Die allgemeine Strategie, die die SQL Server-Datenbank-Engine verwendet, um eine indizierte Ansicht mit ihren Basistabellen zu synchronisieren – die ich in meinem letzten Beitrag ausführlicher beschrieben habe – besteht darin, inkrementelle Wartung durchzuführen der Ansicht, wenn eine Datenänderungsoperation für eine der Tabellen auftritt, auf die in der Ansicht verwiesen wird. Im Großen und Ganzen lautet die Idee:
- Sammeln Sie Informationen über die Änderungen der Basistabelle
- Wenden Sie die in der Ansicht definierten Projektionen, Filter und Verbindungen an
- Aggregieren Sie die Änderungen pro gruppiertem Schlüssel der indizierten Ansicht
- Entscheiden Sie, ob jede Änderung zu einer Einfügung, Aktualisierung oder Löschung der Ansicht führen soll
- Berechnen Sie die Werte, die in der Ansicht geändert, hinzugefügt oder entfernt werden sollen
- Übernehmen Sie die Ansichtsänderungen
Oder noch knapper (allerdings auf die Gefahr einer groben Vereinfachung):
- Berechnen Sie die inkrementellen Ansichtseffekte der ursprünglichen Datenänderungen;
- Wenden Sie diese Änderungen auf die Ansicht an
Dies ist normalerweise eine viel effizientere Strategie als die Neuerstellung der gesamten Ansicht nach jeder zugrunde liegenden Datenänderung (die sichere, aber langsame Option), aber sie beruht darauf, dass die inkrementelle Aktualisierungslogik für jede denkbare Datenänderung korrekt ist, gegen jede mögliche indizierte Ansichtsdefinition.
Wie der Titel vermuten lässt, befasst sich dieser Artikel mit einem interessanten Fall, bei dem die Logik der inkrementellen Aktualisierung zusammenbricht, was zu einer beschädigten indizierten Ansicht führt, die nicht mehr mit den zugrunde liegenden Daten übereinstimmt. Bevor wir zum Fehler selbst kommen, müssen wir uns schnell mit Skalar- und Vektoraggregaten befassen.
Skalare und Vektoraggregate
Falls Sie mit dem Begriff nicht vertraut sind, es gibt zwei Arten von Aggregaten. Ein Aggregat, das mit einer GROUP BY-Klausel verknüpft ist (selbst wenn die Gruppieren-nach-Liste leer ist), wird als Vektoraggregat bezeichnet . Ein Aggregat ohne eine GROUP BY-Klausel wird als skalares Aggregat bezeichnet .
Während ein Vektoraggregat garantiert eine einzelne Ausgabezeile für jede im Datensatz vorhandene Gruppe erzeugt, sind skalare Aggregate etwas anders. Skalare Aggregate immer erzeugt eine einzelne Ausgabezeile, auch wenn die Eingabemenge leer ist.
Beispiel für Vektoraggregate
Das folgende AdventureWorks-Beispiel berechnet zwei Vektoraggregate (eine Summe und eine Anzahl) für einen leeren Eingabesatz:
-- There are no TransactionHistory records for ProductID 848 -- Vector aggregate produces no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY TH.ProductID;
Diese Abfragen erzeugen die folgende Ausgabe (keine Zeilen):

Das Ergebnis ist dasselbe, wenn wir die GROUP BY-Klausel durch eine leere Menge ersetzen (erfordert SQL Server 2008 oder höher):
-- Equivalent vector aggregate queries with -- an empty GROUP BY column list -- (SQL Server 2008 and later required) -- Still no output rows SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY (); SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848 GROUP BY ();
Auch die Ausführungspläne sind in beiden Fällen identisch. Dies ist der Ausführungsplan für die Zählabfrage:
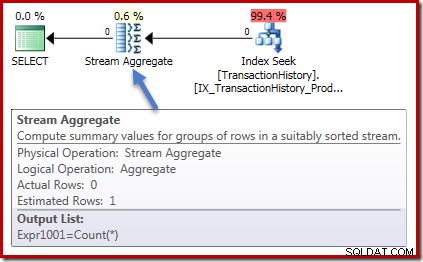
Null Zeilen werden in das Stream Aggregate eingegeben und null Zeilen ausgegeben. Der Summenausführungsplan sieht folgendermaßen aus:

Wieder null Zeilen in das Aggregat und null Zeilen heraus. Alles gute einfache Sachen bisher.
