Wenn es um die Abfrageleistung geht, gibt es in SQL Server viele großartige Informationsquellen, und einer meiner Favoriten ist der Abfrageplan selbst. In den letzten Versionen, insbesondere beginnend mit SQL Server 2012, wurden mit jeder neuen Version mehr Details in die Ausführungspläne aufgenommen. Während die Liste der Verbesserungen weiter wächst, sind hier ein paar Attribute, die ich als wertvoll empfunden habe:
- NonParallelPlanReason (SQL Server 2012)
- Restprädikat-Pushdown-Diagnose (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016 SP1)
- Diagnose von Tempdb-Überlauf (SQL Server 2012 SP3, SQL Server 2014 SP2, SQL Server 2016)
- Trace-Flags aktiviert (SQL Server 2012 SP4, SQL Server 2014 SP2, SQL Server 2016 SP1)
- Ausführungsstatistiken für Operatorabfragen (SQL Server 2014 SP2, SQL Server 2016)
- Maximaler Arbeitsspeicher für eine einzelne Abfrage aktiviert (SQL Server 2014 SP2, SQL Server 2016 SP1)
Um anzuzeigen, was für jede Version von SQL Server vorhanden ist, besuchen Sie die Seite Showplan Schema, auf der Sie das Schema für jede Version seit SQL Server 2005 finden können.
So sehr ich all diese zusätzlichen Daten liebe, ist es wichtig zu beachten, dass einige Informationen für einen tatsächlichen Ausführungsplan relevanter sind als für einen geschätzten (z. B. tempdb-Überlaufinformationen). An manchen Tagen können wir den tatsächlichen Plan erfassen und für die Fehlerbehebung verwenden, an anderen Tagen müssen wir den geschätzten Plan verwenden. Sehr oft erhalten wir diesen geschätzten Plan – den Plan, der möglicherweise für problematische Ausführungen verwendet wurde – aus dem Plan-Cache von SQL Server. Und das Abrufen einzelner Pläne ist angemessen, wenn Sie eine bestimmte Abfrage oder einen Satz oder Abfragen optimieren. Aber was ist, wenn Sie Ideen brauchen, wo Sie Ihre Optimierungsbemühungen in Bezug auf Muster konzentrieren können?
Der SQL Server-Plancache ist eine erstaunliche Informationsquelle, wenn es um die Leistungsoptimierung geht, und ich meine nicht nur die Fehlerbehebung und den Versuch, zu verstehen, was in einem System ausgeführt wird. In diesem Fall spreche ich über das Mining von Informationen aus den Plänen selbst, die in sys.dm_exec_query_plan zu finden sind und als XML in der Spalte query_plan gespeichert sind.
Wenn Sie diese Daten mit Informationen aus sys.dm_exec_sql_text (damit Sie den Text der Abfrage leicht anzeigen können) und sys.dm_exec_query_stats (Ausführungsstatistiken) kombinieren, können Sie plötzlich damit beginnen, nicht nur nach den Abfragen zu suchen, die die Schwergewichte sind, oder auszuführen am häufigsten, aber diejenigen Pläne, die einen bestimmten Join-Typ oder Index-Scan enthalten, oder diejenigen, die die höchsten Kosten verursachen. Dies wird allgemein als Mining des Plan-Cache bezeichnet, und es gibt mehrere Blog-Posts, die darüber sprechen, wie man das macht. Mein Kollege Jonathan Kehayias sagt, dass er es hasst, XML zu schreiben, aber er hat mehrere Posts mit Abfragen zum Mining des Plan-Cache:
- Optimieren des „Kostenschwellenwerts für Parallelität“ aus dem Plan-Cache
- Implizite Spaltenkonvertierungen im Plan-Cache finden
- Feststellen, welche Abfragen im Plan-Cache einen bestimmten Index verwenden
- Den SQL-Plan-Cache durchsuchen:Fehlende Indizes finden
- Schlüsselsuchen im Plan-Cache finden
Wenn Sie noch nie untersucht haben, was sich in Ihrem Plan-Cache befindet, sind die Abfragen in diesen Beiträgen ein guter Anfang. Der Plan-Cache hat jedoch seine Grenzen. Beispielsweise ist es möglich, eine Abfrage auszuführen, ohne dass der Plan in den Cache geht. Wenn Sie beispielsweise die Option „Optimieren für Ad-hoc-Workloads“ aktiviert haben, wird bei der ersten Ausführung der kompilierte Plan-Stub im Plan-Cache gespeichert, nicht der vollständig kompilierte Plan. Die größte Herausforderung besteht jedoch darin, dass der Plan-Cache temporär ist. Es gibt viele Ereignisse in SQL Server, die den Plancache vollständig löschen oder ihn für eine Datenbank löschen können, und Pläne können aus dem Cache gelöscht werden, wenn sie nicht verwendet werden, oder nach einer Neukompilierung entfernt werden. Um dem entgegenzuwirken, müssen Sie in der Regel entweder den Plancache regelmäßig abfragen oder den Inhalt regelmäßig in einer Tabelle speichern.
