Obwohl sie mit vielen Einschränkungen und einigen wichtigen Vorbehalten bei der Implementierung einhergehen, sind indizierte Ansichten immer noch ein sehr leistungsfähiges SQL Server-Feature, wenn sie unter den richtigen Umständen richtig eingesetzt werden. Eine häufige Verwendung besteht darin, eine voraggregierte Ansicht der zugrunde liegenden Daten bereitzustellen, sodass Benutzer Ergebnisse direkt abfragen können, ohne dass bei jeder Ausführung einer Abfrage die Kosten für die Verarbeitung der zugrunde liegenden Verknüpfungen, Filter und Aggregate anfallen.
Obwohl neue Funktionen der Enterprise Edition wie spaltenweise Speicherung und Verarbeitung im Stapelmodus die Leistungsmerkmale vieler großer Abfragen dieses Typs verändert haben, gibt es immer noch keinen schnelleren Weg, um ein Ergebnis zu erhalten, als die gesamte zugrunde liegende Verarbeitung vollständig zu vermeiden, egal wie effizient diese Verarbeitung ist hätte werden können.
Bevor indizierte Ansichten (und ihre begrenzteren Cousins, berechnete Spalten) zum Produkt hinzugefügt wurden, schrieben Datenbankprofis manchmal komplexen Multi-Trigger-Code, um die Ergebnisse einer wichtigen Abfrage in einer echten Tabelle darzustellen. Diese Art der Anordnung ist notorisch schwierig unter allen Umständen richtig hinzubekommen, insbesondere wenn häufig gleichzeitig Änderungen an den zugrunde liegenden Daten vorgenommen werden.
Das Feature der indizierten Ansichten macht all dies viel einfacher, wo es sinnvoll und richtig angewendet wird. Die Datenbank-Engine kümmert sich um alles, was erforderlich ist, um sicherzustellen, dass die aus einer indizierten Ansicht gelesenen Daten jederzeit mit den zugrunde liegenden Abfrage- und Tabellendaten übereinstimmen.
Inkrementelle Wartung
SQL Server hält indizierte Ansichtsdaten mit der zugrunde liegenden Abfrage synchronisiert, indem die Ansichtsindizes automatisch entsprechend aktualisiert werden, wenn sich Daten in den Basistabellen ändern. Die Kosten für diese Pflegetätigkeit trägt der Prozess, der die Stammdaten ändert. Die zusätzlichen Vorgänge, die zum Verwalten der Ansichtsindizes erforderlich sind, werden stillschweigend zum Ausführungsplan für den ursprünglichen Einfüge-, Aktualisierungs-, Lösch- oder Zusammenführungsvorgang hinzugefügt. Im Hintergrund kümmert sich SQL Server auch um subtilere Probleme in Bezug auf die Transaktionsisolation, beispielsweise um die korrekte Behandlung von Transaktionen sicherzustellen, die unter Snapshot- oder Read-Committed-Snapshot-Isolation ausgeführt werden.
Das Konstruieren der zusätzlichen Ausführungsplanoperationen, die zum korrekten Verwalten der Ansichtsindizes erforderlich sind, ist keine triviale Angelegenheit, wie jeder wissen wird, der versucht hat, eine "durch Triggercode verwaltete Zusammenfassungstabelle" zu implementieren. Die Komplexität der Aufgabe ist einer der Gründe dafür, dass indizierte Ansichten so viele Einschränkungen haben. Die Beschränkung der unterstützten Oberfläche auf innere Verbindungen, Projektionen, Auswahlen (Filter) und die Aggregate SUM und COUNT_BIG reduziert die Implementierungskomplexität erheblich.
Indizierte Ansichten werden inkrementell beibehalten . Das bedeutet, dass der Abfrageprozessor die Nettoauswirkung der Änderungen der Basistabelle auf die Ansicht bestimmt und nur die Änderungen anwendet, die erforderlich sind, um die Ansicht auf den neuesten Stand zu bringen. In einfachen Fällen kann es die notwendigen Deltas nur aus den Änderungen der Basistabelle und den aktuell in der Ansicht gespeicherten Daten berechnen. Wenn die Ansichtsdefinition Verknüpfungen enthält, muss der Wartungsabschnitt der indizierten Ansicht des Ausführungsplans ebenfalls auf die verknüpften Tabellen zugreifen, aber dies kann normalerweise effizient durchgeführt werden, wenn geeignete Basistabellenindizes vorhanden sind.
