Der T-SQL-Dienstag dieses Monats wird von Mike Donnelly (@SQLMD) moderiert, und er fasst das Thema wie folgt zusammen:
Das Thema in diesem Monat ist geradlinig, aber sehr offen. Sie müssen etwas Neues lernen und dann einen Blogbeitrag schreiben, der es erklärt.Nun, von dem Moment an, als Mike das Thema ankündigte, machte ich mich nicht wirklich daran, etwas Neues zu lernen, und als das Wochenende näher rückte und ich wusste, dass der Montag mich mit Geschworenenpflichten überfallen würde, dachte ich, ich müsste das hier sitzen Monat aus.
Dann lehrte mich Martin Smith etwas, das ich entweder nie wusste oder vor langer Zeit wusste, aber vergessen habe (manchmal weiß man nicht, was man nicht weiß, und manchmal kann man sich nicht erinnern, was man nie wusste und was nicht erinnern). Meine Erinnerung war, dass eine Spalte von NOT NULL geändert wurde auf NULL sollte ein Nur-Metadaten-Vorgang sein, bei dem Schreibvorgänge auf jede Seite verschoben werden, bis diese Seite aus anderen Gründen aktualisiert wird, da der NULL Bitmap müsste nicht wirklich existieren, bis mindestens eine Zeile NULL werden könnte .
In demselben Post erinnerte mich @ypercube auch an dieses relevante Zitat aus Books Online (Tippfehler und so):
Das Ändern einer Spalte von NOT NULL in NULL wird nicht als Online-Vorgang unterstützt, wenn auf die geänderte Spalte durch nicht gruppierte Indizes verwiesen wird.„Kein Online-Vorgang“ kann als „kein Nur-Metadaten-Vorgang“ interpretiert werden – was bedeutet, dass es sich tatsächlich um einen Datenumfangsvorgang handelt (je größer Ihr Index, desto länger dauert es).
Ich wollte dies mit einem ziemlich einfachen (aber langwierigen) Experiment mit einer bestimmten Zielspalte beweisen, um sie von NOT NULL zu konvertieren auf NULL . Ich würde 3 Tabellen erstellen, alle mit einem gruppierten Primärschlüssel, aber jede mit einem anderen nicht gruppierten Index. Die eine hätte die Zielspalte als Schlüsselspalte, die zweite als INCLUDE Spalte, und die dritte würde überhaupt nicht auf die Zielspalte verweisen.
Hier sind meine Tabellen und wie ich sie gefüllt habe:
CREATE TABLE dbo.test1
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t1 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix1 ON dbo.test1(b,c);
GO
CREATE TABLE dbo.test2
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t2 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix2 ON dbo.test2(b) INCLUDE(c);
GO
CREATE TABLE dbo.test3
(
a INT NOT NULL, b INT NOT NULL, c BIGINT NOT NULL,
CONSTRAINT pk_t3 PRIMARY KEY (a,b)
);
GO
CREATE NONCLUSTERED INDEX ix3 ON dbo.test3(b);
GO
INSERT dbo.test1(a,b,c) -- repeat for test2 / test3
SELECT n1, n2, ABS(n2)-ABS(n1)
FROM
(
SELECT TOP (100000) s1.[object_id], s2.[object_id]
FROM master.sys.all_objects AS s1
CROSS JOIN master.sys.all_objects AS s2
GROUP BY s1.[object_id], s2.[object_id]
) AS n(n1, n2);
Jede Tabelle hatte 100.000 Zeilen, die gruppierten Indizes hatten 310 Seiten und die nicht gruppierten Indizes hatten entweder 272 Seiten (test1 und test2 ) oder 174 Seiten (test3 ). (Diese Werte lassen sich leicht aus sys.dm_db_index_physical_stats abrufen .)
Als Nächstes brauchte ich eine einfache Möglichkeit, Vorgänge zu erfassen, die auf Seitenebene protokolliert wurden – ich wählte sys.fn_dblog() , obwohl ich hätte tiefer graben und Seiten direkt anschauen können. Ich habe mich nicht darum gekümmert, mit LSN-Werten herumzuspielen, um sie an die Funktion zu übergeben, da ich dies nicht in der Produktion ausgeführt habe und mich nicht sehr um die Leistung gekümmert habe, also habe ich nach den Tests einfach die Ergebnisse der Funktion ausgegeben, ohne alle Daten, die das waren wurde vor ALTER TABLE protokolliert Operationen.
