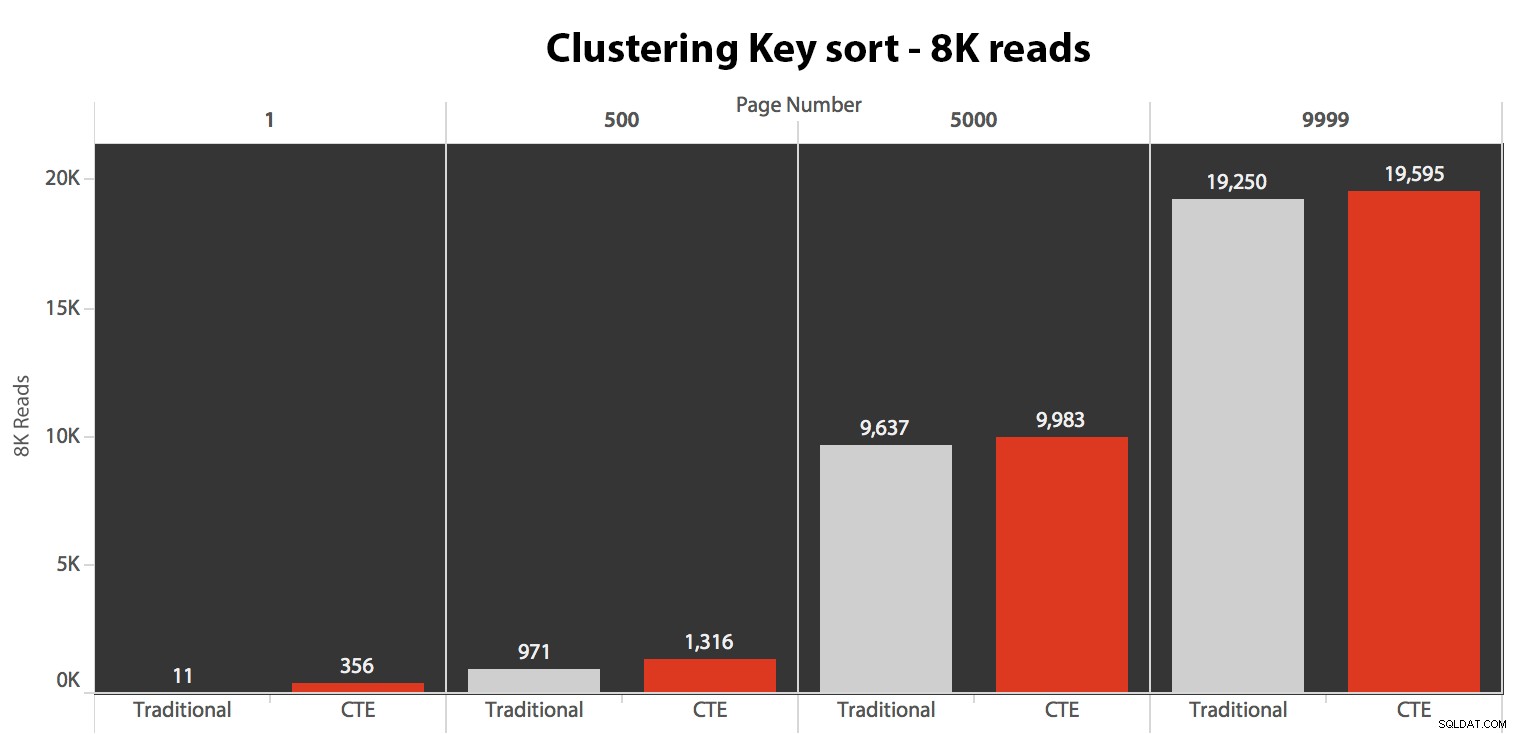
Testen der Clustering-Schlüsselsortierung
Zuerst habe ich den Fall getestet, in dem ich keine großen Unterschiede zwischen den beiden Methoden erwartet hatte – die Sortierung nach dem Clustering-Schlüssel. Ich habe diese Anweisungen in einem Stapel im SQL Sentry Plan Explorer ausgeführt und die Dauer, die Lesevorgänge und die grafischen Pläne beobachtet, um sicherzustellen, dass jede Abfrage von einem vollständig kalten Cache aus gestartet wurde:
SET NOCOUNT ON; -- default method DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Pagination_Test_1 @PageNumber = 9999; -- alternate method DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 1; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 500; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 5000; DBCC DROPCLEANBUFFERS; EXEC dbo.Alternate_Test_1 @PageNumber = 9999;
