Dies ist der vierte Teil einer Serie über Lösungen für die Zahlenreihen-Generator-Challenge. Vielen Dank an Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson #2, Ed Wagner, Michael Burbea und Paul White für das Teilen Ihrer Ideen und Kommentare. P>
Ich liebe die Arbeit von Paul White. Ich bin immer wieder schockiert von seinen Entdeckungen und frage mich, wie zum Teufel er herausfindet, was er tut. Ich liebe auch seinen effizienten und eloquenten Schreibstil. Wenn ich seine Artikel oder Posts lese, schüttle ich oft den Kopf und sage meiner Frau Lilach, dass ich, wenn ich groß bin, genau wie Paul sein möchte.
Als ich die Herausforderung ursprünglich gepostet habe, hatte ich insgeheim gehofft, dass Paul eine Lösung posten würde. Ich wusste, dass es etwas ganz Besonderes werden würde, wenn er es täte. Nun, er hat es getan, und es ist faszinierend! Es hat eine hervorragende Leistung, und Sie können eine Menge davon lernen. Dieser Artikel ist der Lösung von Paulus gewidmet.
Ich werde meine Tests in tempdb durchführen und E/A- und Zeitstatistiken aktivieren:
SET NOCOUNT ON; USE tempdb; SET STATISTICS TIME, IO ON;
Einschränkungen früherer Ideen
Bei der Bewertung früherer Lösungen war einer der wichtigsten Faktoren für eine gute Leistung die Fähigkeit zur Stapelverarbeitung. Aber haben wir es so weit wie möglich ausgeschöpft?
Lassen Sie uns die Pläne für zwei der früheren Lösungen untersuchen, die die Stapelverarbeitung verwendeten. In Teil 1 habe ich die Funktion dbo.GetNumsAlanCharlieItzikBatch behandelt, die Ideen von Alan, Charlie und mir kombinierte.
Hier ist die Definition der Funktion:
-- Helper dummy table
DROP TABLE IF EXISTS dbo.BatchMe;
GO
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
GO
-- Function definition
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Diese Lösung definiert einen Basis-Tabellenwertkonstruktor mit 16 Zeilen und eine Reihe von kaskadierenden CTEs mit Kreuzverknüpfungen, um die Anzahl der Zeilen auf potenziell 4 B zu erhöhen. Die Lösung verwendet die ROW_NUMBER-Funktion, um die Basissequenz von Zahlen in einem CTE namens Nums zu erstellen, und den TOP-Filter, um die gewünschte Kardinalität der Zahlenreihe zu filtern. Um die Stapelverarbeitung zu ermöglichen, verwendet die Lösung einen Dummy-Left-Join mit einer falschen Bedingung zwischen dem CTE von Nums und einer Tabelle namens dbo.BatchMe, die einen Columnstore-Index hat.
Verwenden Sie den folgenden Code, um die Funktion mit der Variablenzuweisungstechnik zu testen:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Die Plan-Explorer-Darstellung des tatsächlichen Der Plan für diese Ausführung ist in Abbildung 1 dargestellt.
 Abbildung 1:Plan für die dbo.GetNumsAlanCharlieItzikBatch-Funktion
Abbildung 1:Plan für die dbo.GetNumsAlanCharlieItzikBatch-Funktion
Bei der Analyse der Verarbeitung im Stapelmodus und im Zeilenmodus ist es ganz nett, wenn man einfach anhand eines Plans auf hoher Ebene erkennen kann, welchen Verarbeitungsmodus jeder Operator verwendet hat. Tatsächlich zeigt der Plan-Explorer eine hellblaue Batch-Figur im unteren linken Teil des Operators an, wenn der tatsächliche Ausführungsmodus Batch ist. Wie Sie in Abbildung 1 sehen können, ist der einzige Operator, der den Batchmodus verwendet hat, der Window Aggregate-Operator, der die Zeilennummern berechnet. Es gibt noch viel Arbeit von anderen Operatoren im Zeilenmodus.
Hier sind die Leistungszahlen, die ich in meinem Test erhalten habe:
CPU-Zeit =10032 ms, verstrichene Zeit =10025 ms.logisch liest 0
Um zu ermitteln, welche Operatoren am meisten Zeit für die Ausführung benötigt haben, verwenden Sie entweder die Option Actual Execution Plan in SSMS oder die Option Get Actual Plan im Plan Explorer. Stellen Sie sicher, dass Sie Pauls kürzlich erschienenen Artikel Understanding Execution Plan Operator Timings lesen. Der Artikel beschreibt, wie die gemeldeten Operator-Ausführungszeiten normalisiert werden, um die korrekten Zahlen zu erhalten.
Im Plan in Abbildung 1 wird die meiste Zeit von den Operatoren Nested Loops und Top ganz links verbracht, die beide im Zeilenmodus ausgeführt werden. Abgesehen davon, dass der Zeilenmodus für CPU-intensive Vorgänge weniger effizient als der Stapelmodus ist, sollten Sie auch bedenken, dass das Umschalten vom Zeilen- in den Stapelmodus und zurück zusätzliche Kosten verursacht.
In Teil 2 habe ich eine andere Lösung behandelt, die Stapelverarbeitung verwendet und in der Funktion dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 implementiert ist. Diese Lösung kombinierte Ideen von John Number2, Dave Mason, Joe Obbish, Alan, Charlie und mir. Der Hauptunterschied zwischen der vorherigen Lösung und dieser Lösung besteht darin, dass erstere als Basiseinheit einen virtuellen Tabellenwertkonstruktor und letztere eine tatsächliche Tabelle mit einem Columnstore-Index verwendet, sodass Sie die Stapelverarbeitung „kostenlos“ erhalten. Hier ist der Code, der die Tabelle erstellt und sie mithilfe einer INSERT-Anweisung mit 102.400 Zeilen füllt, damit sie komprimiert wird:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO Hier ist die Definition der Funktion:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Ein einziger Cross-Join zwischen zwei Instanzen der Basistabelle reicht aus, um weit über das gewünschte Potenzial von 4B-Zeilen hinaus zu produzieren. Auch hier verwendet die Lösung die ROW_NUMBER-Funktion, um die Basisfolge von Zahlen zu erzeugen, und den TOP-Filter, um die gewünschte Zahlenreihenkardinalität einzuschränken.
