Der schnellste Weg, einen Median zu berechnen, verwendet den SQL Server 2012 OFFSET Erweiterung zu ORDER BY Klausel. Die nächstschnellere Lösung, die knapp an zweiter Stelle läuft, verwendet einen (möglicherweise verschachtelten) dynamischen Cursor, der auf allen Versionen funktioniert. Dieser Artikel befasst sich mit einer häufig vorkommenden ROW_NUMBER vor 2012 Lösung des Median-Berechnungsproblems, um zu sehen, warum es weniger gut abschneidet und was getan werden kann, um es schneller zu machen.
Einzelner Mediantest
Die Beispieldaten für diesen Test bestehen aus einer einzelnen Tabelle mit zehn Millionen Zeilen (reproduziert aus dem Originalartikel von Aaron Bertrand):
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id); Die OFFSET-Lösung
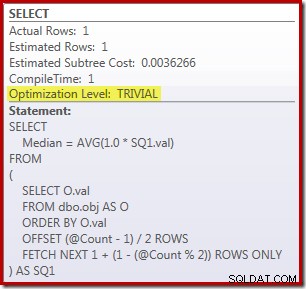
Um Maßstäbe zu setzen, ist hier die von Peter Larsson erstellte OFFSET-Lösung für SQL Server 2012 (oder höher):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - (@Count % 2)) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Die Abfrage zum Zählen der Zeilen in der Tabelle wird auskommentiert und durch einen hartcodierten Wert ersetzt, um sich auf die Leistung des Kerncodes zu konzentrieren. Wenn ein warmer Cache und die Erfassung von Ausführungsplänen deaktiviert sind, wird diese Abfrage 910 ms ausgeführt im Durchschnitt auf meiner Testmaschine. Der Ausführungsplan ist unten dargestellt:

Als Randbemerkung ist es interessant, dass diese mäßig komplexe Abfrage für einen trivialen Plan geeignet ist:
Die ROW_NUMBER-Lösung
Für Systeme, auf denen SQL Server 2008 R2 oder früher ausgeführt wird, verwendet die leistungsstärkste der alternativen Lösungen einen dynamischen Cursor, wie zuvor erwähnt. Wenn Sie dies nicht als Option in Betracht ziehen können (oder wollen), ist es natürlich, darüber nachzudenken, den OFFSET von 2012 zu emulieren Ausführungsplan mit ROW_NUMBER .
Die Grundidee besteht darin, die Zeilen in der richtigen Reihenfolge zu nummerieren und dann nur nach den ein oder zwei Zeilen zu filtern, die zur Berechnung des Medians benötigt werden. Es gibt mehrere Möglichkeiten, dies in Transact SQL zu schreiben; Eine kompakte Version, die alle Schlüsselelemente erfasst, lautet wie folgt:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
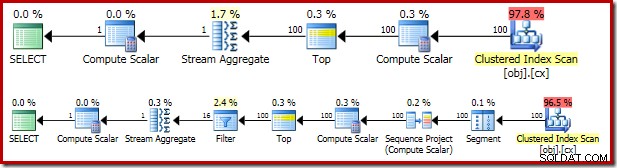
Der resultierende Ausführungsplan ist dem OFFSET ziemlich ähnlich Version:

Es lohnt sich, sich jeden der Planoperatoren der Reihe nach anzusehen, um sie vollständig zu verstehen:
- Der Segmentoperator ist in diesem Plan überflüssig. Es wäre erforderlich, wenn
ROW_NUMBERRanking-Funktion hatte einenPARTITION BYKlausel, tut es aber nicht. Trotzdem bleibt es im endgültigen Plan. - Das Sequence-Projekt fügt dem Zeilenstrom eine berechnete Zeilennummer hinzu.
- Der Compute Scalar definiert einen Ausdruck, der mit der Notwendigkeit verbunden ist, den
valimplizit zu konvertieren Spalte zu numerisch, damit sie mit dem konstanten Literal1.0multipliziert werden kann in der Abfrage. Diese Berechnung wird verschoben, bis sie von einem späteren Operator (der zufällig das Stream-Aggregat ist) benötigt wird. Diese Laufzeitoptimierung bedeutet, dass die implizite Konvertierung nur für die zwei Zeilen durchgeführt wird, die vom Stream Aggregate verarbeitet werden, nicht für die 5.000.001 Zeilen, die für den Compute-Skalar angegeben sind. - Der Top-Operator wird vom Abfrageoptimierer eingeführt. Es erkennt damit höchstens nur den ersten
(@Count + 2) / 2Zeilen werden von der Abfrage benötigt. Wir hätten einenTOP ... ORDER BYhinzufügen können in der Unterabfrage, um dies explizit zu machen, aber diese Optimierung macht das weitgehend unnötig. - Der Filter implementiert die Bedingung im
WHERE-Klausel, wobei alle bis auf die zwei "mittleren" Zeilen herausgefiltert werden, die zur Berechnung des Medians benötigt werden (das eingeführte Top basiert ebenfalls auf dieser Bedingung). - Das Stream Aggregate berechnet die
SUMundCOUNTder beiden mittleren Reihen. - Der abschließende Berechnungsskalar berechnet den Durchschnitt aus der Summe und der Anzahl.
Rohleistung
Verglichen mit dem OFFSET Plan, können wir erwarten, dass die zusätzlichen Segment-, Sequenzprojekt- und Filteroperatoren einige nachteilige Auswirkungen auf die Leistung haben werden. Es lohnt sich, sich einen Moment Zeit zu nehmen, um die Schätzung zu vergleichen Kosten der beiden Pläne:
Der OFFSET Plan hat geschätzte Kosten von 0,0036266 Einheiten, während die ROW_NUMBER Plan wird auf 0,0036744 geschätzt Einheiten. Dies sind sehr kleine Zahlen, und es gibt kaum einen Unterschied zwischen den beiden.
Daher ist es vielleicht überraschend, dass die ROW_NUMBER Abfrage läuft tatsächlich für 4000 ms im Durchschnitt, verglichen mit 910 ms Durchschnitt für OFFSET Lösung. Ein Teil dieses Anstiegs lässt sich sicherlich durch den Overhead der zusätzlichen Planbetreiber erklären, aber ein Faktor von vier erscheint übertrieben. Da muss noch mehr dahinterstecken.
Sie haben wahrscheinlich auch bemerkt, dass die Kardinalitätsschätzungen für beide geschätzten Pläne oben ziemlich hoffnungslos falsch sind. Dies ist auf die Wirkung der Top-Operatoren zurückzuführen, die einen Ausdruck haben, der auf eine Variable als Begrenzung ihrer Zeilenanzahl verweist. Der Abfrageoptimierer kann den Inhalt von Variablen zum Zeitpunkt der Kompilierung nicht sehen, daher greift er auf seine Standardschätzung von 100 Zeilen zurück. Beide Pläne stoßen zur Laufzeit tatsächlich auf 5.000.001 Zeilen.
Das ist alles sehr interessant, erklärt aber nicht direkt, warum ROW_NUMBER Abfrage ist mehr als viermal langsamer als OFFSET Ausführung. Schließlich ist die 100-Zeilen-Kardinalitätsschätzung in beiden Fällen genauso falsch.
Verbesserung der Leistung der Lösung ROW_NUMBER
In meinem vorherigen Artikel haben wir gesehen, wie die Leistung des gruppierten Medians OFFSET ist test konnte fast verdoppelt werden, indem einfach ein PAGLOCK hinzugefügt wurde Hinweis. Dieser Hinweis überschreibt die normale Entscheidung der Speicher-Engine, gemeinsam genutzte Sperren mit der Zeilengranularität zu erwerben und freizugeben (aufgrund der niedrigen erwarteten Kardinalität).
Als weitere Erinnerung das PAGLOCK Hinweis war im einzelnen Median OFFSET unnötig Test aufgrund einer separaten internen Optimierung, die gemeinsame Sperren auf Zeilenebene überspringen kann, was dazu führt, dass nur eine kleine Anzahl gemeinsam genutzter Sperren auf Seitenebene verwendet wird.
Wir erwarten möglicherweise die ROW_NUMBER Single-Median-Lösung, um von derselben internen Optimierung zu profitieren, tut es aber nicht. Überwachung der Sperraktivität während ROW_NUMBER Abfrage ausgeführt wird, sehen wir über eine halbe Million einzelne gemeinsame Sperren auf Zeilenebene genommen und freigelassen.
Da wir jetzt also wissen, was das Problem ist, können wir die Sperrleistung auf die gleiche Weise wie zuvor verbessern:entweder mit einem PAGLOCK Lock-Granularitätshinweis oder durch Erhöhen der Kardinalitätsschätzung mithilfe des dokumentierten Trace-Flags 4138.
Das Deaktivieren des "Zeilenziels" mithilfe des Ablaufverfolgungsflags ist aus mehreren Gründen die weniger zufriedenstellende Lösung. Erstens ist es nur in SQL Server 2008 R2 oder höher wirksam. Wir würden höchstwahrscheinlich den OFFSET bevorzugen Lösung in SQL Server 2012, sodass die Korrektur des Ablaufverfolgungsflags effektiv nur auf SQL Server 2008 R2 beschränkt ist. Zweitens erfordert das Anwenden des Ablaufverfolgungsflags Berechtigungen auf Administratorebene, es sei denn, es wird über eine Planhinweisliste angewendet. Ein dritter Grund ist, dass das Deaktivieren von Zeilenzielen für die gesamte Abfrage andere unerwünschte Auswirkungen haben kann, insbesondere in komplexeren Plänen.
Im Gegensatz dazu ist das PAGLOCK hint ist effektiv, in allen Versionen von SQL Server ohne besondere Berechtigungen verfügbar und hat keine größeren Nebeneffekte als die Sperrgranularität.
Anwenden des PAGLOCK Hinweis auf ROW_NUMBER Abfrage erhöht die Leistung dramatisch:von 4000 ms bis 1500 ms:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK) -- New!
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT Pre2012 = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Die 1500 ms Ergebnis ist immer noch deutlich langsamer als die 910 ms für den OFFSET Lösung, aber zumindest ist es jetzt im selben Stadion. Der verbleibende Leistungsunterschied ist einfach auf die zusätzliche Arbeit im Ausführungsplan zurückzuführen:

Im OFFSET Plan werden fünf Millionen Zeilen bis zum Anfang verarbeitet (wobei die Ausdrücke, die am Compute-Skalar definiert sind, zurückgestellt werden, wie zuvor besprochen). In der ROW_NUMBER Plan, muss die gleiche Anzahl von Zeilen von Segment, Sequence Project, Top und Filter verarbeitet werden.