Wenn Sie die Tabellenpartitionierung mit einer oder mehreren Partitionen verwenden, die in einer schreibgeschützten Dateigruppe gespeichert sind, schlagen SQL-Update- und -Löschanweisungen möglicherweise mit einem Fehler fehl. Dies ist natürlich das erwartete Verhalten, wenn eine der Änderungen das Schreiben in eine schreibgeschützte Dateigruppe erfordern würde; Dieser Fehlerzustand kann jedoch auch auftreten, wenn die Änderungen auf Dateigruppen beschränkt sind, die als Lese-/Schreibzugriff gekennzeichnet sind.
Beispieldatenbank
Um das Problem zu demonstrieren, erstellen wir eine einfache Datenbank mit einer einzelnen benutzerdefinierten Dateigruppe, die wir später als schreibgeschützt markieren. Beachten Sie, dass Sie den Dateinamenpfad entsprechend Ihrer Testinstanz hinzufügen müssen.
USE master;
GO
CREATE DATABASE Test;
GO
-- This filegroup will be marked read-only later
ALTER DATABASE Test
ADD FILEGROUP ReadOnlyFileGroup;
GO
-- Add a file to the new filegroup
ALTER DATABASE Test
ADD FILE
(
NAME = 'Test_RO',
FILENAME = '<...your path...>\MSSQL\DATA\Test_ReadOnly.ndf'
)
TO FILEGROUP ReadOnlyFileGroup; Partitionsfunktion und Schema
Wir werden jetzt eine grundlegende Partitionierungsfunktion und ein Schema erstellen, das Zeilen mit Daten vor dem 1. Januar 2000 leitet auf die schreibgeschützte Partition. Spätere Daten werden in der primären Dateigruppe mit Lese- und Schreibzugriff gespeichert:
USE Test;
GO
CREATE PARTITION FUNCTION PF (datetime)
AS RANGE RIGHT
FOR VALUES ({D '2000-01-01'});
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
TO (ReadOnlyFileGroup, [PRIMARY]); Die Range-Right-Spezifikation bedeutet, dass Zeilen mit dem Grenzwert 1. Januar 2000 in der Read-Write-Partition liegen.
Partitionierte Tabelle und Indizes
Wir können jetzt unsere Testtabelle erstellen:
CREATE TABLE dbo.Test
(
dt datetime NOT NULL,
c1 integer NOT NULL,
c2 integer NOT NULL,
CONSTRAINT PK_dbo_Test__c1_dt
PRIMARY KEY CLUSTERED (dt)
ON PS (dt)
)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c1
ON dbo.Test (c1)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c2
ON dbo.Test (c2)
ON PS (dt); Die Tabelle hat einen gruppierten Primärschlüssel in der datetime-Spalte und ist auch in dieser Spalte partitioniert. Es gibt Nonclustered-Indizes für die anderen beiden Integer-Spalten, die auf die gleiche Weise partitioniert sind (die Indizes sind an der Basistabelle ausgerichtet).
Beispieldaten
Schließlich fügen wir ein paar Zeilen mit Beispieldaten hinzu und machen die Datenpartition vor 2000 schreibgeschützt:
INSERT dbo.Test WITH (TABLOCKX)
(dt, c1, c2)
VALUES
({D '1999-12-31'}, 1, 1), -- Read only
({D '2000-01-01'}, 2, 2); -- Writable
GO
ALTER DATABASE Test
MODIFY FILEGROUP
ReadOnlyFileGroup READ_ONLY;
Sie können die folgenden Testaktualisierungsanweisungen verwenden, um zu bestätigen, dass Daten in der schreibgeschützten Partition nicht geändert werden können, während Daten mit einem dt Wert am oder nach dem 1. Januar 2000 kann geschrieben werden an:
-- Will fail, as expected
UPDATE dbo.Test
SET c2 = 1
WHERE dt = {D '1999-12-31'};
-- Will succeed, as expected
UPDATE dbo.Test
SET c2 = 999
WHERE dt = {D '2000-01-01'};
-- Reset the value of c2
UPDATE dbo.Test
SET c2 = 2
WHERE dt = {D '2000-01-01'}; Ein unerwarteter Fehler
Wir haben zwei Zeilen:eine schreibgeschützte (1999-12-31); und ein Lese-/Schreibzugriff (2000-01-01):

Versuchen Sie nun die folgende Abfrage. Es identifiziert dieselbe beschreibbare "2000-01-01"-Zeile, die wir gerade erfolgreich aktualisiert haben, verwendet aber ein anderes Prädikat der Where-Klausel:
UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;
Der geschätzte Plan (vor der Ausführung) lautet:

Die vier (!) Rechenskalare sind für diese Diskussion nicht wichtig. Sie werden verwendet, um zu bestimmen, ob der Nonclustered-Index für jede Zeile beibehalten werden muss, die beim Clustered Index Update-Operator ankommt.