Die Ergebnisse hier waren nicht erstaunlich. Über 5 Ausführungen wird hier die durchschnittliche Anzahl von Lesevorgängen angezeigt, die vernachlässigbare Unterschiede zwischen den beiden Abfragen über alle Seitenzahlen hinweg zeigt, wenn nach dem Clustering-Schlüssel sortiert wird:
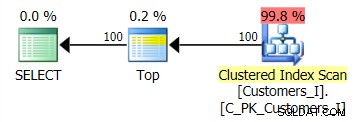
Der Plan für die Standardmethode (wie im Plan-Explorer angezeigt) war in allen Fällen wie folgt:
Während der Plan für die CTE-basierte Methode so aussah:
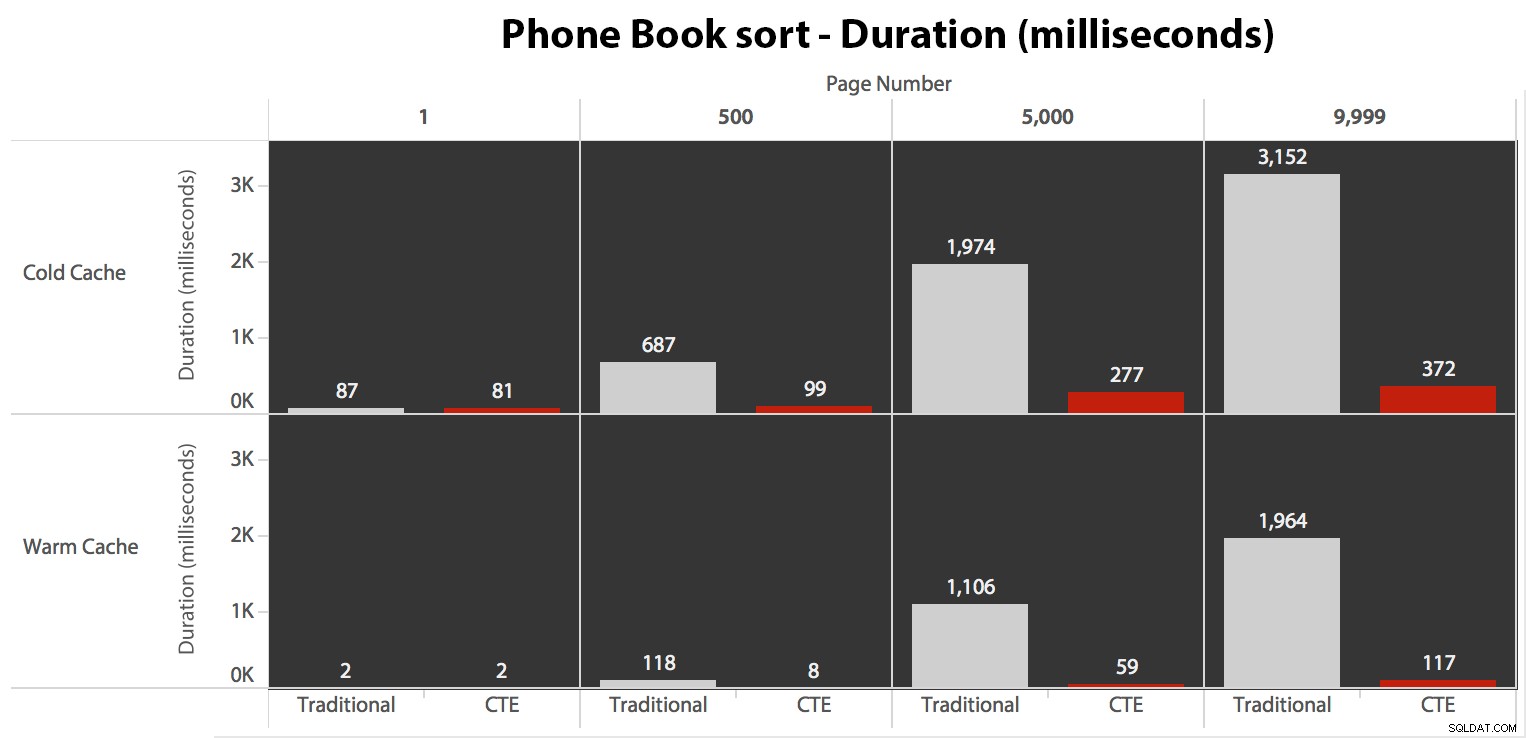
Während die I/O unabhängig vom Caching gleich war (nur viel mehr Read-Ahead-Lesevorgänge im Cold-Cache-Szenario), habe ich die Dauer mit einem Cold-Cache und auch mit einem Warm-Cache gemessen (wobei ich die DROPCLEANBUFFERS-Befehle auskommentiert habe). und die Abfragen vor dem Messen mehrmals ausgeführt haben). Diese Dauern sahen so aus:
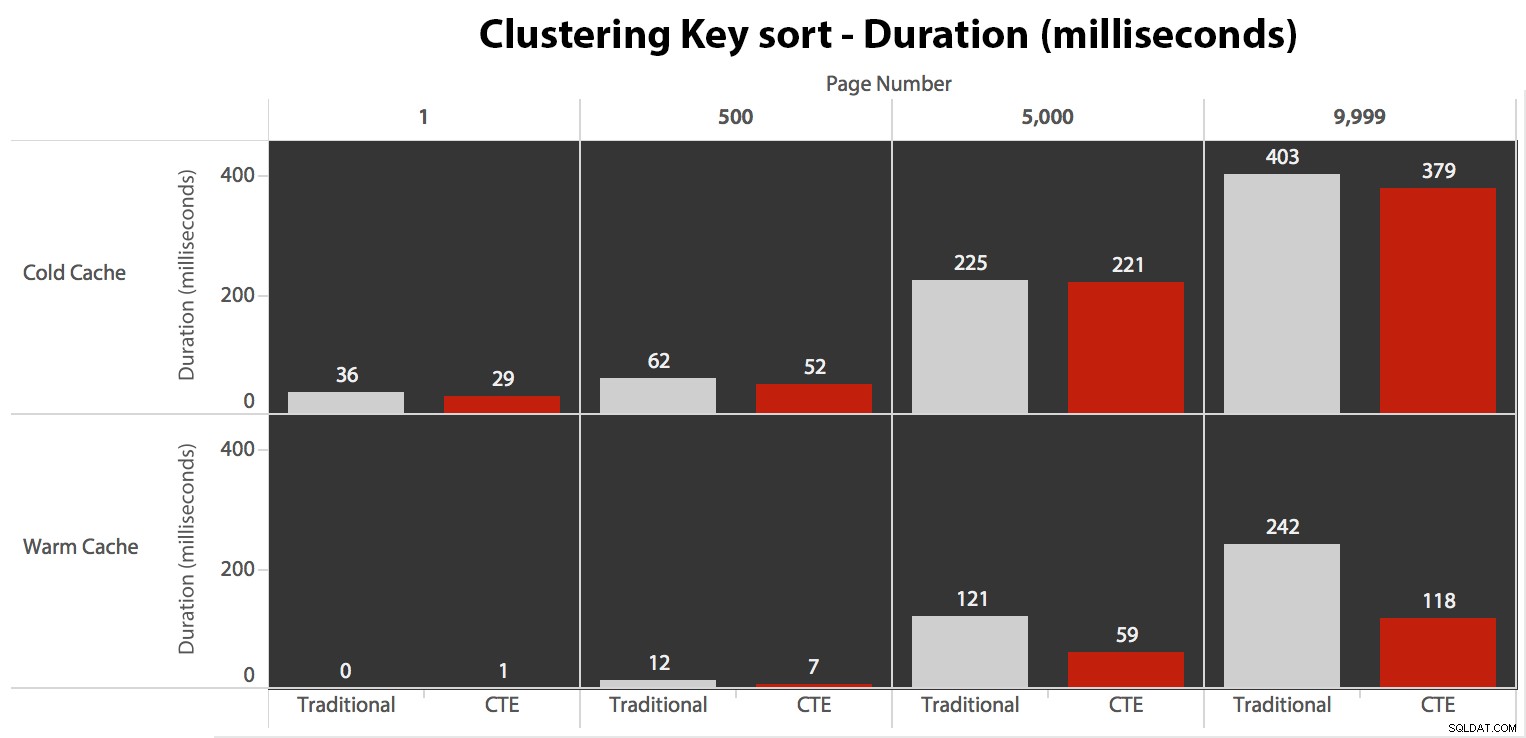