Um die Implementierung weiter zu vereinfachen, verwendet SQL Server immer dieselbe grundlegende Planform (als Ausgangspunkt), um Wartungsvorgänge für indizierte Ansichten zu implementieren. Die vom Abfrageoptimierer bereitgestellten normalen Einrichtungen werden verwendet, um die Standardwartungsform nach Bedarf zu vereinfachen und zu optimieren. Wir wenden uns nun einem Beispiel zu, um diese Konzepte zusammenzubringen.
Beispiel 1 – Einreihige Einfügung
Angenommen, wir haben die folgende einfache Tabelle und indizierte Ansicht:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
SumValue = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
T1.GroupID BETWEEN 1 AND 5
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Nachdem dieses Skript ausgeführt wurde, sehen die Daten in der Beispieltabelle folgendermaßen aus:

Und die indizierte Ansicht enthält:

Das einfachste Beispiel für einen Wartungsplan für indizierte Ansichten für dieses Setup tritt auf, wenn wir der Basistabelle eine einzelne Zeile hinzufügen:
INSERT dbo.T1
(GroupID, Value)
VALUES
(3, 6); Der Ausführungsplan für diese Einlage ist unten dargestellt:
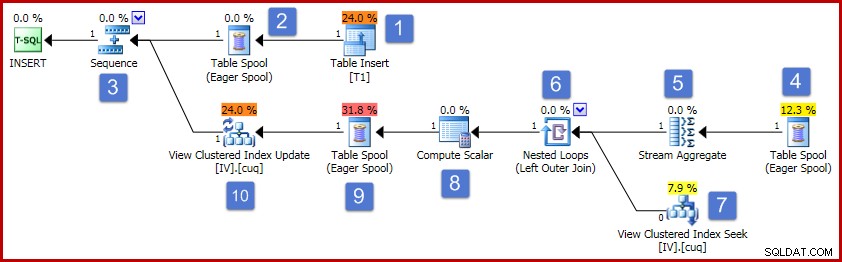
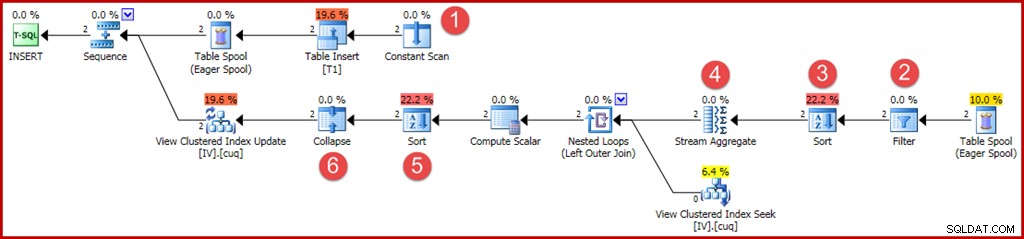
Nach den Nummern im Diagramm läuft die Operation dieses Ausführungsplans wie folgt ab:
- Der Table Insert-Operator fügt die neue Zeile zur Basistabelle hinzu. Dies ist der einzige Planoperator, der der Basistabelleneinfügung zugeordnet ist; alle übrigen Operatoren kümmern sich um die Pflege der indizierten Ansicht.
- Der Eager Table Spool speichert die eingefügten Zeilendaten im temporären Speicher.
- Der Sequence-Operator stellt sicher, dass der oberste Zweig des Plans vollständig ausgeführt wird, bevor der nächste Zweig in der Sequenz aktiviert wird. In diesem speziellen Fall (Einfügen einer einzelnen Zeile) wäre es gültig, die Sequenz (und die Spulen an den Positionen 2 und 4) zu entfernen und die Stream Aggregate-Eingabe direkt mit der Ausgabe der Tabelleneinfügung zu verbinden. Diese mögliche Optimierung wird nicht implementiert, daher bleiben Sequence und Spools.
