Die MySQL-Master-Slave-Replikation ist ziemlich einfach und unkompliziert einzurichten. Dies ist der Hauptgrund, warum Menschen diese Technologie als ersten Schritt wählen, um eine bessere Datenbankverfügbarkeit zu erreichen. Dies hat jedoch den Preis der Komplexität bei Verwaltung und Wartung; Es ist Sache des Administrators, die Datenintegrität aufrechtzuerhalten, insbesondere während Failover, Failback, Wartung, Upgrade usw.
Es gibt viele Artikel, die beschreiben, wie ein Failover-Vorgang für die Einrichtung der Replikation durchgeführt wird. Wir haben dieses Thema auch in diesem Blogbeitrag, Introduction to Failover for MySQL Replication – the 101 Blog, behandelt. In diesem Blog-Beitrag werden wir die Aufgaben nach einer Katastrophe bei der Wiederherstellung der ursprünglichen Topologie behandeln – die Durchführung eines Failback-Vorgangs.
Warum brauchen wir Failback?
Der Replikations-Leader (Master) ist der kritischste Knoten in einer Replikationskonfiguration. Es erfordert gute Hardwarespezifikationen, um sicherzustellen, dass es Schreibvorgänge verarbeiten, Replikationsereignisse generieren, kritische Lesevorgänge usw. auf stabile Weise verarbeiten kann. Wenn während der Notfallwiederherstellung oder Wartung ein Failover erforderlich ist, ist es nicht ungewöhnlich, dass wir einen neuen Marktführer mit minderwertiger Hardware fördern. Diese Situation kann vorübergehend in Ordnung sein, aber für lange Zeit muss der designierte Master zurückgeholt werden, um die Replikation zu leiten, nachdem er als fehlerfrei erachtet wird.
Im Gegensatz zum Failover erfolgt der Failback-Betrieb normalerweise in einer kontrollierten Umgebung durch Switchover, selten im Panikmodus. Dies gibt dem Operationsteam etwas Zeit, um die Übung für einen reibungslosen Übergang sorgfältig zu planen und zu proben. Das Hauptziel besteht einfach darin, den guten alten Master auf den neuesten Stand zu bringen und das Replikationssetup in seiner ursprünglichen Topologie wiederherzustellen. Es gibt jedoch einige Fälle, in denen ein Failback kritisch ist, beispielsweise wenn der neu heraufgestufte Master nicht wie erwartet funktionierte und den gesamten Datenbankdienst beeinträchtigte.
Wie führt man ein Failback sicher durch?
Nach dem Failover war der alte Master zur Wartung oder Wiederherstellung aus der Replikationskette entfernt. Um die Umschaltung durchzuführen, muss man folgendes tun:
- Versorgen Sie den alten Master mit dem richtigen Zustand, indem Sie ihn zum aktuellsten Slave machen.
- Beenden Sie die Anwendung.
- Vergewissere dich, dass alle Sklaven eingeholt wurden.
- Befördern Sie den alten Meister zum neuen Anführer.
- Repoint alle Slaves auf den neuen Master.
- Starten Sie die Anwendung, indem Sie an den neuen Master schreiben.
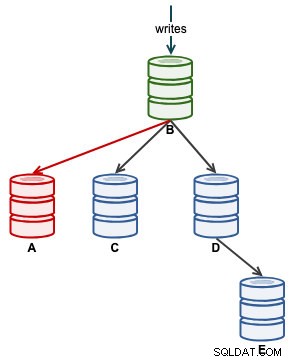
Betrachten Sie die folgende Replikationskonfiguration:
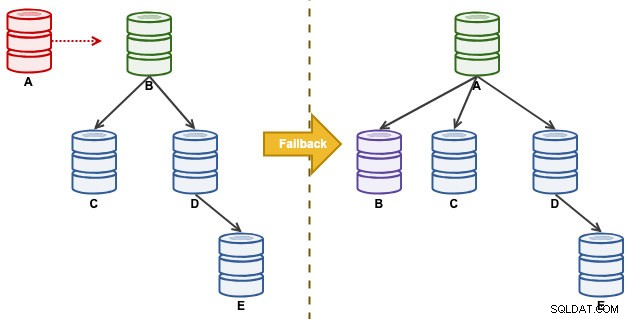
„A“ war ein Master, bis ein Festplatten-Voll-Ereignis Chaos in der Replikationskette verursachte. Nach einem Failover-Ereignis wurde unsere Replikationstopologie von B geleitet und auf C bis E repliziert. Die Failback-Übung bringt A als Leader zurück und stellt die ursprüngliche Topologie vor dem Desaster wieder her. Beachten Sie, dass alle Knoten auf MySQL 8.0.15 mit aktiviertem GTID ausgeführt werden. Unterschiedliche Hauptversionen können unterschiedliche Befehle und Schritte verwenden.