Während Sie ein Muster sehen können, das zeigt, dass die Dauer mit zunehmender Seitenzahl zunimmt, behalten Sie die Skala im Hinterkopf:Um die Zeilen 999.801 -> 999.900 zu erreichen, sprechen wir im schlimmsten Fall von einer halben Sekunde und im besten Fall von 118 Millisekunden. Der CTE-Ansatz gewinnt, aber nicht sehr viel.
Testen der Telefonbuchsortierung
Als nächstes habe ich den zweiten Fall getestet, in dem die Sortierung durch einen nicht abdeckenden Index für LastName, FirstName unterstützt wurde. Die obige Abfrage hat nur alle Instanzen von Test_1 geändert zu Test_2 . Hier waren die Lesevorgänge mit einem Cold-Cache:
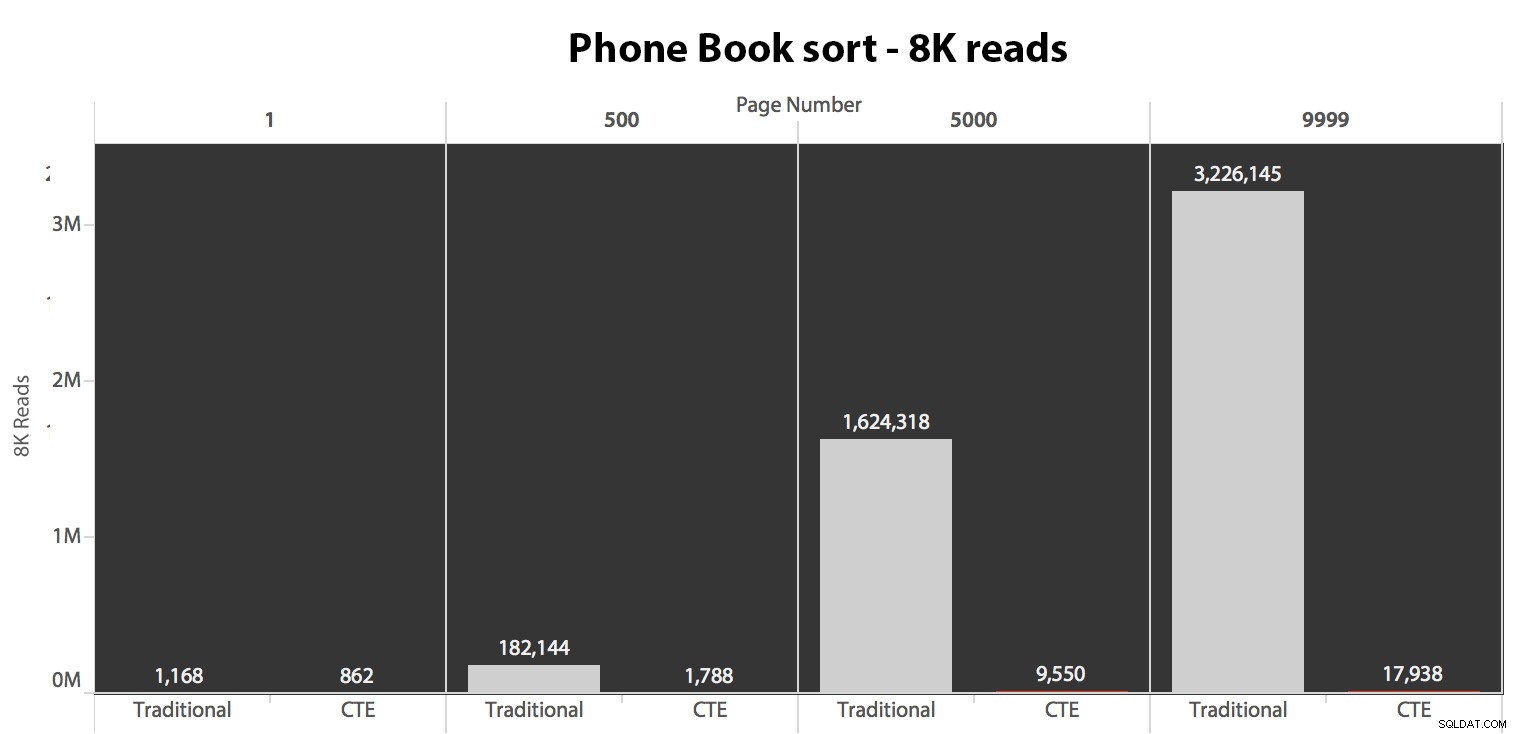
(Die Lesevorgänge unter einem warmen Cache folgten demselben Muster – die tatsächlichen Zahlen wichen leicht ab, aber nicht genug, um ein separates Diagramm zu rechtfertigen.)