Das Interessantere ist, dass diese Update-Anweisung fehlschlägt mit einem ähnlichen Fehler wie:
Msg 652, Level 16, State 1Der Index „PK_dbo_Test__c1_dt“ für die Tabelle „dbo.Test“ (RowsetId 72057594039042048) befindet sich in einer schreibgeschützten Dateigruppe („ReadOnlyFileGroup“), die nicht geändert werden kann.
Keine Partitionsbeseitigung
Wenn Sie schon einmal mit Partitionierung gearbeitet haben, denken Sie vielleicht, dass „Partitionsbeseitigung“ der Grund sein könnte. Die Logik würde in etwa so aussehen:
In den vorherigen Anweisungen wurde ein Literalwert für die Partitionierungsspalte in der where-Klausel bereitgestellt, sodass SQL Server sofort bestimmen kann, auf welche Partition(en) zugegriffen werden soll. Indem wir die where-Klausel so geändert haben, dass sie nicht mehr auf die Partitionierungsspalte verweist, haben wir SQL Server gezwungen, mit einem Clustered Index Scan auf jede Partition zuzugreifen.
Das ist im Allgemeinen alles richtig, aber es ist nicht der Grund, warum die Update-Anweisung hier fehlschlägt.
Das erwartete Verhalten ist, dass SQL Server lesen können sollte von allen Partitionen während der Abfrageausführung. Eine Datenänderungsoperation sollte nur fehlschlagen wenn die Ausführungsmaschine tatsächlich versucht zu ändern eine Zeile, die in einer schreibgeschützten Dateigruppe gespeichert ist.
Nehmen wir zur Veranschaulichung eine kleine Änderung an der vorherigen Abfrage vor:
UPDATE dbo.Test
SET c2 = 2,
dt = dt
WHERE c1 = 2; Die where-Klausel ist genau die gleiche wie zuvor. Der einzige Unterschied besteht darin, dass wir jetzt (absichtlich) die Partitionierungsspalte gleich sich selbst setzen. Dadurch wird der in dieser Spalte gespeicherte Wert nicht geändert, es wirkt sich jedoch auf das Ergebnis aus. Das Update ist jetzt erfolgreich (allerdings mit einem komplexeren Ausführungsplan):

Der Optimierer hat neue Split-, Sort- und Collapse-Operatoren eingeführt und die Maschinerie hinzugefügt, die notwendig ist, um jeden potenziell betroffenen Nonclustered-Index separat zu verwalten (unter Verwendung einer Wide- oder Per-Index-Strategie).
Die Clustered Index Scan-Eigenschaften zeigen, dass beide Partitionen der Tabelle wurde beim Lesen zugegriffen:
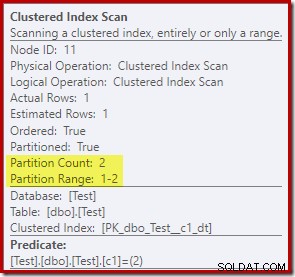
Im Gegensatz dazu zeigt das Clustered Index Update, dass nur auf die Read-Write-Partition zum Schreiben zugegriffen wurde:
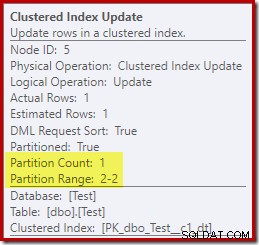
Jeder der Nonclustered Index Update-Operatoren zeigt ähnliche Informationen:Nur die beschreibbare Partition (#2) wurde zur Laufzeit geändert, daher ist kein Fehler aufgetreten.
Der aufgedeckte Grund
Der neue Plan gelingt nicht weil die Nonclustered-Indizes separat verwaltet werden; noch ist es (direkt) aufgrund der Split-Sort-Collapse-Kombination notwendig, um vorübergehende doppelte Schlüsselfehler im eindeutigen Index zu vermeiden.
Der wahre Grund ist etwas, das ich kurz in meinem vorherigen Artikel „Optimieren von Aktualisierungsabfragen“ erwähnt habe – eine interne Optimierung, die als Rowset-Freigabe bekannt ist . Wenn dies verwendet wird, nutzt das Clustered Index Update dasselbe zugrunde liegende Speichermodul-Rowset wie ein Clustered Index Scan, Seek oder Key Lookup auf der Leseseite des Plans.
