In meinem vorherigen Beitrag zu inkrementellen Statistiken, einem neuen Feature in SQL Server 2014, habe ich gezeigt, wie sie dazu beitragen können, die Dauer von Wartungsaufgaben zu verkürzen. Dies liegt daran, dass Statistiken auf Partitionsebene aktualisiert und die Änderungen im Haupthistogramm für die Tabelle zusammengeführt werden können. Ich habe auch festgestellt, dass der Abfrageoptimierer diese Statistiken auf Partitionsebene beim Generieren von Abfrageplänen nicht verwendet, was möglicherweise etwas ist, das die Leute erwartet haben. Es gibt keine Dokumentation, die besagt, dass inkrementelle Statistiken vom Abfrageoptimierer verwendet werden oder nicht. Woher wissen Sie das? Sie müssen es testen. :-)
Die Einrichtung
Das Setup für diesen Test ähnelt dem im letzten Beitrag, jedoch mit weniger Daten. Beachten Sie, dass die Standardgrößen für die Datendateien kleiner sind und das Skript nur wenige Millionen Datenzeilen lädt:
USE [AdventureWorks2014_Partition]; GO /* add filesgroups */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILEGROUP [FG2015]; /* add files */ ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2011.ndf', NAME = N'2011', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2011]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2012.ndf', NAME = N'2012', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2012]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2013.ndf', NAME = N'2013', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2013]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2014.ndf', NAME = N'2014', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2014]; ALTER DATABASE [AdventureWorks2014_Partition] ADD FILE ( FILENAME = N'C:\Databases\AdventureWorks2014_Partition\2015.ndf', NAME = N'2015', SIZE = 512MB, MAXSIZE = 2048MB, FILEGROWTH = 512MB ) TO FILEGROUP [FG2015]; CREATE PARTITION FUNCTION [OrderDateRangePFN] ([datetime]) AS RANGE RIGHT FOR VALUES ( '20110101', --everything in 2011 '20120101', --everything in 2012 '20130101', --everything in 2013 '20140101', --everything in 2014 '20150101' --everything in 2015 ); GO CREATE PARTITION SCHEME [OrderDateRangePScheme] AS PARTITION [OrderDateRangePFN] TO ([PRIMARY], [FG2011], [FG2012], [FG2013], [FG2014], [FG2015]); GO CREATE TABLE [dbo].[Orders] ( [PurchaseOrderID] [int] NOT NULL, [EmployeeID] [int] NULL, [VendorID] [int] NULL, [TaxAmt] [money] NULL, [Freight] [money] NULL, [SubTotal] [money] NULL, [Status] [tinyint] NOT NULL, [RevisionNumber] [tinyint] NULL, [ModifiedDate] [datetime] NULL, [ShipMethodID] [tinyint] NULL, [ShipDate] [datetime] NOT NULL, [OrderDate] [datetime] NOT NULL, [TotalDue] [money] NULL ) ON [OrderDateRangePScheme] (OrderDate);
Wenn wir den gruppierten Index für dbo.Orders erstellen, erstellen wir ihn ohne STATISTICS_INCREMENTAL Option aktiviert, also beginnen wir mit einer herkömmlichen partitionierten Tabelle ohne inkrementelle Statistiken:
ALTER TABLE [dbo].[Orders] ADD CONSTRAINT [OrdersPK] PRIMARY KEY CLUSTERED ([OrderDate], [PurchaseOrderID]) ON [OrderDateRangePScheme] ([OrderDate]);
Als Nächstes laden wir etwa 4 Millionen Zeilen ein, was auf meinem Computer knapp eine Minute dauert:
SET NOCOUNT ON; DECLARE @Loops SMALLINT = 0; DECLARE @Increment INT = 3000; WHILE @Loops < 1000 BEGIN INSERT [dbo].[Orders] ([PurchaseOrderID] ,[EmployeeID] ,[VendorID] ,[TaxAmt] ,[Freight] ,[SubTotal] ,[Status] ,[RevisionNumber] ,[ModifiedDate] ,[ShipMethodID] ,[ShipDate] ,[OrderDate] ,[TotalDue] ) SELECT [PurchaseOrderID] + @Increment , [EmployeeID] , [VendorID] , [TaxAmt] , [Freight] , [SubTotal] , [Status] , [RevisionNumber] , [ModifiedDate] , [ShipMethodID] , DATEADD(DAY, 365, [ShipDate]) , DATEADD(DAY, 365, [OrderDate]) , [TotalDue] + 365 FROM [Purchasing].[PurchaseOrderHeader]; CHECKPOINT; SET @Loops = @Loops + 1; SET @Increment = @Increment + 5000; END
Nach dem Laden der Daten aktualisieren wir die Statistiken mit einem FULLSCAN (damit wir ein möglichst konsistentes Histogramm für Tests erstellen können) und überprüfen dann, welche Daten wir in jeder Partition haben:
UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN; SELECT $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) AS [Partition Number] , MIN([o].[OrderDate]) AS [Min_Order_Date] , MAX([o].[OrderDate]) AS [Max_Order_Date] , COUNT(*) AS [Rows_In_Partition] FROM [dbo].[Orders] AS [o] GROUP BY $PARTITION.[OrderDateRangePFN]([o].[OrderDate]) ORDER BY [Partition Number];
 Daten in jeder Partition nach dem Laden der Daten
Daten in jeder Partition nach dem Laden der Daten
Die meisten Daten befinden sich in der 2015-Partition, aber es gibt auch Daten für 2012, 2013 und 2014. Und wenn wir die Ausgabe der undokumentierten DMV sys.dm_db_stats_properties_internal überprüfen , können wir sehen, dass keine Statistiken auf Partitionsebene existieren:
SELECT *
FROM [sys].[dm_db_stats_properties_internal](OBJECT_ID('dbo.Orders'),1)
ORDER BY [node_id];
 sys.dm_db_stats_properties_internal-Ausgabe, die nur eine Statistik für dbo.Orders zeigt
sys.dm_db_stats_properties_internal-Ausgabe, die nur eine Statistik für dbo.Orders zeigt
Der Test
Das Testen erfordert eine einfache Abfrage, die wir verwenden können, um zu überprüfen, ob die Partitionsbeseitigung erfolgt, und auch um Schätzungen basierend auf Statistiken zu überprüfen. Die Abfrage gibt keine Daten zurück, aber das macht nichts, uns interessiert, was der Optimierer gedacht hat es würde, basierend auf Statistiken, zurückgeben:
SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
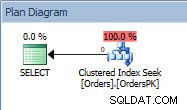 Abfrageplan für die SELECT-Anweisung
Abfrageplan für die SELECT-Anweisung
Der Plan hat einen Clustered Index Seek, und wenn wir die Eigenschaften überprüfen, sehen wir, dass er 4000 Zeilen geschätzt und auf Partition 5 zugegriffen hat, die Daten von 2014 enthält.
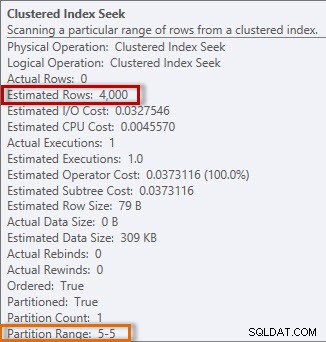 Geschätzte und tatsächliche Informationen aus dem Clustered Index Seek
Geschätzte und tatsächliche Informationen aus dem Clustered Index Seek
Wenn wir uns das Histogramm für die Tabelle dbo.Orders ansehen, insbesondere im Bereich der Daten vom April 2014, sehen wir, dass es keinen Schritt für den 1. April 2014 gibt, sodass der Optimierer die Anzahl der Zeilen für dieses Datum anhand des Schritts schätzt für 2014-04-24, wobei AVG_RANGE_ROWS ist 4000 (für jeden Wert zwischen 2014-02-14 und 2014-04-23 einschließlich schätzt der Optimierer, dass 4000 Zeilen zurückgegeben werden).