Hier ist der Code zum Testen der Funktion mit der Variablenzuweisungstechnik:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
Der Plan für diese Ausführung ist in Abbildung 2 dargestellt.
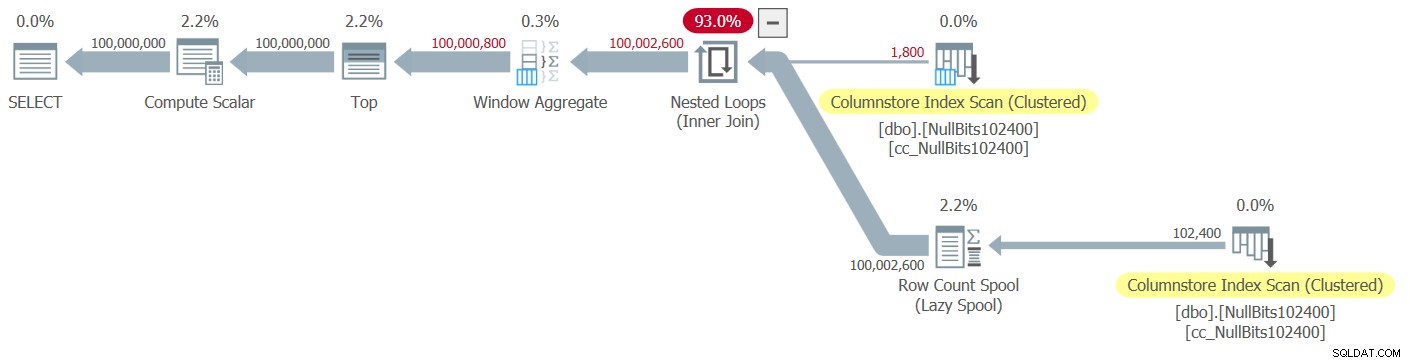 Abbildung 2:Plan für die Funktion dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Abbildung 2:Plan für die Funktion dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Beachten Sie, dass nur zwei Operatoren in diesem Plan den Stapelmodus verwenden – der obere Scan des gruppierten Columnstore-Index der Tabelle, der als äußere Eingabe des Nested Loops-Joins verwendet wird, und der Window Aggregate-Operator, der zum Berechnen der Basiszeilennummern verwendet wird .
Ich habe die folgenden Leistungszahlen für meinen Test erhalten:
CPU-Zeit =9812 ms, verstrichene Zeit =9813 ms.Tabelle 'NullBits102400'. Scan-Anzahl 2, logische Lesevorgänge 0, physische Lesevorgänge 0, Page-Server-Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Page-Server-Read-Ahead-Lesevorgänge 0, logische Lob-Lesezugriffe 8, Lob-Physical Reads 0, Lob-Page-Server-Lesungen 0, Lob-Read- Ahead lautet 0, Read-Ahead des Lob-Page-Servers lautet 0.
Tabelle 'NullBits102400'. Segment liest 2, Segment übersprungen 0.
Auch hier wird die meiste Zeit bei der Ausführung dieses Plans von den äußerst linken Nested Loops und Top-Operatoren aufgewendet, die im Zeilenmodus ausgeführt werden.
Pauls Lösung
Bevor ich Pauls Lösung präsentiere, beginne ich mit meiner Theorie bezüglich des Denkprozesses, den er durchlaufen hat. Dies ist eigentlich eine großartige Lernübung, und ich schlage vor, dass Sie sie durchgehen, bevor Sie sich die Lösung ansehen. Paul erkannte die schwächenden Auswirkungen eines Plans, der sowohl Stapel- als auch Zeilenmodi mischt, und stellte sich der Herausforderung, eine Lösung zu finden, die einen Plan für alle Stapelmodi erhält. Im Erfolgsfall ist das Potenzial für eine gute Leistung einer solchen Lösung recht hoch. Es ist sicherlich interessant zu sehen, ob ein solches Ziel überhaupt erreichbar ist, da es immer noch viele Betreiber gibt, die den Batch-Modus noch nicht unterstützen, und viele Faktoren, die die Batch-Verarbeitung behindern. Zum Zeitpunkt des Verfassens dieses Artikels ist beispielsweise der Hash-Join-Algorithmus der einzige Join-Algorithmus, der Stapelverarbeitung unterstützt. Ein Cross Join wird mithilfe des Nested-Loops-Algorithmus optimiert. Außerdem ist der Top-Operator derzeit nur im Zeilenmodus implementiert. Diese beiden Elemente sind wichtige grundlegende Elemente, die in den Plänen für viele der Lösungen verwendet werden, die ich bisher behandelt habe, einschließlich der beiden oben genannten.
Angenommen, Sie haben die Herausforderung, eine Lösung mit einem Plan im Batch-Modus zu erstellen, einen anständigen Versuch gewagt, fahren wir mit der zweiten Übung fort. Ich werde zunächst Pauls Lösung so präsentieren, wie er sie bereitgestellt hat, mit seinen Inline-Kommentaren. Ich werde es auch ausführen, um seine Leistung mit den anderen Lösungen zu vergleichen. Ich habe viel gelernt, indem ich seine Lösung Schritt für Schritt dekonstruiert und rekonstruiert habe, um sicherzustellen, dass ich genau verstehe, warum er jede seiner Techniken verwendet hat. Ich schlage vor, dass Sie dasselbe tun, bevor Sie meine Erklärungen lesen.