Während unsere Architektur jetzt nach dem Failover so aussieht (entnommen aus der Topologieansicht von ClusterControl):
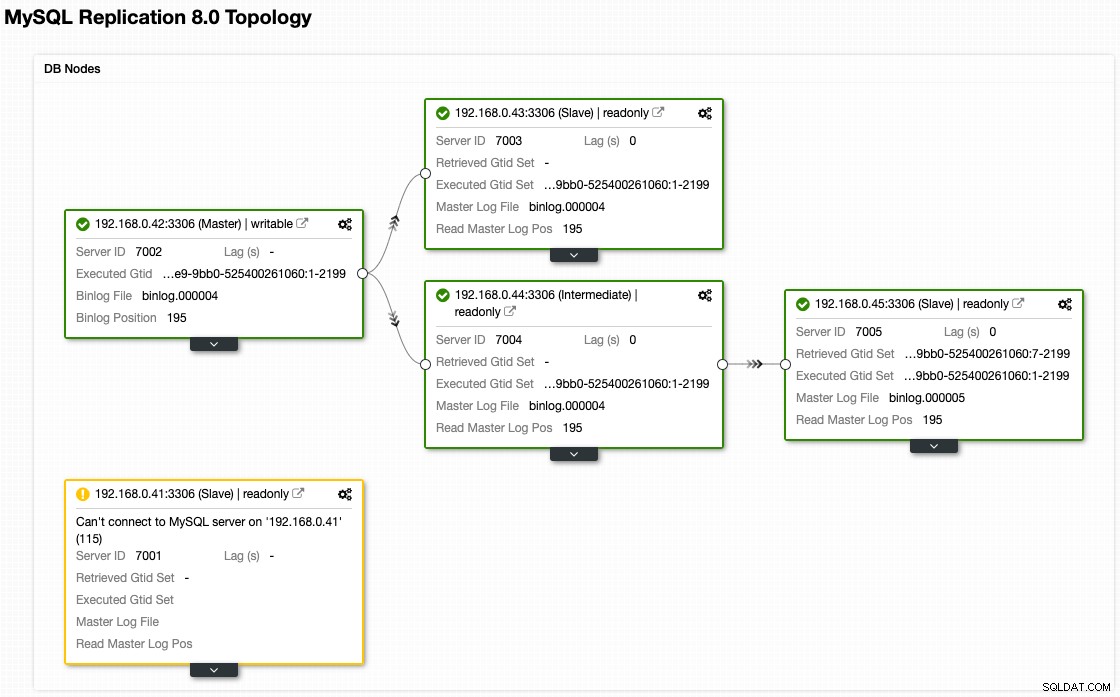
Knotenbereitstellung
Bevor A ein Master sein kann, muss es mit dem aktuellen Datenbankzustand aktualisiert werden. Der beste Weg, dies zu tun, besteht darin, A als Slave zum aktiven Master zu machen, B. Da alle Knoten mit log_slave_updates=ON konfiguriert sind (das bedeutet, dass ein Slave auch Binärprotokolle produziert), können wir tatsächlich andere Slaves wie C und D als auswählen die Quelle der Wahrheit für die anfängliche Synchronisierung. Je näher jedoch am aktiven Master, desto besser. Berücksichtigen Sie die zusätzliche Belastung, die dadurch entstehen kann, wenn Sie das Backup erstellen. Dieser Teil beansprucht die meisten Failback-Stunden. Je nach Node-Status und Dataset-Größe kann das Synchronisieren des alten Masters einige Zeit dauern (es kann Stunden oder Tage dauern).
