Abweichend von meiner Reihe „Knieruck-Performance-Tuning“ möchte ich erörtern, wie sich unter Umständen eine Indexfragmentierung einschleichen kann.
Was ist Indexfragmentierung?
Die meisten Leute denken bei „Indexfragmentierung“ an das Problem, bei dem die Indexblattseiten nicht in der richtigen Reihenfolge sind – die Indexblattseite mit dem nächsten Schlüsselwert ist nicht diejenige, die in der Datendatei physisch an die gerade untersuchte Indexblattseite angrenzt . Dies wird als logische Fragmentierung bezeichnet (und einige Leute bezeichnen es als externe Fragmentierung – ein verwirrender Begriff, den ich nicht mag).
Eine logische Fragmentierung tritt auf, wenn eine Indexblattseite voll ist und Platz darauf benötigt wird, entweder für eine Einfügung oder um einen vorhandenen Datensatz länger zu machen (durch Aktualisieren einer Spalte mit variabler Länge). In diesem Fall erstellt die Storage Engine eine neue, leere Seite und verschiebt 50 % der Zeilen (normalerweise, aber nicht immer) von der vollständigen Seite auf die neue Seite. Dieser Vorgang schafft Platz auf beiden Seiten, sodass das Einfügen oder Aktualisieren fortgesetzt werden kann, und wird als Seitenteilung bezeichnet. Es gibt interessante pathologische Fälle mit wiederholten Seitenteilungen aus einer einzigen Operation und Seitenteilungen, die die Indexebenen nach oben kaskadieren, aber sie würden den Rahmen dieses Beitrags sprengen.
Wenn eine Seite geteilt wird, führt dies normalerweise zu einer logischen Fragmentierung, da es höchst unwahrscheinlich ist, dass die neu zugewiesene Seite physisch mit der geteilten Seite zusammenhängt. Wenn ein Index eine starke logische Fragmentierung aufweist, werden Index-Scans verlangsamt, da die physischen Lesevorgänge der erforderlichen Seiten nicht so effizient durchgeführt werden können (unter Verwendung von Readahead-Lesevorgängen für mehrere Seiten), wenn die Blattseiten nicht der Reihe nach in der Datendatei gespeichert sind .
Das ist die grundlegende Definition der Indexfragmentierung, aber es gibt eine zweite Art der Indexfragmentierung, die die meisten Leute nicht in Betracht ziehen:niedrige Seitendichte (manchmal interne Fragmentierung genannt, wiederum ein verwirrender Begriff, den ich nicht mag).
Die Seitendichte ist ein Maß dafür, wie viele Daten auf einer Indexblattseite gespeichert sind. Wenn eine Seitenteilung mit dem üblichen 50/50-Fall auftritt, wird jede Blattseite (die Teilungsseite und die neue) mit einer Seitendichte von nur 50 % belassen. Je niedriger die Seitendichte, desto mehr leerer Speicherplatz ist im Index vorhanden und desto mehr Festplattenspeicher und Pufferpoolspeicher können Sie als verschwendet betrachten. Ich habe vor ein paar Jahren über dieses Problem gebloggt und Sie können es hier nachlesen.
Nachdem ich nun eine grundlegende Definition der beiden Arten der Indexfragmentierung gegeben habe, werde ich sie zusammenfassend einfach als „Fragmentierung“ bezeichnen.
Für den Rest dieses Beitrags möchte ich drei Fälle diskutieren, in denen Clustered-Indizes fragmentiert werden können, selbst wenn Sie Operationen vermeiden, die offensichtlich eine Fragmentierung verursachen würden (d. h. zufällige Einfügungen und längere Aktualisierungsdatensätze).
Fragmentierung durch Löschungen
„Wie kann ein Löschvorgang von einer Clustered-Index-Blattseite zu einer Seitenteilung führen?“ fragen Sie vielleicht. Unter normalen Umständen wird es das nicht (und ich saß ein paar Minuten da und dachte darüber nach, um sicherzugehen, dass es nicht irgendeinen seltsamen pathologischen Fall gab! Aber siehe Abschnitt unten …) Allerdings können Löschungen dazu führen, dass die Seitendichte zunehmend geringer wird.
Stellen Sie sich den Fall vor, in dem der gruppierte Index einen Bigint-Identitätsschlüsselwert hat, sodass Einfügungen immer auf der rechten Seite des Indexes erscheinen und niemals in einen früheren Teil des Indexes eingefügt werden (es sei denn, jemand setzt den Identitätswert neu – potenziell sehr problematisch!). Stellen Sie sich nun vor, dass die Workload Datensätze aus der Tabelle löscht, die nicht mehr benötigt werden, woraufhin die Geisterbereinigungsaufgabe im Hintergrund den Speicherplatz auf der Seite zurückfordert und zu freiem Speicherplatz wird.