Hier ist Pauls Lösung, die eine Columnstore-Hilfstabelle namens dbo.CS und eine Funktion namens dbo.GetNums_SQLkiwi beinhaltet:
-- Helper columnstore table
DROP TABLE IF EXISTS dbo.CS;
-- 64K rows (enough for 4B rows when cross joined)
-- column 1 is always zero
-- column 2 is (1...65536)
SELECT
-- type as integer NOT NULL
-- (everything is normalized to 64 bits in columnstore/batch mode anyway)
n1 = ISNULL(CONVERT(integer, 0), 0),
n2 = ISNULL(CONVERT(integer, N.rn), 0)
INTO dbo.CS
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
rn ASC
OFFSET 0 ROWS
FETCH NEXT 65536 ROWS ONLY
) AS N;
-- Single compressed rowgroup of 65,536 rows
CREATE CLUSTERED COLUMNSTORE INDEX CCI
ON dbo.CS
WITH (MAXDOP = 1);
GO
-- The function
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scala
@low - 2 + N.rn < @high;
GO Hier ist der Code, den ich verwendet habe, um die Funktion mit der Variablenzuweisungstechnik zu testen:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000);
Ich habe den in Abbildung 3 gezeigten Plan für meinen Test bekommen.
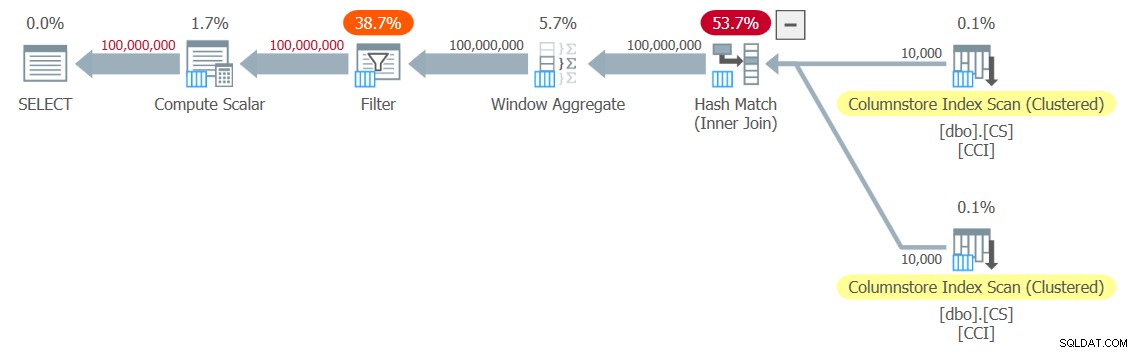 Abbildung 3:Plan für die dbo.GetNums_SQLkiwi-Funktion
Abbildung 3:Plan für die dbo.GetNums_SQLkiwi-Funktion
Es ist ein All-Batch-Modus-Plan! Das ist ziemlich beeindruckend.
Hier sind die Leistungszahlen, die ich für diesen Test auf meiner Maschine erhalten habe:
CPU-Zeit =7812 ms, verstrichene Zeit =7876 ms.Tabelle 'CS'. Scan-Anzahl 2, logische Lesevorgänge 0, physische Lesevorgänge 0, Page-Server liest 0, Read-Ahead-Lesevorgänge 0, Page-Server-Read-Ahead-Lesevorgänge 0, logische Lob-Lesezugriffe 44, Lob-physische Lesevorgänge 0, Lob-Page-Server liest 0, Lob-Lese- Ahead lautet 0, Read-Ahead des Lob-Page-Servers lautet 0.
Tabelle 'CS'. Segment liest 2, Segment übersprungen 0.
Lassen Sie uns auch überprüfen, ob die Lösung, wenn Sie die nach n geordneten Zahlen zurückgeben müssen, die Reihenfolge in Bezug auf rn bewahrt – zumindest wenn Sie Konstanten als Eingaben verwenden – und somit eine explizite Sortierung im Plan vermeiden. Hier ist der Code, um es mit der Bestellung zu testen:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000) ORDER BY n;
Sie erhalten denselben Plan wie in Abbildung 3 und daher ähnliche Leistungszahlen:
CPU-Zeit =7765 ms, verstrichene Zeit =7822 ms.Tabelle 'CS'. Scan-Anzahl 2, logische Lesevorgänge 0, physische Lesevorgänge 0, Page-Server liest 0, Read-Ahead-Lesevorgänge 0, Page-Server-Read-Ahead-Lesevorgänge 0, logische Lob-Lesezugriffe 44, Lob-physische Lesevorgänge 0, Lob-Page-Server liest 0, Lob-Lese- Ahead lautet 0, Read-Ahead des Lob-Page-Servers lautet 0.
Tabelle 'CS'. Segment liest 2, Segment übersprungen 0.
Das ist ein wichtiger Aspekt der Lösung.
Änderung unserer Testmethodik
Die Leistung von Pauls Lösung ist eine anständige Verbesserung sowohl der verstrichenen Zeit als auch der CPU-Zeit im Vergleich zu den beiden vorherigen Lösungen, aber es scheint nicht die dramatischere Verbesserung zu sein, die man von einem All-Batch-Modus-Plan erwarten würde. Vielleicht übersehen wir etwas?
Lassen Sie uns versuchen, die Ausführungszeiten der Operatoren zu analysieren, indem wir uns den tatsächlichen Ausführungsplan in SSMS ansehen, wie in Abbildung 4 gezeigt.
