In meinem letzten Beitrag habe ich einige effiziente Ansätze zur gruppierten Verkettung gezeigt. Dieses Mal wollte ich über ein paar zusätzliche Facetten dieses Problems sprechen, die wir leicht mit FOR XML PATH erreichen können Ansatz:Sortieren der Liste und Entfernen von Duplikaten.
Ich habe einige Möglichkeiten gesehen, wie Leute die durch Kommas getrennte Liste geordnet haben möchten. Manchmal möchten sie, dass das Element in der Liste alphabetisch geordnet wird; Das habe ich bereits in meinem vorherigen Beitrag gezeigt. Aber manchmal möchten sie, dass es nach einem anderen Attribut sortiert wird, das eigentlich nicht in die Ausgabe eingeführt wird; Zum Beispiel möchte ich die Liste vielleicht zuerst nach dem neuesten Element ordnen. Nehmen wir ein einfaches Beispiel, in dem wir eine Employees-Tabelle und eine CoffeeOrders-Tabelle haben. Lassen Sie uns einfach die Bestellungen einer Person für ein paar Tage auffüllen:
CREATE TABLE dbo.Employees
(
EmployeeID INT PRIMARY KEY,
Name NVARCHAR(128)
);
INSERT dbo.Employees(EmployeeID, Name) VALUES(1, N'Jack');
CREATE TABLE dbo.CoffeeOrders
(
EmployeeID INT NOT NULL REFERENCES dbo.Employees(EmployeeID),
OrderDate DATE NOT NULL,
OrderDetails NVARCHAR(64)
);
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
VALUES(1,'20140801',N'Large double double'),
(1,'20140802',N'Medium double double'),
(1,'20140803',N'Large Vanilla Latte'),
(1,'20140804',N'Medium double double');
Wenn wir den bestehenden Ansatz verwenden, ohne einen ORDER BY anzugeben , erhalten wir eine willkürliche Reihenfolge (in diesem Fall ist es sehr wahrscheinlich, dass Sie die Zeilen in der Reihenfolge sehen, in der sie eingefügt wurden, aber verlassen Sie sich bei größeren Datensätzen, mehr Indizes usw. nicht darauf):
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Ergebnisse (denken Sie daran, dass Sie möglicherweise *andere* Ergebnisse erhalten, es sei denn, Sie geben einen ORDER BY an ):
Jack | Großes Doppel-Doppel, Medium-Doppel-Doppel, Large Vanilla Latte, Medium-Doppel-Doppel
Wenn wir die Liste alphabetisch ordnen wollen, ist es einfach; wir fügen einfach ORDER BY c.OrderDetails hinzu :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDetails -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Ergebnisse:
Name | BestellungenJack | Großes Doppelzimmer, Großes Vanilla Latte, Mittleres Doppelzimmer, Mittleres Doppelzimmer
Wir können auch nach einer Spalte sortieren, die nicht in der Ergebnismenge erscheint; Beispielsweise können wir nach der letzten Kaffeebestellung zuerst bestellen:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID ORDER BY c.OrderDate DESC -- only change FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Ergebnisse:
Name | BestellungenJack | Medium Double Double, Large Vanilla Latte, Medium Double Double, Large Double Double
Eine andere Sache, die wir oft tun möchten, ist das Entfernen von Duplikaten; schließlich gibt es wenig Grund, „Medium double double“ zweimal zu sehen. Wir können das beseitigen, indem wir GROUP BY verwenden :
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails -- removed ORDER BY and added GROUP BY here FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Nun, dies *passiert*, um die Ausgabe alphabetisch zu ordnen, aber auch hierauf können Sie sich nicht verlassen:
Name | BestellungenJack | Großes Doppel-Doppel, Großer Vanilla Latte, Mittleres Doppel-Doppel
Wenn Sie diese Bestellung auf diese Weise garantieren möchten, können Sie einfach wieder ein ORDER BY hinzufügen:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDetails -- added ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Die Ergebnisse sind die gleichen (aber ich wiederhole, das ist in diesem Fall nur ein Zufall; wenn Sie diese Reihenfolge wünschen, sagen Sie es immer):
Name | BestellungenJack | Großes Doppel-Doppel, Großer Vanilla Latte, Mittleres Doppel-Doppel
Aber was, wenn wir Duplikate eliminieren *und* die Liste zuerst nach der letzten Kaffeebestellung sortieren wollen? Ihre erste Neigung könnte sein, GROUP BY beizubehalten und ändern Sie einfach den ORDER BY , etwa so:
SELECT e.Name, Orders = STUFF((SELECT N', ' + c.OrderDetails FROM dbo.CoffeeOrders AS c WHERE c.EmployeeID = e.EmployeeID GROUP BY c.OrderDetails ORDER BY c.OrderDate DESC -- changed ORDER BY FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Das wird nicht funktionieren, da das OrderDate wird nicht als Teil der Abfrage gruppiert oder aggregiert:
Spalte „dbo.CoffeeOrders.OrderDate“ ist in der ORDER BY-Klausel ungültig, da sie weder in einer Aggregatfunktion noch in der GROUP BY-Klausel enthalten ist.
