Kürzlich war ich an der Entwicklung der Funktionalität beteiligt, die eine schnelle und häufige Übertragung großer Datenmengen auf Disc erforderte. Außerdem sollten diese Daten von Zeit zu Zeit von der Platte gelesen werden. Daher war ich dazu bestimmt, den Ort, die Art und Weise und die Mittel zum Speichern dieser Daten herauszufinden. In diesem Artikel werde ich die Aufgabe kurz wiederholen und Lösungen für die Erfüllung dieser Aufgabe untersuchen und vergleichen.
Kontext der Aufgabe :Ich arbeite in einem Team, das Tools für die Entwicklung relativer Datenbanken entwickelt (SQL Server, MySQL, Oracle). Die Toolpalette umfasst sowohl eigenständige Tools als auch Add-Ins für MS SSMS.
Aufgabe :Wiederherstellen von Dokumenten, die zum Zeitpunkt des Schließens von IDE geöffnet waren, beim nächsten Start von IDE.
Anwendungsfall :Um IDE schnell zu schließen, bevor Sie das Büro verlassen, ohne darüber nachzudenken, welche Dokumente gespeichert wurden und welche nicht. Beim nächsten Start von IDE müssen wir dieselbe Umgebung wie beim Schließen erhalten und die Arbeit fortsetzen. Alle Arbeitsergebnisse sind im Moment der ordnungswidrigen Stilllegung aufzubewahren, z.B. beim Absturz eines Programms oder Betriebssystems oder beim Ausschalten.
Aufgabenanalyse :Die ähnliche Funktion ist in Webbrowsern vorhanden. Browser speichern jedoch nur URLs, die aus ungefähr 100 Symbolen bestehen. In unserem Fall müssen wir den gesamten Dokumentinhalt speichern. Daher benötigen wir einen Ort zum Speichern und Speichern von Benutzerdokumenten. Außerdem arbeiten Benutzer mit SQL manchmal anders als mit anderen Sprachen. Wenn ich zum Beispiel eine C#-Klasse mit mehr als 1000 Zeilen schreibe, ist das kaum akzeptabel. Während im SQL-Universum neben 10-20-Zeilen-Abfragen die monströsen Datenbank-Dumps existieren. Solche Dumps können kaum bearbeitet werden, was bedeutet, dass Benutzer ihre Änderungen lieber sicher aufbewahren möchten.
Anforderungen an einen Speicher:
- Es sollte eine leichtgewichtige eingebettete Lösung sein.
- Es sollte eine hohe Schreibgeschwindigkeit haben.
- Es sollte eine Option für den Multiprocessing-Zugriff haben. Diese Anforderung ist nicht kritisch, da wir den Zugriff mit Hilfe der Synchronisationsobjekte sicherstellen können, aber es wäre trotzdem schön, diese Option zu haben.
Kandidaten
Der erste Kandidat ist ziemlich ungeschickt, nämlich alles in einem Ordner zu speichern, irgendwo in AppData.
Der zweite Kandidat liegt auf der Hand – SQLite, ein Standard eingebetteter Datenbanken. Sehr solider und beliebter Kandidat.
Der dritte Kandidat ist die LiteDB-Datenbank. Es ist das erste Ergebnis für die Suchanfrage „Embedded Database for .net“ in Google.
Erster Anblick
Dateisystem. Dateien sind Dateien, sie müssen gepflegt und richtig benannt werden. Neben dem Dateiinhalt müssen wir eine kleine Reihe von Eigenschaften speichern (ursprünglicher Pfad auf der Disc, Verbindungszeichenfolge, Version der IDE, in der sie geöffnet wurde). Das bedeutet, dass wir entweder zwei Dateien für ein Dokument erstellen oder ein Format erfinden müssen, das Eigenschaften von Inhalten trennt.
SQLite ist eine klassische relationale Datenbank. Die Datenbank wird durch eine Datei auf der Disc dargestellt. Diese Datei wird mit dem Datenbankschema verbunden, wonach wir mit Hilfe der SQL-Mittel damit interagieren müssen. Wir können 2 Tabellen erstellen, eine für Eigenschaften und die andere für Inhalte, falls wir Eigenschaften oder Inhalte separat verwenden müssen.
LiteDB ist eine nicht relationale Datenbank. Ähnlich wie bei SQLite wird die Datenbank durch eine einzelne Datei dargestellt. Es ist vollständig in С# geschrieben. Es hat eine fesselnde Benutzerfreundlichkeit:Wir müssen der Bibliothek nur ein Objekt geben, während die Serialisierung mit eigenen Mitteln durchgeführt wird.
