In meinem letzten Beitrag habe ich demonstriert, dass ein speicheroptimierter TVP bei kleinen Volumina erhebliche Leistungsvorteile für typische Abfragemuster liefern kann.
Zum Testen in etwas höherem Maßstab habe ich eine Kopie von SalesOrderDetailEnlarged erstellt Tabelle, die ich dank dieses Skripts von Jonathan Kehayias (Blog | @SQLPoolBoy) auf ungefähr 5.000.000 Zeilen erweitert hatte).
DROP TABLE dbo.SalesOrderDetailEnlarged; GO SELECT * INTO dbo.SalesOrderDetailEnlarged FROM AdventureWorks2012.Sales.SalesOrderDetailEnlarged; -- 4,973,997 rows CREATE CLUSTERED INDEX PK_SODE ON dbo.SalesOrderDetailEnlarged(SalesOrderID, SalesOrderDetailID);
Ich habe auch drei In-Memory-Versionen dieser Tabelle erstellt, jede mit einer anderen Bucket-Anzahl (Fischen nach einem „Sweet Spot“) – 16.384, 131.072 und 1.048.576. (Sie können runde Zahlen verwenden, aber sie werden trotzdem auf die nächste Zweierpotenz aufgerundet.) Beispiel:
CREATE TABLE [dbo].[SalesOrderDetailEnlarged_InMem_16K] -- and _131K and _1MM ( [SalesOrderID] [int] NOT NULL, [SalesOrderDetailID] [int] NOT NULL, [CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL, [OrderQty] [smallint] NOT NULL, [ProductID] [int] NOT NULL, [SpecialOfferID] [int] NOT NULL, [UnitPrice] [money] NOT NULL, [UnitPriceDiscount] [money] NOT NULL, [LineTotal] [numeric](38, 6) NOT NULL, [rowguid] [uniqueidentifier] NOT NULL, [ModifiedDate] [datetime] NOT NULL PRIMARY KEY NONCLUSTERED HASH ( [SalesOrderID], [SalesOrderDetailID] ) WITH ( BUCKET_COUNT = 16384) -- and 131072 and 1048576 ) WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA ); GO INSERT dbo.SalesOrderDetailEnlarged_InMem_16K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_131K SELECT * FROM dbo.SalesOrderDetailEnlarged; INSERT dbo.SalesOrderDetailEnlarged_InMem_1MM SELECT * FROM dbo.SalesOrderDetailEnlarged; GO
Beachten Sie, dass ich die Bucket-Größe gegenüber dem vorherigen Beispiel (256) geändert habe. Beim Erstellen der Tabelle möchten Sie den „Sweet Spot“ für die Bucket-Größe auswählen – Sie möchten den Hash-Index für Punktsuchen optimieren, was bedeutet, dass Sie so viele Buckets wie möglich mit so wenig Zeilen wie möglich in jedem Bucket haben möchten. Wenn Sie ~5 Millionen Buckets erstellen (da es in diesem Fall vielleicht kein sehr gutes Beispiel gibt, gibt es ~5 Millionen eindeutige Kombinationen von Werten), müssen Sie sich natürlich mit einigen Kompromissen bei der Speichernutzung und der Garbage-Collection auseinandersetzen. Wenn Sie jedoch versuchen, ~5 Millionen eindeutige Werte in 256 Buckets zu stopfen, werden Sie auch auf einige Probleme stoßen. Jedenfalls geht diese Diskussion weit über den Rahmen meiner Tests für diesen Beitrag hinaus.
