Dieser Artikel ist der dritte in einer Reihe über Optimierungsschwellenwerte für das Gruppieren und Aggregieren von Daten. In Teil 1 habe ich den vorbestellten Stream Aggregate-Algorithmus behandelt. In Teil 2 habe ich den nicht vorbestellten Sort + Stream Aggregate-Algorithmus behandelt. In diesem Teil behandle ich den Hash Match (Aggregate)-Algorithmus, den ich einfach als Hash Aggregate bezeichnen werde. Ich stelle auch eine Zusammenfassung und einen Vergleich zwischen den Algorithmen bereit, die ich in Teil 1, Teil 2 und Teil 3 behandle.
Ich verwende dieselbe Beispieldatenbank namens PerformanceV3, die ich in den vorherigen Artikeln der Serie verwendet habe. Stellen Sie einfach sicher, dass Sie vor dem Ausführen der Beispiele im Artikel zuerst den folgenden Code ausführen, um ein paar nicht benötigte Indizes zu löschen:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders;DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Die einzigen beiden Indizes, die in dieser Tabelle verbleiben sollten, sind idx_cl_od (geclustert mit orderdate als Schlüssel) und PK_Orders (nicht geclustert mit orderid als Schlüssel).
Hash-Aggregat
Der Hash-Aggregate-Algorithmus organisiert die Gruppen in einer Hash-Tabelle basierend auf einer intern gewählten Hash-Funktion. Im Gegensatz zum Stream Aggregate-Algorithmus müssen die Zeilen nicht in Gruppenreihenfolge konsumiert werden. Betrachten Sie die folgende Abfrage (wir nennen sie Abfrage 1) als Beispiel (erzwingt ein Hash-Aggregat und einen seriellen Plan):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1);
Abbildung 1 zeigt den Plan für Abfrage 1.
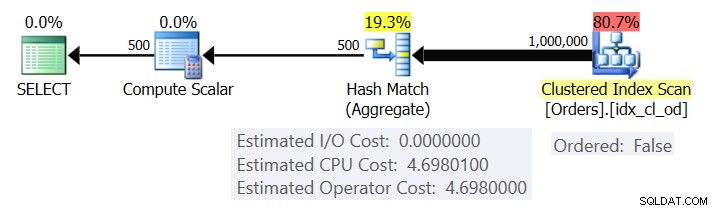
Abbildung 1:Plan für Abfrage 1
Der Plan scannt die Zeilen aus dem gruppierten Index mit einer Ordered:False-Eigenschaft (der Scan ist nicht erforderlich, um die nach dem Indexschlüssel geordneten Zeilen zu liefern). Typischerweise zieht es der Optimierer vor, den engsten abdeckenden Index zu scannen, der in unserem Fall zufällig der geclusterte Index ist. Der Plan erstellt eine Hashtabelle mit den gruppierten Spalten und den Aggregaten. Unsere Abfrage fordert ein COUNT-Aggregat vom Typ INT an. Der Plan berechnet ihn tatsächlich als Wert vom Typ BIGINT, daher der Operator Compute Scalar, der eine implizite Konvertierung in INT anwendet.
Microsoft teilt die verwendeten Hash-Algorithmen nicht öffentlich. Dies ist eine sehr proprietäre Technologie. Um das Konzept zu veranschaulichen, nehmen wir dennoch an, dass SQL Server die Hash-Funktion % 250 (Modulo 250) für unsere obige Abfrage verwendet. Vor der Verarbeitung von Zeilen enthält unsere Hash-Tabelle 250 Buckets, die die 250 möglichen Ergebnisse der Hash-Funktion darstellen (0 bis 249). Während SQL Server jede Zeile verarbeitet, wendet es die Hash-Funktion
orderid empid ------- ----- 320 330 5660 253820 3850 11000 255700 31240 253350 4400 255
Abbildung 2 zeigt drei Zustände der Hashtabelle:vor der Verarbeitung von Zeilen, nach der Verarbeitung der ersten 5 Zeilen und nach der Verarbeitung der ersten 10 Zeilen. Jedes Element in der verknüpften Liste enthält das Tupel (empid, COUNT(*)).