Sobald das Problem auf "A" behoben und bereit ist, der Replikationskette beizutreten, besteht der beste erste Schritt darin, zu versuchen, von "B" (192.168.0.42) mit der CHANGE MASTER-Anweisung zu replizieren:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Wenn die Replikation funktioniert, sollten Sie Folgendes im Replikationsstatus sehen:
Slave_IO_Running: Yes
Slave_SQL_Running: YesWenn die Replikation fehlschlägt, sehen Sie sich Last_IO_Error oder Last_SQL_Error aus der Slave-Statusausgabe an. Wenn Sie beispielsweise den folgenden Fehler sehen:
Last_IO_Error: error connecting to master 'example@sqldat.com:3306' - retry-time: 60 retries: 2Dann müssen wir den Replikationsbenutzer auf dem aktuell aktiven Master B:
erstellenmysql> CREATE USER example@sqldat.com IDENTIFIED BY 'p4ss';
mysql> GRANT REPLICATION SLAVE ON *.* TO example@sqldat.com;Starten Sie dann den Slave auf A neu, um die Replikation erneut zu starten:
mysql> STOP SLAVE;
mysql> START SLAVE;Ein weiterer häufiger Fehler, den Sie sehen würden, ist diese Zeile:
Last_IO_Error: Got fatal error 1236 from master when reading data from binary log: ...Das bedeutet wahrscheinlich, dass der Slave Probleme hat, die binäre Protokolldatei vom aktuellen Master zu lesen. In manchen Fällen kann der Slave weit zurückliegen, wodurch die erforderlichen binären Ereignisse zum Starten der Replikation im aktuellen Master gefehlt haben oder die Binärdatei auf dem Master während des Failovers gelöscht wurde und so weiter. In diesem Fall führen Sie am besten eine vollständige Synchronisierung durch, indem Sie ein vollständiges Backup auf B erstellen und es auf A wiederherstellen. Auf B können Sie entweder mysqldump oder Percona Xtrabackup verwenden, um ein vollständiges Backup zu erstellen:
$ mysqldump -uroot -p --all-databases --single-transaction --triggers --routines > dump.sql # for mysqldump
$ xtrabackup --defaults-file=/etc/my.cnf --backup --parallel 1 --stream=xbstream --no-timestamp | gzip -6 - > backup-full-2019-04-16_071649.xbstream.gz # for xtrabackupÜbertragen Sie die Sicherungsdatei nach A, initialisieren Sie die vorhandene MySQL-Installation für eine ordnungsgemäße Bereinigung neu und führen Sie eine Datenbankwiederherstellung durch:
$ systemctl stop mysqld # if mysql is still running
$ rm -Rf /var/lib/mysql # wipe out old data
$ mysqld --initialize --user=mysql # initialize database
$ systemctl start mysqld # start mysql
$ grep -i 'temporary password' /var/log/mysql/mysqld.log # retrieve the temporary root password
$ mysql -uroot -p -e 'ALTER USER example@sqldat.com IDENTIFIED BY "p455word"' # mandatory root password update
$ mysql -uroot -p < dump.sql # restore the backup using the new root passwordRichten Sie nach der Wiederherstellung die Replikationsverbindung zum aktiven Master B (192.168.0.42) ein und aktivieren Sie den Schreibschutz. Führen Sie auf A die folgenden Anweisungen aus:
mysql> SET GLOBAL read_only = 1; /* enable read-only */
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.42', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1; /* master information to connect */
mysql> START SLAVE; /* start replication */
mysql> SHOW SLAVE STATUS\G /* check replication status */Für Percona Xtrabackup lesen Sie bitte die Dokumentationsseite zur Wiederherstellung auf A. Es beinhaltet einen vorausgesetzten Schritt, um zuerst die Sicherung vorzubereiten, bevor das MySQL-Datenverzeichnis ersetzt wird.
Sobald A mit der korrekten Replikation begonnen hat, überwachen Sie den Seconds_Behind_Master im Slave-Status. Dies gibt Ihnen eine Vorstellung davon, wie weit der Sklave zurückgelassen hat und wie lange Sie warten müssen, bis er aufholt. An diesem Punkt sieht unsere Architektur so aus:
Sobald Seconds_Behind_Master auf 0 zurückfällt, ist das der Moment, in dem A als aktueller Slave aufgeholt hat.