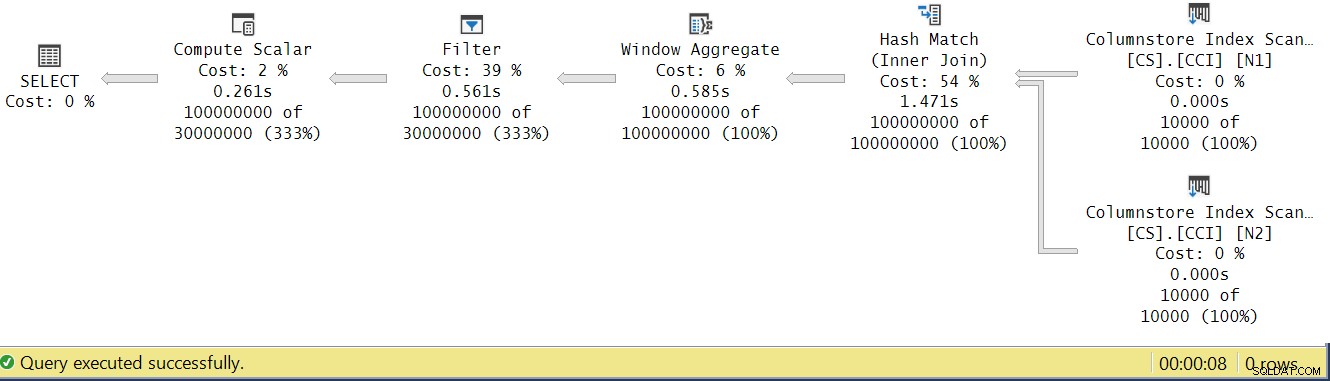 Abbildung 4:Operatorausführungszeiten für die Funktion dbo.GetNums_SQLkiwi
Abbildung 4:Operatorausführungszeiten für die Funktion dbo.GetNums_SQLkiwi
In Pauls Artikel über die Analyse der Ausführungszeiten von Operatoren erklärt er, dass bei Stapelmodusoperatoren jeder seine eigene Ausführungszeit meldet. Wenn Sie die Ausführungszeiten aller Operatoren in diesem tatsächlichen Plan summieren, erhalten Sie 2,878 Sekunden, aber die Ausführung des Plans dauerte 7,876. 5 Sekunden der Ausführungszeit scheinen zu fehlen. Die Antwort darauf liegt in der Testtechnik, die wir verwenden, mit der Variablenzuweisung. Denken Sie daran, dass wir uns für diese Technik entschieden haben, um die Notwendigkeit zu beseitigen, alle Zeilen vom Server an den Aufrufer zu senden, und um die E/A-Vorgänge zu vermeiden, die beim Schreiben des Ergebnisses in eine Tabelle erforderlich wären. Es schien die perfekte Option zu sein. Die wahren Kosten der Variablenzuweisung sind jedoch in diesem Plan verborgen, und er wird natürlich im Zeilenmodus ausgeführt. Rätsel gelöst.
Letztendlich ist ein guter Test natürlich ein Test, der Ihre Produktionsnutzung der Lösung angemessen widerspiegelt. Wenn Sie die Daten normalerweise in eine Tabelle schreiben, muss Ihr Test dies widerspiegeln. Wenn Sie das Ergebnis an den Anrufer senden, muss Ihr Test dies widerspiegeln. Jedenfalls scheint die Variablenzuweisung in unserem Test einen großen Teil der Ausführungszeit zu repräsentieren, und es ist ganz klar unwahrscheinlich, dass sie eine typische Verwendung der Funktion in der Produktion darstellt. Paul schlug vor, dass der Test anstelle einer Variablenzuweisung ein einfaches Aggregat wie MAX auf die zurückgegebene Zahlenspalte (n/rn/op) anwenden könnte. Ein Aggregatoperator kann die Stapelverarbeitung verwenden, sodass der Plan aufgrund seiner Verwendung keine Umstellung vom Stapel- auf den Zeilenmodus beinhalten würde, und sein Beitrag zur Gesamtlaufzeit sollte ziemlich gering und bekannt sein.
Lassen Sie uns also alle drei in diesem Artikel behandelten Lösungen erneut testen. Hier ist der Code zum Testen der Funktion dbo.GetNumsAlanCharlieItzikBatch:
SELECT MAX(n) AS mx FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Ich habe den in Abbildung 5 gezeigten Plan für diesen Test erhalten.
 Abbildung 5:Plan für dbo.GetNumsAlanCharlieItzikBatch-Funktion mit Aggregat
Abbildung 5:Plan für dbo.GetNumsAlanCharlieItzikBatch-Funktion mit Aggregat
Hier sind die Leistungszahlen, die ich für diesen Test erhalten habe:
CPU-Zeit =8469 ms, verstrichene Zeit =8733 ms.logisch liest 0
Beachten Sie, dass die Laufzeit von 10,025 Sekunden mit der Variablenzuweisungstechnik auf 8,733 Sekunden mit der Aggregattechnik gesunken ist. Das ist etwas mehr als eine Sekunde Ausführungszeit, die wir hier der Variablenzuweisung zuschreiben können.
Hier ist der Code zum Testen der Funktion dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
SELECT MAX(n) AS mx FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
Ich habe den in Abbildung 6 gezeigten Plan für diesen Test erhalten.
 Abbildung 6:Plan für die Funktion dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 mit Aggregat
Abbildung 6:Plan für die Funktion dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 mit Aggregat
Hier sind die Leistungszahlen, die ich für diesen Test erhalten habe:
CPU-Zeit =7031 ms, verstrichene Zeit =7053 ms.Tabelle 'NullBits102400'. Scan-Anzahl 2, logische Lesevorgänge 0, physische Lesevorgänge 0, Page-Server-Lesevorgänge 0, Read-Ahead-Lesevorgänge 0, Page-Server-Read-Ahead-Lesevorgänge 0, logische Lob-Lesezugriffe 8, Lob-Physical Reads 0, Lob-Page-Server-Lesungen 0, Lob-Read- Ahead lautet 0, Read-Ahead des Lob-Page-Servers lautet 0.
Tabelle 'NullBits102400'. Segment liest 2, Segment übersprungen 0.
Beachten Sie, dass die Laufzeit von 9,813 Sekunden mit der Variablenzuweisungstechnik auf 7,053 Sekunden mit der Aggregattechnik gesunken ist. Das sind etwas mehr als zwei Sekunden Ausführungszeit, die wir hier der Variablenzuweisung zuschreiben können.
Und hier ist der Code zum Testen von Pauls Lösung:
SELECT MAX(n) AS mx FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(MAXDOP 1);
Ich erhalte den in Abbildung 7 gezeigten Plan für diesen Test.
 Abbildung 7:Plan für dbo.GetNums_SQLkiwi-Funktion mit Aggregat
Abbildung 7:Plan für dbo.GetNums_SQLkiwi-Funktion mit Aggregat
Und jetzt zum großen Moment. Ich habe die folgenden Leistungszahlen für diesen Test:
CPU-Zeit =3125 ms, verstrichene Zeit =3149 ms.Tabelle 'CS'. Scan-Anzahl 2, logische Lesevorgänge 0, physische Lesevorgänge 0, Page-Server liest 0, Read-Ahead-Lesevorgänge 0, Page-Server-Read-Ahead-Lesevorgänge 0, logische Lob-Lesezugriffe 44, Lob-physische Lesevorgänge 0, Lob-Page-Server liest 0, Lob-Lese- Ahead lautet 0, Read-Ahead des Lob-Page-Servers lautet 0.