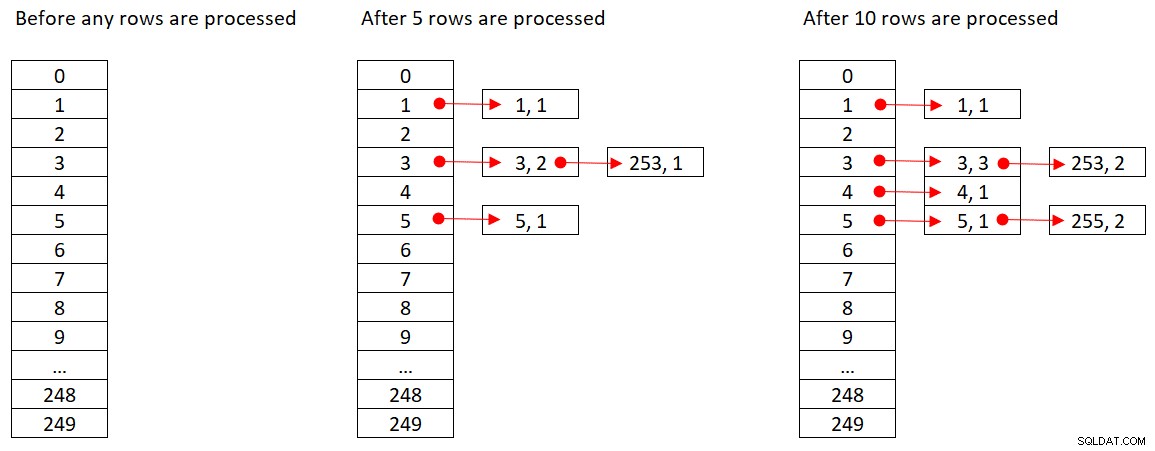
Abbildung 2:Zustände der Hash-Tabelle
Sobald der Hash-Aggregat-Operator die Verarbeitung aller Eingabezeilen beendet hat, enthält die Hash-Tabelle alle Gruppen mit dem Endzustand des Aggregats.
Wie der Sort-Operator erfordert der Hash Aggregate-Operator eine Arbeitsspeicherzuweisung, und wenn ihm der Arbeitsspeicher ausgeht, muss er nach tempdb überlaufen; Während für das Sortieren jedoch eine Arbeitsspeicherzuweisung erforderlich ist, die proportional zur Anzahl der zu sortierenden Zeilen ist, erfordert das Hashing eine Arbeitsspeicherzuweisung, die proportional zur Anzahl der Gruppen ist. Daher benötigt dieser Algorithmus insbesondere dann, wenn der Gruppierungssatz eine hohe Dichte hat (kleine Anzahl von Gruppen), deutlich weniger Speicher als wenn eine explizite Sortierung erforderlich ist.
Betrachten Sie die folgenden zwei Abfragen (nennen Sie sie Abfrage 1 und Abfrage 2):
SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (HASH GROUP, MAXDOP 1); SELECT empid, COUNT(*) AS numorders FROM dbo.Orders GROUP BY empid OPTION (ORDER GROUP, MAXDOP 1);
Abbildung 3 vergleicht die Arbeitsspeicherzuweisungen für diese Abfragen.

Abbildung 3:Pläne für Abfrage 1 und Abfrage 2
Beachten Sie den großen Unterschied zwischen den Speicherzuweisungen in den beiden Fällen.