Skalare Aggregate
Sehen Sie sich nun an, was passiert, wenn wir die GROUP BY-Klausel vollständig aus den Abfragen entfernen:
-- Scalar aggregate (no GROUP BY clause) -- Returns a single output row from an empty input SELECT COUNT_BIG(*) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848; SELECT SUM(TH.Quantity) FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 848;
Anstelle eines leeren Ergebnisses erzeugt das COUNT-Aggregat eine Null und das SUM eine NULL:
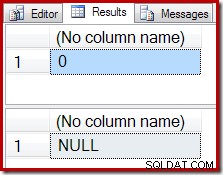
Der Ausführungsplan für die Zählung bestätigt, dass null Eingabezeilen eine einzelne Ausgabezeile aus dem Stream-Aggregat erzeugen:
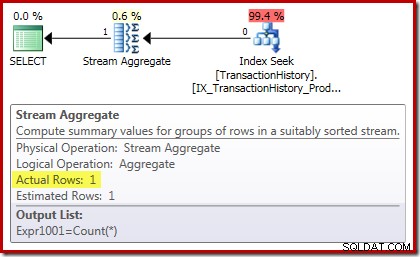
Der Summenausführungsplan ist sogar noch interessanter:
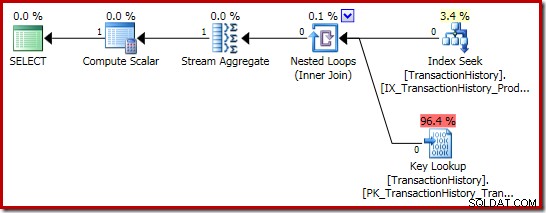
Die Stream-Aggregate-Eigenschaften zeigen, dass zusätzlich zu der Summe, nach der wir gefragt haben, ein Zählaggregat berechnet wird:
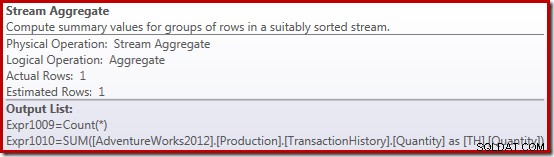
Der neue Compute Scalar-Operator wird verwendet, um NULL zurückzugeben, wenn die Anzahl der vom Stream-Aggregat empfangenen Zeilen null ist, andernfalls gibt er die Summe der gefundenen Daten zurück:
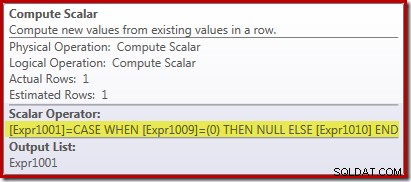
Das mag alles etwas seltsam erscheinen, aber so funktioniert es:
- Ein Vektoraggregat aus null Zeilen gibt null Zeilen zurück;
- Ein skalares Aggregat erzeugt immer genau eine Ausgabezeile, sogar für eine leere Eingabe;
- Die skalare Anzahl von Nullzeilen ist Null; und
- Die Skalarsumme von Nullzeilen ist NULL (nicht Null).
Der wichtige Punkt für unsere gegenwärtigen Zwecke ist, dass skalare Aggregate immer eine einzelne Ausgabezeile erzeugen, selbst wenn dies bedeutet, eine aus dem Nichts zu erstellen. Außerdem ist die Skalarsumme von Nullzeilen NULL, nicht Null.
Diese Verhaltensweisen sind übrigens alle "richtig". Die Dinge sind so, wie sie sind, weil der SQL-Standard das Verhalten von skalaren Aggregaten ursprünglich nicht definierte und es der Implementierung überließ. SQL Server behält seine ursprüngliche Implementierung aus Gründen der Abwärtskompatibilität bei. Vektoraggregate hatten schon immer genau definierte Verhaltensweisen.