Wenn wir den Clustered-Index nicht zum Sortieren verwenden, ist es klar, dass die I/O-Kosten, die mit der traditionellen Methode von OFFSET/FETCH verbunden sind, weitaus höher sind, als wenn die Schlüssel zuerst in einem CTE identifiziert und die restlichen Spalten abgerufen werden nur für diese Teilmenge.
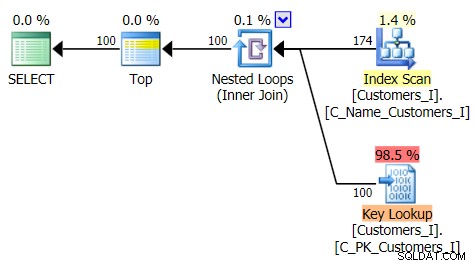
Hier ist der Plan für den traditionellen Abfrageansatz:
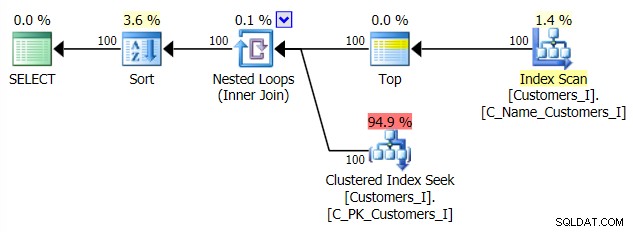
Und der Plan für meinen alternativen CTE-Ansatz:
Zum Schluss noch die Dauer:
Der traditionelle Ansatz zeigt einen sehr offensichtlichen Anstieg der Dauer, wenn Sie zum Ende der Paginierung marschieren. Der CTE-Ansatz zeigt ebenfalls ein nichtlineares Muster, aber es ist weit weniger ausgeprägt und ergibt ein besseres Timing bei jeder Seitenzahl. Wir sehen 117 Millisekunden für die vorletzte Seite, im Gegensatz zum herkömmlichen Ansatz, der bei fast zwei Sekunden liegt.
