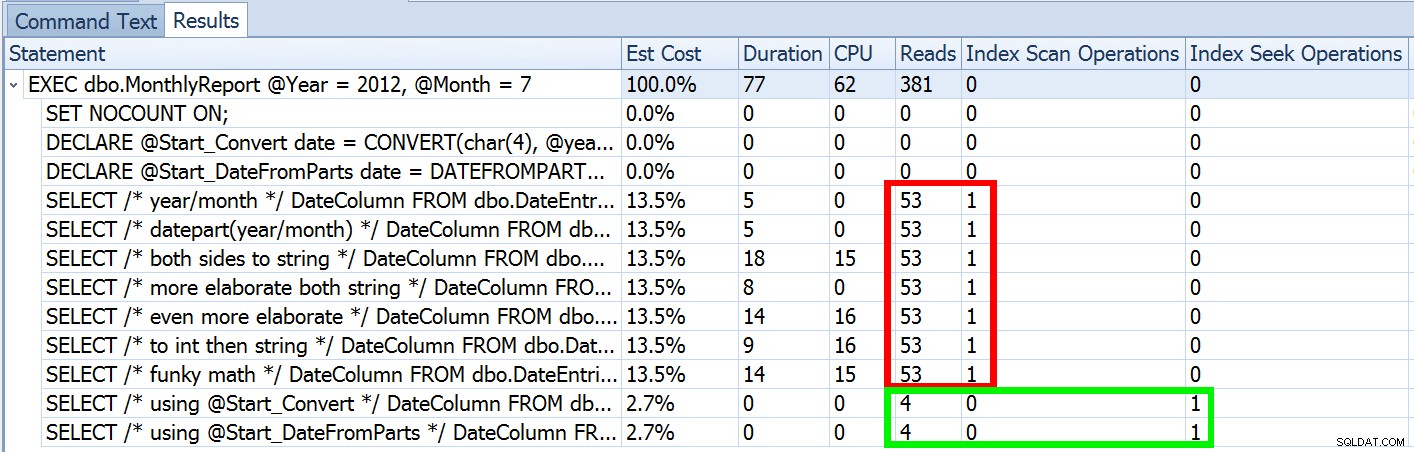
Letzte Woche habe ich einen Beitrag mit dem Titel #BackToBasics :DATEFROMPARTS() veröffentlicht , wo ich gezeigt habe, wie man diese 2012+-Funktion für sauberere, unterteilbare Datumsbereichsabfragen verwendet. Ich habe es verwendet, um zu demonstrieren, dass Sie, wenn Sie ein Datumsprädikat mit offenem Ende verwenden und einen Index für die relevante Datums-/Zeitspalte haben, am Ende eine viel bessere Indexnutzung und weniger I/O (oder im schlimmsten Fall , ebenso, wenn eine Suche aus irgendeinem Grund nicht verwendet werden kann oder wenn kein passender Index existiert):
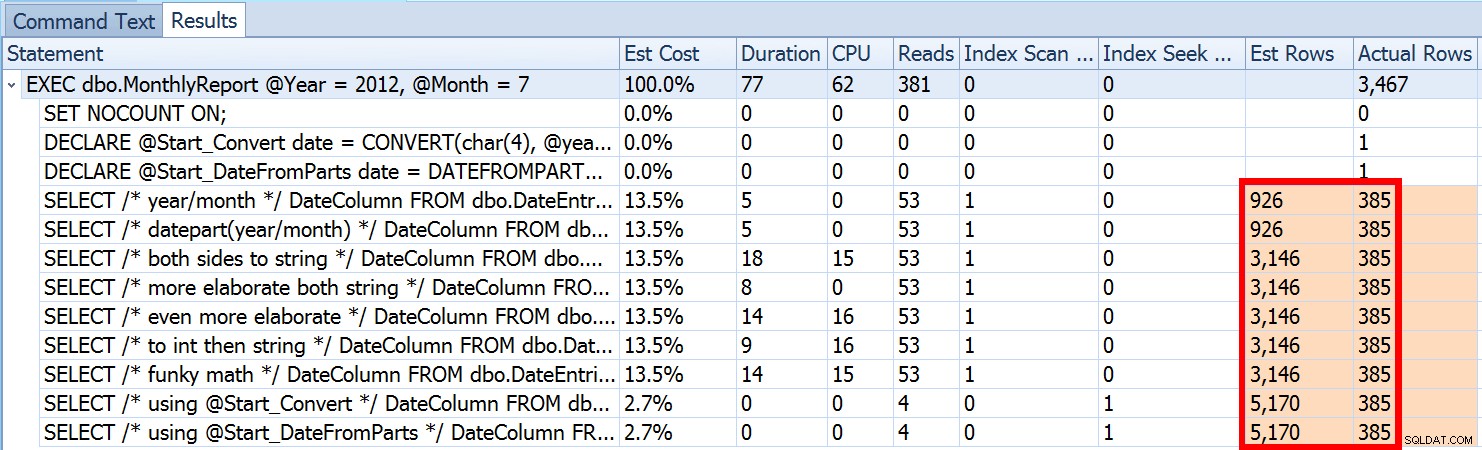
Aber das ist nur ein Teil der Geschichte (und um es klar zu sagen, DATEFROMPARTS() ist technisch nicht erforderlich, um eine Suche zu erhalten, es ist in diesem Fall nur sauberer). Wenn wir etwas herauszoomen, stellen wir fest, dass unsere Schätzungen alles andere als genau sind, eine Komplexität, die ich im vorherigen Beitrag nicht einführen wollte:
Dies ist sowohl bei Ungleichheitsprädikaten als auch bei erzwungenen Scans nicht ungewöhnlich. Und würde die von mir vorgeschlagene Methode nicht natürlich die ungenauesten Statistiken liefern? Hier ist der grundlegende Ansatz (Sie können das Tabellenschema, Indizes und Beispieldaten aus meinem vorherigen Beitrag abrufen):
CREATE PROCEDURE dbo.MonthlyReport_Original
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO Nun sind ungenaue Schätzungen nicht immer ein Problem, aber sie können Probleme mit ineffizienten Planentscheidungen an den beiden Extremen verursachen. Ein einzelner Plan ist möglicherweise nicht optimal, wenn der ausgewählte Bereich einen sehr kleinen oder sehr großen Prozentsatz der Tabelle oder des Index ergibt, und dies kann für SQL Server sehr schwer vorherzusagen sein, wenn die Datenverteilung ungleichmäßig ist. Joseph Sack skizzierte in seinem Beitrag „Zehn häufige Bedrohungen für die Qualität von Ausführungsplänen“ die typischeren Auswirkungen schlechter Schätzungen:
„[…] Bad-Row-Schätzungen können eine Vielzahl von Entscheidungen beeinflussen, darunter Indexauswahl, Such- vs. Scan-Operationen, parallele vs. serielle Ausführung, Join-Algorithmus-Auswahl, innere vs. äußere physische Join-Auswahl (z. B. Build vs. Probe), Spool-Generierung, Lesezeichensuche im Vergleich zu vollständigem Cluster- oder Heap-Tabellenzugriff, Stream- oder Hash-Aggregatauswahl und ob eine Datenänderung einen breiten oder engen Plan verwendet oder nicht.
Es gibt auch andere, wie Speicherzuteilungen, die zu groß oder zu klein sind. Er fährt fort, einige der häufigeren Ursachen für schlechte Schätzungen zu beschreiben, aber die Hauptursache in diesem Fall fehlt in seiner Liste:Schätzwerte. Weil wir eine lokale Variable verwenden, um den eingehenden int zu ändern Parameter zu einem einzigen lokalen date -Variable weiß SQL Server nicht, wie der Wert aussehen wird, und nimmt daher basierend auf der gesamten Tabelle standardisierte Schätzungen der Kardinalität vor.
Wir haben oben gesehen, dass die Schätzung für meinen vorgeschlagenen Ansatz 5.170 Zeilen betrug. Nun wissen wir, dass bei einem Ungleichheitsprädikat und wenn SQL Server die Parameterwerte nicht kennt, 30 % der Tabelle erraten werden. 31,645 * 0.3 ist nicht 5.170. Auch nicht 31,465 * 0.3 * 0.3 , wenn wir uns daran erinnern, dass tatsächlich zwei Prädikate gegen dieselbe Spalte arbeiten. Woher kommt also dieser Wert von 5.170?
Wie Paul White in seinem Beitrag „Cardinality Estimation for Multiple Predicates“ beschreibt, verwendet der neue Kardinalitätsschätzer in SQL Server 2014 exponentielles Backoff, sodass er die Zeilenanzahl der Tabelle (31.465) mit der Selektivität des ersten Prädikats (0,3) multipliziert. , und multipliziert diese dann mit der Quadratwurzel der Selektivität des zweiten Prädikats (~0,547723).