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
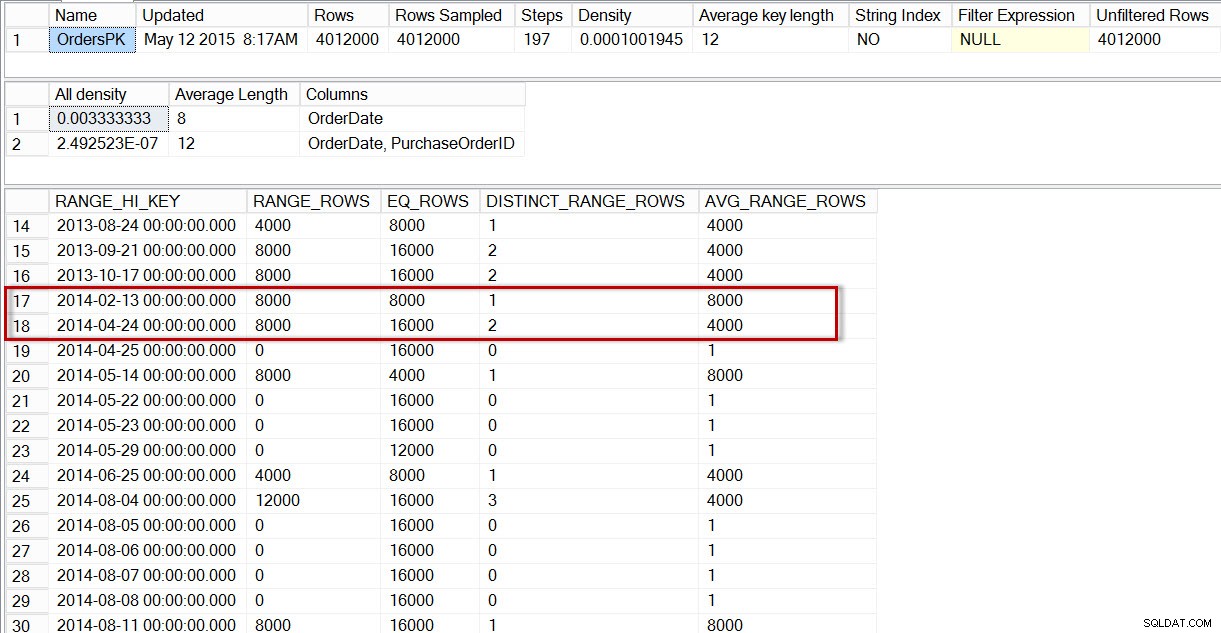 Verteilung im dbo.Orders-Histogramm
Verteilung im dbo.Orders-Histogramm
Die Schätzung und der Plan werden vollständig erwartet. Lassen Sie uns inkrementelle Statistiken aktivieren und sehen, was wir bekommen.
ALTER INDEX [OrdersPK] ON [dbo].[Orders] REBUILD WITH (STATISTICS_INCREMENTAL = ON); GO UPDATE STATISTICS [dbo].[Orders] WITH FULLSCAN;
Wenn wir unsere Abfrage gegen sys.dm_db_stats_properties_internal erneut ausführen , können wir die inkrementelle Statistik sehen:
 sys.dm_db_stats_properties_internal zeigt inkrementelle Statistikinformationen an
sys.dm_db_stats_properties_internal zeigt inkrementelle Statistikinformationen an
Lassen Sie uns nun unsere Abfrage dbo.Orders erneut ausführen, und wir führen DBCC FREEPROCCACHE aus Stellen Sie zunächst sicher, dass der Plan nicht wiederverwendet wird:
DBCC FREEPROCCACHE; GO SELECT * FROM [dbo].[Orders] WHERE [OrderDate] = '2014-04-01';
Wir erhalten denselben Plan und dieselbe Schätzung:
Abfrageplan für die SELECT-Anweisung
Geschätzte und tatsächliche Informationen aus dem Clustered Index Seek
Wenn wir das Haupthistogramm für dbo.Orders überprüfen, sehen wir fast dasselbe Histogramm wie zuvor:
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK');
 Histogramm für dbo.Orders, nachdem inkrementelle Statistiken aktiviert wurden
Histogramm für dbo.Orders, nachdem inkrementelle Statistiken aktiviert wurden
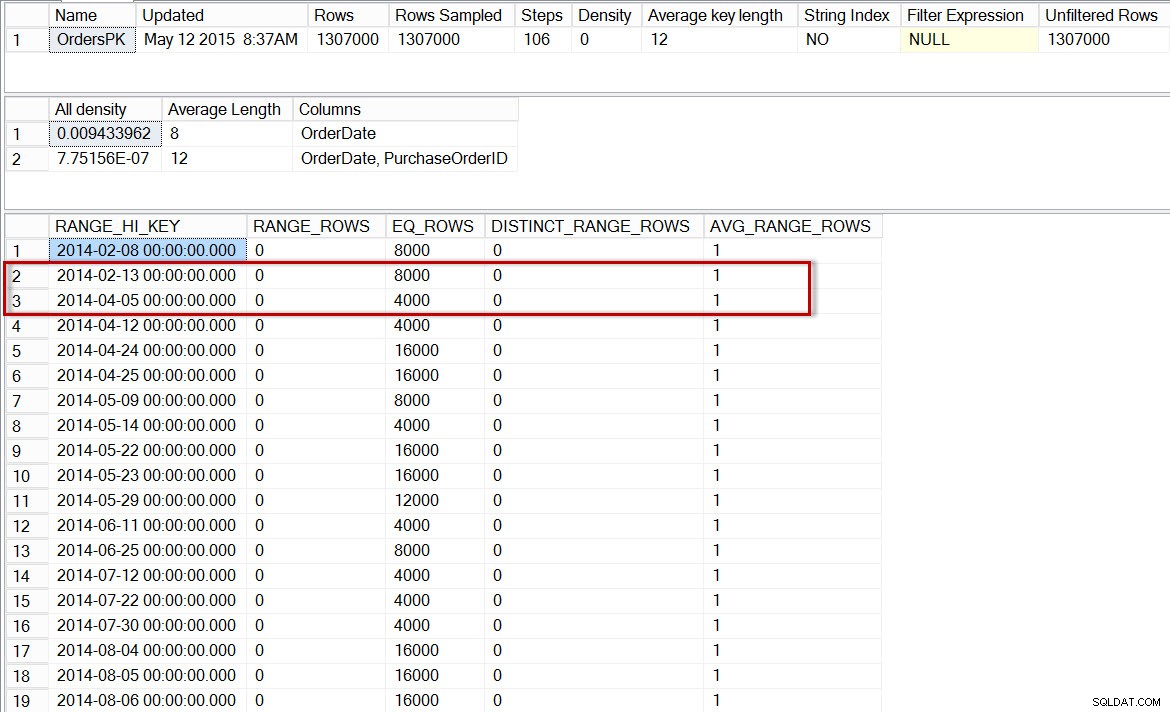