Leistungstest
Bevor ich Code bereitstelle, möchte ich das allgemeine Konzept erläutern und Vergleichsergebnisse liefern.
Das allgemeine Konzept vergleicht die Geschwindigkeit beim Schreiben einer großen Menge kleiner Dateien in die Datenbank, die durchschnittliche Menge durchschnittlicher Dateien und eine kleine Menge großer Dateien. Der Fall mit durchschnittlichen Dateien ist meist nah am realen Fall, während Fälle mit kleinen und großen Dateien Grenzfälle sind, die ebenfalls berücksichtigt werden müssen.
Ich habe mit Hilfe von FileStream Inhalte mit der Standardpuffergröße in eine Datei geschrieben.
Es gab eine Nuance in SQLite, die ich erwähnen möchte. Wir waren nicht in der Lage, alle Dokumentinhalte (wie oben erwähnt, können sie sehr groß sein) in eine Datenbankzelle zu packen. Die Sache ist, dass wir zu Optimierungszwecken den Dokumenttext Zeile für Zeile speichern. Das bedeutet, dass wir, um Text in eine einzelne Zelle zu packen, alle Dokumente in eine einzige Zeile packen müssen, was die Menge des verwendeten Arbeitsspeichers verdoppeln würde. Die andere Seite des Problems würde sich beim Lesen von Daten aus der Datenbank zeigen. Deshalb gab es in SQLite eine separate Tabelle, in der Daten zeilenweise gespeichert und mit Hilfe von Fremdschlüsseln mit der Tabelle verknüpft wurden, die nur Dateieigenschaften enthielt. Außerdem ist es mir gelungen, die Datenbank mit Batch Data Insert (mehrere tausend Zeilen gleichzeitig) im OFF-Synchronisationsmodus ohne Protokollierung und innerhalb einer Transaktion zu beschleunigen.
LiteDB hat ein Objekt erhalten, das List unter seinen Eigenschaften hat, und die Bibliothek hat es selbst auf Disc gespeichert.
Während der Entwicklung der Testanwendung habe ich verstanden, dass ich LiteDB bevorzuge. Die Sache ist, dass der Testcode für SQLite mehr als 120 Zeilen benötigt, während Code, der das gleiche Problem in LiteDb löst, nur 20 Zeilen benötigt.
Generierung von Testdaten
FileStrings.cs
interne Klasse FileStrings { private static readonly Random random =new Random(); öffentliche Listenzeichenfolgen { erhalten; einstellen; } =neue Liste(); public int SomeInfo { erhalten; einstellen; } public FileStrings() {} public FileStrings (int id, int minLines, decimal lineIncrement) { SomeInfo =id; int lines =minLines + (int)(id * lineIncrement); for (int i =0; i new FileStrings(f, MIN_NUM_LINES, (MAX_NUM_LINES - MIN_NUM_LINES) / (decimal)NUM_FILES)) .ToList();
SQLite
private static void SaveToDb(List files) { using (var connection =new SQLiteConnection()) { connection.ConnectionString =@"Data Source=data\database.db;FailIfMissing=False;"; Verbindung.Öffnen(); var command =connection.CreateCommand(); command.CommandText =@"CREATE TABLE files(id INTEGER PRIMARY KEY, file_name TEXT);CREATE TABLE strings(id INTEGER PRIMARY KEY, string TEXT, file_id INTEGER, line_number INTEGER);CREATE UNIQUE INDEX strings_file_id_line_number_uindex ON strings(file_id,line_number); PRAGMA synchron =AUS;PRAGMA journal_mode =AUS"; Befehl.ExecuteNonQuery(); var insertFilecommand =connection.CreateCommand(); insertFilecommand.CommandText ="INSERT INTO files(file_name) VALUES(?); SELECT last_insert_rowid();"; insertFilecommand.Parameters.Add(insertFilecommand.CreateParameter()); insertFilecommand.Prepare(); var insertLineCommand =connection.CreateCommand(); insertLineCommand.CommandText ="INSERT INTO strings(string, file_id, line_number) VALUES(?, ?, ?);"; insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter()); insertLineCommand.Prepare(); foreach (var item in files) { using (var tr =connection.BeginTransaction()) { SaveToDb(item, insertFilecommand, insertLineCommand); tr.Commit(); } } } } private static void SaveToDb(FileStrings item, SQLiteCommand insertFileCommand, SQLiteCommand insertLinesCommand) { string fileName =Path.Combine("data", item.SomeInfo + ".sql"); insertFileCommand.Parameters[0].Value =Dateiname; var fileId =insertFileCommand.ExecuteScalar(); int lineIndex =0; foreach (var line in item.Strings) { insertLinesCommand.Parameters[0].Value =line; insertLinesCommand.Parameters[1].Value =fileId; insertLinesCommand.Parameters[2].Value =lineIndex++; insertLinesCommand.ExecuteNonQuery(); } }
LiteDB
private static void SaveToNoSql(List item) { using (var db =new LiteDatabase("data\\litedb.db")) { var data =db.GetCollection("files"); data.EnsureIndex(f => f.SomeInfo); data.Insert(item); } }
Die folgende Tabelle zeigt Durchschnittsergebnisse für mehrere Durchläufe des Testcodes. Während der Modifikationen war die statistische Abweichung kaum wahrnehmbar.