31.645 * (0,3) * SQRT(0,3) ~=5.170,227Jetzt können wir also sehen, woher SQL Server mit seiner Schätzung gekommen ist; Mit welchen Methoden können wir dagegen vorgehen?
- Datumsparameter übergeben. Wenn möglich, können Sie die Anwendung so ändern, dass sie statt separater ganzzahliger Parameter die richtigen Datumsparameter übergibt.
- Verwenden Sie eine Wrapper-Prozedur. Eine Variation von Methode Nr. 1 – zum Beispiel, wenn Sie die Anwendung nicht ändern können – wäre, eine zweite gespeicherte Prozedur zu erstellen, die konstruierte Datumsparameter von der ersten akzeptiert.
- Verwenden Sie
OPTION (RECOMPILE). Zu den geringfügigen Kosten für die Kompilierung bei jeder Ausführung der Abfrage zwingt dies SQL Server dazu, basierend auf den Werten, die jedes Mal präsentiert werden, zu optimieren, anstatt einen einzelnen Plan für unbekannte, erste oder durchschnittliche Parameterwerte zu optimieren. (Für eine gründliche Behandlung dieses Themas siehe Paul Whites "Parameter Sniffing, Embedding, and the RECOMPILE Options."
- Verwenden Sie dynamisches SQL. Wenn dynamisches SQL das konstruierte
dateakzeptiert Variable erzwingt eine korrekte Parametrisierung (so als ob Sie eine gespeicherte Prozedur mit einemdateaufgerufen hätten Parameter), aber es ist ein wenig hässlich und schwieriger zu warten.
- Spielen Sie mit Hinweisen und Trace-Flags herum. Paul White spricht über einige davon in dem oben erwähnten Post.
Ich behaupte nicht, dass dies eine erschöpfende Liste ist, und ich werde Pauls Ratschläge zu Hinweisen oder Trace-Flags nicht wiederholen, also werde ich mich nur darauf konzentrieren, zu zeigen, wie die ersten vier Ansätze das Problem mit schlechten Schätzungen entschärfen können .
1. Datumsparameter
CREATE PROCEDURE dbo.MonthlyReport_TwoDates
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Two Dates */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO 2. Wrapper-Prozedur
CREATE PROCEDURE dbo.MonthlyReport_WrapperTarget
@Start date,
@End date
AS
BEGIN
SET NOCOUNT ON;
SELECT /* Wrapper */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;
END
GO
CREATE PROCEDURE dbo.MonthlyReport_WrapperSource
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
EXEC dbo.MonthlyReport_WrapperTarget @Start = @Start, @End = @End;
END
GO 3. OPTION (NEU KOMPILIEREN)
CREATE PROCEDURE dbo.MonthlyReport_Recompile
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
SELECT /* Recompile */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End OPTION (RECOMPILE);
END
GO 4. Dynamisches SQL
CREATE PROCEDURE dbo.MonthlyReport_DynamicSQL
@Year int,
@Month int
AS
BEGIN
SET NOCOUNT ON;
DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1);
DECLARE @End date = DATEADD(MONTH, 1, @Start);
DECLARE @sql nvarchar(max) = N'SELECT /* Dynamic SQL */ DateColumn
FROM dbo.DateEntries
WHERE DateColumn >= @Start
AND DateColumn < @End;';
EXEC sys.sp_executesql @sql, N'@Start date, @End date', @Start, @End;
END
GO
Die Tests
Mit den vier vorhandenen Prozeduren war es einfach, Tests zu konstruieren, die mir die Pläne und die von SQL Server abgeleiteten Schätzungen zeigten. Da einige Monate geschäftiger sind als andere, habe ich drei verschiedene Monate ausgewählt und sie alle mehrmals ausgeführt.