Testen der benutzerdefinierten Sortierung
Schließlich habe ich die Abfrage so geändert, dass sie Test_3 verwendet gespeicherte Prozeduren, um den Fall zu testen, in dem die Sortierung vom Benutzer definiert wurde und keinen unterstützenden Index hatte. Die E/A war über alle Testreihen hinweg konsistent; Die Grafik ist so uninteressant, ich werde nur darauf verlinken. Lange Rede kurzer Sinn:Bei allen Tests gab es etwas mehr als 19.000 Reads. Der Grund dafür ist, dass jede einzelne Variante einen vollständigen Scan durchführen musste, da kein Index zur Unterstützung der Bestellung vorhanden war. Hier ist der Plan für den traditionellen Ansatz:
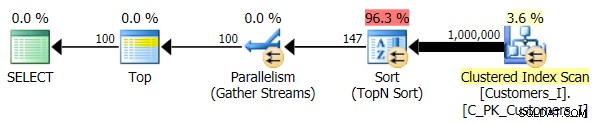
Und während der Plan für die CTE-Version der Abfrage erschreckend komplexer aussieht …
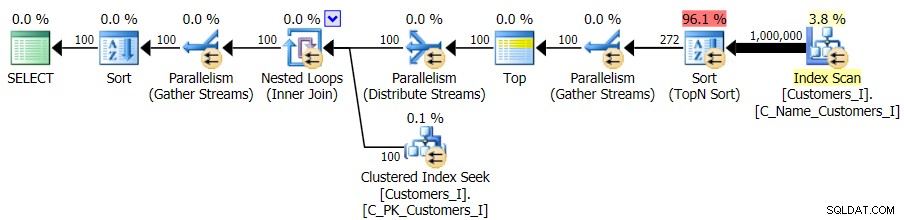
…es führt in allen bis auf einen Fall zu geringeren Laufzeiten. Hier sind die Dauern:
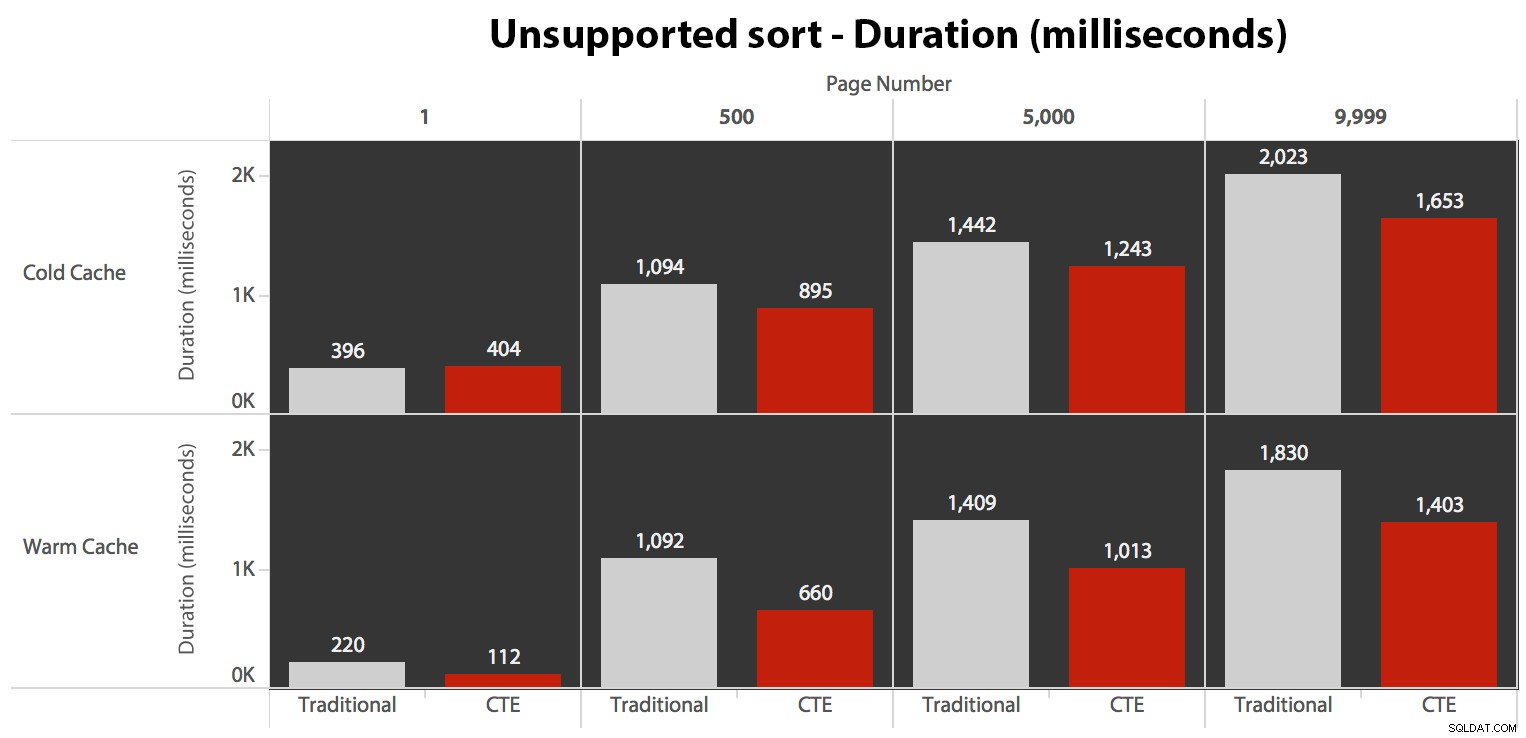
Sie können sehen, dass wir hier mit beiden Methoden keine lineare Leistung erzielen können, aber der CTE ist in jedem einzelnen Fall mit einem guten Vorsprung (irgendwo zwischen 16 % und 65 % besser) am besten, außer bei der Cold-Cache-Abfrage gegen die erste Seite (wo es satte 8 Millisekunden verloren hat). Es ist auch interessant festzustellen, dass der traditionellen Methode durch einen warmen Cache in der "Mitte" (Seiten 500 und 5000) überhaupt nicht viel geholfen wird; erst gegen ende des Sets gibt es nennenswerte effizienz.