Ohne zufällige Einfügungen (in unserem Szenario unmöglich, es sei denn, jemand setzt die Identität neu oder gibt einen zu verwendenden Schlüsselwert an, nachdem SET IDENTITY INSERT für die Tabelle aktiviert wurde), werden keine neuen Datensätze jemals den Speicherplatz verwenden, der von den gelöschten Datensätzen freigegeben wurde. Dies bedeutet, dass die durchschnittliche Seitendichte der früheren Teile des Clustered-Index stetig abnimmt, was zu einer zunehmenden Verschwendung von Festplattenspeicher und Pufferpoolspeicher führt, wie ich zuvor beschrieben habe.
Löschungen können eine Fragmentierung verursachen, solange Sie die Seitendichte als Teil der „Fragmentierung“ betrachten.
Fragmentierung durch Snapshot-Isolation
In SQL Server 2005 wurden zwei neue Isolationsstufen eingeführt:Snapshot-Isolation und Snapshot-Isolation mit Lesebestätigung. Diese beiden haben eine leicht unterschiedliche Semantik, ermöglichen aber im Grunde Abfragen, um eine Point-in-Time-Ansicht einer Datenbank anzuzeigen, und um Sperrkollisions-freie Auswahlen zu ermöglichen. Das ist eine enorme Vereinfachung, aber für meine Zwecke reicht es aus.
Um diese Isolationsstufen zu erleichtern, hat das von mir geleitete Entwicklungsteam bei Microsoft einen Mechanismus namens Versionierung implementiert. Die Versionsverwaltung funktioniert so, dass immer dann, wenn sich ein Datensatz ändert, die Version vor der Änderung des Datensatzes in den Versionsspeicher in tempdb kopiert wird und am Ende des geänderten Datensatzes ein 14-Byte-Versionierungs-Tag hinzugefügt wird. Das Tag enthält einen Zeiger auf die vorherige Version des Datensatzes sowie einen Zeitstempel, der verwendet werden kann, um zu bestimmen, welche die richtige Version eines Datensatzes für eine bestimmte zu lesende Abfrage ist. Wieder stark vereinfacht, aber uns interessiert nur die Hinzufügung der 14 Byte.
Wenn sich also ein Datensatz ändert, wenn eine dieser Isolationsstufen in Kraft ist, kann er um 14 Byte erweitert werden, wenn nicht bereits ein Versionierungs-Tag für den Datensatz vorhanden ist. Was ist, wenn auf der Indexblattseite nicht genügend Platz für die zusätzlichen 14 Bytes vorhanden ist? Richtig, es kommt zu einer Seitenteilung, die zu einer Fragmentierung führt.
Eine große Sache, könnten Sie denken, da sich der Datensatz sowieso ändert. Wenn sich also die Größe sowieso ändern würde, wäre wahrscheinlich eine Seitenteilung aufgetreten. Nein – diese Logik gilt nur, wenn die Datensatzänderung die Größe einer Spalte mit variabler Länge erhöhen sollte. Ein Versionierungs-Tag wird hinzugefügt, selbst wenn eine Spalte mit fester Länge aktualisiert wird!
Das ist richtig – wenn Versionierung im Spiel ist, können Aktualisierungen von Spalten mit fester Länge dazu führen, dass ein Datensatz erweitert wird, was möglicherweise zu einer Seitenteilung und Fragmentierung führt. Noch interessanter ist, dass ein Löschvorgang auch das 14-Byte-Tag hinzufügt, sodass ein Löschvorgang in einem Clustered-Index zu einer Seitenteilung führen kann, wenn Versionierung verwendet wird!
Das Fazit hier ist, dass die Aktivierung einer der beiden Formen der Snapshot-Isolation dazu führen kann, dass plötzlich eine Fragmentierung in Clustered-Indizes auftritt, wo zuvor keine Möglichkeit der Fragmentierung bestand.
Fragmentierung von lesbaren Secondaries
Der letzte Fall, den ich erörtern möchte, ist die Verwendung von lesbaren sekundären Datenbanken, die Teil der Verfügbarkeitsgruppenfunktion sind, die in SQL Server 2012 hinzugefügt wurde.
Wenn Sie ein lesbares sekundäres Replikat aktivieren, werden alle Abfragen, die Sie für das sekundäre Replikat durchführen, in die verdeckte Verwendung von Snapshot-Isolierung umgewandelt. Dadurch wird verhindert, dass die Abfragen die ständige Wiedergabe von Protokolldatensätzen vom primären Replikat blockieren, da der Wiederherstellungscode im Laufe der Zeit Sperren erwirbt.
Dazu müssen 14-Byte-Versionierungstags für Datensätze auf dem sekundären Replikat vorhanden sein. Es gibt ein Problem, weil alle Replikate identisch sein müssen, damit die Protokollwiedergabe funktioniert. Nicht ganz. Der Inhalt des Versionierungs-Tags ist nicht relevant, da er nur auf der Instanz verwendet wird, die ihn erstellt hat. Das sekundäre Replikat kann jedoch keine Versionierungs-Tags hinzufügen, wodurch die Datensätze länger werden, da dies das physische Layout der Datensätze auf einer Seite ändern und die Protokollwiedergabe unterbrechen würde. Wenn die Versionierungs-Tags jedoch bereits vorhanden wären, könnte es das Leerzeichen verwenden, ohne etwas zu beschädigen.