- Dieser Eager-Tabellen-Spool ist dem Spool an Position 2 zugeordnet (er hat eine primäre Knoten-ID-Eigenschaft, die diesen Link explizit bereitstellt). Die Spule gibt Zeilen (im vorliegenden Fall eine Zeile) aus demselben temporären Speicher wieder, in den von der primären Spule geschrieben wurde. Wie oben erwähnt, sind die Spools und die Positionen 2 und 4 unnötig und nur deshalb vorhanden, weil sie in der generischen Vorlage für die Pflege der indizierten Ansicht vorhanden sind.
- Das Stream-Aggregat berechnet die Summe der Wertspaltendaten im eingefügten Satz und zählt die Anzahl der Zeilen, die pro Ansichtsschlüsselgruppe vorhanden sind. Die Ausgabe sind die inkrementellen Daten, die benötigt werden, um die Ansicht mit den Basisdaten synchron zu halten. Beachten Sie, dass Stream Aggregate kein Group By-Element hat, da der Abfrageoptimierer weiß, dass nur ein einziger Wert verarbeitet wird. Der Optimierer wendet jedoch keine ähnliche Logik an, um die Aggregate durch Projektionen zu ersetzen (die Summe eines einzelnen Werts ist nur der Wert selbst, und die Anzahl ist immer eins für eine einzelne Zeileneinfügung). Das Berechnen der Summen- und Anzahlaggregate für eine einzelne Datenzeile ist kein teurer Vorgang, daher ist diese verpasste Optimierung kein Grund zur Sorge.
- Der Join bezieht jede berechnete inkrementelle Änderung auf einen vorhandenen Schlüssel in der indizierten Ansicht. Der Join ist ein Outer Join, da die neu eingefügten Daten möglicherweise nicht mit vorhandenen Daten in der Ansicht übereinstimmen.
- Dieser Operator lokalisiert die zu ändernde Zeile in der Ansicht.
- Der Rechenskalar hat zwei wichtige Aufgaben. Zunächst wird bestimmt, ob sich jede inkrementelle Änderung auf eine vorhandene Zeile in der Ansicht auswirkt oder ob eine neue Zeile erstellt werden muss. Dies geschieht, indem überprüft wird, ob der Outer-Join auf der Ansichtsseite des Joins eine Null erzeugt hat. Unser Beispieleinsatz ist für Gruppe 3, die derzeit nicht in der Ansicht vorhanden ist, daher wird eine neue Zeile erstellt. Die zweite Funktion des Berechnungsskalars besteht darin, neue Werte für die Ansichtsspalten zu berechnen. Wenn der Ansicht eine neue Zeile hinzugefügt werden soll, ist dies einfach das Ergebnis der inkrementellen Summe aus dem Stream Aggregate. Wenn eine vorhandene Zeile in der Ansicht aktualisiert werden soll, ist der neue Wert der vorhandene Wert in der Ansichtszeile plus die inkrementelle Summe aus dem Stream-Aggregat.
- Diese eifrige Tischspule dient als Halloween-Schutz. Es ist aus Gründen der Korrektheit erforderlich, wenn sich eine Einfügeoperation auf eine Tabelle auswirkt, auf die auch auf der Datenzugriffsseite der Abfrage verwiesen wird. Es ist technisch nicht erforderlich, wenn der Einzelzeilen-Wartungsvorgang zu einer Aktualisierung einer vorhandenen Ansichtszeile führt, aber es bleibt trotzdem im Plan.
- Der letzte Operator im Plan ist als Update-Operator gekennzeichnet, führt jedoch entweder eine Einfügung oder eine Aktualisierung für jede empfangene Zeile aus, abhängig vom Wert der Spalte "Aktionscode", die vom Berechnungsskalar an Knoten 8 hinzugefügt wurde Allgemeiner kann dieser Aktualisierungsoperator Einfügungen, Aktualisierungen und Löschungen ausführen.
Es gibt dort ziemlich viele Details, also zusammenfassend:
- Die aggregierten Gruppendaten ändern sich durch den eindeutigen gruppierten Schlüssel der Ansicht. Es berechnet die Nettoauswirkung der Basistabellenänderungen auf jede Spalte pro Schlüssel.