Höhere Lautstärke
Nachdem ich einige Ausführungen einzeln getestet und Durchschnittswerte genommen hatte, hielt ich es auch für sinnvoll, ein hohes Transaktionsvolumen zu testen, das den realen Datenverkehr auf einem ausgelasteten System einigermaßen simuliert. Also habe ich einen Job mit 6 Schritten erstellt, einen für jede Kombination aus Abfragemethode (traditionelles Paging vs. CTE) und Sortiertyp (Clustering-Schlüssel, Telefonbuch und nicht unterstützt), mit einer 100-Schritte-Sequenz zum Treffen der vier obigen Seitenzahlen , jeweils 10 Mal und 60 weitere zufällig ausgewählte Seitenzahlen (aber für jeden Schritt gleich). So habe ich das Joberstellungsskript generiert:
SET NOCOUNT ON;
DECLARE @sql NVARCHAR(MAX), @job SYSNAME = N'Paging Test', @step SYSNAME, @command NVARCHAR(MAX);
;WITH t10 AS (SELECT TOP (10) number FROM master.dbo.spt_values),
f AS (SELECT f FROM (VALUES(1),(500),(5000),(9999)) AS f(f))
SELECT @sql = STUFF((SELECT CHAR(13) + CHAR(10)
+ N'EXEC dbo.$p$_Test_$v$ @PageNumber = ' + RTRIM(f) + ';'
FROM
(
SELECT f FROM
(
SELECT f.f FROM t10 CROSS JOIN f
UNION ALL
SELECT TOP (60) f = ABS(CHECKSUM(NEWID())) % 10000
FROM sys.all_objects
) AS x
) AS y ORDER BY NEWID()
FOR XML PATH(''),TYPE).value(N'.[1]','nvarchar(max)'),1,0,'');
IF EXISTS (SELECT 1 FROM msdb.dbo.sysjobs WHERE name = @job)
BEGIN
EXEC msdb.dbo.sp_delete_job @job_name = @job;
END
EXEC msdb.dbo.sp_add_job
@job_name = @job,
@enabled = 0,
@notify_level_eventlog = 0,
@category_id = 0,
@owner_login_name = N'sa';
EXEC msdb.dbo.sp_add_jobserver
@job_name = @job,
@server_name = N'(local)';
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT step = p.p + '_' + v.v,
command = REPLACE(REPLACE(@sql, N'$p$', p.p), N'$v$', v.v)
FROM
(SELECT v FROM (VALUES('1'),('2'),('3')) AS v(v)) AS v
CROSS JOIN
(SELECT p FROM (VALUES('Alternate'),('Pagination')) AS p(p)) AS p
ORDER BY p.p, v.v;
OPEN c; FETCH c INTO @step, @command;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC msdb.dbo.sp_add_jobstep
@job_name = @job,
@step_name = @step,
@command = @command,