Mit der Rowset-Sharing-Optimierung sucht SQL Server nach Offline- oder schreibgeschützten Dateigruppen beim Lesen. In Plänen, in denen das Clustered Index Update ein separates Rowset verwendet, wird die Offline-/schreibgeschützte Prüfung nur für jede Zeile im Iterator zum Aktualisieren (oder Löschen) durchgeführt.
Undokumentierte Problemumgehungen
Lassen Sie uns zuerst die lustigen, geekigen, aber unpraktischen Dinge aus dem Weg räumen.
Die gemeinsam genutzte Rowset-Optimierung kann nur angewendet werden, wenn die Route von der Clustered-Index-Suche, -Überprüfung oder -Schlüsselsuche eine Pipeline ist . Es sind keine blockierenden oder halbblockierenden Operatoren zulässig. Anders ausgedrückt, jede Zeile muss in der Lage sein, von der Lesequelle zum Schreibziel zu gelangen, bevor die nächste Zeile gelesen wird.
Zur Erinnerung, hier sind die Beispieldaten, die Aussage und der Ausführungsplan für fehlgeschlagen erneut aktualisieren:
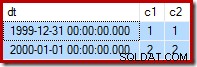
--Change the read-write row UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;

Halloween-Schutz
Eine Möglichkeit, einen blockierenden Operator in den Plan einzuführen, besteht darin, expliziten Halloween-Schutz (HP) für dieses Update zu verlangen. Das Trennen des Lesevorgangs vom Schreibvorgang mit einem Sperroperator verhindert, dass die Rowset-Sharing-Optimierung verwendet wird (keine Pipeline). Das undokumentierte und nicht unterstützte (nur Testsystem!) Trace-Flag 8692 fügt einen Eager Table Spool für explizites HP hinzu:
-- Works (explicit HP) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8692);
Der tatsächliche Ausführungsplan (verfügbar, da der Fehler nicht mehr geworfen wird) ist:

Die Kombination Sortieren in der Split-Sort-Collapse-Kombination, die in der früheren erfolgreichen Aktualisierung zu sehen war, stellt die Blockierung bereit, die zum Deaktivieren der Rowset-Freigabe in diesem Fall erforderlich ist.
Das Anti-Rowset-Sharing-Trace-Flag
Es gibt ein weiteres undokumentiertes Ablaufverfolgungsflag, das die Optimierung der Rowset-Freigabe deaktiviert. Dies hat den Vorteil, dass kein möglicherweise teurer Sperroperator eingeführt wird. Es kann natürlich nicht in der Praxis verwendet werden (es sei denn, Sie wenden sich an den Microsoft-Support und erhalten schriftlich eine Empfehlung, es zu aktivieren, nehme ich an). Trotzdem ist hier zur Unterhaltung das Ablaufverfolgungsflag 8746 in Aktion:
-- Works (no rowset sharing) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8746);
Der tatsächliche Ausführungsplan für diese Anweisung lautet:

Experimentieren Sie gerne mit verschiedenen Werten (solche, die die gespeicherten Werte tatsächlich ändern, wenn Sie möchten), um sich hier von dem Unterschied zu überzeugen. Wie in meinem vorherigen Beitrag erwähnt, können Sie auch das undokumentierte Trace-Flag 8666 verwenden, um die Rowset-Sharing-Eigenschaft im Ausführungsplan verfügbar zu machen.
Wenn Sie den Rowset-Sharing-Fehler mit einer delete-Anweisung sehen möchten, ersetzen Sie einfach die update- und set-Klauseln durch eine delete, während Sie dieselbe where-Klausel verwenden.
Unterstützte Problemumgehungen
Es gibt eine Reihe von Möglichkeiten, um sicherzustellen, dass die Rowset-Freigabe nicht in realen Abfragen angewendet wird, ohne Ablaufverfolgungsflags zu verwenden. Jetzt, da Sie wissen, dass das Kernproblem einen Lese- und Schreibplan für gemeinsam genutzte und geclusterte Indizes erfordert, können Sie sich wahrscheinlich Ihren eigenen ausdenken. Trotzdem gibt es ein paar Beispiele, die hier besonders sehenswert sind.