- Der äußere Join verbindet die inkrementellen Änderungen pro Schlüssel mit bestehenden Zeilen in der Ansicht.
- Der Compute-Skalar berechnet, ob der Ansicht eine neue Zeile hinzugefügt oder eine vorhandene Zeile aktualisiert werden soll. Es berechnet die endgültigen Spaltenwerte für den Einfüge- oder Aktualisierungsvorgang der Ansicht.
- Der View-Update-Operator fügt eine neue Zeile ein oder aktualisiert eine vorhandene, wie vom Aktionscode vorgegeben.
Beispiel 2 – Mehrzeilige Einfügung
Ob Sie es glauben oder nicht, der oben besprochene Ausführungsplan für die Einfügung einer einzeiligen Basistabelle wurde einer Reihe von Vereinfachungen unterzogen. Obwohl einige mögliche weitere Optimierungen übersehen wurden (wie angemerkt), gelang es dem Abfrageoptimierer dennoch, einige Operationen aus der allgemeinen Wartungsvorlage für indizierte Ansichten zu entfernen und die Komplexität anderer zu reduzieren.
Einige dieser Optimierungen waren zulässig, weil wir nur eine einzelne Zeile eingefügt haben, aber andere wurden aktiviert, weil der Optimierer sehen konnte, dass die Literalwerte der Basistabelle hinzugefügt wurden. Beispielsweise könnte der Optimierer erkennen, dass der eingefügte Gruppenwert das Prädikat in der WHERE-Klausel der Ansicht passieren würde.
Wenn wir nun zwei Zeilen einfügen, deren Werte in lokalen Variablen "versteckt" sind, erhalten wir einen etwas komplexeren Plan:
DECLARE
@Group1 integer = 4,
@Value1 integer = 7,
@Group2 integer = 5,
@Value2 integer = 8;
INSERT dbo.T1
(GroupID, Value)
VALUES
(@Group1, @Value1),
(@Group2, @Value2);
Die neuen bzw. geänderten Operatoren sind wie bisher gekennzeichnet:
- Der Constant Scan liefert die einzufügenden Werte. Bisher erlaubte eine Optimierung für einzeilige Einfügungen das Weglassen dieses Operators.
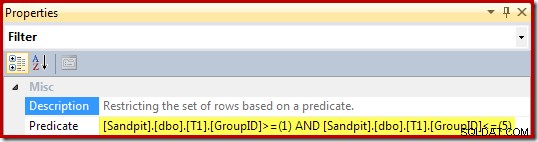
- Ein expliziter Filteroperator ist jetzt erforderlich, um zu prüfen, ob die in die Basistabelle eingefügten Gruppen mit der WHERE-Klausel in der Ansicht übereinstimmen. Zufällig werden beide neuen Zeilen den Test bestehen, aber der Optimierer kann die Werte in den Variablen nicht sehen, um dies im Voraus zu wissen. Darüber hinaus wäre es nicht sicher, einen Plan zwischenzuspeichern, der diesen Filter übersprungen hat, da eine zukünftige Wiederverwendung des Plans andere Werte in den Variablen haben könnte.
- Eine Sortierung ist jetzt erforderlich, um sicherzustellen, dass die Zeilen in Gruppenreihenfolge beim Stream-Aggregat ankommen. Die Sortierung wurde zuvor entfernt, weil es sinnlos ist, eine Zeile zu sortieren.
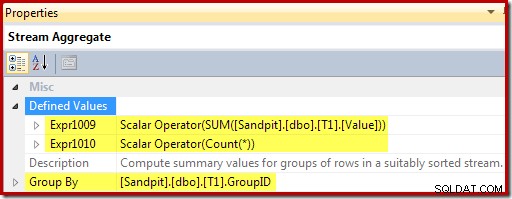
- Das Stream-Aggregat hat jetzt eine "Gruppieren nach"-Eigenschaft, die mit dem eindeutigen gruppierten Schlüssel der Ansicht übereinstimmt.