@database_name = N'IDs',
@on_success_action = 3;
FETCH c INTO @step, @command;
END
EXEC msdb.dbo.sp_update_jobstep
@job_name = @job,
@step_id = 6,
@on_success_action = 1; -- quit with success
PRINT N'EXEC msdb.dbo.sp_start_job @job_name = ''' + @job + ''';'; Hier ist die resultierende Job-Step-Liste und eine der Eigenschaften des Steps:
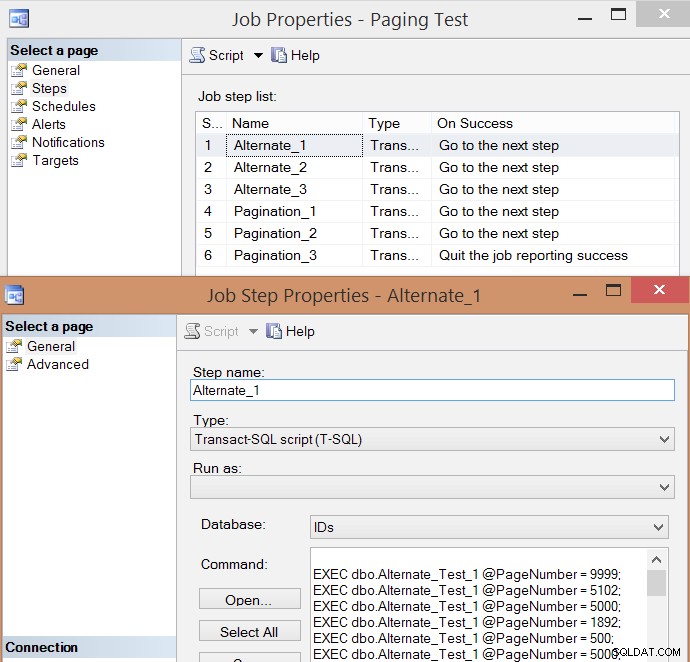
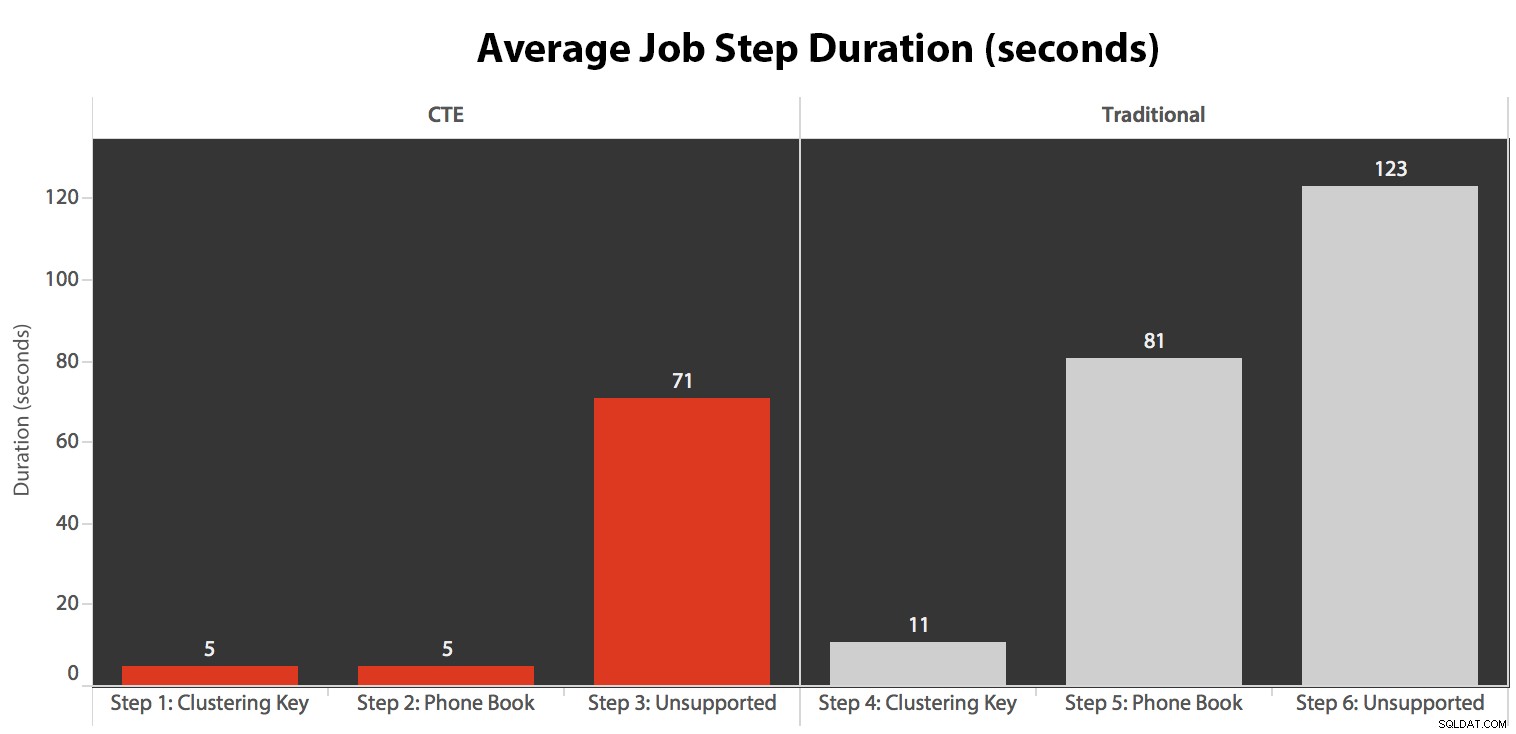
Ich habe den Job fünfmal ausgeführt, dann den Jobverlauf überprüft und hier die durchschnittliche Laufzeit jedes Schritts:
Ich habe auch eine der Ausführungen mit dem SQL Sentry Event Manager-Kalender korreliert…
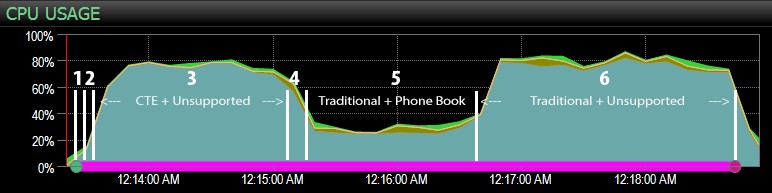
…mit dem SQL Sentry-Dashboard und manuell ungefähr markiert, wo jeder der sechs Schritte lief. Hier ist das CPU-Auslastungsdiagramm von der Windows-Seite des Dashboards:
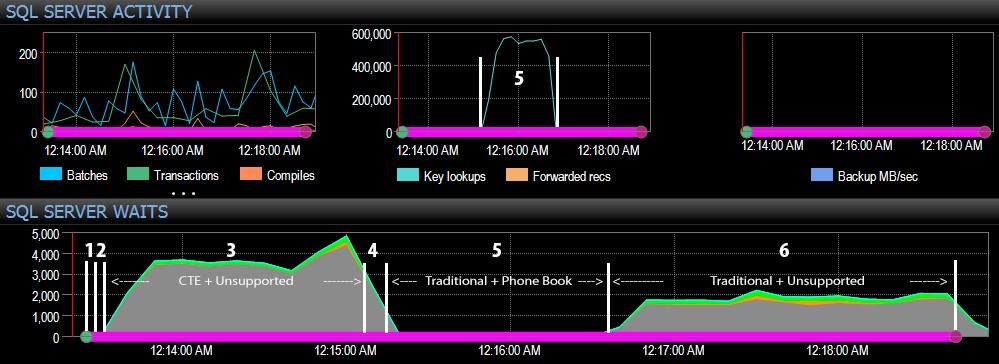
Und auf der SQL Server-Seite des Dashboards befanden sich die interessanten Metriken in den Key Lookups- und Waits-Diagrammen:
Die interessantesten Beobachtungen nur aus rein visueller Perspektive:
- Die CPU ist während Schritt 3 (CTE + kein unterstützender Index) und Schritt 6 (herkömmlich + kein unterstützender Index) mit etwa 80 % ziemlich heiß;
- CXPACKET-Wartezeiten sind in Schritt 3 relativ hoch und in geringerem Maße in Schritt 6;
- Sie können den enormen Anstieg der Schlüsselsuchvorgänge auf fast 600.000 innerhalb einer Zeitspanne von etwa einer Minute sehen (entsprechend Schritt 5 – dem traditionellen Ansatz mit einem Index im Stil eines Telefonbuchs).
In einem zukünftigen Test – wie bei meinem vorherigen Beitrag zu GUIDs – möchte ich dies auf einem System testen, bei dem die Daten nicht in den Speicher passen (einfach zu simulieren) und bei dem die Festplatten langsam sind (nicht so einfach zu simulieren). , da einige dieser Ergebnisse wahrscheinlich von Dingen profitieren, die nicht jedes Produktionssystem hat – schnelle Festplatten und ausreichend RAM. Ich sollte die Tests auch erweitern, um mehr Variationen einzubeziehen (mit dünnen und breiten Spalten, dünnen und breiten Indizes, einem Telefonbuchindex, der tatsächlich alle Ausgabespalten abdeckt, und Sortierung in beide Richtungen). Scope Creep hat den Umfang meiner Tests für diese erste Testreihe definitiv begrenzt.