Tabelle 'CS'. Segment liest 2, Segment übersprungen 0.
Die Laufzeit sank von 7,822 Sekunden auf 3,149 Sekunden! Untersuchen wir die Operatorausführungszeiten im tatsächlichen Plan in SSMS, wie in Abbildung 8 gezeigt.
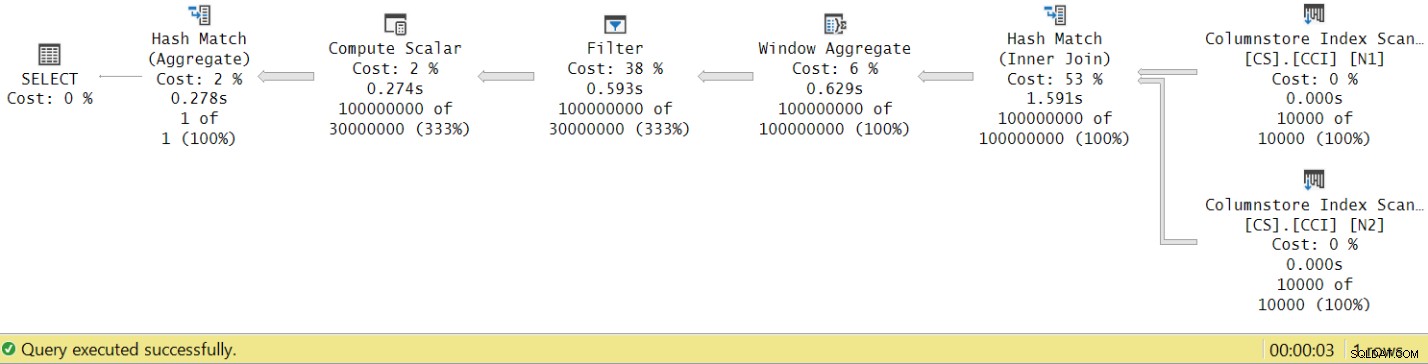 Abbildung 8:Operatorausführungszeiten für die dbo.GetNums-Funktion mit Aggregat
Abbildung 8:Operatorausführungszeiten für die dbo.GetNums-Funktion mit Aggregat
Wenn Sie nun die Ausführungszeiten der einzelnen Operatoren kumulieren, erhalten Sie eine ähnliche Zahl wie die Gesamtausführungszeit des Plans.
Abbildung 9 zeigt einen Leistungsvergleich in Bezug auf die verstrichene Zeit zwischen den drei Lösungen unter Verwendung sowohl der Variablenzuweisungs- als auch der Aggregattesttechniken.
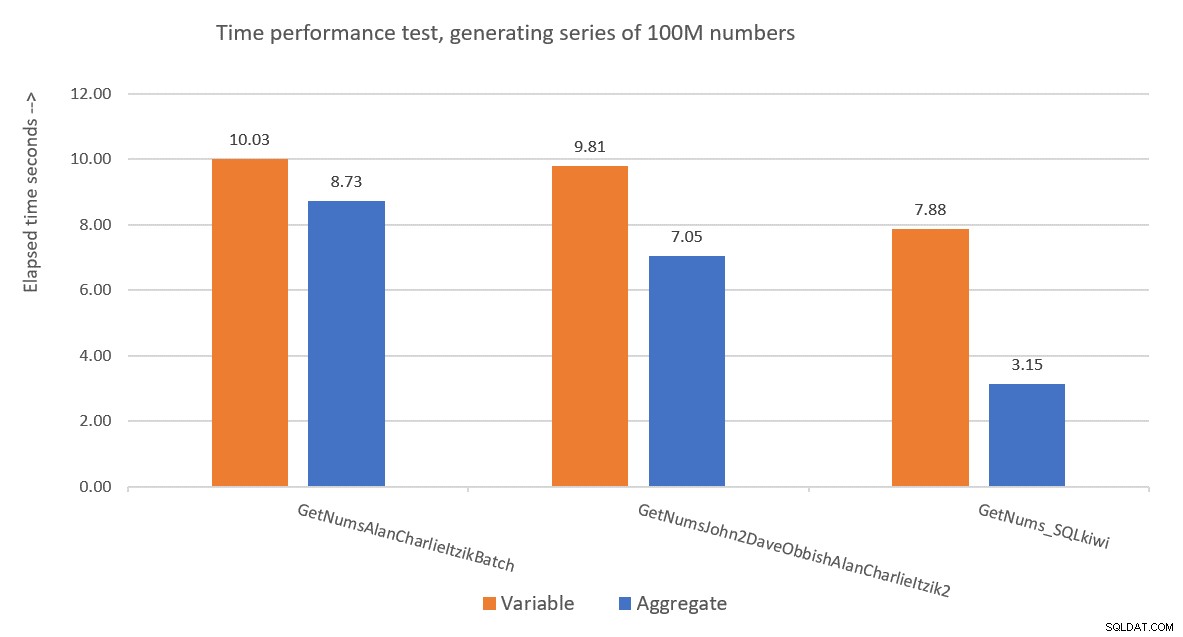 Abbildung 9:Leistungsvergleich
Abbildung 9:Leistungsvergleich
Pauls Lösung ist ein klarer Gewinner, und dies wird besonders deutlich, wenn die Aggregat-Testtechnik verwendet wird. Was für eine beeindruckende Leistung!
Dekonstruktion und Rekonstruktion der Lösung von Paul
Das Dekonstruieren und anschließende Rekonstruieren von Pauls Lösung ist eine großartige Übung, und Sie lernen dabei viel. Wie bereits vorgeschlagen, empfehle ich Ihnen, den Prozess selbst durchzugehen, bevor Sie weiterlesen.