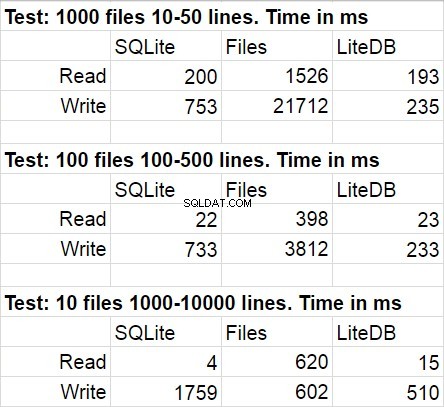
Ich war nicht überrascht, dass LiteDB in diesem Vergleich gewonnen hat. Ich war jedoch schockiert über den Sieg von LiteDB über Dateien. Nach einem kurzen Studium des Bibliotheks-Repositorys fand ich heraus, dass das paginale Schreiben auf Disc sehr sorgfältig implementiert wurde, aber ich bin mir sicher, dass dies nur einer von vielen Performance-Tricks ist, die dort verwendet werden. Eine weitere Sache, auf die ich hinweisen möchte, ist eine schnelle Geschwindigkeitsabnahme des Dateisystemzugriffs, wenn die Menge der Dateien im Ordner sehr groß wird.
Wir haben LiteDB für die Entwicklung unseres Features ausgewählt und diese Wahl kaum bereut. Die Sache ist, dass die Bibliothek für alle C# in nativem C# geschrieben ist, und wenn etwas nicht ganz klar war, konnten wir immer auf den Quellcode verweisen.
Nachteile
Neben den oben genannten Vorteilen von LiteDB im Vergleich zu seinen Konkurrenten sind uns während der Entwicklung auch Nachteile aufgefallen. Die meisten dieser Nachteile können durch die „Jugend“ der Bibliothek erklärt werden. Nachdem wir begonnen hatten, die Bibliothek etwas über die Grenzen des „Standard“-Szenarios hinaus zu verwenden, entdeckten wir mehrere Probleme (Nr. 419, Nr. 420, Nr. 483, Nr. 496). Der Autor der Bibliothek hat ziemlich schnell auf Fragen geantwortet, und die meisten Probleme wurden schnell gelöst. Jetzt ist nur noch eine Aufgabe übrig (nicht zu verwechseln mit dem Status „Geschlossen“). Dies ist eine Frage des wettbewerblichen Zugangs. Es scheint, als ob sich irgendwo tief in der Bibliothek eine sehr böse Rennbedingung versteckt. Wir haben diesen Fehler auf ziemlich originelle Weise übergangen (ich beabsichtige, einen separaten Artikel zu diesem Thema zu schreiben).
Ich möchte auch das Fehlen eines ordentlichen Editors und Viewers erwähnen. Es gibt LiteDBShell, aber nur für echte Konsolenfans.
Zusammenfassung
Wir haben eine große und wichtige Funktionalität über LiteDB aufgebaut, und jetzt arbeiten wir an einem weiteren großen Feature, bei dem wir diese Bibliothek ebenfalls verwenden werden. Für diejenigen, die eine In-Process-Datenbank suchen, empfehle ich, auf LiteDB zu achten und darauf, wie sie sich im Kontext Ihrer Aufgabe bewährt, denn wie Sie wissen, wenn etwas für eine Aufgabe geklappt hätte, würde es nicht unbedingt funktionieren für eine andere Aufgabe trainieren.