Wenn Sie ClusterControl verwenden, haben Sie die Möglichkeit, den Knoten neu zu synchronisieren, indem Sie aus einer vorhandenen Sicherung wiederherstellen, oder die Sicherung direkt vom aktiven Master-Knoten erstellen und streamen:
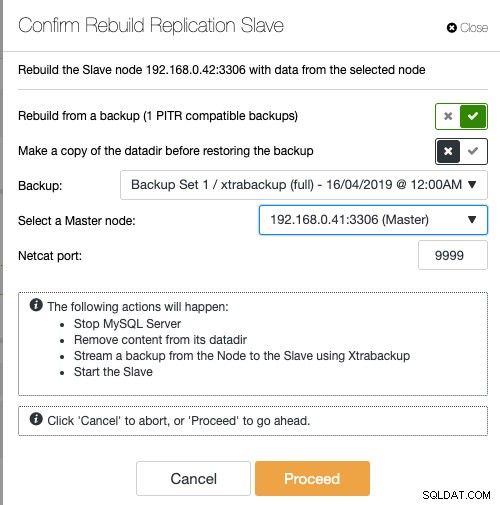
Das Bereitstellen des Slaves mit vorhandenem Backup ist die empfohlene Methode, um den Slave zu erstellen, da dies keine Auswirkungen auf den aktiven Master-Server beim Vorbereiten des Knotens hat.
Fördere den alten Meister
Bevor A zum neuen Master hochgestuft wird, ist es am sichersten, alle Schreibvorgänge auf B zu stoppen. Wenn dies nicht möglich ist, zwingen Sie B einfach, im Nur-Lese-Modus zu arbeiten:
mysql> SET GLOBAL read_only = 'ON';
mysql> SET GLOBAL super_read_only = 'ON';Führen Sie dann auf A SHOW SLAVE STATUS aus und überprüfen Sie den folgenden Replikationsstatus:
Read_Master_Log_Pos: 45889974
Exec_Master_Log_Pos: 45889974
Seconds_Behind_Master: 0
Slave_SQL_Running_State: Slave has read all relay log; waiting for more updatesDer Wert von Read_Master_Log_Pos und Exec_Master_Log_Pos muss identisch sein, während Seconds_Behind_Master 0 ist und der Status „Slave has read all relay log“ sein muss. Stellen Sie sicher, dass alle Slaves alle Anweisungen in ihrem Relay-Log verarbeitet haben, sonst riskieren Sie, dass die neuen Abfragen Transaktionen aus dem Relay-Log beeinflussen und alle möglichen Probleme auslösen (z. B. kann eine Anwendung einige Zeilen entfernen, auf die von Transaktionen zugegriffen wird aus dem Staffelprotokoll).
Stoppen Sie auf A die Replikation und verwenden Sie die Anweisung RESET SLAVE ALL, um alle replikationsbezogenen Konfigurationen zu entfernen und den Schreibschutz zu deaktivieren:
mysql> STOP SLAVE;
mysql> RESET SLAVE ALL;
mysql> SET GLOBAL read_only = 'OFF';
mysql> SET GLOBAL super_read_only = 'OFF';An diesem Punkt ist A bereit, Schreibvorgänge zu akzeptieren (read_only=OFF), jedoch sind keine Slaves damit verbunden, wie unten dargestellt:
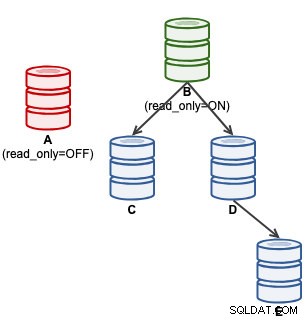
Für ClusterControl-Benutzer kann die Heraufstufung von A mit der Funktion „Promote Slave“ unter Node Actions erfolgen. ClusterControl wird den aktiven Master B automatisch degradieren, Slave A als Master hochstufen und C und D neu verweisen, um von A zu replizieren. B wird beiseite gelegt und der Benutzer muss explizit „Change Replication Master“ wählen, um zu einem späteren Zeitpunkt wieder B beizutreten, der von A repliziert .
Slave-Neuzuweisung
Es ist jetzt sicher, den Master auf verwandten Slaves zu ändern, um von A (192.168.0.41) zu replizieren. Konfigurieren Sie auf allen Slaves außer E Folgendes:
mysql> STOP SLAVE;
mysql> CHANGE MASTER TO MASTER_HOST = '192.168.0.41', MASTER_USER = 'rpl_user', MASTER_PASSWORD = 'p4ss', MASTER_AUTO_POSITION = 1;
mysql> START SLAVE;Wenn Sie ein ClusterControl-Benutzer sind, können Sie diesen Schritt überspringen, da die Neuverweisung automatisch durchgeführt wird, wenn Sie sich zuvor entschieden haben, A hochzustufen.
