Das ist auch keine gute Fragmentierung
Letzten Monat habe ich über die unerwartete Fragmentierung von Clustered-Indizes geschrieben, daher möchte ich dieses Mal einige der Dinge besprechen, die Sie tun können, um eine Indexfragmentierung zu vermeiden. Ich gehe davon aus, dass Sie den vorherigen Post gelesen haben und mit den Begriffen vertraut sind, die ich dort definiert habe, und im Rest dieses Artikels beziehe ich mich, wenn ich „Fragmentierung“ sage, sowohl auf die logische Fragmentierung als auch auf Probleme mit geringer Seitendichte.
Wählen Sie einen guten Clusterschlüssel
Die teuerste Datenstruktur zum Entfernen der Fragmentierung ist der gruppierte Index einer Tabelle, da er die größte Struktur ist, da er alle Tabellendaten enthält. Aus Sicht der Fragmentierung ist es sinnvoll, einen Clusterschlüssel zu wählen, der dem Tabelleneinfügemuster entspricht, sodass keine Möglichkeit besteht, dass eine Einfügung auf einer Seite erfolgt, auf der kein Platz vorhanden ist, und somit eine Seitenaufteilung verursacht und eine Fragmentierung einführt.
Was der beste Cluster-Schlüssel für eine bestimmte Tabelle ist, ist umstritten, aber im Allgemeinen werden Sie nichts falsch machen, wenn Ihr Cluster-Schlüssel die folgenden einfachen Eigenschaften hat:
- Schmal (d. h. so wenig Spalten wie möglich)
- Statisch (d. h. Sie aktualisieren es nie)
- Einzigartig
- Immer mehr
Es ist die ständig zunehmende Eigenschaft, die für die Fragmentierungsverhinderung am wichtigsten ist, da sie zufällige Einfügungen vermeidet, die Seitenaufteilungen auf bereits vollen Seiten verursachen können. Beispiele für eine solche Schlüsselauswahl sind int-Identitäts- und bigint-Identitätsspalten oder sogar eine sequentielle GUID aus der NEWSEQUENTIALID()-Funktion.
Bei diesen Schlüsseltypen haben neue Zeilen einen Schlüsselwert, der garantiert höher ist als alle anderen in der Tabelle, und daher befindet sich der Einfügepunkt der neuen Zeile am Ende der Seite ganz rechts in der Clustered-Index-Struktur. Schließlich füllen die neuen Zeilen diese Seite auf und eine weitere Seite wird auf der rechten Seite des Indexes hinzugefügt, aber ohne dass eine schädliche Seitenteilung auftritt.
Nun, wenn Sie einen gruppierten Indexschlüssel haben, der nicht ständig ansteigt, kann es ein sehr komplexes und unangenehmes Verfahren sein, ihn in einen ständig ansteigenden zu ändern, also machen Sie sich keine Sorgen – stattdessen können Sie einen Füllfaktor verwenden, wie ich bespreche unten.
Übrigens, für einen viel tieferen Einblick in die Auswahl eines Cluster-Schlüssels und all seine Auswirkungen, schauen Sie sich die Blog-Kategorie „Clustering Key“ von Kimberly an (von unten nach oben lesen).
Indexschlüsselspalten nicht aktualisieren
Wann immer eine Schlüsselspalte aktualisiert wird, handelt es sich nicht nur um ein einfaches In-Place-Update, obwohl viele Stellen im Internet und in Büchern sagen, dass dies der Fall ist (sie liegen falsch). Eine Schlüsselspalte kann nicht an Ort und Stelle aktualisiert werden, da der neue Schlüsselwert dann bedeuten würde, dass die Zeile in der falschen Schlüsselreihenfolge für den Index ist. Stattdessen wird eine Schlüsselspaltenaktualisierung in eine vollständige Zeilenlöschung plus eine vollständige Zeileneinfügung mit dem neuen Schlüsselwert übersetzt. Wenn auf der Seite, auf der die neue Zeile eingefügt wird, nicht genügend Platz vorhanden ist, wird eine Seite geteilt, was zu einer Fragmentierung führt.
Das Vermeiden von Schlüsselspaltenaktualisierungen sollte für den gruppierten Index einfach zu bewerkstelligen sein, da es sich um ein schlechtes Design handelt, das die Aktualisierung des Clusterschlüssels einer Tabellenzeile erfordert. Bei Nonclustered-Indizes ist es jedoch unvermeidlich, wenn Aktualisierungen der Tabelle Spalten betreffen, für die ein Nonclustered-Index vorhanden ist. In diesen Fällen müssen Sie einen Füllfaktor verwenden.
Spalten variabler Länge nicht aktualisieren
Das ist leichter gesagt als getan. Wenn Sie Spalten mit variabler Länge verwenden müssen und es möglich ist, dass sie aktualisiert werden, dann ist es möglich, dass sie wachsen und so mehr Platz für die aktualisierte Zeile benötigen, was zu einer Seitenteilung führt, wenn die Seite bereits voll ist.