- Diese Sortierung ist erforderlich, um Zeilen in der Reihenfolge von Ansichtsschlüsseln und Aktionscodes darzustellen, was für den korrekten Betrieb des Collapse-Operators erforderlich ist. Sort ist ein vollständig blockierender Operator, sodass für den Halloween-Schutz keine Eager Table Spool mehr erforderlich ist.
- Der neue Collapse-Operator kombiniert ein benachbartes Einfügen und Löschen für denselben Schlüsselwert in einem einzigen Aktualisierungsvorgang. Dieser Operator ist eigentlich nicht erforderlich in diesem Fall, da keine Löschaktionscodes generiert werden können (nur Einfügungen und Aktualisierungen). Dies scheint ein Versehen zu sein, oder vielleicht etwas, das aus Sicherheitsgründen gelassen wurde. Die automatisch generierten Teile eines Aktualisierungsabfrageplans können extrem komplex werden, daher ist dies schwer genau zu wissen.
Die Eigenschaften des Filters (abgeleitet von der WHERE-Klausel der Ansicht) sind:
Das Stream-Aggregat gruppiert nach Ansichtsschlüssel und berechnet die Summe und Anzahl der Aggregate pro Gruppe:
Der Berechnungsskalar identifiziert die pro Zeile durchzuführende Aktion (in diesem Fall Einfügen oder Aktualisieren) und berechnet den Wert, der in die Ansicht eingefügt oder aktualisiert werden soll:
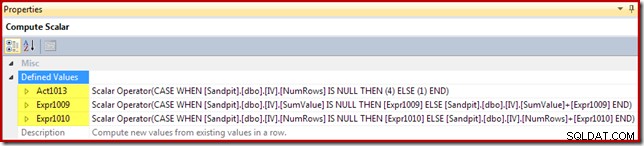
Dem Aktionscode wird ein Ausdruckslabel von [Act1xxx] gegeben. Gültige Werte sind 1 für eine Aktualisierung, 3 für eine Löschung und 4 für eine Einfügung. Dieser Aktionsausdruck führt zu einer Einfügung (Code 4), wenn keine übereinstimmende Zeile in der Ansicht gefunden wurde (d. h. der äußere Join hat eine Null für die Spalte NumRows zurückgegeben). Wenn eine übereinstimmende Zeile gefunden wurde, ist der Aktionscode 1 (aktualisieren).
Beachten Sie, dass NumRows der Name ist, der der erforderlichen COUNT_BIG(*)-Spalte in der Ansicht gegeben wird. In einem Plan, der zu Löschungen aus der Ansicht führen könnte, würde der Compute-Skalar erkennen, wann dieser Wert Null werden würde (keine Zeilen für die aktuelle Gruppe) und einen Löschaktionscode (3) generieren.
Die verbleibenden Ausdrücke behalten die sum- und count-Aggregate in der Ansicht bei. Beachten Sie jedoch, dass die Ausdrucksbezeichnungen [Ausdr1009] und [Ausdr1010] nicht neu sind; Sie beziehen sich auf die vom Stream Aggregate erstellten Labels. Die Logik ist einfach:Wenn keine übereinstimmende Zeile gefunden wurde, ist der einzufügende neue Wert nur der Wert, der im Aggregat berechnet wurde. Wenn eine übereinstimmende Zeile in der Ansicht gefunden wurde, ist der aktualisierte Wert der aktuelle Wert in der Zeile plus das vom Aggregat berechnete Inkrement.