Was die Kosten des Hash-Aggregate-Operators anbelangt, beachten Sie, dass es keine E/A-Kosten gibt, sondern nur CPU-Kosten, wenn Sie zu Abbildung 1 zurückkehren. Versuchen Sie als Nächstes, die CPU-Kostenformel mit ähnlichen Techniken wie denen, die ich in den vorherigen Teilen der Serie behandelt habe, zurückzuentwickeln. Die Faktoren, die sich möglicherweise auf die Kosten des Operators auswirken können, sind die Anzahl der Eingabezeilen, die Anzahl der Ausgabegruppen, die verwendete Aggregatfunktion und das, wonach Sie gruppieren (Kardinalität des Gruppierungssatzes, verwendete Datentypen).
Sie würden erwarten, dass dieser Operator Anlaufkosten in Vorbereitung auf die Erstellung der Hash-Tabelle hat. Sie würden auch erwarten, dass es in Bezug auf die Anzahl der Zeilen und Gruppen linear skaliert wird. Das habe ich tatsächlich gefunden. Während die Kosten sowohl des Stream Aggregate- als auch des Sort-Operators nicht davon beeinflusst werden, wonach Sie gruppieren, scheinen die Kosten des Hash Aggregate-Operators dies zu sein – sowohl in Bezug auf die Kardinalität des Gruppierungssatzes als auch auf die verwendeten Datentypen.
Um festzustellen, dass sich die Kardinalität des Gruppierungssatzes auf die Kosten des Operators auswirkt, überprüfen Sie die CPU-Kosten der Hash-Aggregate-Operatoren in den Plänen für die folgenden Abfragen (nennen Sie sie Abfrage 3 und Abfrage 4):
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 50 AS grp1, orderid % 20 AS grp2, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 50, orderid % 20 OPTION(HASH GROUP, MAXDOP 1 );
Natürlich möchten Sie sicherstellen, dass die geschätzte Anzahl der Eingabezeilen und Ausgabegruppen in beiden Fällen gleich ist. Die geschätzten Pläne für diese Abfragen sind in Abbildung 4 dargestellt.
Abbildung 4:Pläne für Abfrage 3 und Abfrage 4
Wie Sie sehen können, betragen die CPU-Kosten des Hash Aggregate-Operators 0,16903 beim Gruppieren nach einer ganzzahligen Spalte und 0,174016 beim Gruppieren nach zwei ganzzahligen Spalten, wobei alle anderen gleich sind. Das bedeutet, dass sich die Kardinalität des Gruppierungssatzes tatsächlich auf die Kosten auswirkt.
Um festzustellen, ob der Datentyp des gruppierten Elements die Kosten beeinflusst, habe ich die folgenden Abfragen verwendet, um dies zu überprüfen (nennen Sie sie Abfrage 5, Abfrage 6 und Abfrage 7):
SELECT CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT) AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY CAST(orderid AS SMALLINT) % CAST(1000 AS SMALLINT) OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT) AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY CAST(orderid AS BIGINT) % CAST(1000 AS BIGINT) OPTION(HASH GROUP, MAXDOP 1);
Die Pläne für alle drei Abfragen haben die gleiche geschätzte Anzahl von Eingabezeilen und Ausgabegruppen, erhalten jedoch alle unterschiedliche geschätzte CPU-Kosten (0,121766, 0,16903 und 0,171716), daher wirkt sich der verwendete Datentyp auf die Kosten aus.
Auch die Art der Aggregatfunktion scheint einen Einfluss auf die Kosten zu haben. Betrachten Sie beispielsweise die folgenden zwei Abfragen (nennen Sie sie Abfrage 8 und Abfrage 9):
SELECT orderid % 1000 AS grp, COUNT(*) AS numorders FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1);
Die geschätzten CPU-Kosten für das Hash-Aggregat im Plan für Abfrage 8 betragen 0,166344 und in Abfrage 9 0,16903.
