Wenn ein Ausführungsplan einen Scan einer B-Tree-Indexstruktur enthält, kann die Speicher-Engine möglicherweise in der Lage sein, zwischen zwei physikalischen Zugangsstrategien zu wählen, wenn der Plan ausgeführt wird:
- Folgen Sie der b-Baumstruktur des Index; oder
- Suchen Sie Seiten anhand interner Seitenzuordnungsinformationen.
Wo eine Auswahl verfügbar ist, trifft die Speicher-Engine die Laufzeitentscheidung bei jeder Ausführung. Eine Neuzusammenstellung des Plans ist nicht erforderlich, damit es seine Meinung ändert.
Die B-Tree-Strategie beginnt an der Wurzel des Baums, steigt bis zu einem äußersten Rand der Blattebene ab (abhängig davon, ob der Scan vorwärts oder rückwärts erfolgt) und folgt dann Seitenverknüpfungen auf Blattebene, bis das andere Ende des Index erreicht ist . Die Zuordnungsstrategie verwendet Index Allocation Map (IAM)-Strukturen, um Datenbankseiten zu lokalisieren, die dem Index zugeordnet sind. Jede IAM-Seite ordnet Zuweisungen einem 4-GB-Intervall in einer einzelnen physischen Datenbankdatei zu, sodass beim Scannen der mit einem Index verknüpften IAM-Ketten tendenziell auf Indexseiten in der physischen Dateireihenfolge zugegriffen wird (zumindest soweit SQL Server dies erkennen kann).
Die Hauptunterschiede zwischen den beiden Strategien sind:
- Ein B-Tree-Scan kann Zeilen in der Reihenfolge der Indexschlüssel an den Abfrageprozessor liefern; ein IAM-gesteuerter Scan kann dies nicht;
- Ein B-Tree-Scan kann möglicherweise keine großen Read-Ahead-E/A-Anforderungen ausgeben, wenn logisch zusammenhängende Indexseiten nicht auch physisch zusammenhängend sind (z. B. als Ergebnis einer Seitenaufteilung im Index).
Für einen Index ist immer ein B-Tree-Scan verfügbar. Die Bedingungen, die häufig genannt werden, damit Zuordnungsreihenfolge-Scans verfügbar sind, sind:
- Der Abfrageplan muss einen ungeordneten Scan des Index zulassen;
- der Index muss mindestens 64 Seiten umfassen; und
- entweder ein
TABLOCKoderNOLOCKHinweis muss angegeben werden.
Die erste Bedingung bedeutet einfach, dass der Abfrageoptimierer den Scan mit dem Ordered:False markiert haben muss Eigentum. Markieren des Scans Ordered:False bedeutet, dass korrekte Ergebnisse aus dem Ausführungsplan nicht erforderlich sind der Scan, um Zeilen in der Reihenfolge der Indexschlüssel zurückzugeben (obwohl dies möglich ist, wenn es bequem oder anderweitig erforderlich ist).
Die zweite Bedingung (Größe) gilt nur für SQL Server 2005 und höher. Es spiegelt die Tatsache wider, dass die Durchführung eines IAM-gesteuerten Scans mit gewissen Anfangskosten verbunden ist, sodass eine Mindestanzahl von Seiten erforderlich ist, damit die potenziellen Einsparungen die Anfangsinvestition amortisieren. Die „64 Seiten“ beziehen sich auf den Wert von data_pages für IN_ROW_DATA Nur Zuordnungseinheit, wie in sys.allocation_units.
Natürlich kann sich ein Allokationsauftragsscan nur dann auszahlen, wenn die möglicherweise größeren Read-Ahead-Überlegungen tatsächlich ins Spiel kommen, aber SQL Server berücksichtigt diesen Faktor derzeit nicht. Insbesondere berücksichtigt es nicht, wie viel des Index sich derzeit im Arbeitsspeicher befindet, noch kümmert es sich darum, wie fragmentiert der Index ist.
Die dritte Bedingung ist wahrscheinlich die am wenigsten vollständige Beschreibung in der Liste. Hinweise sind eigentlich nicht erforderlich , obwohl sie verwendet werden können, um die realen Anforderungen zu erfüllen:Die Daten müssen sichergestellt sein, dass sie sich nicht ändern während des Scans, oder (umstrittener) wir müssen angeben, dass es uns egal ist über potenziell ungenaue Ergebnisse, indem Sie den Scan auf der Isolationsstufe „Read Uncommitted“ durchführen.