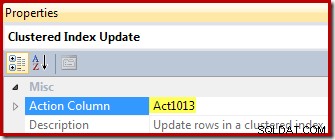
Schließlich zeigt der View-Update-Operator (in SSMS als Clustered-Index-Update dargestellt) die Aktionsspaltenreferenz ([Act1013] definiert durch den Compute-Skalar):
Beispiel 3 – Mehrzeilige Aktualisierung
Bisher haben wir uns nur Einsätze zum Grundtisch angesehen. Die Ausführungspläne für eine Löschung sind sehr ähnlich, mit nur wenigen geringfügigen Unterschieden in den detaillierten Berechnungen. Dieses nächste Beispiel geht daher weiter, um den Wartungsplan für eine Basistabellenaktualisierung zu betrachten:
DECLARE
@Group1 integer = 1,
@Group2 integer = 2,
@Value integer = 1;
UPDATE dbo.T1
SET Value = Value + @Value
WHERE GroupID IN (@Group1, @Group2); Wie zuvor verwendet diese Abfrage Variablen, um Literalwerte vor dem Optimierer zu verbergen, wodurch verhindert wird, dass einige Vereinfachungen angewendet werden. Es wird auch darauf geachtet, zwei separate Gruppen zu aktualisieren, um Optimierungen zu verhindern, die angewendet werden können, wenn der Optimierer weiß, dass nur eine einzelne Gruppe (eine einzelne Zeile der indizierten Ansicht) betroffen ist. Der kommentierte Ausführungsplan für die Aktualisierungsabfrage ist unten:
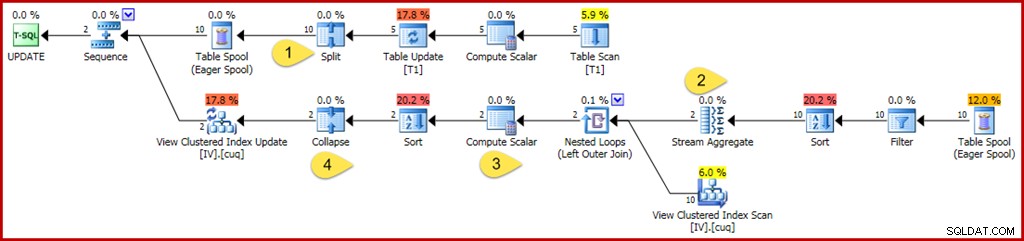
Die Änderungen und interessanten Punkte sind:
- Der neue Split-Operator verwandelt jede Zeilenaktualisierung der Basistabelle in einen separaten Lösch- und Einfügevorgang. Jede Aktualisierungszeile wird in zwei separate Zeilen aufgeteilt, wodurch sich die Anzahl der Zeilen nach diesem Punkt im Plan verdoppelt. Split ist Teil des Split-Sort-Collapse-Musters, das zum Schutz vor fehlerhaften vorübergehenden Fehlern aufgrund einer eindeutigen Schlüsselverletzung erforderlich ist.
- Das Stream-Aggregat wird modifiziert, um eingehende Zeilen zu berücksichtigen, die entweder eine Löschung oder eine Einfügung angeben können (aufgrund der Teilung und bestimmt durch eine Aktionscode-Spalte in der Zeile). Eine Einfügungszeile trägt den ursprünglichen Wert in Summenaggregaten bei; bei Löschaktionszeilen ist das Vorzeichen umgekehrt. In ähnlicher Weise zählt das Aggregat für die Zeilenanzahl hier eingefügte Zeilen als +1 und gelöschte Zeilen als –1.
- Die Compute Scalar-Logik wurde ebenfalls modifiziert, um widerzuspiegeln, dass der Nettoeffekt der Änderungen pro Gruppe eventuell eine Einfüge-, Aktualisierungs- oder Löschaktion für die materialisierte Ansicht erfordern könnte. Es ist eigentlich nicht möglich, dass diese spezielle Aktualisierungsabfrage dazu führt, dass eine Zeile in dieser Ansicht eingefügt oder gelöscht wird, aber die Logik, die erforderlich ist, um dies abzuleiten, übersteigt die derzeitigen Denkfähigkeiten des Optimierers. Eine etwas andere Aktualisierungsabfrage oder Ansichtsdefinition könnte tatsächlich zu einer Mischung aus Einfüge-, Lösch- und Ansichtsaktualisierungsaktionen führen.
- Der Collapse-Operator wird nur wegen seiner Rolle im oben erwähnten Split-Sort-Collapse-Muster hervorgehoben. Beachten Sie, dass es nur Löschungen und Einfügungen auf derselben Taste reduziert; unübertroffene Löschungen und Einfügungen nach dem Zusammenbruch sind durchaus möglich (und durchaus üblich).
Wie zuvor sind die wichtigsten Operatoreigenschaften, die Sie sich ansehen sollten, um die Wartungsarbeiten für indizierte Ansichten zu verstehen, Filter, Stream Aggregate, Outer Join und Compute Scalar.