Es könnte eine interessante Übung sein, herauszufinden, wie sich die Kardinalität des Gruppierungssatzes, die verwendeten Datentypen und die verwendete Aggregatfunktion auf die Kosten auswirken. Diesen Aspekt der Kostenrechnung habe ich einfach nicht weiterverfolgt. Nachdem Sie die Gruppierungsmenge und die Aggregatfunktion für Ihre Abfrage ausgewählt haben, können Sie die Kostenformel zurückentwickeln. Lassen Sie uns beispielsweise die CPU-Kostenformel für den Hash-Aggregatoperator zurückentwickeln, wenn nach einer einzelnen Ganzzahlspalte gruppiert und das MAX(orderdate)-Aggregat zurückgegeben wird. Die Formel sollte lauten:
Operator-CPU-Kosten =Unter Verwendung der Techniken, die ich in den vorherigen Artikeln der Serie demonstriert habe, habe ich die folgende Reverse-Engineering-Formel erhalten:
Operator-CPU-Kosten =0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087Sie können die Genauigkeit der Formel mit den folgenden Abfragen überprüfen:
SELECT orderid % 1000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 1000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 2000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 2000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 3000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 3000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 6000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 6000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 5000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 5000 OPTION(HASH GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(HASH GROUP, MAXDOP 1);
Ich erhalte die folgenden Ergebnisse:
numrows numgroups vorhergesagte Kosten geschätzte Kosten ----------- ----------- -------------- ------- ------- 100000 1000 0,703315 0,703316100000 2000 0,721023 0,721024200000 3000 1,40659 1.40659200000 6000 1.45972 1.45972500000 5000 3.44558 3.44558500000 10000 10000 10000 3.53412 3.534122 Die Formel scheint genau richtig zu sein.Kostenübersicht und -vergleich
Jetzt haben wir die Kalkulationsformeln für die drei verfügbaren Strategien:Preordered Stream Aggregate, Sort + Stream Aggregate und Hash Aggregate. Die folgende Tabelle fasst die Kostenmerkmale der drei Algorithmen zusammen und vergleicht sie:
| Vorbestelltes Stream-Aggregat | Sortieren + Stream aggregieren | Hash-Aggregat | |
| Formel | @numrows * 0,0000006 + @numgroups * 0,0000005 | 0,0112613 + Kleine Zeilenzahl: 9.99127891201865E-05 + @numrows * LOG(@numrows) * 2.25061348918698E-06 Große Anzahl von Zeilen: 1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06 + @numrows * 0,0000006 + @numgroups * 0.0000005 | 0,017749 + @numrows * 0,00000667857 + @numgroups * 0,0000177087
* Gruppierung nach einer einzelnen Integer-Spalte, Rückgabe von MAX( |
| Skalierung | linear | n log n | linear |
| Start-E/A-Kosten | keine | 0,0112613 | keine |
| CPU-Kosten beim Start | keine | ~ 0,0001 | 0,017749 |
Gemäß diesen Formeln zeigt Abbildung 5, wie jede der Strategien für eine unterschiedliche Anzahl von Eingabezeilen skaliert, wobei eine feste Anzahl von Gruppen von 500 als Beispiel verwendet wird.