Auch mit diesen Klarstellungen ist die Liste der Bedingungen für einen zuweisungsgeordneten Scan immer noch nicht vollständig. Es gibt eine Reihe wichtiger Vorbehalte und Ausnahmen, auf die wir gleich noch eingehen werden.
Demo
Die folgende Abfrage verwendet die AdventureWorks-Beispieldatenbank:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P; Beachten Sie, dass die Personentabelle 3.869 Seiten enthält. Der (tatsächliche) Plan nach der Ausführung sieht wie folgt aus (im SQL Sentry Plan Explorer angezeigt):
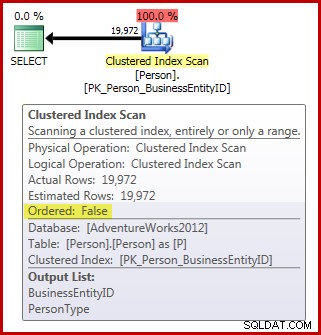
In Bezug auf die Scan-Anforderungen der Zuordnungsreihenfolge haben wir bisher:
- Der Plan hat den erforderlichen
Ordered:FalseEigentum; und, - die Tabelle hat mehr als 64 Seiten; sondern,
- Wir haben nichts unternommen, um sicherzustellen, dass sich die Daten während des Scans nicht ändern können. Angenommen, unsere Sitzung verwendet die Standardeinstellung read commit Isolationsstufe, der Scan wird nicht mit read uncommitted durchgeführt Isolationsstufe auch nicht.
Infolgedessen würden wir erwarten, dass dieser Scan durch Scannen des B-Baums durchgeführt wird, anstatt IAM-gesteuert zu sein. Die Abfrageergebnisse zeigen, dass dies wahrscheinlich zutrifft:
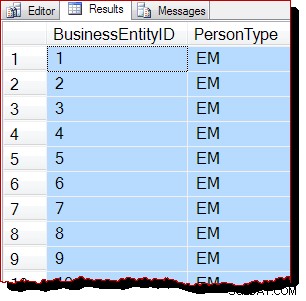
Die Zeilen werden in der Schlüsselreihenfolge des Clustered Index (nach BusinessEntityID) zurückgegeben ). Ich möchte klarstellen, dass diese Ergebnisreihenfolge absolut nicht garantiert ist , und man sollte sich nicht darauf verlassen. Geordnete Ergebnisse werden nur durch einen entsprechenden ORDER BY auf oberster Ebene garantiert Klausel.
Nichtsdestotrotz ist die beobachtete Ausgabereihenfolge ein Indiz dafür, dass der Scan dieses Mal durchgeführt wurde, indem der Clustered-Index-B-Baumstruktur gefolgt wurde. Wenn mehr Beweise benötigt werden, können wir einen Debugger anhängen und uns den Codepfad ansehen, den SQL Server während des Scans ausführt:

Der Aufrufstapel zeigt deutlich den Scan nach dem B-Baum.
Hinzufügen eines Tabellensperrhinweises
Wir modifizieren jetzt die Abfrage so, dass sie einen Tabellensperrhinweis enthält:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK); Auf der standardmäßigen Isolationsstufe für das Sperren von Lesevorgängen verhindert die gemeinsam genutzte Sperre auf Tabellenebene alle möglichen gleichzeitigen Änderungen an den Daten. Wenn alle drei Voraussetzungen für IAM-gesteuerte Scans erfüllt sind, würden wir jetzt erwarten, dass SQL Server einen Scan in Zuordnungsreihenfolge verwendet. Der Ausführungsplan ist derselbe wie zuvor, daher werde ich ihn nicht wiederholen, aber die Abfrageergebnisse sehen sicherlich anders aus:
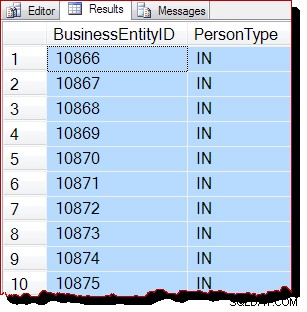
Die Ergebnisse sind anscheinend immer noch nach BusinessEntityID geordnet , aber der Startpunkt (10866) ist anders. In der Tat, wenn wir die Ergebnisse nach unten scrollen, stoßen wir bald auf Abschnitte, die offensichtlicher nicht in der richtigen Reihenfolge sind:
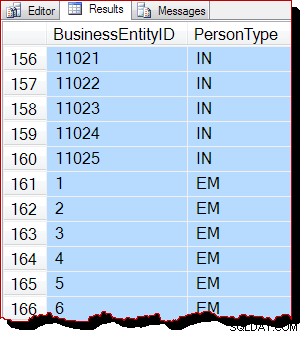
Die Teilreihenfolge ist darauf zurückzuführen, dass der Scan der Zuordnungsreihenfolge eine ganze Indexseite auf einmal verarbeitet. Die Ergebnisse innerhalb einer Seite zufällig nach dem Indexschlüssel geordnet zurückgegeben, aber die Reihenfolge der gescannten Seiten ist jetzt anders. Ich möchte noch einmal betonen, dass die Ergebnisse für Sie anders aussehen können:Es gibt keine Garantie für die Ausgabereihenfolge, nicht einmal innerhalb einer Seite, ohne ORDER BY auf oberster Ebene auf der ursprünglichen Abfrage.