Es gibt ein paar Dinge, die Sie tun könnten, um in diesem Fall eine Fragmentierung zu vermeiden:
- Verwenden Sie einen Füllfaktor
- Verwenden Sie stattdessen eine Spalte mit fester Länge, wenn der Overhead aller zusätzlichen Füllbytes weniger ein Problem darstellt als die Fragmentierung oder die Verwendung eines Füllfaktors
- Verwenden Sie einen Platzhalterwert, um Platz für die Spalte zu „reservieren“ – dies ist ein Trick, den Sie verwenden können, wenn die Anwendung eine neue Zeile eingibt und dann zurückkommt, um einige der Details auszufüllen, was zu einer Spaltenerweiterung mit variabler Länge führt
- Führen Sie statt einer Aktualisierung ein Löschen plus Einfügen durch
Verwenden Sie einen Füllfaktor
Wie Sie sehen können, sind viele der Möglichkeiten zur Vermeidung von Fragmentierung unangenehm, da sie Anwendungs- oder Schemaänderungen beinhalten, und daher ist die Verwendung eines Füllfaktors eine einfache Möglichkeit, die Fragmentierung zu verringern.
Ein Indexfüllfaktor ist eine Einstellung für den Index, die angibt, wie viel leerer Platz auf jeder Seite auf Blattebene gelassen werden soll, wenn der Index erstellt, neu erstellt oder neu organisiert wird. Die Idee ist, dass auf der Seite genügend freier Speicherplatz vorhanden ist, um zufällige Einfügungen oder Zeilenerweiterungen (durch das Hinzufügen eines Versionierungs-Tags oder das Aktualisieren von Spalten mit variabler Länge) zu ermöglichen, ohne dass die Seite voll wird und eine Seitenteilung erforderlich ist. Irgendwann füllt sich die Seite jedoch, und daher muss der freie Speicherplatz regelmäßig aktualisiert werden, indem der Index neu erstellt oder neu organisiert wird (allgemein als Indexwartung bezeichnet). Der Trick besteht darin, den richtigen Füllfaktor zusammen mit der richtigen Periodizität der Indexpflege zu finden.
Weitere Informationen zum Festlegen eines Füllfaktors in MSDN finden Sie hier. Tappen Sie nicht in die Falle, den Füllfaktor für die gesamte Instanz festzulegen (mithilfe von sp_configure), da dies bedeutet, dass alle Indizes mit diesem Füllfaktorwert neu erstellt oder neu organisiert werden, selbst diejenigen Indizes, die keine Fragmentierungsprobleme haben. Sie möchten nicht, dass Ihre großen Cluster-Indizes mit netten, ständig wachsenden Schlüsseln 30 % ihres Speicherplatzes auf Blattebene verschwenden, um zufällige Einfügungen vorzubereiten, die niemals vorkommen werden. Es ist viel besser, herauszufinden, welche Indizes tatsächlich von der Fragmentierung betroffen sind, und nur für diese einen Füllfaktor festzulegen.
Es gibt keine richtige Antwort oder Zauberformel, die ich Ihnen dafür geben kann. Die allgemein akzeptierte Praxis besteht darin, einen Füllfaktor von 70 (d. h. 30 % freien Speicherplatz zu lassen) für die Indizes festzulegen, bei denen die Fragmentierung ein Problem darstellt, zu überwachen, wie schnell die Fragmentierung auftritt, und dann entweder den Füllfaktor oder die Wartungshäufigkeit des Index zu ändern (oder beides).
Ja, das bedeutet, dass Sie absichtlich Speicherplatz in den Indizes verschwenden, um eine Fragmentierung zu vermeiden, aber das ist ein guter Kompromiss, wenn man bedenkt, wie teuer Seitenaufteilungen sind und wie nachteilig die Fragmentierung für die Leistung sein kann. Und ja, ungeachtet dessen, was manche sagen, ist dies immer noch wichtig, selbst wenn Sie SSDs verwenden.
Zusammenfassung
Es gibt einige einfache Dinge, die Sie tun können, um eine Fragmentierung zu vermeiden, aber sobald Sie in nicht gruppierte Indizes gelangen oder Snapshot-Isolation oder lesbare Secondaries verwenden, zeigt die Fragmentierung ihr hässliches Gesicht und Sie müssen versuchen, sie zu verhindern.
Denken Sie jetzt nicht reflexartig, dass Sie für alle Ihre Instanzen einen Füllfaktor von 70 festlegen sollten – Sie müssen sie sorgfältig auswählen und festlegen, wie ich oben beschrieben habe.
Und vergessen Sie nicht den SQL Sentry Fragmentation Manager, den Sie (als Add-on zu Performance Advisor) verwenden können, um herauszufinden, wo Fragmentierungsprobleme liegen, und sie dann zu beheben. Beispielsweise können Sie auf der Registerkarte „Indizes“ Ihre Indizes einfach zuerst nach der höchsten Fragmentierung sortieren (und, wenn Sie möchten, einen Filter auf die Spalte „Zeilenzahl“ anwenden, um Ihre kleineren Tabellen zu ignorieren):
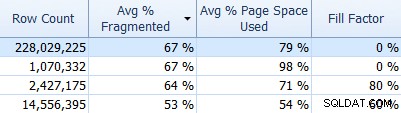
Und prüfen Sie dann, ob diese Indizes den standardmäßigen Füllfaktor (0 %) oder vielleicht einen nicht standardmäßigen Füllfaktor verwenden, der möglicherweise nicht gut zu Ihren Daten und DML-Mustern passt. Ich lasse Sie raten, welche im obigen Screenshot mich am meisten interessieren würden. Die Implementierung geeigneterer Index-Füllfaktoren ist die einfachste Möglichkeit, Probleme zu lösen, die Sie entdecken.