Indizierte Ansichten und Vektoraggregation
Stellen Sie sich nun eine einfache indizierte Ansicht vor, die ein paar (Vektor-) Aggregate enthält:
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
T1.GroupID,
GroupSum = SUM(T1.Value),
RowsInGroup = COUNT_BIG(*)
FROM dbo.T1 AS T1
GROUP BY
T1.GroupID;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (GroupID); Die folgenden Abfragen zeigen den Inhalt der Basistabelle, das Ergebnis der Abfrage der indizierten Ansicht und das Ergebnis der Ausführung der Ansichtsabfrage für die der Ansicht zugrunde liegende Tabelle:
-- Sample data SELECT * FROM dbo.T1 AS T1; -- Indexed view contents SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Underlying view query results SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
Die Ergebnisse sind:
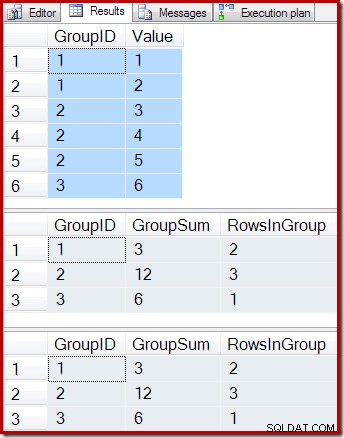
Wie erwartet geben die indizierte Ansicht und die zugrunde liegende Abfrage genau die gleichen Ergebnisse zurück. Die Ergebnisse bleiben nach allen möglichen Änderungen an der Basistabelle T1 weiterhin synchronisiert. Um uns daran zu erinnern, wie das alles funktioniert, betrachten wir den einfachen Fall, eine einzelne neue Zeile zur Basistabelle hinzuzufügen:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Der Ausführungsplan für diese Einfügung enthält die gesamte Logik, die erforderlich ist, um die indizierte Ansicht synchron zu halten:
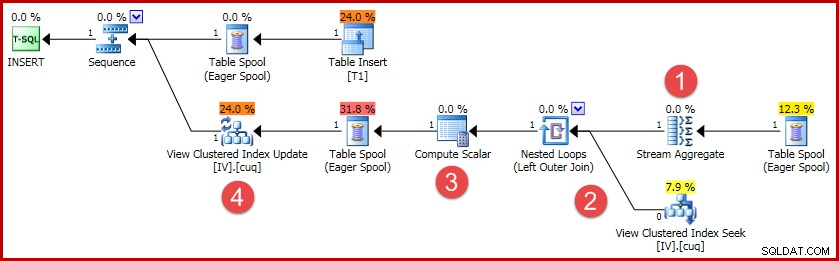
Die wichtigsten Aktivitäten im Plan sind:
- Das Stream-Aggregat berechnet die Änderungen pro Schlüssel der indizierten Ansicht
- Der Outer Join mit der Ansicht verknüpft die Änderungszusammenfassung mit der Zeile der Zielansicht, falls vorhanden
- Der Berechnungsskalar entscheidet, ob jede Änderung eine Einfügung, Aktualisierung oder Löschung der Ansicht erfordert, und berechnet die erforderlichen Werte.
- Der View-Update-Operator führt physisch jede Änderung am View-Clustered-Index durch.
Es gibt einige Planunterschiede für verschiedene Änderungsvorgänge an der Basistabelle (z. B. Aktualisierungen und Löschungen), aber die allgemeine Idee hinter der Synchronisierung der Ansicht bleibt dieselbe:aggregieren Sie die Änderungen pro Ansichtsschlüssel, suchen Sie die Ansichtszeile, falls vorhanden, und führen Sie sie dann aus je nach Bedarf eine Kombination aus Einfüge-, Aktualisierungs- und Löschvorgängen für den Ansichtsindex.
Unabhängig davon, welche Änderungen Sie in diesem Beispiel an der Basistabelle vornehmen, die indizierte Ansicht bleibt korrekt synchronisiert – die obigen NOEXPAND- und EXPAND VIEWS-Abfragen geben immer dieselbe Ergebnismenge zurück. So sollte es immer laufen.
Indizierte Ansichten und skalare Aggregation
Probieren Sie nun dieses Beispiel aus, bei dem die indizierte Ansicht eine skalare Aggregation verwendet (keine GROUP BY-Klausel in der Ansicht):
DROP VIEW dbo.IV;
DROP TABLE dbo.T1;
GO
CREATE TABLE dbo.T1
(
GroupID integer NOT NULL,
Value integer NOT NULL
);
GO
INSERT dbo.T1
(GroupID, Value)
VALUES
(1, 1),
(1, 2),
(2, 3),
(2, 4),
(2, 5),
(3, 6);
GO
CREATE VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Dies ist eine vollkommen legale indizierte Ansicht; Beim Erstellen treten keine Fehler auf. Es gibt jedoch einen Hinweis darauf, dass wir möglicherweise etwas Seltsames tun:Wenn es an der Zeit ist, die Ansicht zu materialisieren, indem der erforderliche eindeutige gruppierte Index erstellt wird, gibt es keine offensichtliche Spalte, die als Schlüssel ausgewählt werden kann. Normalerweise würden wir die Gruppierungsspalten natürlich aus der GROUP BY-Klausel der Ansicht auswählen.