Um gegen die Standardtabelle zu testen, habe ich ähnliche gespeicherte Prozeduren wie in den vorherigen Tests erstellt:
CREATE PROCEDURE dbo.SODE_InMemory
@InMemory dbo.InMemoryTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @InMemory AS t
WHERE sode.SalesOrderID = t.Item);
END
GO
CREATE PROCEDURE dbo.SODE_Classic
@Classic dbo.ClassicTVP READONLY
AS
BEGIN
SET NOCOUNT ON;
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged AS sode
WHERE EXISTS (SELECT 1 FROM @Classic AS t
WHERE sode.SalesOrderID = t.Item);
END
GO Schauen wir uns also zuerst die Pläne für beispielsweise 1.000 Zeilen an, die in die Tabellenvariablen eingefügt werden, und führen dann die Prozeduren aus:
DECLARE @InMemory dbo.InMemoryTVP; INSERT @InMemory SELECT TOP (1000) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); DECLARE @Classic dbo.ClassicTVP; INSERT @Classic SELECT Item FROM @InMemory; EXEC dbo.SODE_Classic @Classic = @Classic; EXEC dbo.SODE_InMemory @InMemory = @InMemory;
Dieses Mal sehen wir, dass der Optimierer in beiden Fällen eine Clustered-Index-Suche gegen die Basistabelle und einen Join mit verschachtelten Schleifen gegen den TVP gewählt hat. Einige Kostenmetriken sind unterschiedlich, aber ansonsten sind die Pläne ziemlich ähnlich:
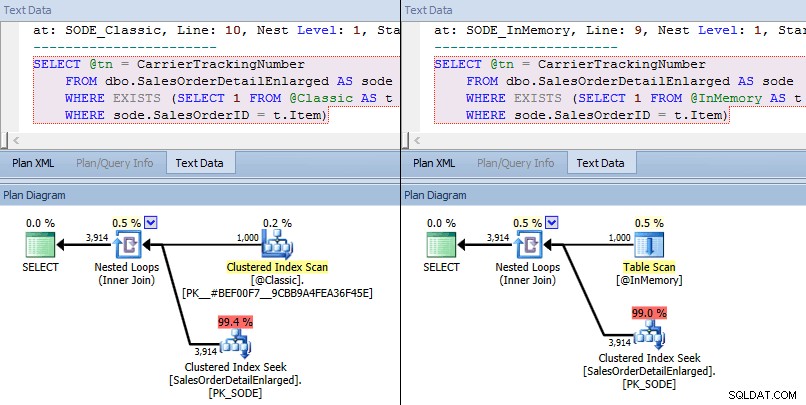 Ähnliche Pläne für In-Memory-TVP im Vergleich zu klassischem TVP in größerem Umfang
Ähnliche Pläne für In-Memory-TVP im Vergleich zu klassischem TVP in größerem Umfang
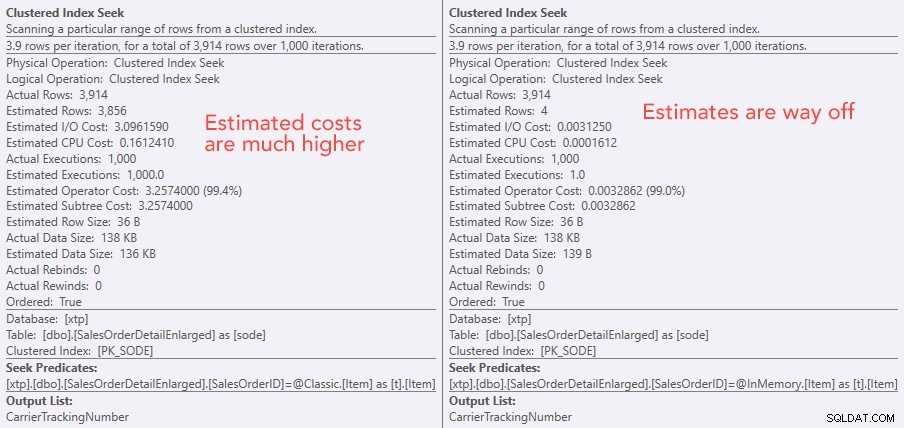 Vergleich der Kosten des Suchoperators – Classic links, In-Memory rechts
Vergleich der Kosten des Suchoperators – Classic links, In-Memory rechts
Der absolute Wert der Kosten lässt den Eindruck entstehen, dass das klassische TVP viel weniger effizient wäre als das In-Memory-TVP. Aber ich fragte mich, ob dies in der Praxis zutreffen würde (insbesondere, da die Zahl der geschätzten Anzahl von Hinrichtungen auf der rechten Seite verdächtig erschien), also führte ich natürlich einige Tests durch. Ich habe mich entschieden, 100, 1.000 und 2.000 Werte zu prüfen, die an die Prozedur gesendet werden sollen.