Verbessern der SQL Server-Paginierung
Paginierung muss nicht immer schmerzhaft sein; SQL Server 2012 vereinfacht sicherlich die Syntax, aber wenn Sie einfach die native Syntax einfügen, sehen Sie möglicherweise nicht immer einen großen Vorteil. Hier habe ich gezeigt, dass eine etwas ausführlichere Syntax unter Verwendung eines CTE im besten Fall zu einer viel besseren Leistung und im schlimmsten Fall zu wohl vernachlässigbaren Leistungsunterschieden führen kann. Indem wir die Datenlokalisierung vom Datenabruf in zwei verschiedene Schritte trennen, können wir in einigen Szenarien einen enormen Vorteil sehen, abgesehen von höheren CXPACKET-Wartezeiten in einem Fall (und selbst dann wurden die parallelen Abfragen schneller beendet als die anderen Abfragen, die wenig oder keine Wartezeiten anzeigten, daher war es unwahrscheinlich, dass sie die "bösen" CXPACKET-Wartezeiten waren, vor denen Sie alle warnen).
Dennoch ist selbst die schnellere Methode langsam, wenn es keinen unterstützenden Index gibt. Während Sie vielleicht versucht sind, einen Index für jeden möglichen Sortieralgorithmus zu implementieren, den ein Benutzer wählen könnte, sollten Sie vielleicht erwägen, weniger Optionen bereitzustellen (da wir alle wissen, dass Indizes nicht kostenlos sind). Muss Ihre Anwendung beispielsweise unbedingt die Sortierung nach Nachname aufsteigend *und* Nachname absteigend unterstützen? Wenn sie direkt zu den Kunden gehen wollen, deren Nachnamen mit Z beginnen, können sie dann nicht zur *letzten* Seite gehen und rückwärts arbeiten? Das ist eher eine geschäftliche und benutzerfreundliche Entscheidung als eine technische Entscheidung. Behalten Sie sie einfach als Option bei, bevor Sie Indizes auf jede Sortierspalte in beide Richtungen schlagen, um die beste Leistung selbst für die undurchsichtigsten Sortieroptionen zu erzielen.