Die erste Wahl, die Sie treffen müssen, ist die Technik, die Sie verwenden würden, um die gewünschte potenzielle Anzahl von Reihen von 4B zu erzeugen. Paul entschied sich für die Verwendung einer Columnstore-Tabelle und füllte sie mit so vielen Zeilen wie die Quadratwurzel der erforderlichen Zahl, also 65.536 Zeilen, sodass Sie mit einem einzigen Cross Join die erforderliche Zahl erhalten würden. Vielleicht denken Sie, dass Sie mit weniger als 102.400 Zeilen keine komprimierte Zeilengruppe erhalten würden, aber dies gilt, wenn Sie die Tabelle mit einer INSERT-Anweisung füllen, wie wir es mit der Tabelle dbo.NullBits102400 getan haben. Sie gilt nicht, wenn Sie einen Columnstore-Index für eine vorab ausgefüllte Tabelle erstellen. Also verwendete Paul eine SELECT INTO-Anweisung, um die Tabelle als Rowstore-basierten Heap mit 65.536 Zeilen zu erstellen und zu füllen, und erstellte dann einen gruppierten Columnstore-Index, was zu einer komprimierten Zeilengruppe führte.
Die nächste Herausforderung besteht darin, herauszufinden, wie ein Cross-Join mit einem Batch-Modus-Operator verarbeitet werden kann. Dazu muss der Join-Algorithmus Hash sein. Denken Sie daran, dass ein Cross Join mithilfe des Nested-Loops-Algorithmus optimiert wird. Sie müssen den Optimierer irgendwie dazu bringen, zu glauben, dass Sie einen inneren Equijoin verwenden (Hash erfordert mindestens ein gleichheitsbasiertes Prädikat), aber in der Praxis einen Cross Join erhalten.
Ein offensichtlicher erster Versuch besteht darin, einen Inner Join mit einem künstlichen Join-Prädikat zu verwenden, das immer wahr ist, etwa so:
SELECT *
FROM dbo.CS AS N1
INNER HASH JOIN dbo.CS AS N2
ON 0 = 0; Aber dieser Code schlägt mit dem folgenden Fehler fehl:
Nachricht 8622, Ebene 16, Status 1, Zeile 246Der Abfrageprozessor konnte aufgrund der in dieser Abfrage definierten Hinweise keinen Abfrageplan erstellen. Senden Sie die Abfrage erneut, ohne Hinweise anzugeben und ohne SET FORCEPLAN zu verwenden.
Der Optimierer von SQL Server erkennt, dass dies ein künstliches Inner Join-Prädikat ist, vereinfacht den Inner Join zu einem Cross Join und erzeugt einen Fehler, der besagt, dass er den Hinweis zum Erzwingen eines Hash-Join-Algorithmus nicht berücksichtigen kann.
Um dies zu lösen, erstellte Paul in seiner dbo.CS-Tabelle eine INT NOT NULL-Spalte (mehr dazu in Kürze) mit dem Namen n1 und füllte sie mit 0 in allen Zeilen. Dann verwendete er das Join-Prädikat N2.n1 =N1.n1, wodurch er effektiv die Proposition 0 =0 in allen Übereinstimmungsbewertungen erhielt, während er die Mindestanforderungen für einen Hash-Join-Algorithmus erfüllte.
Dies funktioniert und erzeugt einen All-Batch-Modus-Plan:
SELECT *
FROM dbo.CS AS N1
INNER HASH JOIN dbo.CS AS N2
ON N2.n1 = N1.n1; Was den Grund dafür betrifft, dass n1 als INT NOT NULL definiert wird; warum NULLs verbieten und warum nicht BIGINT verwenden? Der Grund für diese Auswahl besteht darin, einen Hash-Sonde-Residuum (einen zusätzlichen Filter, der vom Hash-Join-Operator über das ursprüngliche Join-Prädikat hinaus angewendet wird) zu vermeiden, was zu zusätzlichen unnötigen Kosten führen könnte. Weitere Informationen finden Sie in Pauls Artikel Join-Leistung, implizite Konvertierungen und Residuen. Hier ist der Teil des Artikels, der für uns relevant ist:
„Wenn sich der Join auf einer einzelnen Spalte befindet, die als tinyint, smallint oder integer typisiert ist, und wenn beide Spalten auf NOT NULL beschränkt sind, ist die Hash-Funktion ‚perfekt‘ – was bedeutet, dass es keine Chance einer Hash-Kollision gibt, und der Abfrageprozessor muss die Werte nicht erneut auf Übereinstimmung prüfen.Beachten Sie, dass diese Optimierung nicht für bigint-Spalten gilt."
Um diesen Aspekt zu überprüfen, erstellen wir eine weitere Tabelle namens dbo.CS2 mit einer n1-Spalte, die Nullwerte zulässt:
DROP TABLE IF EXISTS dbo.CS2; SELECT * INTO dbo.CS2 FROM dbo.CS; ALTER TABLE dbo.CS2 ALTER COLUMN n1 INT NULL; CREATE CLUSTERED COLUMNSTORE INDEX CCI ON dbo.CS2 WITH (MAXDOP = 1);
Lassen Sie uns zuerst eine Abfrage gegen dbo.CS testen (wobei n1 als INT NOT NULL definiert ist), 4B-Basiszeilennummern in einer Spalte namens rn generieren und das MAX-Aggregat auf die Spalte anwenden:
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
) AS N; Wir werden den Plan für diese Abfrage mit dem Plan für eine ähnliche Abfrage für dbo.CS2 vergleichen (wobei n1 als INT NULL definiert ist):
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS2 AS N1
JOIN dbo.CS2 AS N2
ON N2.n1 = N1.n1
) AS N; Die Pläne für beide Abfragen sind in Abbildung 10 dargestellt.
