Eine der besten Möglichkeiten, sich über Fehler in SQL Server zu informieren, besteht darin, die Versionshinweise für kumulative Updates und Service Packs zu lesen, wenn sie herauskommen. Gelegentlich ist dies jedoch auch eine großartige Möglichkeit, sich über Verbesserungen an SQL Server zu informieren.
Kumulatives Update 6 für SQL Server 2014 Service Pack 1 führte ein neues Ablaufverfolgungsflag 7471 ein, das das Sperrverhalten von UPDATE STATISTICS-Tasks in SQL Server ändert (siehe KB #3156157). In diesem Beitrag sehen wir uns den Unterschied im Sperrverhalten an und wo dieses Trace-Flag nützlich sein könnte.
Um eine geeignete Demoumgebung für diesen Beitrag einzurichten, habe ich die AdventureWorks2014-Datenbank verwendet und basierend auf dem in meinem Blog verfügbaren Skript eine vergrößerte Version der SalesOrderDetail-Tabelle erstellt. Die Tabelle „SalesOrderDetailEnlarged“ wurde auf 2 GB vergrößert, sodass UPDATE STATISTICS WITH FULLSCAN-Operationen gleichzeitig für verschiedene Statistiken in der Tabelle ausgeführt werden konnten. Ich habe dann sp_whoisactive verwendet, um die Sperren zu untersuchen, die von beiden Sitzungen gehalten werden.
Verhalten ohne TF 7471
Das Standardverhalten von SQL Server erfordert eine exklusive Sperre (X) für die Ressource OBJECT.UPDSTATS für die Tabelle, wenn ein UPDATE STATISTICS-Befehl für eine Tabelle ausgeführt wird. Sie können dies in der sp_whoisactive-Ausgabe für zwei gleichzeitige Ausführungen von UPDATE STATISTICS WITH FULLSCAN für die Sales.SalesOrderDetailEnlarged-Tabelle sehen, wobei unterschiedliche Indexnamen für die zu aktualisierenden Statistiken verwendet werden. Dies führt dazu, dass die zweite Ausführung von UPDATE STATISTICS blockiert wird, bis die erste Ausführung abgeschlossen ist.
STATISTIKEN [Umsätze].[SalesOrderDetailEnlarged] ([PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID]) MIT FULLSCAN AKTUALISIEREN;
STATISTIKEN [Umsätze].[SalesOrderDetailEnlarged] ([IX_SalesOrderDetailEnlarged_ProductID]) MIT FULLSCAN AKTUALISIEREN;
Die Granularität der Sperrressource auf OBJECT.UPDSTATS verhindert gleichzeitige Aktualisierungen mehrerer Statistiken für dieselbe Tabelle. Hardwareverbesserungen in den letzten Jahren haben die potenziellen Engpässe, die bei SQL Server-Implementierungen üblich sind, wirklich verändert, und ebenso wie Änderungen an DBCC CHECKDB vorgenommen wurden, um es schneller laufen zu lassen, wurde das Sperrverhalten von UPDATE STATISTICS geändert, um gleichzeitige Aktualisierungen von Statistiken auf dem zu ermöglichen Dieselbe Tabelle kann Wartungsfenster für VLDBs erheblich verkürzen, insbesondere wenn genügend CPU- und E/A-Subsystemkapazität vorhanden ist, um gleichzeitige Aktualisierungen zu ermöglichen, ohne die Endbenutzererfahrung zu beeinträchtigen.
Verhalten mit TF 7471
Das Sperrverhalten mit aktiviertem Ablaufverfolgungsflag 7471 ändert sich vom Erfordernis einer exklusiven Sperre (X) für die Ressource OBJECT.UPDSTATS zum Erfordernis einer Aktualisierungssperre (U) für die Ressource METADATA.STATS für die bestimmte Statistik, die aktualisiert wird, was gleichzeitige Ausführungen ermöglicht von UPDATE STATISTICS auf derselben Tabelle. Die Ausgabe von sp_whoisactive für die gleichen UPDATE STATISTICS WITH FULLCAN-Befehle mit aktiviertem Trace-Flag wird unten gezeigt:
STATISTIKEN [Umsätze].[SalesOrderDetailEnlarged] ([PK_SalesOrderDetailEnlarged_SalesOrderID_SalesOrderDetailID]) MIT FULLSCAN AKTUALISIEREN;
STATISTIKEN [Umsätze].[SalesOrderDetailEnlarged] ([IX_SalesOrderDetailEnlarged_ProductID]) MIT FULLSCAN AKTUALISIEREN;
Für VLDBs, die immer häufiger verwendet werden, kann dies einen großen Unterschied in der Zeit ausmachen, die zum Durchführen von Statistikaktualisierungen auf einem Server benötigt wird.