Lassen Sie uns nun das Histogramm für die Partition mit Daten von 2014 überprüfen (wir können dies mit dem undokumentierten Trace-Flag 2309 tun, das die Angabe einer Partitionsnummer als zusätzliches Argument für DBCC SHOW_STATISTICS ermöglicht ):
DBCC TRACEON(2309);
GO
DBCC SHOW_STATISTICS('dbo.Orders','OrdersPK', 6);
Histogramm für die 2014-Partition von dbo.Orders, nachdem inkrementelle Statistiken aktiviert wurden
Hier sehen wir wiederum, dass es für den 01.04.2014 keinen Schritt gibt, aber 0 RANGE_ROWS zwischen 2014-02-13 und 2014-04-05, mit einem AVG_RANGE_ROWS von 1. Wenn der Optimierer das Histogramm für die Statistiken auf Partitionsebene verwendet, wäre die Schätzung für die Anzahl der Zeilen für den 1.4.2014 1.
Hinweis:Die im Abfrageplan als verwendet identifizierte Partition ist 5, aber Sie werden feststellen, dass DBCC SHOW_STATISTICS -Anweisung verweist auf Partition 6. Die Annahme ist eine Inkonsistenz in Statistik-Metadaten (ein häufiger Off-by-one-Fehler, wahrscheinlich aufgrund einer 0-basierten vs. 1-basierten Zählung), die möglicherweise in Zukunft behoben wird oder nicht. Beachten Sie, dass das Trace-Flag derzeit nicht dokumentiert ist und dass die Verwendung in einer Produktionsumgebung nicht empfohlen wird.
Zusammenfassung
Das Hinzufügen inkrementeller Statistiken in der Version von SQL Server 2014 ist ein Schritt in die richtige Richtung für verbesserte Kardinalitätsschätzungen für partitionierte Tabellen. Wie wir jedoch gezeigt haben, ist der aktuelle Wert inkrementeller Statistiken auf kürzere Wartungszeiten beschränkt, da diese inkrementellen Statistiken noch nicht vom Abfrageoptimierer verwendet werden.



