Der Typ und die Anzahl der während der Abfrageausführung erworbenen und freigegebenen Sperren kann überraschende Auswirkungen auf die Leistung haben (bei Verwendung einer Isolationsstufe für Sperren wie dem standardmäßigen Read Committed), selbst wenn kein Warten oder Blockieren auftritt. Es gibt keine Informationen in Ausführungsplänen, die die Menge an Sperraktivitäten während der Ausführung angeben, was es schwieriger macht, zu erkennen, wenn übermäßige Sperren ein Leistungsproblem verursachen.
Um einige weniger bekannte Sperrverhalten in SQL Server zu untersuchen, werde ich die Abfragen und Beispieldaten aus meinem letzten Beitrag zur Berechnung von Medianen wiederverwenden. In diesem Beitrag erwähnte ich, dass der OFFSET Die gruppierte Medianlösung benötigte ein explizites PAGLOCK Verriegelungshinweis, um zu vermeiden, dass der verschachtelte Cursor zu stark verloren geht Lösung, also schauen wir uns zunächst die Gründe dafür im Detail an.
Die OFFSET gruppierte Median-Lösung
Der gruppierte Mediantest verwendete die Beispieldaten aus Aaron Bertrands früherem Artikel wieder. Das folgende Skript stellt dieses Millionen-Zeilen-Setup nach, das aus zehntausend Datensätzen für jeden von hundert imaginären Vertriebsmitarbeitern besteht:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
Der SQL Server 2012 (und höher) OFFSET Die von Peter Larsson erstellte Lösung lautet wie folgt (ohne Sperrhinweise):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Die wichtigen Teile des Post-Execution-Plans sind unten aufgeführt:

Mit allen erforderlichen Daten im Arbeitsspeicher wird diese Abfrage in 580 ms ausgeführt im Durchschnitt auf meinem Laptop (mit SQL Server 2014 Service Pack 1). Die Leistung dieser Abfrage kann auf 320 ms verbessert werden einfach durch Hinzufügen eines Sperrhinweises für die Seitengranularität zur Sales-Tabelle in der Apply-Unterabfrage:
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
(SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK) -- NEW!
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Der Ausführungsplan ist unverändert (na ja, abgesehen von dem Sperrhinweistext in Showplan-XML natürlich):
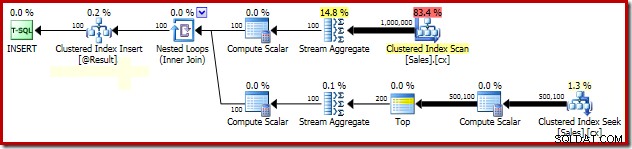
Gruppierte Median-Locking-Analyse
Die Erklärung für die dramatische Leistungssteigerung durch PAGLOCK hint ist ganz einfach, zumindest anfangs.
Wenn wir die Sperraktivität während der Ausführung dieser Abfrage manuell überwachen, sehen wir, dass SQL Server ohne den Granularitätshinweis für Seitensperren über eine halbe Million Sperren auf Zeilenebene erwirbt und freigibt beim Suchen des Clustered-Index. Es gibt keine Schuld an der Blockierung; Das einfache Anfordern und Freigeben dieser vielen Sperren fügt der Ausführung dieser Abfrage einen erheblichen Overhead hinzu. Durch das Anfordern von Sperren auf Seitenebene wird die Sperraktivität erheblich reduziert, was zu einer erheblich verbesserten Leistung führt.
Das Sperrleistungsproblem dieses speziellen Plans beschränkt sich auf die Clustered-Index-Suche im obigen Plan. Der vollständige Scan des Clustered-Index (der verwendet wird, um die Anzahl der Zeilen zu berechnen, die für jeden Vertriebsmitarbeiter vorhanden sind) verwendet automatisch Sperren auf Seitenebene. Dies ist ein interessanter Punkt. Das detaillierte Sperrverhalten der SQL Server-Engine ist nicht in großem Umfang in der Onlinedokumentation dokumentiert, aber verschiedene Mitglieder des SQL Server-Teams haben im Laufe der Jahre einige allgemeine Bemerkungen gemacht, einschließlich der Tatsache, dass die uneingeschränkten Scans dazu neigen, Seiten zu erfassen Sperren, wohingegen kleinere Operationen dazu neigen, mit Zeilensperren zu beginnen.