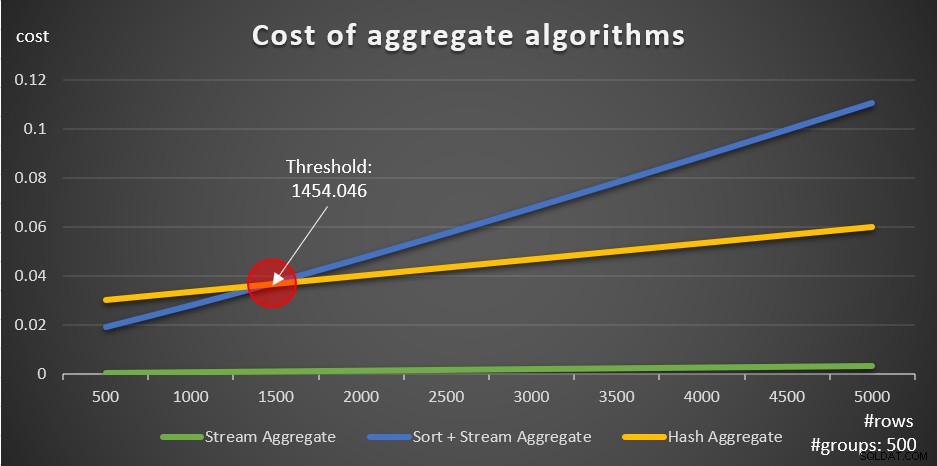
Abbildung 5:Kosten aggregierter Algorithmen
Sie können deutlich sehen, dass bei vorgeordneten Daten, z. B. in einem überdeckenden Index, die vorgeordnete Stream Aggregate-Strategie die beste Option ist, unabhängig davon, wie viele Zeilen betroffen sind. Angenommen, Sie müssen die Tabelle „Bestellungen“ abfragen und das maximale Bestelldatum für jeden Mitarbeiter berechnen. Sie erstellen den folgenden abdeckenden Index:
CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate);
Hier sind fünf Abfragen, die eine Orders-Tabelle mit unterschiedlicher Zeilenanzahl emulieren (10.000, 20.000, 30.000, 40.000 und 50.000):
SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (30000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (40000) * FROM dbo.Orders) AS D GROUP BY empid; SELECT empid, MAX(orderdate) AS maxod FROM (SELECT TOP (50000) * FROM dbo.Orders) AS D GROUP BY empid;
Abbildung 6 zeigt die Pläne für diese Abfragen.
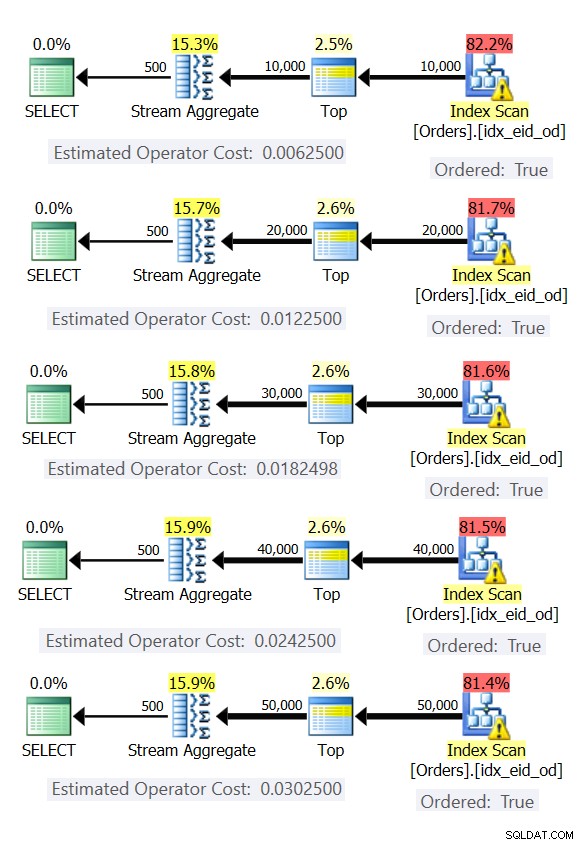
Abbildung 6:Pläne mit vorbestellter Stream Aggregate-Strategie
In allen Fällen führen die Pläne einen geordneten Scan des abdeckenden Index durch und wenden den Stream Aggregate-Operator an, ohne dass eine explizite Sortierung erforderlich ist.