Erzwungener Index / Deckungsindex
Eine natürliche Idee besteht darin, die Leseseite des Plans zu zwingen, einen nicht gruppierten Index anstelle des gruppierten Index zu verwenden. Wir können der Testabfrage wie geschrieben keinen Indexhinweis direkt hinzufügen, aber Aliasing der Tabelle erlaubt dies:
UPDATE T SET c2 = 2 FROM dbo.Test AS T WITH (INDEX(IX_dbo_Test_c1)) WHERE c1 = 2;
Dies scheint die Lösung zu sein, die der Abfrageoptimierer von Anfang an hätte wählen sollen, da wir einen nicht gruppierten Index für die Prädikatspalte c1 der where-Klausel haben. Der Ausführungsplan zeigt, warum der Optimierer so entschieden hat:
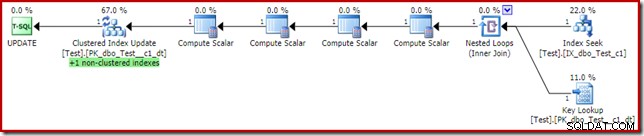
Die Kosten für die Schlüsselsuche reichen aus, um den Optimierer davon zu überzeugen, den Clustered-Index zum Lesen zu verwenden. Die Suche wird benötigt, um den aktuellen Wert von Spalte c2 abzurufen, damit die Compute Scalars entscheiden können, ob der Nonclustered-Index beibehalten werden muss.
Das Hinzufügen von Spalte c2 zum Nonclustered-Index (Schlüssel oder Include) würde das Problem vermeiden. Der Optimierer würde statt des geclusterten Index den jetzt abdeckenden Index wählen.
Allerdings ist es nicht immer möglich, vorauszusehen, welche Spalten benötigt werden, oder sie alle einzubeziehen, selbst wenn der Satz bekannt ist. Denken Sie daran, dass die Spalte benötigt wird, weil c2 in der set-Klausel steht der Update-Anweisung. Wenn die Abfragen Ad-hoc sind (z. B. von Benutzern gesendet oder von einem Tool generiert), müsste jeder nicht gruppierte Index alle Spalten enthalten, um dies zu einer robusten Option zu machen.
Eine interessante Sache am obigen Plan mit der Schlüsselsuche ist, dass dies nicht der Fall ist einen Fehler erzeugen. Dies gilt trotz der Schlüsselsuche und Clustered-Index-Aktualisierung unter Verwendung eines freigegebenen Rowsets. Der Grund dafür ist, dass der Nonclustered Index Seek die Zeile mit c1 =2 vorher findet die Schlüsselsuche berührt den gruppierten Index. Die freigegebene Rowset-Prüfung für Offline-/schreibgeschützte Dateigruppen wird weiterhin bei der Suche durchgeführt, berührt jedoch nicht die schreibgeschützte Partition, sodass kein Fehler ausgegeben wird. Beachten Sie als letzten (verwandten) Punkt von Interesse, dass die Indexsuche beide Partitionen berührt, die Schlüsselsuche jedoch nur eine trifft.
Ausschließen der schreibgeschützten Partition
Eine triviale Lösung besteht darin, sich auf die Eliminierung von Partitionen zu verlassen, sodass die Leseseite des Plans niemals die schreibgeschützte Partition berührt. Dies kann mit einem expliziten Prädikat erfolgen, zum Beispiel mit einem der folgenden:
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND dt >= {D '2000-01-01'};
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND $PARTITION.PF(dt) > 1; -- Not partition #1 Wenn es unmöglich oder unbequem ist, jede Abfrage so zu ändern, dass sie ein Prädikat zur Partitionsbeseitigung hinzufügt, können andere Lösungen wie das Aktualisieren über eine Ansicht geeignet sein. Zum Beispiel:
CREATE VIEW dbo.TestWritablePartitions
WITH SCHEMABINDING
AS
-- Only the writable portion of the table
SELECT
T.dt,
T.c1,
T.c2
FROM dbo.Test AS T
WHERE
$PARTITION.PF(dt) > 1;
GO
-- Succeeds
UPDATE dbo.TestWritablePartitions
SET c2 = 2
WHERE c1 = 2; Ein Nachteil der Verwendung einer Ansicht besteht darin, dass eine Aktualisierung oder Löschung, die auf den schreibgeschützten Teil der Basistabelle abzielt, erfolgreich ist, ohne dass Zeilen betroffen sind, anstatt mit einem Fehler fehlzuschlagen. Ein Anstatt-Trigger auf der Tabelle oder Ansicht könnte in einigen Situationen eine Problemumgehung dafür sein, kann aber auch mehr Probleme mit sich bringen … aber ich schweife ab.
Wie bereits erwähnt, gibt es viele mögliche unterstützte Lösungen. Der Zweck dieses Artikels besteht darin, zu zeigen, wie die Rowset-Freigabe den unerwarteten Aktualisierungsfehler verursacht hat.