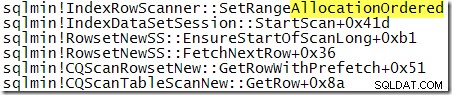
Zum Vergleich mit dem zuvor gezeigten Aufrufstapel ist dies ein Stack-Trace, der erhalten wurde, während SQL Server die Abfrage mit dem TABLOCK verarbeitete Hinweis:
Etwas weiter durch die Ausführung gehen:

Offensichtlich führt SQL Server einen nach Zuordnung geordneten Scan durch, wenn die Tabellensperre angegeben ist. Schade, dass es in einem Post-Execution-Plan keinen Hinweis darauf gibt, welche Art von Scan zur Laufzeit verwendet wurde. Zur Erinnerung:Die Art des Scans wird von der Speicher-Engine gewählt und kann sich zwischen den Ausführungen ohne Neukompilierung des Plans ändern.
Andere Möglichkeiten, die dritte Bedingung zu erfüllen
Ich habe bereits gesagt, dass wir für einen IAM-gesteuerten Scan sicherstellen müssen, dass sich die Daten während des Scans nicht ändern können, oder wir müssen die Abfrage auf der Read Uncommitted-Isolationsebene ausführen. Wir haben gesehen, dass ein Hinweis auf eine Tabellensperre zum Sperren der Read-Committed-Isolation ausreicht, um die erste dieser Anforderungen zu erfüllen, und es ist leicht zu zeigen, dass die Verwendung von NOLOCK/READUNCOMMITTED hint aktiviert auch einen Allocation-Order-Scan mit der Demo-Abfrage.
Tatsächlich gibt es viele Möglichkeiten, die dritte Bedingung zu erfüllen, einschließlich:
- Verändern des Index, um nur Tabellensperren zuzulassen;
- Die Datenbank schreibgeschützt machen (damit Daten garantiert nicht geändert werden); oder,
- Ändern der Sitzung Isolationsstufe auf
READ UNCOMMITTED.
Es gibt jedoch viel interessantere Variationen zu diesem Thema, die bedeuten, dass wir die drei zuvor genannten Bedingungen ändern müssen…
Isolationsstufen der Zeilenversionierung
Aktivieren Sie Read Committed Snapshot Isolation (RCSI) für die AdventureWorks-Datenbank und führen Sie den Test mit TABLOCK aus erneuter Hinweis (bei Read Committed Isolation):
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT ON
WITH ROLLBACK IMMEDIATE;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
GO
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (TABLOCK);
GO
ALTER DATABASE AdventureWorks2012
SET READ_COMMITTED_SNAPSHOT OFF
WITH ROLLBACK IMMEDIATE;
Bei aktivem RCSI wird ein index-ordered scan wird mit TABLOCK verwendet , nicht der Scan der Zuordnungsreihenfolge, den wir gerade gesehen haben. Der Grund ist der TABLOCK hint gibt eine gemeinsame Sperre auf Tabellenebene an, aber bei aktiviertem RCSI keine gemeinsamen Sperren sind vergeben. Ohne die gemeinsam genutzte Tabellensperre haben wir die Anforderung nicht erfüllt, gleichzeitige Änderungen an den Daten zu verhindern, während der Scan ausgeführt wird, sodass ein nach Zuordnung geordneter Scan nicht verwendet werden kann.