Das obige Skript wählt willkürlich die NumRows-Spalte aus. Diese Wahl ist nicht wichtig. Fühlen Sie sich frei, den einzigartigen gruppierten Index zu erstellen, wie Sie möchten. Die Ansicht enthält immer genau eine Zeile wegen der skalaren Aggregate, also gibt es keine Möglichkeit einer eindeutigen Schlüsselverletzung. Insofern ist die Wahl des View-Indexschlüssels redundant, aber dennoch erforderlich.
Unter Wiederverwendung der Testabfragen aus dem vorherigen Beispiel können wir sehen, dass die indizierte Ansicht korrekt funktioniert:
SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
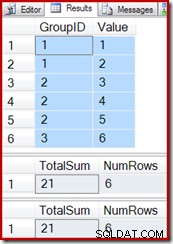
Das Einfügen einer neuen Zeile in die Basistabelle (wie wir es bei der indizierten Vektoraggregatansicht getan haben) funktioniert auch weiterhin korrekt:
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100); Der Ausführungsplan ist ähnlich, aber nicht ganz identisch:
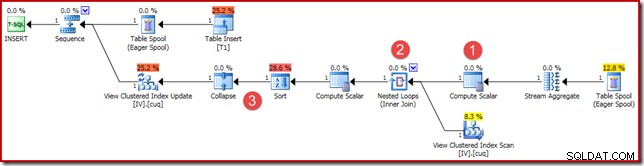
Die Hauptunterschiede sind:
- Dieser neue Berechnungsskalar ist aus den gleichen Gründen wie beim früheren Vergleich von Vektor- und Skalaraggregationsergebnissen vorhanden:Er stellt sicher, dass eine NULL-Summe zurückgegeben wird (anstelle von Null), wenn das Aggregat auf einer leeren Menge operiert. Dies ist das erforderliche Verhalten für eine Skalarsumme ohne Zeilen.
- Der frühere Outer Join wurde durch einen Inner Join ersetzt. Es gibt immer genau eine Zeile in der indizierten Ansicht (aufgrund der skalaren Aggregation), sodass es keine Frage der Notwendigkeit eines äußeren Joins gibt, um zu testen, ob eine Ansichtszeile übereinstimmt oder nicht. Die eine in der Ansicht vorhandene Zeile repräsentiert immer den gesamten Datensatz. Dieser Inner Join hat kein Prädikat, ist also technisch gesehen ein Cross Join (zu einer Tabelle mit einer garantierten einzelnen Zeile).
- Die Sortier- und Reduzieren-Operatoren sind aus technischen Gründen vorhanden, die in meinem vorherigen Artikel über die Wartung indizierter Ansichten behandelt wurden. Sie haben hier keinen Einfluss auf den korrekten Betrieb der Wartung der indizierten Ansicht.
Tatsächlich können in diesem Beispiel viele verschiedene Typen von Datenänderungsoperationen erfolgreich an der Basistabelle T1 durchgeführt werden; Die Effekte werden in der indizierten Ansicht korrekt wiedergegeben. Die folgenden Änderungsoperationen für die Basistabelle können alle durchgeführt werden, während die indizierte Ansicht korrekt bleibt:
- Vorhandene Zeilen löschen
- Vorhandene Zeilen aktualisieren
- Neue Zeilen einfügen
Dies mag wie eine umfassende Liste erscheinen, ist es aber nicht.
Der Fehler wurde aufgedeckt
Das Problem ist eher subtil und bezieht sich (wie zu erwarten war) auf das unterschiedliche Verhalten von Vektor- und Skalaraggregaten. Die wichtigsten Punkte sind, dass ein skalares Aggregat immer eine Ausgabezeile erzeugt, selbst wenn es keine Zeilen an seiner Eingabe erhält, und die skalare Summe einer leeren Menge NULL und nicht null ist.