DECLARE @Year int = 2012, @Month int = 7; -- 385 rows DECLARE @Start date = DATEFROMPARTS(@Year, @Month, 1); DECLARE @End date = DATEADD(MONTH, 1, @Start); EXEC dbo.MonthlyReport_Original @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_TwoDates @Start = @Start, @End = @End; EXEC dbo.MonthlyReport_WrapperSource @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_Recompile @Year = @Year, @Month = @Month; EXEC dbo.MonthlyReport_DynamicSQL @Year = @Year, @Month = @Month; /* repeat for @Year = 2011, @Month = 9 -- 157 rows */ /* repeat for @Year = 2014, @Month = 4 -- 2,115 rows */
Das Ergebnis? Jeder einzelne Plan ergibt die gleiche Indexsuche, aber die Schätzungen sind nur über alle drei Zeiträume hinweg korrekt in der OPTION (RECOMPILE) Ausführung. Der Rest verwendet weiterhin die Schätzungen, die aus dem ersten Parametersatz (Juli 2012) abgeleitet wurden, und erhält so während des ersten bessere Schätzungen Ausführung, diese Schätzung wird später nicht unbedingt besser sein Ausführungen mit unterschiedlichen Parametern (ein klassischer Lehrbuchfall des Parameter-Sniffings):
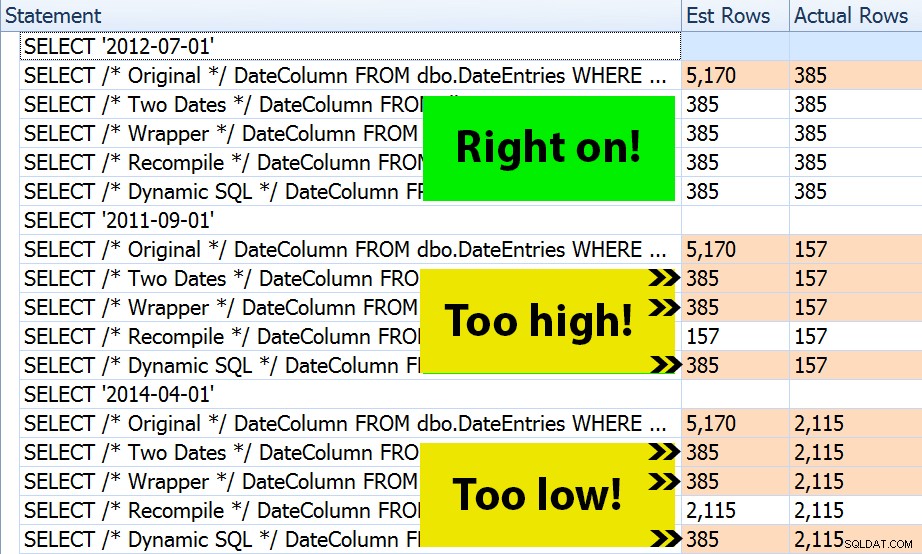
Beachten Sie, dass das Obige keine *genaue* Ausgabe des SQL Sentry Plan Explorers ist – zum Beispiel habe ich die Zeilen der Anweisungsstruktur entfernt, die die Aufrufe der äußeren gespeicherten Prozeduren und Parameterdeklarationen zeigten.
Es liegt an Ihnen zu entscheiden, ob die Taktik, jedes Mal zu kompilieren, für Sie am besten ist oder ob Sie überhaupt etwas "reparieren" müssen. Hier endeten wir mit den gleichen Plänen und ohne merkliche Unterschiede in den Laufzeitleistungsmetriken. Aber bei größeren Tabellen, mit stärker verzerrter Datenverteilung und größeren Abweichungen in den Prädikatwerten (z. B. einen Bericht, der eine Woche, ein Jahr und alles dazwischen abdecken kann), kann es eine Untersuchung wert sein. Und beachten Sie, dass Sie hier Methoden kombinieren können – zum Beispiel könnten Sie zu richtigen Datumsparametern wechseln *und* OPTION (RECOMPILE) hinzufügen , wenn Sie wollten.
Schlussfolgerung
In diesem speziellen Fall, der eine bewusste Vereinfachung darstellt, hat sich der Aufwand für die richtigen Schätzungen nicht wirklich gelohnt – wir haben keinen anderen Plan bekommen, und die Laufzeitleistung war gleichwertig. Es gibt jedoch sicherlich andere Fälle, in denen dies einen Unterschied machen wird, und es ist wichtig, Schätzungsunterschiede zu erkennen und festzustellen, ob sie zu einem Problem werden könnten, wenn Ihre Daten wachsen und/oder Ihre Verteilungsunterschiede auftreten. Leider gibt es keine Schwarz-Weiß-Antwort, da viele Variablen beeinflussen, ob der Kompilierungsaufwand gerechtfertigt ist – wie bei vielen Szenarien, IT DEPENDS™ …