Also genau das passiert. Die Speicher-Engine stellt sicher, dass alle erforderlichen Versionierungs-Tags für das sekundäre Replikat bereits vorhanden sind, indem sie zum primären Replikat hinzugefügt werden!
Sobald eine lesbare sekundäre Replik einer Datenbank erstellt wird, führt jede Aktualisierung eines Datensatzes in der primären Replik dazu, dass dem Datensatz ein leeres 14-Byte-Tag hinzugefügt wird, sodass die 14-Byte in allen Protokolldatensätzen ordnungsgemäß berücksichtigt werden . Das Tag wird für nichts verwendet (es sei denn, die Snapshot-Isolation ist auf dem primären Replikat selbst aktiviert), aber die Tatsache, dass es erstellt wird, führt dazu, dass der Datensatz erweitert wird, und wenn die Seite bereits voll ist, dann …
Ja, das Aktivieren eines lesbaren sekundären Replikats hat die gleiche Auswirkung auf das primäre Replikat, als ob Sie die Snapshot-Isolation darauf aktiviert hätten – Fragmentierung.
Zusammenfassung
Denken Sie nicht, dass Ihre Clustered-Indizes immun gegen Fragmentierung sind, weil Sie die Verwendung von GUIDs als Cluster-Schlüssel und die Aktualisierung von Spalten mit variabler Länge in Ihren Tabellen vermeiden. Wie ich oben beschrieben habe, gibt es andere Workload- und Umgebungsfaktoren, die Fragmentierungsprobleme in Ihren Clustered-Indizes verursachen können, die Sie beachten müssen.
Machen Sie jetzt keinen Reflex und denken Sie, Sie sollten keine Datensätze löschen, keine Snapshot-Isolation verwenden und keine lesbaren Secondaries verwenden. Sie müssen sich nur darüber im Klaren sein, dass sie alle eine Fragmentierung verursachen können, und wissen, wie man sie erkennt, entfernt und mindert.
SQL Sentry verfügt über ein cooles Tool, Fragmentation Manager, das Sie als Add-on zu Performance Advisor verwenden können, um herauszufinden, wo Fragmentierungsprobleme liegen, und diese dann zu beheben. Sie werden überrascht sein über die Fragmentierung, die Sie beim Überprüfen finden! Als kurzes Beispiel kann ich hier visuell sehen – bis auf die Ebene der einzelnen Partitionen – wie viel Fragmentierung vorhanden ist, wie schnell sie so wurde, welche Muster vorhanden sind und welche tatsächlichen Auswirkungen sie auf den verschwendeten Speicher im System hat:
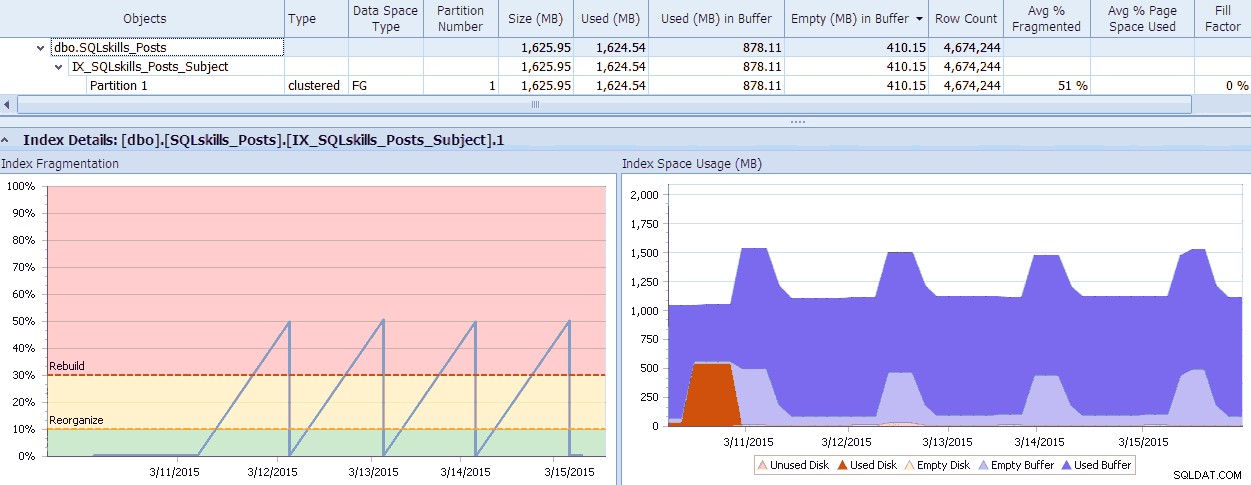 SQL Sentry Fragmentation Manager-Daten (zum Vergrößern klicken)
SQL Sentry Fragmentation Manager-Daten (zum Vergrößern klicken)
In meinem nächsten Beitrag werde ich mehr über Fragmentierung und deren Minderung diskutieren, um sie weniger problematisch zu machen.