Es ist jedoch möglich, einen zuweisungsgeordneten Scan zu erreichen, wenn RCSI aktiviert ist. Eine Möglichkeit ist die Verwendung eines TABLOCKX hint (für eine exklusive Tabellenebene lock) statt TABLOCK . Wir könnten auch den TABLOCK beibehalten Hinweis und fügen Sie einen weiteren wie READCOMMITTEDLOCK hinzu , oder REPEATABLE READ oder SERIALIZABLE … und so weiter. All dies funktioniert, indem die Möglichkeit gleichzeitiger Änderungen verhindert wird, indem eine gemeinsam genutzte Tabellensperre verwendet wird, auf Kosten des Verlusts der Vorteile von RCSI . Wir können auch immer noch einen Scan der Zuordnungsreihenfolge mit einem NOLOCK erreichen oder READUNCOMMITTED Hinweis natürlich.
Die Situation unter Snapshot Isolation (SI) ist der RCSI sehr ähnlich und wird aus Platzgründen nicht im Detail untersucht.
TABLESAMPLE führt immer* einen Scan der Zuordnungsreihenfolge durch
Das TABLESAMPLE -Klausel ist eine interessante Ausnahme von vielen Dingen, die wir bisher besprochen haben.
Angabe eines TABLESAMPLE -Klausel führt immer* zu einem Allocation-Order-Scan, sogar unter RCSI oder SI und sogar ohne Hinweise. Um es klar zu sagen, der Scan der Zuordnungsreihenfolge, der sich aus der Verwendung von TABLESAMPLE ergibt behält die RCSI/SI-Semantik bei – der Scan verwendet Zeilenversionen und das Lesen blockiert nicht das Schreiben (und umgekehrt).
Eine zweite Überraschung ist, dass TABLESAMPLE always* führt einen IAM-gesteuerten Scan durch, selbst wenn die Tabelle weniger als 64 Seiten hat . Das macht Sinn, weil die Dokumentation zumindest andeutet, dass das SYSTEM Die Stichprobenmethode verwendet die IAM-Struktur (es gibt also keine andere Wahl, als einen Scan der Zuordnungsreihenfolge durchzuführen):
SYSTEM Ist eine implementierungsabhängige Stichprobenmethode, die durch ISO-Standards spezifiziert ist. In SQL Server ist dies die einzige verfügbare Stichprobenmethode und wird standardmäßig angewendet. SYSTEM wendet eine seitenbasierte Stichprobenmethode an, bei der ein zufälliger Satz von Seiten aus der Tabelle für die Stichprobe ausgewählt wird und alle Zeilen auf diesen Seiten als Stichprobenteilmenge zurückgegeben werden.
* Eine Ausnahme tritt auf, wenn ROWS oder PERCENT Spezifikation in TABLESAMPLE Klausel bedeutet 100 % der Tabelle. Angabe weiterer ROWS als die Metadaten angeben, die derzeit in der Tabelle sind, funktionieren auch nicht. Verwendung von TABLESAMPLE SYSTEM (100 PERCENT) oder gleichwertig wird nicht Erzwingen Sie einen Scan der Zuordnungsreihenfolge.
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
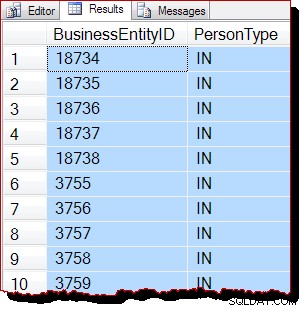
TABLESAMPLE SYSTEM (50 ROWS)
REPEATABLE (12345678)
--WITH (TABLOCK); Ergebnisse:
Die Auswirkung von TOP und SET ROWCOUNT
Kurz gesagt, beides hat keinen Einfluss auf die Entscheidung, einen Scan der Zuordnungsreihenfolge zu verwenden oder nicht. Dies mag in Fällen überraschend erscheinen, in denen "offensichtlich" weniger als 64 Seiten gescannt werden.
Beispielsweise verwenden die folgenden Abfragen beide einen IAM-gesteuerten Scan, um 5 Zeilen aus einem Scan zurückzugeben:
SELECT TOP (5)
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 5;
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P WITH (TABLOCK)
SET ROWCOUNT 0; Die Ergebnisse sind für beide gleich:
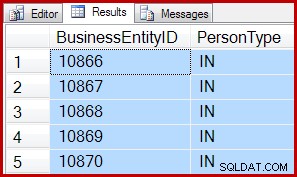
Das bedeutet TOP und SET ROWCOUNT Abfragen könnten den Overhead für die Einrichtung eines Scans in Zuordnungsreihenfolge, selbst wenn weniger als 64 Seiten gescannt werden. Zur Abschwächung könnten komplexere TOP-Abfragen mit selektiven Prädikaten, die in den Scan geschoben werden, immer noch von einem Scan der Zuordnungsreihenfolge profitieren. Wenn der Scan 10.000 Seiten verarbeiten muss, um die ersten 5 übereinstimmenden Zeilen zu finden, könnte ein Scan der Zuordnungsreihenfolge immer noch ein Gewinn sein.