DECLARE @values INT = 100; -- 1000, 2000 DECLARE @Classic dbo.ClassicTVP; DECLARE @InMemory dbo.InMemoryTVP; INSERT @Classic(Item) SELECT TOP (@values) SalesOrderID FROM dbo.SalesOrderDetailEnlarged GROUP BY SalesOrderID ORDER BY NEWID(); INSERT @InMemory(Item) SELECT Item FROM @Classic; DECLARE @i INT = 1; SELECT SYSDATETIME(); WHILE @i <= 10000 BEGIN EXEC dbo.SODE_Classic @Classic = @Classic; SET @i += 1; END SELECT SYSDATETIME(); SET @i = 1; WHILE @i <= 10000 BEGIN EXEC dbo.SODE_InMemory @InMemory = @InMemory; SET @i += 1; END SELECT SYSDATETIME();
Die Leistungsergebnisse zeigen, dass die Verwendung eines In-Memory-TVP bei einer größeren Anzahl von Punktsuchen zu leicht abnehmenden Renditen führt und jedes Mal etwas langsamer ist:
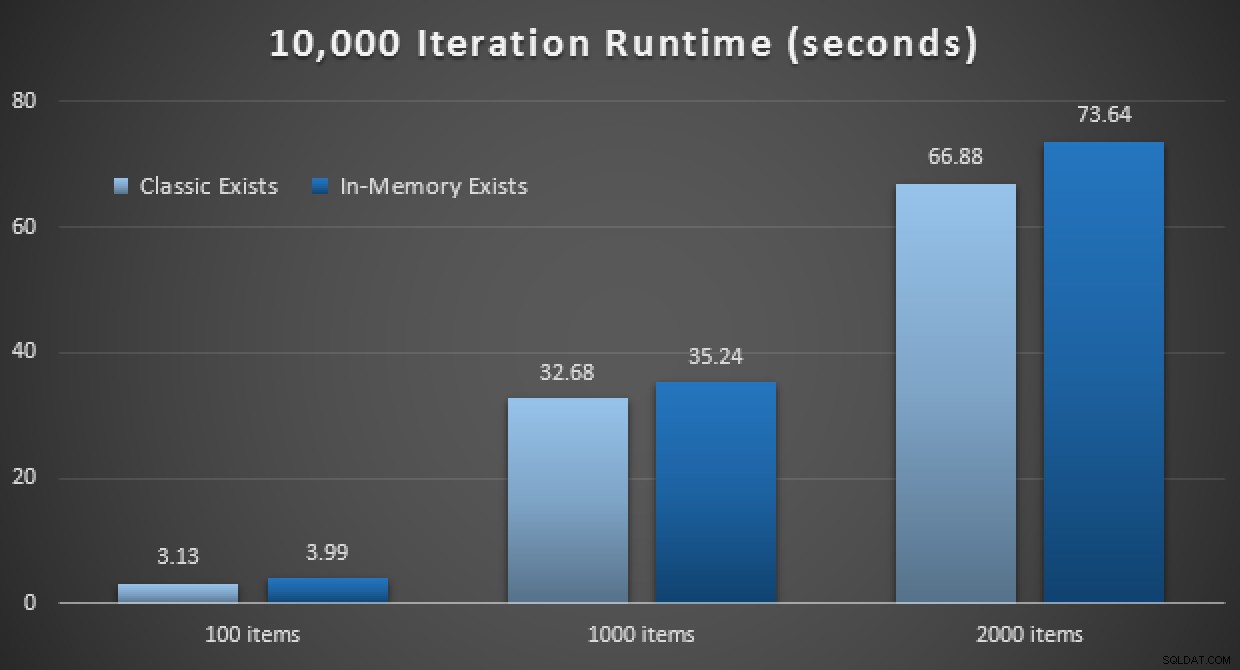
Ergebnisse von 10.000 Ausführungen mit klassischen und In-Memory-TVPs
Entgegen dem Eindruck, den Sie vielleicht aus meinem vorherigen Beitrag gewonnen haben, ist die Verwendung eines In-Memory-TVP also nicht unbedingt in allen Fällen von Vorteil.