Ich habe kürzlich über eine parallele Wartungslösung für SQL Server gebloggt, die Wartungsskripts von Service Broker und Ola Hallengren verwendet, um nächtliche Wartungsaufgaben zu optimieren und die Zeit zu reduzieren, die zum Neuerstellen von Indizes und Aktualisieren von Statistiken auf Servern mit viel CPU- und E/A-Kapazität erforderlich ist erhältlich. Als Teil dieser Lösung habe ich eine Reihenfolge von Warteschlangenaufgaben für Service Broker erzwungen, um zu versuchen und zu vermeiden, dass gleichzeitige Ausführungen für dieselbe Tabelle sowohl für die Indexneuerstellung/-reorganisation als auch für die Aufgaben „STATISTIK AKTUALISIEREN“ ausgeführt werden. Ziel war es, die Arbeiter bis zum Ende der Wartungsaufgaben so beschäftigt wie möglich zu halten, wo die Dinge in der Ausführung auf der Grundlage der Blockierung gleichzeitiger Aufgaben serialisiert würden.
Ich habe einige Änderungen an der Verarbeitung in diesem Beitrag vorgenommen, um die Auswirkungen dieses Trace-Flags nur mit gleichzeitigen Statistikaktualisierungen zu testen, und die Ergebnisse sind unten aufgeführt.
Testen der Leistung bei gleichzeitiger Statistikaktualisierung
Um die Leistung der ausschließlichen parallelen Aktualisierung von Statistiken mit der Service Broker-Konfiguration zu testen, habe ich mit dem Erstellen einer Spaltenstatistik für jede Spalte in der AdventureWorks2014-Datenbank begonnen, indem ich das folgende Skript verwendet habe, um die auszuführenden DDL-Befehle zu generieren.
USE [AdventureWorks2014]GO SELECT *, 'DROP STATISTICS ' + QUOTENAME(c.TABLE_SCHEMA) + '.' + ZITATNAME(c.TABLE_NAME) + '.' + QUOTENAME(c.TABLE_NAME + '_' + c.COLUMN_NAME) + ';GOCREATE STATISTICS ' +QUOTENAME(c.TABLE_NAME + '_' + c.COLUMN_NAME) + ' ON ' + QUOTENAME(c.TABLE_SCHEMA) + '. ' + QUOTENAME(c.TABLE_NAME) + ' (' +QUOTENAME(c.COLUMN_NAME) + ');' + 'GO' FROM INFORMATION_SCHEMA.COLUMNS AS cINNER JOIN INFORMATION_SCHEMA.TABLES AS t ON c.TABLE_CATALOG =t.TABLE_CATALOG AND c.TABLE_SCHEMA =t.TABLE_SCHEMA AND c.TABLE_NAME =t.TABLE_NAMEWHERE t.TABLE_TYPE ='BASE TABLE' AND c .DATA_TYPE <> N'xml';Dies ist etwas, was Sie normalerweise nicht tun möchten, aber es gibt mir viele Statistiken zum parallelen Testen der Auswirkungen des Ablaufverfolgungsflags auf die gleichzeitige Aktualisierung von Statistiken. Anstatt die Reihenfolge, in der ich die Aufgaben in die Warteschlange von Service Broker stelle, zufällig zu bestimmen, warte ich stattdessen einfach die Aufgaben so, wie sie in der CommandLog-Tabelle basierend auf der ID der Tabelle vorhanden sind, und erhöhe einfach die ID um eins, bis alle Befehle in die Warteschlange gestellt wurden zur Verarbeitung.
USE [master]; -- Befehlsprotokoll löschen TRUNCATE TABLE [master].[dbo].[CommandLog]; DECLARE @MaxID INT;SELECT @MaxID =MAX(ID) FROM master.dbo.CommandLog; SELECT @MaxID =ISNULL(@MaxID, 1) ---- Lade neue Aufgaben in das Command LogEXEC master.dbo.IndexOptimize @Databases =N'AdventureWorks2014', @FragmentationLow =NULL, @FragmentationMedium =NULL, @FragmentationHigh =NULL, @UpdateStatistics ='ALL', @StatisticsSample =100, @LogToTable ='Y', @Execute ='N'; DECLARE @NewMaxID INTSELECT @NewMaxID =MAX(ID) FROM master.dbo.CommandLog; msdb VERWENDEN; DECLARE @CurrentID INT =@MaxIDWHILE (@CurrentID <=@NewMaxID)BEGIN – Beginnen Sie eine Konversation und senden Sie eine Anforderungsnachricht DECLARE @conversation_handle UNIQUEIDENTIFIER; DECLARE @message_body XML; TRANSAKTION BEGINNEN; BEGIN DIALOG @conversation_handle FROM SERVICE [OlaHallengrenMaintenanceTaskService] TO