Der Abfrageoptimierer stellt der Speicher-Engine einige Informationen zur Verfügung, darunter Kardinalitätsschätzungen, interne Hinweise für die Isolationsstufe und Sperrgranularität, welche internen Optimierungen sicher angewendet werden können und so weiter. Auch diese Details sind nicht in Books Online dokumentiert. Am Ende verwendet die Speicher-Engine eine Vielzahl von Informationen, um zu entscheiden, welche Sperren zur Laufzeit erforderlich sind und mit welcher Granularität sie vorgenommen werden sollten.
Als Nebenbemerkung, und denken Sie daran, dass wir über eine Abfrage sprechen, die unter der standardmäßigen Isolationsstufe für sperrende, festgeschriebene Transaktionen ausgeführt wird, beachten Sie, dass die ohne den Granularitätshinweis vorgenommenen Zeilensperren in diesem Fall nicht zu einer Tabellensperre eskalieren. Dies liegt daran, dass das normale Verhalten beim Read Committed darin besteht, die vorherige Sperre kurz vor dem Erwerb der nächsten Sperre freizugeben, was bedeutet, dass zu einem bestimmten Zeitpunkt nur eine einzige gemeinsam genutzte Zeilensperre (mit den zugehörigen beabsichtigten gemeinsam genutzten Sperren auf höherer Ebene) gehalten wird. Da die Anzahl der gleichzeitig gehaltenen Zeilensperren den Schwellenwert nie erreicht, wird keine Sperreneskalation versucht.
Die OFFSET-Single-Median-Lösung
Der Leistungstest für eine einzelne Medianberechnung verwendet einen anderen Satz von Beispieldaten, die wiederum aus Aarons früherem Artikel reproduziert wurden. Das folgende Skript erstellt eine Tabelle mit zehn Millionen Zeilen pseudozufälliger Daten:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
Der OFFSET Lösung ist:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Der Nachausführungsplan lautet:

Diese Abfrage wird in 910 ms ausgeführt im Durchschnitt auf meiner Testmaschine. Die Leistung bleibt unverändert, wenn ein PAGLOCK Hinweis wurde hinzugefügt, aber der Grund dafür ist nicht das, was Sie vielleicht denken ...
Single-Median-Locking-Analyse
Möglicherweise erwarten Sie aufgrund des Clustered-Index-Scans sowieso, dass die Speicher-Engine gemeinsame Sperren auf Seitenebene auswählt, was erklärt, warum ein PAGLOCK Hinweis hat keine Wirkung. Tatsächlich zeigt die Überwachung der Sperren, die während der Ausführung dieser Abfrage genommen werden, dass überhaupt keine gemeinsamen Sperren (S) genommen werden, in jeder Granularität . Die einzigen getroffenen Sperren sind Intent-Shared (IS) auf Objekt- und Seitenebene.
Die Erklärung für dieses Verhalten besteht aus zwei Teilen. Als Erstes fällt auf, dass der Clustered Index Scan im Ausführungsplan unter einem Top-Operator liegt. Dies hat eine wichtige Auswirkung auf Kardinalitätsschätzungen, wie im (geschätzten) Plan vor der Ausführung gezeigt:

Der OFFSET und FETCH Klauseln in der Abfrage verweisen auf einen Ausdruck und eine Variable, sodass der Abfrageoptimierer die Anzahl der Zeilen schätzt, die zur Laufzeit benötigt werden. Die Standardschätzung für Top ist einhundert Zeilen. Dies ist natürlich eine schreckliche Vermutung, aber es reicht aus, um die Speicher-Engine davon zu überzeugen, auf Zeilengranularität statt auf Seitenebene zu sperren.
Wenn wir den „Zeilenziel“-Effekt des Top-Operators mithilfe des dokumentierten Trace-Flags 4138 deaktivieren, ändert sich die geschätzte Anzahl der Zeilen beim Scan auf zehn Millionen (was immer noch falsch ist, aber in die andere Richtung). Dies reicht aus, um die Granularitätsentscheidung der Speicher-Engine für die Sperrung zu ändern, sodass gemeinsame Sperren auf Seitenebene (Anmerkung:keine beabsichtigten gemeinsamen Sperren) vorgenommen werden:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1
OPTION (QUERYTRACEON 4138); -- NEW!