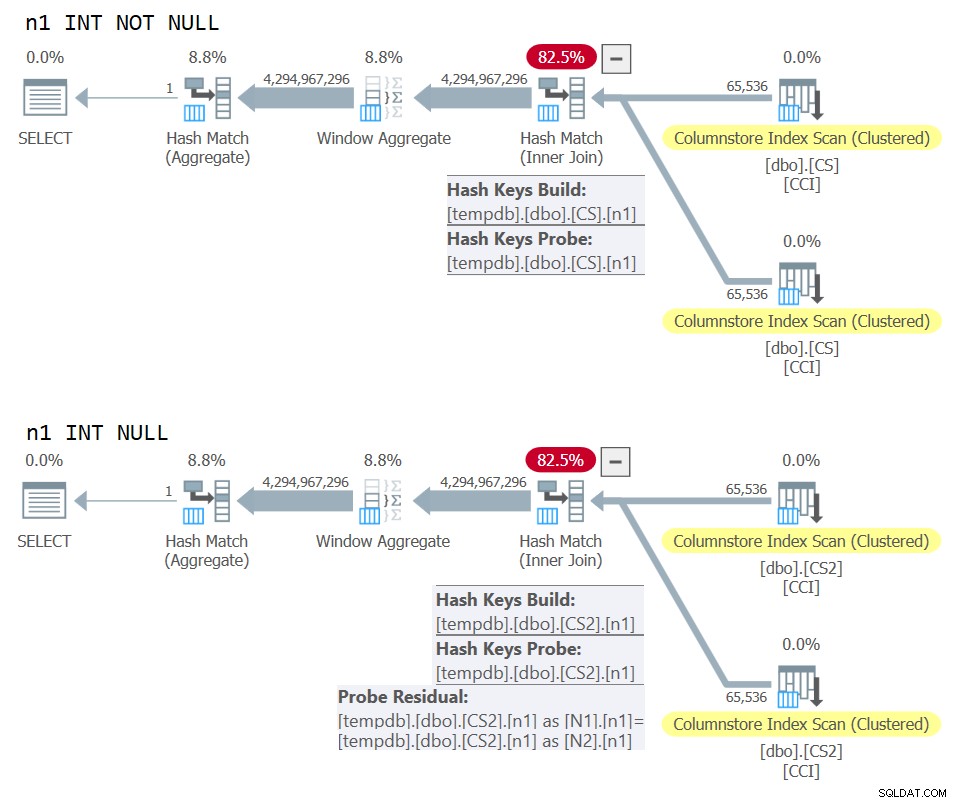 Abbildung 10:Planvergleich für den Join-Schlüssel NOT NULL vs. NULL
Abbildung 10:Planvergleich für den Join-Schlüssel NOT NULL vs. NULL
Sie können deutlich den zusätzlichen Sondenrest sehen, der im zweiten Plan angewendet wird, aber nicht im ersten.
Auf meinem Rechner wurde die Abfrage von dbo.CS in 91 Sekunden und die Abfrage von dbo.CS2 in 92 Sekunden abgeschlossen. In Pauls Artikel berichtet er für das von ihm verwendete Beispiel von einem Unterschied von 11 % zugunsten des NOT NULL-Falls.
Übrigens, diejenigen unter Ihnen mit einem scharfen Auge werden die Verwendung von ORDER BY @@TRANCOUNT als Bestellspezifikation der ROW_NUMBER-Funktion bemerkt haben. Wenn Sie Pauls Inline-Kommentare in seiner Lösung sorgfältig lesen, erwähnt er, dass die Verwendung der Funktion @@TRANCOUNT ein Parallelitätshemmer ist, während die Verwendung von @@SPID dies nicht ist. Sie können also @@TRANCOUNT als Laufzeitkonstante in der Bestellspezifikation verwenden, wenn Sie einen seriellen Plan erzwingen möchten, und @@SPID, wenn Sie dies nicht tun.
Wie bereits erwähnt, dauerte es 91 Sekunden, bis die Abfrage von dbo.CS auf meinem Computer ausgeführt wurde. An dieser Stelle könnte es interessant sein, den gleichen Code mit einem echten Cross-Join zu testen, wobei der Optimierer einen Join-Algorithmus mit verschachtelten Schleifen im Zeilenmodus verwendet:
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
CROSS JOIN dbo.CS AS N2
) AS N; Es dauerte 104 Sekunden, bis dieser Code auf meinem Computer abgeschlossen war. Wir erhalten also eine beträchtliche Leistungsverbesserung mit dem Batch-Modus-Hash-Join.
Unser nächstes Problem ist die Tatsache, dass Sie bei Verwendung von TOP zum Filtern der gewünschten Anzahl von Zeilen einen Plan mit einem Top-Operator im Zeilenmodus erhalten. Hier ist ein Versuch, die Funktion dbo.GetNums_SQLkiwi mit einem TOP-Filter zu implementieren:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT TOP (100000000 - 1 + 1)
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
ORDER BY rn
) AS N;
GO Testen wir die Funktion:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
Ich habe den in Abbildung 11 gezeigten Plan für diesen Test erhalten.
 Abbildung 11:Plan mit TOP-Filter
Abbildung 11:Plan mit TOP-Filter
Beachten Sie, dass der Top-Operator der einzige im Plan ist, der die Verarbeitung im Zeilenmodus verwendet.
Ich habe die folgenden Zeitstatistiken für diese Ausführung:
CPU-Zeit =6078 ms, verstrichene Zeit =6071 ms.Der größte Teil der Laufzeit in diesem Plan wird vom Top-Operator im Zeilenmodus und der Tatsache aufgewendet, dass der Plan die Batch-zu-Zeilenmodus-Konvertierung und zurück durchlaufen muss.
Unsere Herausforderung besteht darin, eine Batch-Modus-Filteralternative zum Row-Modus-TOP zu finden. Auf Prädikaten basierende Filter, wie sie mit der WHERE-Klausel angewendet werden, können möglicherweise mit Stapelverarbeitung behandelt werden.
Pauls Ansatz bestand darin, eine zweite INT-Typ-Spalte einzuführen (siehe den Inline-Kommentar „Im Columnstore/Batch-Modus ist sowieso alles auf 64-Bit normalisiert“). ) mit dem Namen n2 in die Tabelle dbo.CS und füllen Sie sie mit der Ganzzahlfolge 1 bis 65.536. Im Code der Lösung verwendete er zwei prädikatbasierte Filter. Einer ist ein grober Filter in der inneren Abfrage mit Prädikaten, die die Spalte n2 von beiden Seiten des Joins betreffen. Dieser Grobfilter kann zu einigen Fehlalarmen führen. Hier ist der erste vereinfachte Versuch eines solchen Filters:
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1)))) Mit den Eingaben 1 und 100.000.000 als @low und @high erhalten Sie keine Fehlalarme. Aber versuchen Sie es mit 1 und 100.000.001, und Sie bekommen einige. Sie erhalten eine Folge von 100.020.001 Zahlen statt 100.000.001.