Wir können dann unsere Anwendung starten, um auf A zu schreiben. An diesem Punkt sieht unsere Architektur etwa so aus:
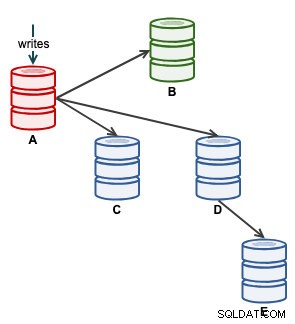
Aus der ClusterControl-Topologieansicht haben wir unseren Replikationscluster in seiner ursprünglichen Architektur wiederhergestellt, die wie folgt aussieht:
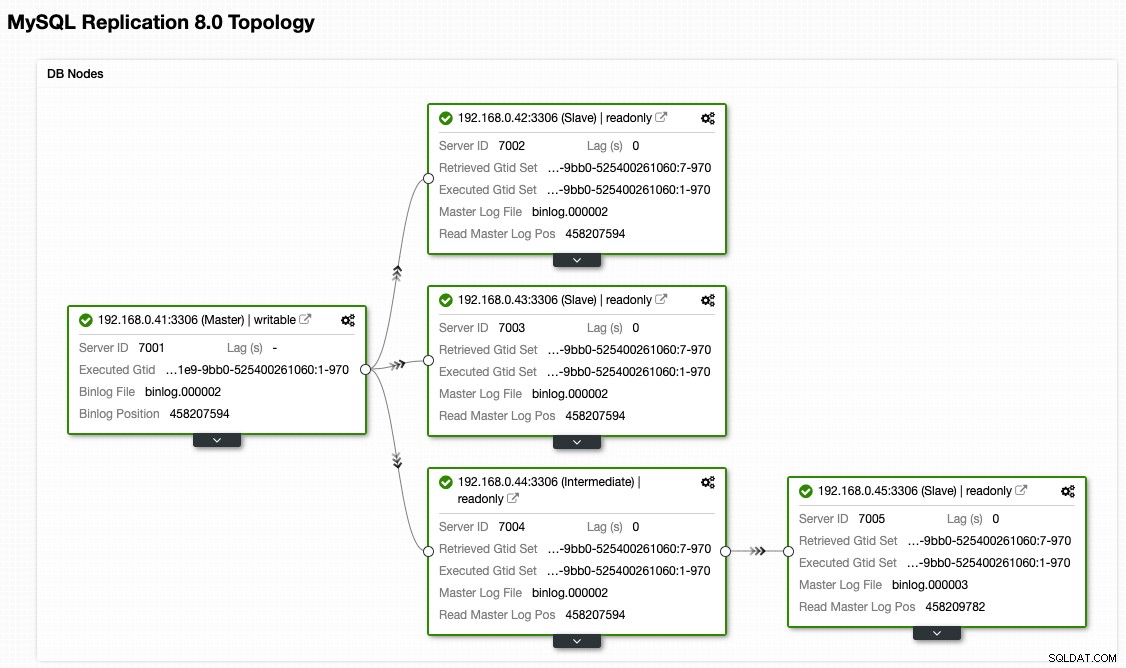
Beachten Sie, dass die Failback-Übung im Vergleich zum Failover viel weniger riskant ist. Es ist wichtig, diese Übung außerhalb der Spitzenzeiten zu planen, um die Auswirkungen auf Ihr Unternehmen so gering wie möglich zu halten.
Abschließende Gedanken
Failover- und Failback-Operationen müssen sorgfältig durchgeführt werden. Der Vorgang ist ziemlich einfach, wenn Sie eine kleine Anzahl von Knoten haben, aber für mehrere Knoten mit einer komplexen Replikationskette könnte es eine riskante und fehleranfällige Übung sein. Wir haben auch gezeigt, wie ClusterControl verwendet werden kann, um komplexe Vorgänge zu vereinfachen, indem sie über die Benutzeroberfläche ausgeführt werden. Außerdem wird die Topologieansicht in Echtzeit visualisiert, sodass Sie die Replikationstopologie verstehen, die Sie erstellen möchten.