Um ein Problem zu verursachen, brauchen wir nur keine Zeilen in die Basistabelle einzufügen oder zu löschen.
Diese Aussage ist nicht so verrückt, wie sie zunächst klingen mag.
Der Punkt ist, dass eine Einfüge- oder Löschabfrage, die keine Basistabellenzeilen betrifft, immer noch die Ansicht aktualisiert da das skalare Stream-Aggregat im Abschnitt zur Verwaltung der indizierten Ansicht des Abfrageplans eine Ausgabezeile erzeugt, selbst wenn keine Eingabe vorhanden ist. Der Compute-Skalar, der dem Stream-Aggregat folgt, generiert ebenfalls eine NULL-Summe, wenn die Anzahl der Zeilen null ist.
Das folgende Skript demonstriert den Fehler in Aktion:
-- So we can undo BEGIN TRANSACTION; -- Show the starting state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- A table variable intended to hold new base table rows DECLARE @NewRows AS table (GroupID integer NOT NULL, Value integer NOT NULL); -- Insert to the base table (no rows in the table variable!) INSERT dbo.T1 SELECT NR.GroupID,NR.Value FROM @NewRows AS NR; -- Show the final state SELECT * FROM dbo.T1 AS T1; SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS); SELECT * FROM dbo.IV AS IV WITH (NOEXPAND); -- Undo the damage ROLLBACK TRANSACTION;
Die Ausgabe dieses Skripts wird unten gezeigt:
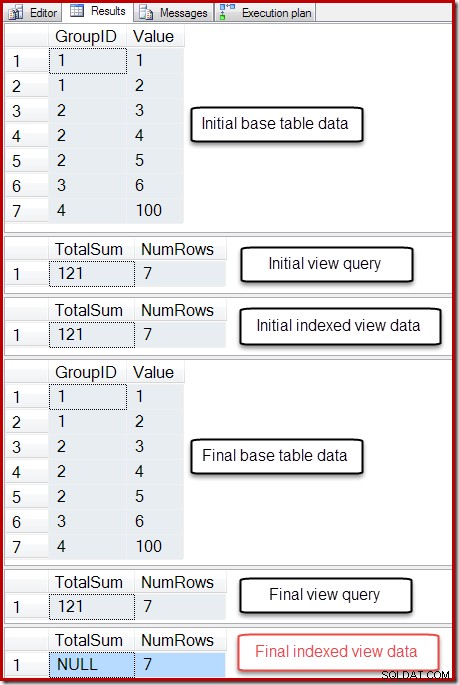
Der endgültige Zustand der Spalte Gesamtsumme der indizierten Ansicht stimmt nicht mit der zugrunde liegenden Ansichtsabfrage oder den Basistabellendaten überein. Die NULL-Summe hat die Ansicht beschädigt, was durch Ausführen von DBCC CHECKTABLE (für die indizierte Ansicht) bestätigt werden kann.
Der Ausführungsplan, der für die Korruption verantwortlich ist, wird unten gezeigt:
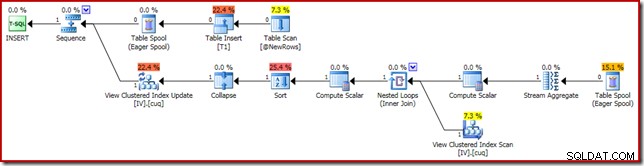
Beim Vergrößern wird die Null-Zeilen-Eingabe für das Stream-Aggregat und die Ein-Zeilen-Ausgabe angezeigt:
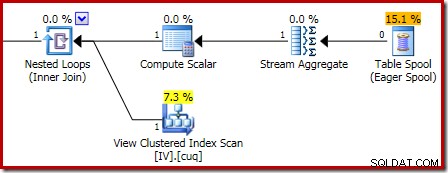
Wenn Sie das obige Korruptionsskript mit einem Löschen anstelle eines Einfügens ausprobieren möchten, finden Sie hier ein Beispiel:
-- No rows match this predicate DELETE dbo.T1 WHERE Value BETWEEN 10 AND 50;
Der Löschvorgang betrifft keine Basistabellenzeilen, ändert jedoch die Summenspalte der indizierten Ansicht auf NULL.