Verwenden Sie den folgenden Code, um den Index zu löschen, den Sie für dieses Beispiel erstellt haben:
DROP INDEX idx_eid_od ON dbo.Orders;
Die andere wichtige Sache, die bei den Diagrammen in Abbildung 5 zu beachten ist, ist, was passiert, wenn die Daten nicht vorgeordnet sind. Dies passiert, wenn kein abdeckender Index vorhanden ist, sowie wenn Sie nach manipulierten Ausdrücken im Gegensatz zu Basisspalten gruppieren. Es gibt einen Optimierungsschwellenwert – in unserem Fall bei 1454.046 Zeilen – unterhalb dessen die Sort + Stream Aggregate-Strategie geringere Kosten verursacht und ab dem die Hash Aggregate-Strategie geringere Kosten verursacht. Dies hat mit der Tatsache zu tun, dass erstere niedrigere Startkosten haben, aber in einer n log n-Weise skalieren, während letztere höhere Startkosten haben, aber linear skalieren. Dadurch wird ersteres bei einer kleinen Anzahl von Eingabezeilen bevorzugt. Wenn unsere Reverse-Engineering-Formeln korrekt sind, sollten die folgenden zwei Abfragen (nennen Sie sie Abfrage 10 und Abfrage 11) unterschiedliche Pläne erhalten:
SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1454) * FROM dbo.Orders) AS D GROUP BY orderid % 500; SELECT orderid % 500 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (1455) * FROM dbo.Orders) AS D GROUP BY orderid % 500;
Die Pläne für diese Abfragen sind in Abbildung 7 dargestellt.
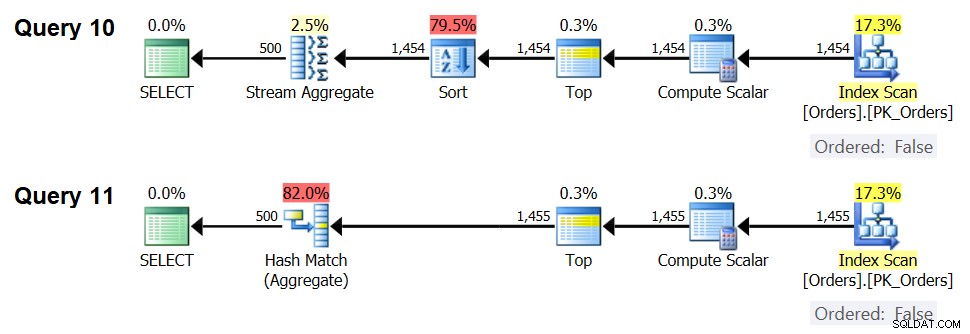
Abbildung 7:Pläne für Abfrage 10 und Abfrage 11
Bei 1.454 Eingabezeilen (unter dem Optimierungsschwellenwert) bevorzugt der Optimierer natürlich den Sort + Stream Aggregate-Algorithmus für Abfrage 10, und bei 1.455 Eingabezeilen (über dem Optimierungsschwellenwert) bevorzugt der Optimierer natürlich den Hash Aggregate-Algorithmus für Abfrage 11 .
Potential für Adaptive Aggregate-Operator
Einer der kniffligen Aspekte von Optimierungsschwellenwerten sind Parameter-Sniffing-Probleme bei der Verwendung parametersensitiver Abfragen in gespeicherten Prozeduren. Betrachten Sie die folgende gespeicherte Prozedur als Beispiel:
CREATE OR ALTER PROC dbo.EmpOrders @initialorderid AS INTAS SELECT empid, COUNT(*) AS numorders FROM dbo.Orders WHERE orderid>=@initialorderid GROUP BY empid;GO
Sie erstellen den folgenden optimalen Index zur Unterstützung der Abfrage gespeicherter Prozeduren:
CREATE INDEX idx_oid_i_eid ON dbo.Orders(orderid) INCLUDE(empid);
Sie haben den Index mit orderid als Schlüssel erstellt, um den Bereichsfilter der Abfrage zu unterstützen, und empid für die Abdeckung eingefügt. Dies ist eine Situation, in der Sie nicht wirklich einen Index erstellen können, der sowohl den Bereichsfilter unterstützt als auch die gefilterten Zeilen durch den Gruppierungssatz vorgeordnet hat. Das bedeutet, dass der Optimierer zwischen den Algorithmen Sort + Stream Aggregate und Hash Aggregate wählen muss. Basierend auf unseren Kalkulationsformeln liegt der Optimierungsschwellenwert zwischen 937 und 938 Eingabezeilen (sagen wir 937,5 Zeilen).