Um die falsch positiven Ergebnisse zu eliminieren, fügte Paul einen zweiten, präzisen Filter hinzu, der die Spalte rn in der äußeren Abfrage einbezog. Hier ist der erste vereinfachte Versuch eines so präzisen Filters:
WHERE
-- Precise filter:
N.rn < @high - @low + 2 Lassen Sie uns die Definition der Funktion überarbeiten, um die obigen prädikatbasierten Filter anstelle von TOP zu verwenden, nehmen Sie 1:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
) AS N
WHERE
-- Precise filter:
N.rn < @high - @low + 2;
GO Testen wir die Funktion:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
Ich habe den in Abbildung 12 gezeigten Plan für diesen Test erhalten.
 Abbildung 12:Plan mit WHERE-Filter, nehmen Sie 1
Abbildung 12:Plan mit WHERE-Filter, nehmen Sie 1
Leider ist etwas offensichtlich schief gelaufen. SQL Server hat unseren Prädikat-basierten Filter mit der Spalte rn in einen TOP-basierten Filter umgewandelt und mit einem Top-Operator optimiert – genau das wollten wir vermeiden. Um das Ganze noch schlimmer zu machen, entschied sich der Optimierer außerdem, den Nested-Loop-Algorithmus für den Join zu verwenden.
Es dauerte 18,8 Sekunden, bis dieser Code auf meinem Computer fertig war. Sieht nicht gut aus.
In Bezug auf die Verknüpfung mit verschachtelten Schleifen könnten wir dies leicht mit einem Verknüpfungshinweis in der inneren Abfrage erledigen. Nur um die Auswirkungen auf die Leistung zu sehen, ist hier ein Test mit einem erzwungenen Hash-Join-Abfragehinweis, der in der Testabfrage selbst verwendet wird:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(HASH JOIN);
Die Laufzeit reduziert sich auf 13,2 Sekunden.
Wir haben immer noch das Problem mit der Umwandlung des WHERE-Filters gegen rn in einen TOP-Filter. Versuchen wir zu verstehen, wie das passiert ist. Wir haben den folgenden Filter in der äußeren Abfrage verwendet:
WHERE N.rn < @high - @low + 2
Denken Sie daran, dass rn einen nicht manipulierten ROW_NUMBER-basierten Ausdruck darstellt. Ein Filter, der darauf basiert, dass sich ein solcher nicht manipulierter Ausdruck in einem bestimmten Bereich befindet, wird häufig mit einem Top-Operator optimiert, was für uns aufgrund der Verwendung der Zeilenmodusverarbeitung eine schlechte Nachricht ist.
Pauls Problemumgehung bestand darin, ein äquivalentes Prädikat zu verwenden, aber eines, das Manipulationen auf rn anwendet, etwa so:
WHERE @low - 2 + N.rn < @high
Filtering an expression that adds manipulation to a ROW_NUMBER-based expression inhibits the conversion of the predicate-based filter to a TOP-based one. That’s brilliant!
Let’s revise the function’s definition to use the above WHERE predicate, take 2:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
) AS N
WHERE
-- Precise filter:
@low - 2 + N.rn < @high;
GO Test the function again, without any special hints or anything:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
It naturally gets an all-batch-mode plan with a hash join algorithm and no Top operator, resulting in an execution time of 3.177 seconds. Looking good.
The next step is to check if the solution handles bad inputs well. Let’s try it with a negative delta:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(100000000, 1);
This execution fails with the following error.
Msg 3623, Level 16, State 1, Line 436An invalid floating point operation occurred.
The failure is due to the attempt to apply a square root of a negative number.
Paul’s solution involved two additions. One is to add the following predicate to the inner query’s WHERE clause:
@high >= @low
This filter does more than what it seems initially. If you’ve read Paul’s inline comments carefully, you could find this part:
“Try to avoid SQRT on negative numbers and enable simplification to single constant scan if @low> @high (with literals). No start-up filters in batch mode.”The intriguing part here is the potential to use a constant scan with constants as inputs. I’ll get to this shortly.
The other addition is to apply the IIF function to the input expression to the SQRT function. This is done to avoid negative input when using nonconstants as inputs to our numbers function, and in case the optimizer decides to handle the predicate involving SQRT before the predicate @high>=@low.
Before the IIF addition, for example, the predicate involving N1.n2 looked like this:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
After adding IIF, it looks like this:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
With these two additions, we’re now basically ready for the final definition of the dbo.GetNums_SQLkiwi function:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scalar
@low - 2 + N.rn < @high;
GO Now back to the comment about the constant scan. When using constants that result in a negative range as inputs to the function, e.g., 100,000,000 and 1 as @low and @high, after parameter embedding the WHERE filter of the inner query looks like this:
WHERE
1 >= 100000000
AND ... The whole plan can then be simplified to a single Constant Scan operator. Try it:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(100000000, 1);
The plan for this execution is shown in Figure 13.
 Figure 13:Plan with constant scan
Figure 13:Plan with constant scan
Unsurprisingly, I got the following performance numbers for this execution:
CPU time =0 ms, elapsed time =0 ms.logical reads 0
When passing a negative range with nonconstants as inputs, the use of the IIF function will prevent any attempt to compute a square root of a negative input.
Now let’s test the function with a valid input range:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
You get the all-batch-mode plan shown in Figure 14.
 Figure 14:Plan for dbo.GetNums_SQLkiwi function
Figure 14:Plan for dbo.GetNums_SQLkiwi function
This is the same plan you saw earlier in Figure 7.
I got the following time statistics for this execution:
CPU time =3000 ms, elapsed time =3111 ms.Ladies and gentlemen, I think we have a winner! :)
Schlussfolgerung
I’ll have what Paul’s having.
Are we done yet, or is this series going to last forever?
No and no.