Beispiel 4 – Mehrzeilige Aktualisierung mit Joins
Um die Übersicht über die Ausführungspläne für die Wartung indizierter Ansichten zu vervollständigen, benötigen wir eine neue Beispielansicht, die mehrere Tabellen miteinander verbindet und eine Projektion in die Auswahlliste einbezieht:
CREATE TABLE dbo.E1 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E2 (g integer NULL, a integer NULL);
CREATE TABLE dbo.E3 (g integer NULL, a integer NULL);
GO
INSERT dbo.E1 (g, a) VALUES (1, 1);
INSERT dbo.E2 (g, a) VALUES (1, 1);
INSERT dbo.E3 (g, a) VALUES (1, 1);
GO
CREATE VIEW dbo.V1
WITH SCHEMABINDING
AS
SELECT
g = E1.g,
sa1 = SUM(ISNULL(E1.a, 0)),
sa2 = SUM(ISNULL(E2.a, 0)),
sa3 = SUM(ISNULL(E3.a, 0)),
cbs = COUNT_BIG(*)
FROM dbo.E1 AS E1
JOIN dbo.E2 AS E2
ON E2.g = E1.g
JOIN dbo.E3 AS E3
ON E3.g = E2.g
WHERE
E1.g BETWEEN 1 AND 5
GROUP BY
E1.g;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.V1 (g); Um die Korrektheit sicherzustellen, besteht eine der Anforderungen für indizierte Sichten darin, dass ein Summenaggregat nicht mit einem Ausdruck arbeiten kann, der als Null ausgewertet werden könnte. Die obige Ansichtsdefinition verwendet ISNULL, um diese Anforderung zu erfüllen. Eine beispielhafte Aktualisierungsabfrage, die eine ziemlich umfassende Komponente des Indexwartungsplans erzeugt, wird unten zusammen mit dem Ausführungsplan gezeigt, den sie erzeugt:
UPDATE dbo.E1
SET g = g + 1,
a = a + 1;
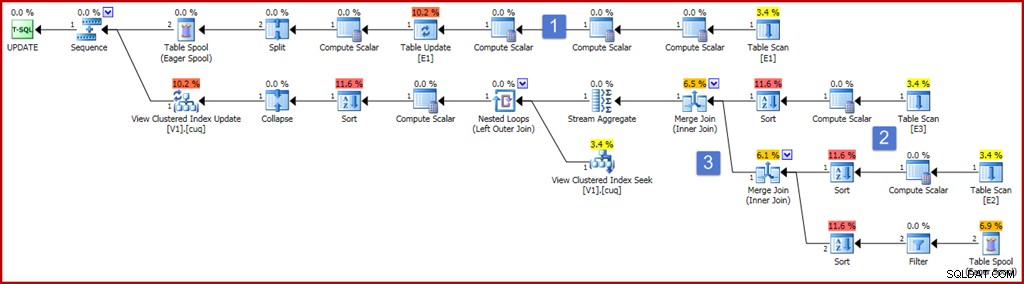
Der Plan sieht jetzt ziemlich groß und kompliziert aus, aber die meisten Elemente sind genau so, wie wir es bereits gesehen haben. Die Hauptunterschiede sind:
- Der oberste Zweig des Plans enthält eine Reihe zusätzlicher Compute Scalar-Operatoren. Diese könnten kompakter angeordnet sein, aber im Wesentlichen sind sie vorhanden, um die Voraktualisierungswerte der Nicht-Gruppierungsspalten zu erfassen. Der Berechnungsskalar links neben der Tabellenaktualisierung erfasst den Post-Update-Wert von Spalte „a“, wobei die ISNULL-Projektion angewendet wird.
- Die neuen Berechnungsskalare in diesem Bereich des Plans berechnen den Wert, der durch den ISNULL-Ausdruck für jede Quelltabelle erzeugt wird. Im Allgemeinen werden Projektionen auf die verknüpften Tabellen in der Ansicht hier durch Compute Scalars dargestellt. Die Sortierungen in diesem Bereich des Plans sind nur deshalb vorhanden, weil der Optimierer aus Kostengründen eine Merge-Join-Strategie gewählt hat (denken Sie daran, dass Merge eine sortierte Eingabe nach Join-Schlüssel erfordert).