SERVICE N'OlaHallengrenMaintenanceTaskService' ON CONTRACT [OlaHallengrenMaintenanceTaskContract] WITH ENCRYPTION =OFF; SELECT @message_body =N''+CAST(@CurrentID AS NVARCHAR)+N' '; IM GESPRÄCH SENDEN @conversation_handle NACHRICHTENTYP [OlaHallengrenMaintenanceTaskMessage] (@message_body); COMMIT-TRANSAKTION; SET @CurrentID =@CurrentID + 1;END WHILE EXISTS (SELECT 1 FROM OlaHallengrenMaintenanceTaskQueue WITH(NOLOCK))BEGIN WAITFOR DELAY '00:00:01.000'END WAITFOR DELAY '00:00:06.000' SELECT DATEDIFF(ms, MIN(StartTime ), MAX(EndTime)) FROM master.dbo.CommandLog;GO 10Dann habe ich auf den Abschluss aller Aufgaben gewartet, das Delta der Startzeit und der Endzeit der Aufgabenausführungen gemessen und den Durchschnitt von zehn Tests genommen, um die Verbesserungen zu bestimmen, nur um die Statistiken gleichzeitig mit den Standard-Sampling- und vollständigen Scan-Updates zu aktualisieren. P>
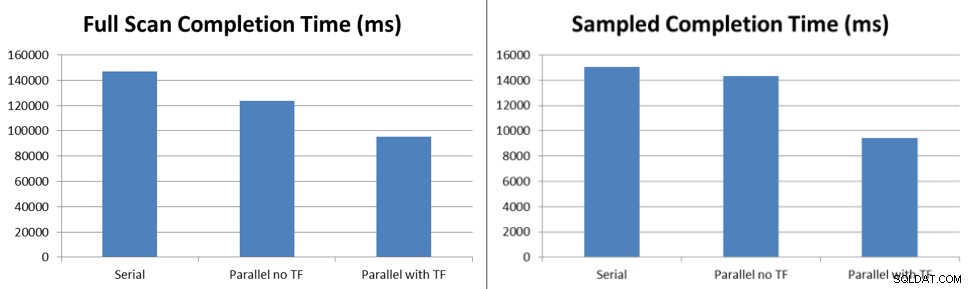
Die Testergebnisse zeigen, dass selbst mit der Blockierung, die unter dem Standardverhalten ohne Ablaufverfolgungsflag auftritt, Stichprobenaktualisierungen von Statistiken 6 % schneller ausgeführt werden und vollständige Scanaktualisierungen 16 % schneller ausgeführt werden, wobei fünf Threads die Aufgaben verarbeiten, die in Service Broker in die Warteschlange gestellt werden. Wenn das Ablaufverfolgungsflag 7471 aktiviert ist, werden die gleichen Stichprobenaktualisierungen von Statistiken 38 % schneller ausgeführt und vollständige Scanaktualisierungen werden 45 % schneller ausgeführt, wobei fünf Threads die Aufgaben verarbeiten, die in Service Broker in die Warteschlange gestellt werden.
Potenzielle Herausforderungen mit TF 7471
So überzeugend die Testergebnisse auch sind, nichts auf dieser Welt ist kostenlos, und bei meinen ersten Tests stieß ich auf einige Probleme mit der Größe der VM, die ich auf meinem Laptop verwendete, was zu Workload-Problemen führte.
Ursprünglich habe ich die parallele Wartung mit einer 4-vCPU-VM mit 4 GB RAM getestet, die ich speziell für diesen Zweck eingerichtet habe. Als ich begann, die Anzahl von MAX_QUEUE_READERS für die Aktivierungsprozedur in Service Broker zu erhöhen, traten Probleme mit RESOURCE_SEMAPHORE-Wartezeiten auf, wenn das Ablaufverfolgungsflag aktiviert war, was parallele Aktualisierungen von Statistiken in den vergrößerten Tabellen in meiner AdventureWorks2014-Datenbank aufgrund der Speicherzuweisungsanforderungen ermöglichte für jeden der UPDATE STATISTICS-Befehle, die ausgeführt wurden. Dies wurde durch die Änderung der VM-Konfiguration auf 16 GB RAM gemildert, aber dies ist etwas, das Sie überwachen und beobachten sollten, wenn Sie parallele Aufgaben in größeren Tabellen ausführen, um die Indexwartung einzuschließen, da sich der Mangel an Speicherzuweisung auch auf Endbenutzeranforderungen auswirkt, die möglicherweise auszuführen versuchen und benötigen auch eine größere Speicherzuteilung.
Auch das Produktteam hat über dieses Trace-Flag gebloggt und warnt in seinem Beitrag davor, dass beim gleichzeitigen Aktualisieren von Statistiken Deadlock-Szenarien auftreten können, während gleichzeitig Statistiken erstellt werden. Das ist etwas, auf das ich während meiner Tests noch nicht gestoßen bin, aber es ist definitiv etwas, dessen man sich bewusst sein sollte (Kendra Little warnt auch davor). Aus diesem Grund empfehlen sie, dass dieses Trace-Flag nur während der parallelen Ausführung von Wartungsaufgaben aktiviert und dann für normale Workload-Zeiträume deaktiviert werden sollte.
Viel Spaß!