Alle* Scans der Zuordnungsreihenfolge instanzweit verhindern
Dies ist etwas, das Sie wahrscheinlich niemals absichtlich tun würden, aber es gibt eine Servereinstellung, die Scans in der Zuordnungsreihenfolge für alle* Benutzerabfragen in allen Datenbanken verhindert.
So unwahrscheinlich es scheinen mag, die fragliche Einstellung ist die Serverkonfigurationsoption für den Cursor-Schwellenwert, die in der Online-Dokumentation wie folgt beschrieben wird:
Die Cursorschwellenwertoption gibt die Anzahl der Zeilen im Cursorsatz an, bei denen Cursorschlüsselsätze asynchron generiert werden. Wenn Cursor ein Keyset für eine Ergebnismenge generieren, schätzt der Abfrageoptimierer die Anzahl der Zeilen, die für diese Ergebnismenge zurückgegeben werden. Wenn der Abfrageoptimierer schätzt, dass die Anzahl der zurückgegebenen Zeilen größer als dieser Schwellenwert ist, wird der Cursor asynchron generiert, sodass der Benutzer Zeilen aus dem Cursor abrufen kann, während der Cursor weiterhin gefüllt wird. Andernfalls wird der Cursor synchron generiert und die Abfrage wartet, bis alle Zeilen zurückgegeben werden.
Wenn der cursor threshold auf einen anderen Wert als –1 (Standardeinstellung) gesetzt ist, werden keine Scans der Zuordnungsreihenfolge für Benutzerabfragen in Datenbanken auf der SQL Server-Instanz ausgeführt.
Mit anderen Worten, wenn die asynchrone Cursorauffüllung aktiviert ist, keine IAM-gesteuerten Scans für Sie.
* Die Ausnahme ist (nicht 100 %) TABLESAMPLE Abfragen. Auch die vom System generierten internen Abfragen zur Statistikerstellung und Statistikaktualisierung verwenden weiterhin Allocation-Ordered Scans.
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
GO
-- WARNING! Disables allocation-order scans instance-wide
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = 5000;
RECONFIGURE WITH OVERRIDE;
GO
-- Would normally result in an allocation-order scan
SELECT
P.BusinessEntityID,
P.PersonType
FROM Person.Person AS P
WITH (READUNCOMMITTED);
GO
-- Reset to default allocation-order scans
EXECUTE sys.sp_configure
@configname = 'cursor threshold',
@configvalue = -1;
RECONFIGURE WITH OVERRIDE; Ergebnisse (kein Allocation-Order-Scan):
Man kann nur vermuten, dass die asynchrone Cursorbestückung aus irgendeinem Grund nicht gut mit Scans der Zuordnungsreihenfolge funktioniert. Es ist völlig unerwartet, dass diese Einschränkung alle Nicht-Cursor-Benutzerabfragen betreffen würde aber auch. Vielleicht ist es für SQL Server zu schwer zu erkennen, ob eine Abfrage als Teil eines extern ausgegebenen API-Cursors ausgeführt wird? Wer weiß.
Es wäre schön, wenn dieser Nebeneffekt irgendwo offiziell dokumentiert würde, obwohl es schwierig ist, genau zu wissen, wo er in Books Online hingehört. Ich frage mich, wie viele Produktionssysteme da draußen aus diesem Grund keine Scans der Zuordnungsreihenfolge verwenden? Vielleicht nicht viele, aber man weiß nie.
Zum Abschluss hier noch eine Zusammenfassung. Ein nach Zuordnung geordneter Scan ist verfügbar, wenn:
- Die Serveroption
cursor thresholdist auf –1 (Standardwert) eingestellt; und, - der Scan-Operator des Abfrageplans hat den
Ordered:FalseEigentum; und, - die gesamten data_pages des
IN_ROW_DATAZuordnungseinheiten mindestens 64; und, - entweder:
- SQL Server hat eine akzeptable Garantie, dass gleichzeitige Änderungen unmöglich sind; oder,
- Der Scan wird auf der Isolationsstufe „Lesen ohne Commit“ ausgeführt.
Unabhängig davon ein Scan mit einem TABLESAMPLE -Klausel verwendet immer zuweisungsgeordnete Scans (mit der einen technischen Ausnahme, die im Haupttext erwähnt wird).