- Die beiden Join-Operatoren sind neu und implementieren einfach die Joins in der Ansichtsdefinition. Diese Verknüpfungen werden immer vor dem Stream-Aggregat angezeigt, das die inkrementelle Auswirkung der Änderungen auf die Ansicht berechnet. Beachten Sie, dass eine Änderung an einer Basistabelle dazu führen kann, dass eine Zeile, die zuvor die Join-Kriterien erfüllte, nicht mehr verknüpft wird und umgekehrt. Alle diese potenziellen Komplexitäten werden korrekt gehandhabt (angesichts der indizierten Ansichtsbeschränkungen), indem das Stream-Aggregat eine Zusammenfassung der Änderungen pro Ansichtsschlüssel erstellt, nachdem die Joins durchgeführt wurden.
Abschließende Gedanken
Dieser letzte Plan stellt so ziemlich die vollständige Vorlage zum Verwalten einer indizierten Ansicht dar, obwohl das Hinzufügen von nicht gruppierten Indizes zu der Ansicht zusätzliche Operatoren hinzufügen würde, die auch aus der Ausgabe des Ansichtsaktualisierungsoperators gespoolt werden. Abgesehen von einem zusätzlichen Teilen (und einer Kombination aus Sortieren und Reduzieren, wenn der nicht gruppierte Index der Ansicht eindeutig ist) gibt es an dieser Möglichkeit nichts Besonderes. Das Hinzufügen einer Ausgabeklausel zur Basistabellenabfrage kann auch zu einigen interessanten zusätzlichen Operatoren führen, aber auch diese beziehen sich nicht auf die Wartung der indizierten Ansicht per se.
Um die vollständige Gesamtstrategie zusammenzufassen:
- Basistabellenänderungen werden wie gewohnt angewendet; Pre-Update-Werte können erfasst werden.
- Ein Split-Operator kann verwendet werden, um Aktualisierungen in Lösch-/Einfügepaare umzuwandeln.
- Ein Eifer-Spool speichert Änderungsinformationen der Basistabelle in einem temporären Speicher.
- Auf alle Tabellen in der Ansicht wird zugegriffen, mit Ausnahme der aktualisierten Basistabelle (die aus der Spule gelesen wird).
- Projektionen in der Ansicht werden durch Berechnungsskalare dargestellt.
- Filter in der Ansicht werden angewendet. Filter können als Residuen in Scans oder Suchen geschoben werden.
- In der Ansicht angegebene Verknüpfungen werden ausgeführt.
- Ein Aggregat berechnet inkrementelle Nettoänderungen gruppiert nach gruppiertem Ansichtsschlüssel.
- Der inkrementelle Änderungssatz ist mit der Ansicht über eine äußere Verbindung verbunden.
- Ein Rechenskalar berechnet einen Aktionscode (Einfügen/Aktualisieren/Löschen für die Ansicht) für jede Änderung und berechnet die einzufügenden oder zu aktualisierenden tatsächlichen Werte. Die Berechnungslogik basiert auf der Ausgabe des Aggregats und dem Ergebnis des äußeren Joins zur Ansicht.
- Änderungen werden nach Ansichtsschlüssel und Aktionscode sortiert und gegebenenfalls zu Aktualisierungen reduziert.
- Schließlich werden die inkrementellen Änderungen auf die Ansicht selbst angewendet.
Wie wir gesehen haben, werden die normalen Tools, die dem Abfrageoptimierer zur Verfügung stehen, immer noch auf die automatisch generierten Teile des Plans angewendet, was bedeutet, dass einer oder mehrere der oben genannten Schritte vereinfacht, transformiert oder vollständig entfernt werden können. Die grundlegende Form und Funktionsweise des Plans bleibt jedoch intakt.
Wenn Sie die Codebeispiele mitverfolgt haben, können Sie das folgende Skript zum Aufräumen verwenden:
DROP VIEW dbo.V1; DROP TABLE dbo.E3, dbo.E2, dbo.E1; DROP VIEW dbo.IV; DROP TABLE dbo.T1;