Eine Problemumgehung, die die Abfrage zugegebenermaßen etwas hässlicher macht, besteht darin, die Bestellungen zuerst separat zu gruppieren und dann nur die Zeilen mit dem maximalen Datum für diese Kaffeebestellung pro Mitarbeiter zu nehmen:
;WITH grouped AS ( SELECT EmployeeID, OrderDetails, OrderDate = MAX(OrderDate) FROM dbo.CoffeeOrders GROUP BY EmployeeID, OrderDetails ) SELECT e.Name, Orders = STUFF((SELECT N', ' + g.OrderDetails FROM grouped AS g WHERE g.EmployeeID = e.EmployeeID ORDER BY g.OrderDate DESC FOR XML PATH, TYPE).value(N'.[1]', N'nvarchar(max)'), 1, 2, N'') FROM dbo.Employees AS e GROUP BY e.EmployeeID, e.Name;
Ergebnisse:
Name | BestellungenJack | Medium Double Double, Large Vanilla Latte, Large Double Double
Dadurch werden unsere beiden Ziele erreicht:Wir haben Duplikate eliminiert und die Liste nach etwas geordnet, das eigentlich nicht in der Liste enthalten ist.
Leistung
Sie fragen sich vielleicht, wie schlecht diese Methoden gegenüber einem robusteren Datensatz abschneiden. Ich werde unsere Tabelle mit 100.000 Zeilen füllen, sehen, wie sie ohne zusätzliche Indizes auskommt, und dann dieselben Abfragen erneut mit ein wenig Indexoptimierung ausführen, um unsere Abfragen zu unterstützen. Also zuerst 100.000 Zeilen auf 1.000 Mitarbeiter verteilen:
-- clear out our tiny sample data
DELETE dbo.CoffeeOrders;
DELETE dbo.Employees;
-- create 1000 fake employees
INSERT dbo.Employees(EmployeeID, Name)
SELECT TOP (1000)
EmployeeID = ROW_NUMBER() OVER (ORDER BY t.[object_id]),
Name = LEFT(t.name + c.name, 128)
FROM sys.all_objects AS t
INNER JOIN sys.all_columns AS c
ON t.[object_id] = c.[object_id];
-- create 100 fake coffee orders for each employee
-- we may get duplicates in here for name
INSERT dbo.CoffeeOrders(EmployeeID, OrderDate, OrderDetails)
SELECT e.EmployeeID,
OrderDate = DATEADD(DAY, ROW_NUMBER() OVER
(PARTITION BY e.EmployeeID ORDER BY c.[guid]), '20140630'),
LEFT(c.name, 64)
FROM dbo.Employees AS e
CROSS APPLY
(
SELECT TOP (100) name, [guid] = NEWID()
FROM sys.all_columns
WHERE [object_id] < e.EmployeeID
ORDER BY NEWID()