-- establish an exclusion set SELECT * INTO #x FROM sys.fn_dblog(NULL, NULL);
Jetzt konnte ich meine Tests durchführen, die viel einfacher waren als die Einrichtung.
ALTER TABLE dbo.test1 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test2 ALTER COLUMN c BIGINT NULL; ALTER TABLE dbo.test3 ALTER COLUMN c BIGINT NULL;
Nun konnte ich die jeweils protokollierten Operationen untersuchen:
SELECT AllocUnitName, [Operation], Context, c = COUNT(*)
FROM
(
SELECT * FROM sys.fn_dblog(NULL, NULL)
WHERE [Operation] = N'LOP_FORMAT_PAGE'
AND AllocUnitName LIKE N'dbo.test%'
EXCEPT
SELECT * FROM #x
) AS x
GROUP BY AllocUnitName, [Operation], Context
ORDER BY AllocUnitName, [Operation], Context; Die Ergebnisse scheinen darauf hinzudeuten, dass jede Blattseite des nicht gruppierten Index für die Fälle berührt wird, in denen die Zielspalte in irgendeiner Weise im Index erwähnt wurde, aber keine derartigen Operationen für den Fall auftreten, in dem die Zielspalte in keiner Weise erwähnt wird Nicht gruppierter Index:
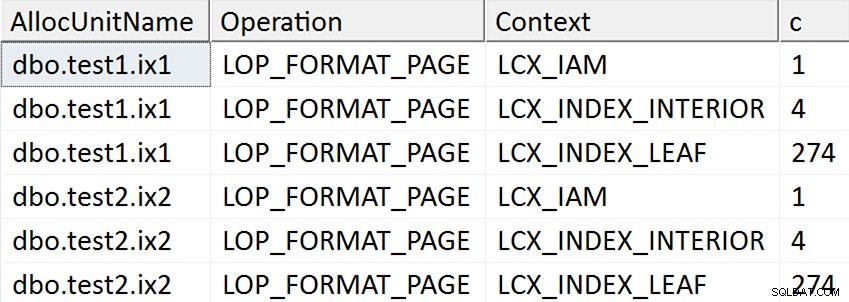
Tatsächlich werden in den ersten beiden Fällen neue Seiten zugewiesen (Sie können dies mit DBCC IND validieren , wie Spörri es in seiner Antwort getan hat), sodass die Operation online erfolgen kann, aber das bedeutet nicht, dass sie schnell ist (da sie immer noch eine Kopie all dieser Daten schreiben und den NULL erstellen muss Bitmap-Änderung als Teil des Schreibens jeder neuen Seite, und protokollieren Sie alle diese Aktivitäten).
Ich denke, die meisten Leute würden vermuten, dass das Ändern einer Spalte von NOT NULL auf NULL wäre in allen Szenarien nur Metadaten, aber ich habe hier gezeigt, dass dies nicht zutrifft, wenn die Spalte von einem nicht gruppierten Index referenziert wird (und ähnliche Dinge passieren, egal ob es sich um einen Schlüssel oder INCLUDE handelt Säule). Vielleicht kann diese Operation auch ONLINE erzwungen werden in Azure SQL Database heute oder wird es in der nächsten Hauptversion möglich sein? Dadurch werden die eigentlichen physischen Vorgänge nicht unbedingt schneller, aber es wird dadurch eine Blockierung verhindert.
Ich habe dieses Szenario weder getestet (und die Analyse, ob es wirklich online ist, ist in Azure ohnehin schwieriger), noch habe ich es auf einem Haufen getestet. Etwas, auf das ich in einem zukünftigen Beitrag zurückkommen kann. Seien Sie in der Zwischenzeit vorsichtig mit Annahmen, die Sie möglicherweise zu reinen Metadatenvorgängen machen.