Zuvor habe ich mir auch nativ kompilierte Stored Procedures und In-Memory-Tabellen in Kombination mit In-Memory-TVPs angesehen. Könnte das hier einen Unterschied machen? Spoiler:absolut nicht. Ich habe drei Prozeduren wie diese erstellt:
CREATE PROCEDURE [dbo].[SODE_Native_InMem_16K] -- and _131K and _1MM
@InMemory dbo.InMemoryTVP READONLY
WITH NATIVE_COMPILATION, SCHEMABINDING, EXECUTE AS OWNER
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL = SNAPSHOT, LANGUAGE = N'us_english');
DECLARE @tn NVARCHAR(25);
SELECT @tn = CarrierTrackingNumber
FROM dbo.SalesOrderDetailEnlarged_InMem_16K AS sode -- and _131K and _1MM
INNER JOIN @InMemory AS t -- no EXISTS allowed here
ON sode.SalesOrderID = t.Item;
END
GO Noch ein Spoiler:Ich konnte diese 9 Tests nicht mit einer Iterationszahl von 10.000 durchführen – das hat viel zu lange gedauert. Stattdessen habe ich jede Prozedur 10 Mal durchlaufen und ausgeführt, diese Testreihe 10 Mal ausgeführt und den Durchschnitt genommen. Hier sind die Ergebnisse:
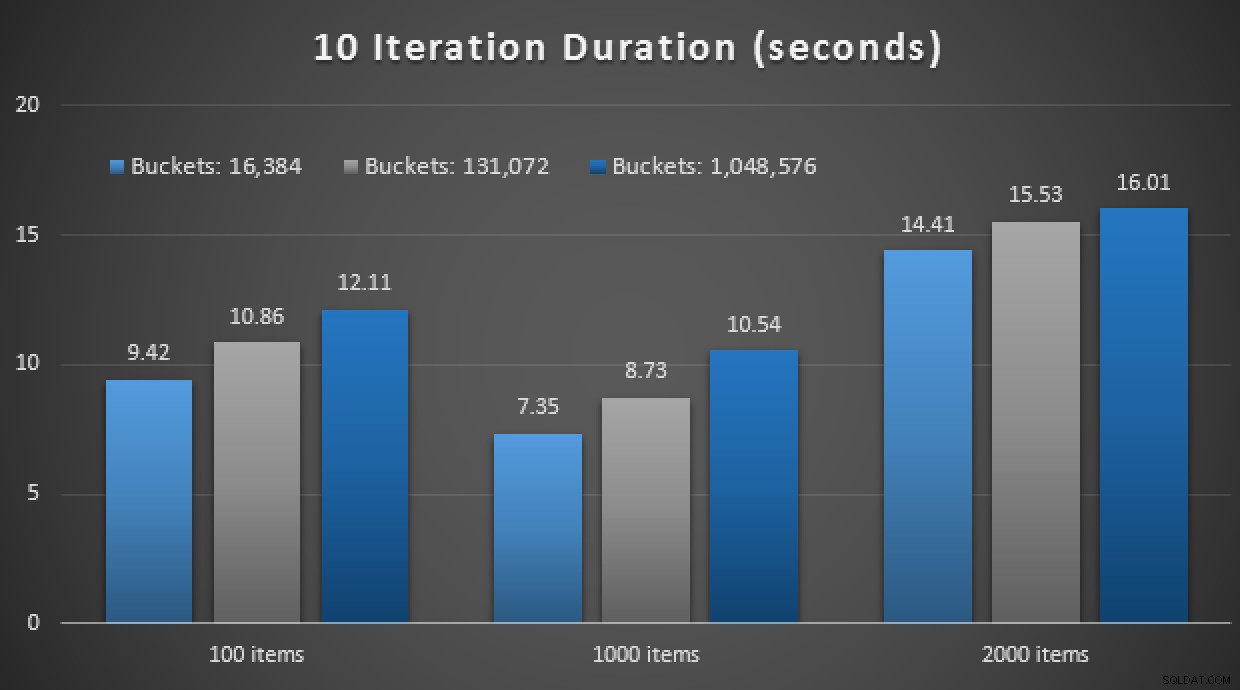
Ergebnisse von 10 Ausführungen mit In-Memory-TVPs und nativ kompiliert gespeichert Verfahren
Insgesamt war dieses Experiment eher enttäuschend. Wenn man sich nur die schiere Größe des Unterschieds ansieht, wurde der durchschnittliche Aufruf einer gespeicherten Prozedur bei einer Tabelle auf der Festplatte in durchschnittlich 0,0036 Sekunden abgeschlossen. Wenn jedoch alles In-Memory-Technologien verwendet wurde, betrug der durchschnittliche Aufruf gespeicherter Prozeduren 1,1662 Sekunden. Autsch . Es ist sehr wahrscheinlich, dass ich gerade einen schlechten Anwendungsfall für die Demo insgesamt ausgewählt habe, aber es schien damals ein intuitiver "erster Versuch" zu sein.
Schlussfolgerung
In diesem Szenario gibt es noch viel mehr zu testen, und ich werde noch weitere Blog-Posts folgen. Ich habe den optimalen Anwendungsfall für In-Memory-TVPs in größerem Maßstab noch nicht identifiziert, hoffe aber, dass dieser Beitrag als Erinnerung daran dient, dass eine Lösung zwar in einem Fall optimal erscheint, aber niemals davon ausgegangen werden kann, dass sie gleichermaßen anwendbar ist zu verschiedenen Szenarien. Genau so sollte In-Memory OLTP angegangen werden:als eine Lösung mit einer begrenzten Anzahl von Anwendungsfällen, die unbedingt validiert werden müssen, bevor sie in der Produktion implementiert werden.