) AS c; Lassen Sie uns jetzt einfach jede unserer Abfragen zweimal ausführen und sehen, wie das Timing beim zweiten Versuch ist (wir machen hier einen Vertrauensvorschuss und gehen davon aus, dass wir – in einer idealen Welt – mit einem vorbereiteten Cache arbeiten werden ). Ich habe diese im SQL Sentry Plan Explorer ausgeführt, da dies der einfachste Weg ist, den ich kenne, um eine Reihe von einzelnen Abfragen zeitlich zu vergleichen und zu vergleichen:
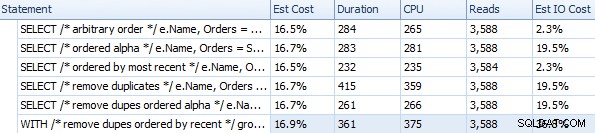 Dauer und andere Laufzeitmetriken für verschiedene FOR XML PATH-Ansätze
Dauer und andere Laufzeitmetriken für verschiedene FOR XML PATH-Ansätze
Diese Timings (Dauer ist in Millisekunden) sind meiner Meinung nach gar nicht so schlecht, wenn man bedenkt, was hier eigentlich gemacht wird. Der komplizierteste Plan, zumindest optisch, schien derjenige zu sein, bei dem wir Duplikate entfernt und nach der neuesten Reihenfolge sortiert haben:
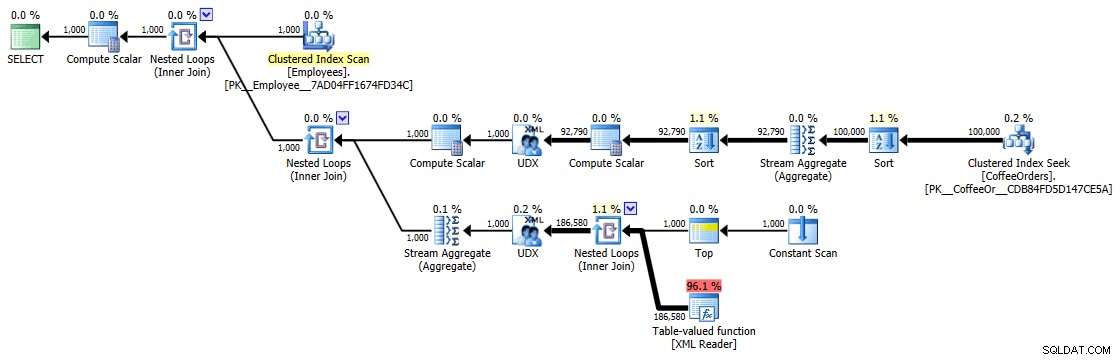 Ausführungsplan für gruppierte und sortierte Abfragen
Ausführungsplan für gruppierte und sortierte Abfragen
Aber selbst der teuerste Operator hier – die XML-Tabellenwertfunktion – scheint nur CPU zu sein (obwohl ich offen zugeben werde, dass ich nicht sicher bin, wie viel der tatsächlichen Arbeit in den Details des Abfrageplans offengelegt wird):
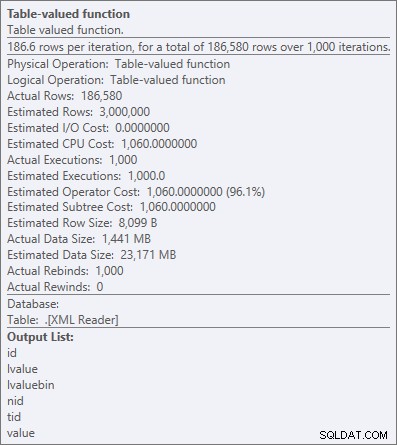 Operatoreigenschaften für die XML-Tabellenwertfunktion
Operatoreigenschaften für die XML-Tabellenwertfunktion
"Alle CPU" ist normalerweise in Ordnung, da die meisten Systeme E/A-gebunden und/oder speichergebunden und nicht CPU-gebunden sind. Wie ich oft sage, tausche ich in den meisten Systemen an jedem Tag der Woche etwas von meinem CPU-Headroom gegen Speicher oder Festplatte (einer der Gründe, warum ich OPTION (RECOMPILE) mag als Lösung für allgegenwärtige Parameter-Sniffing-Probleme).
Ich empfehle Ihnen jedoch dringend, diese Ansätze mit ähnlichen Ergebnissen zu testen, die Sie mit dem CLR-Ansatz GROUP_CONCAT auf CodePlex erzielen können, sowie die Aggregation und Sortierung auf der Präsentationsebene durchzuführen (insbesondere, wenn Sie die normalisierten Daten in irgendeiner Form aufbewahren der Caching-Schicht).