Verallgemeinerung des Fehlers
Sie können sich wahrscheinlich eine beliebige Anzahl von Abfragen zum Einfügen und Löschen von Basistabellen einfallen lassen, die keine Zeilen betreffen und diese indizierte Ansicht beschädigen. Dasselbe grundlegende Problem gilt jedoch für eine breitere Problemklasse als nur Einfügungen und Löschungen, die keine Basistabellenzeilen betreffen.
Es ist zum Beispiel möglich, die gleiche Beschädigung mit einer Einfügung zu erzeugen, die macht Hinzufügen von Zeilen zur Basistabelle. Der wesentliche Bestandteil ist, dass keine hinzugefügten Zeilen für die Ansicht in Frage kommen sollten . Dies führt zu einer leeren Eingabe für das Stream-Aggregat und der korruptionsverursachenden NULL-Zeilenausgabe des folgenden Compute-Skalars.
Eine Möglichkeit, dies zu erreichen, besteht darin, eine WHERE-Klausel in die Ansicht aufzunehmen, die einige der Basistabellenzeilen ablehnt:
ALTER VIEW dbo.IV
WITH SCHEMABINDING
AS
SELECT
TotalSum = SUM(T1.Value),
NumRows = COUNT_BIG(*)
FROM dbo.T1 AS T1
WHERE
-- New!
T1.GroupID BETWEEN 1 AND 3;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.IV (NumRows); Angesichts der neuen Beschränkung für Gruppen-IDs, die in der Ansicht enthalten sind, fügt die folgende Einfügung Zeilen zur Basistabelle hinzu, beschädigt die indizierte Ansicht jedoch immer noch mit einer NULL-Summe:
-- So we can undo
BEGIN TRANSACTION;
-- Show the starting state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- The added row does not qualify for the view
INSERT dbo.T1
(GroupID, Value)
VALUES
(4, 100);
-- Show the final state
SELECT * FROM dbo.IV AS IV OPTION (EXPAND VIEWS);
SELECT * FROM dbo.IV AS IV WITH (NOEXPAND);
-- Undo the damage
ROLLBACK TRANSACTION; Die Ausgabe zeigt die inzwischen bekannte Indexbeschädigung:
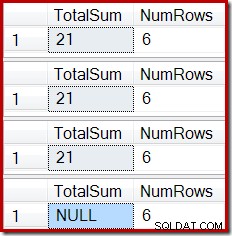
Ein ähnlicher Effekt kann mit einer Ansicht erzielt werden, die einen oder mehrere innere Joins enthält. Solange der Basistabelle hinzugefügte Zeilen zurückgewiesen werden (z. B. durch fehlgeschlagenen Join), erhält das Stream-Aggregat keine Zeilen, der Compute-Skalar generiert eine NULL-Summe und die indizierte Ansicht wird wahrscheinlich beschädigt.
Abschließende Gedanken
Dieses Problem tritt nicht bei Update-Anfragen auf (zumindest soweit ich das beurteilen kann), aber dies scheint eher ein Zufall als ein Design zu sein – das problematische Stream Aggregate ist immer noch in potenziell anfälligen Update-Plänen vorhanden, aber der Compute Scalar, der generiert die NULL-Summe wird nicht hinzugefügt (oder vielleicht wegoptimiert). Bitte teilen Sie mir mit, ob Sie den Fehler mit einer Update-Anfrage reproduzieren können.
Bis dieser Fehler behoben ist (oder vielleicht skalare Aggregate in indizierten Ansichten nicht mehr zulässig sind), seien Sie sehr vorsichtig bei der Verwendung von Aggregaten in einer indizierten Ansicht ohne eine GROUP BY-Klausel.
Dieser Artikel wurde durch ein Connect-Element veranlasst, das von Vladimir Moldovanenko eingereicht wurde, der so freundlich war, einen Kommentar zu einem alten Blog-Beitrag von mir zu hinterlassen (der eine andere Beschädigung der indizierten Ansicht betrifft, die durch die MERGE-Anweisung verursacht wurde). Vladimir hat aus vernünftigen Gründen skalare Aggregate in einer indizierten Ansicht verwendet, also beurteilen Sie diesen Fehler nicht zu schnell als Grenzfall, auf den Sie in einer Produktionsumgebung niemals stoßen werden! Mein Dank geht an Vladimir, dass er mich auf sein Connect-Objekt aufmerksam gemacht hat.