Angenommen, Sie führen die gespeicherte Prozedur zum ersten Mal mit einer eingegebenen Anfangsauftrags-ID aus, die Ihnen eine kleine Anzahl von Übereinstimmungen (unterhalb des Schwellenwerts) liefert:
EXEC dbo.EmpOrders @initialorderid =999991;
SQL Server erstellt einen Plan, der den Sort + Stream Aggregate-Algorithmus verwendet, und speichert den Plan zwischen. Nachfolgende Ausführungen verwenden den zwischengespeicherten Plan erneut, unabhängig davon, wie viele Zeilen betroffen sind. Die folgende Ausführung hat beispielsweise eine Anzahl von Übereinstimmungen oberhalb des Optimierungsschwellenwerts:
EXEC dbo.EmpOrders @initialorderid =990001;
Dennoch wird der zwischengespeicherte Plan wiederverwendet, obwohl er für diese Ausführung nicht optimal ist. Das ist ein klassisches Parameter-Sniffing-Problem.
SQL Server 2017 führt adaptive Abfrageverarbeitungsfunktionen ein, die darauf ausgelegt sind, solche Situationen zu bewältigen, indem während der Abfrageausführung bestimmt wird, welche Strategie angewendet werden soll. Zu diesen Verbesserungen gehört ein Adaptive-Join-Operator, der während der Ausführung bestimmt, ob ein Loop- oder ein Hash-Algorithmus basierend auf einem berechneten Optimierungsschwellenwert aktiviert werden soll. Unsere aggregierte Geschichte verlangt nach einem ähnlichen Adaptive Aggregate-Operator, der während der Ausführung eine Wahl zwischen einer Sort + Stream Aggregate-Strategie und einer Hash Aggregate-Strategie treffen würde, basierend auf einem berechneten Optimierungsschwellenwert. Abbildung 8 zeigt einen Pseudoplan, der auf dieser Idee basiert.
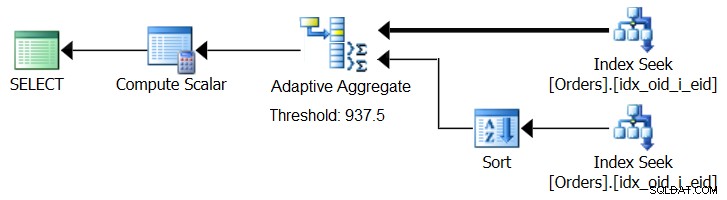
Abbildung 8:Pseudoplan mit Adaptive Aggregate-Operator
Um einen solchen Plan zu erhalten, müssen Sie vorerst Microsoft Paint verwenden. Da das Konzept der adaptiven Abfrageverarbeitung jedoch so intelligent ist und so gut funktioniert, ist es nur vernünftig, in Zukunft weitere Verbesserungen in diesem Bereich zu erwarten.
Führen Sie den folgenden Code aus, um den Index zu löschen, den Sie für dieses Beispiel erstellt haben:
DROP INDEX idx_oid_i_eid ON dbo.Orders;
Schlussfolgerung
In diesem Artikel habe ich die Kosten und Skalierung des Hash-Aggregate-Algorithmus behandelt und ihn mit den Strategien Stream Aggregate und Sort + Stream Aggregate verglichen. Ich habe die Optimierungsschwelle beschrieben, die zwischen den Strategien Sort + Stream Aggregate und Hash Aggregate besteht. Bei kleinen Zahlen von Eingabezeilen wird ersteres bevorzugt und bei großen Zahlen letzteres. Ich habe auch das Potenzial für das Hinzufügen eines Adaptive Aggregate-Operators beschrieben, ähnlich dem bereits implementierten Adaptive Join-Operator, um bei der Behandlung von Parameter-Sniffing-Problemen bei der Verwendung parametersensitiver Abfragen zu helfen. Nächsten Monat werde ich die Diskussion fortsetzen, indem ich Überlegungen zur Parallelität und Fälle anspreche, die eine Neufassung der Abfrage erfordern.