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Der unter Trace-Flag 4138 erstellte geschätzte Ausführungsplan lautet:

Zurück zum Hauptbeispiel:Die Hundert-Zeilen-Schätzung aufgrund des geschätzten Zeilenziels bedeutet, dass die Speicher-Engine sich entscheidet, auf Zeilenebene zu sperren. Allerdings beobachten wir Intent-Shared (IS)-Sperren nur auf Tabellen- und Seitenebene. Diese Sperren auf höherer Ebene wären ganz normal, wenn wir gemeinsam genutzte Sperren (S) auf Zeilenebene sehen würden. Wo sind sie also geblieben?
Die Antwort ist, dass die Speicher-Engine eine weitere Optimierung enthält, die unter bestimmten Umständen die gemeinsamen Sperren auf Zeilenebene überspringen kann. Wenn diese Optimierung angewendet wird, werden die Intent-Shared-Locks auf höherer Ebene weiterhin erworben.
Zusammenfassend für die Single-Median-Abfrage:
- Die Verwendung einer Variablen und eines Ausdrucks im
OFFSET-Klausel bedeutet, dass der Optimierer die Kardinalität schätzt. - Die niedrige Schätzung bedeutet, dass die Speicher-Engine sich für eine Sperrstrategie auf Zeilenebene entscheidet.
- Eine interne Optimierung bedeutet, dass die S-Sperren auf Zeilenebene zur Laufzeit übersprungen werden und nur die IS-Sperren auf Seiten- und Objektebene übrig bleiben.
Die einzelne Median-Abfrage hätte das gleiche Leistungsproblem beim Zeilensperren gehabt wie der gruppierte Median (aufgrund der ungenauen Schätzung des Abfrageoptimierers), aber sie wurde durch eine separate Speicher-Engine-Optimierung eingespart, die dazu führte, dass nur Seiten- und Tabellensperren mit gemeinsamer Absicht vorgenommen wurden zur Laufzeit.
Der gruppierte Median-Test erneut besucht
Sie fragen sich vielleicht, warum der Clustered Index Seek im gruppierten Mediantest nicht die gleiche Speicher-Engine-Optimierung genutzt hat, um gemeinsame Sperren auf Zeilenebene zu überspringen. Warum wurden so viele gemeinsam genutzte Zeilensperren verwendet, wodurch das PAGLOCK Hinweis nötig?
Die kurze Antwort lautet, dass diese Optimierung für INSERT...SELECT nicht verfügbar ist Abfragen. Wenn wir den SELECT ausführen allein (d.h. ohne die Ergebnisse in eine Tabelle zu schreiben) und ohne PAGLOCK Hinweis, die Optimierung zum Überspringen von Zeilensperren ist angewandt:
DECLARE @s datetime2 = SYSUTCDATETIME();
--DECLARE @Result AS table
--(
-- SalesPerson integer PRIMARY KEY,
-- Median float NOT NULL
--);
--INSERT @Result
-- (SalesPerson, Median)
SELECT
d.SalesPerson,
w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w (Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());
Es werden nur Intent-Shared (IS)-Sperren auf Tabellen- und Seitenebene verwendet, und die Leistung steigt auf das gleiche Niveau wie bei Verwendung von PAGLOCK Hinweis. Dieses Verhalten finden Sie natürlich nicht in der Dokumentation und es kann sich jederzeit ändern. Dennoch ist es gut, sich dessen bewusst zu sein.
Falls Sie sich fragen, hat das Ablaufverfolgungsflag 4138 in diesem Fall keine Auswirkung auf die Wahl der Sperrgranularität der Speicher-Engine, da die geschätzte Anzahl von Zeilen bei der Suche zu niedrig ist (pro Anwendungsiteration), selbst wenn das Zeilenziel deaktiviert ist.
Bevor Sie Rückschlüsse auf die Leistung einer Abfrage ziehen, überprüfen Sie unbedingt die Anzahl und Art der Sperren, die sie während der Ausführung einnimmt. Obwohl SQL Server normalerweise die „richtige“ Granularität wählt, kann es vorkommen, dass etwas schief geht, manchmal mit dramatischen Auswirkungen auf die Leistung.