Dies ändert sich in SQL Server 2016 mit Abfragespeicher.
Wenn für eine Benutzerdatenbank der Abfragespeicher aktiviert ist, werden der Text und die Pläne für Abfragen, die für diese Datenbank ausgeführt werden, erfasst und in internen Tabellen gespeichert. Anstelle einer vorübergehenden Ansicht dessen, was derzeit ausgeführt wird, haben wir ein langfristiges Bild dessen, was zuvor ausgeführt wurde. Die Menge der aufbewahrten Daten wird durch die Einstellung CLEANUP_POLICY bestimmt, die standardmäßig 30 Tage beträgt. Verglichen mit einem Plan-Cache, der nur einige Stunden der Abfrageausführung darstellen kann, sind die Daten des Abfragespeichers ein Wendepunkt.
Stellen Sie sich ein Szenario vor, in dem Sie eine Indexanalyse durchführen – Sie haben einige Indizes, die nicht verwendet werden, und Sie haben einige Empfehlungen aus den fehlenden Index-DMVs. Die fehlenden Index-DMVs enthalten keine Details darüber, welche Abfrage die fehlende Indexempfehlung generiert hat. Sie können den Plan-Cache abfragen, indem Sie die Abfrage aus Jonathans Post „Finding Missing Indexes“ verwenden. Wenn ich das für meine lokale SQL Server-Instanz ausführe, erhalte ich ein paar Ausgabezeilen, die sich auf einige Abfragen beziehen, die ich zuvor ausgeführt habe.

Ich kann den Plan im Plan-Explorer öffnen und sehe, dass beim SELECT-Operator eine Warnung angezeigt wird, die für den fehlenden Index steht:
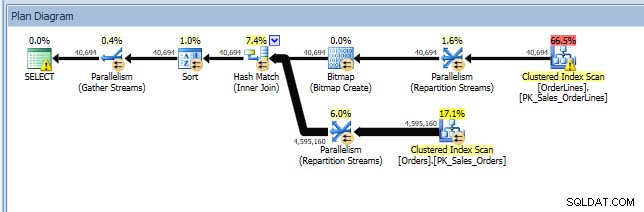
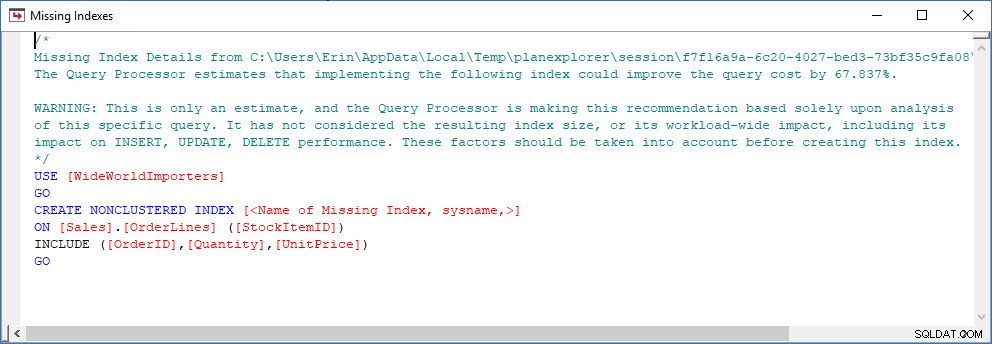
Dies ist ein großartiger Anfang, aber auch hier hängt meine Ausgabe davon ab, was sich im Cache befindet. Ich kann Jonathans Abfrage nehmen und für den Abfragespeicher modifizieren und sie dann gegen meine WideWorldImporters-Demodatenbank ausführen:
USE WideWorldImporters;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT TRY_CONVERT(XML, [qsp].[query_plan]) AS [query_plan]
FROM sys.query_store_plan [qsp]) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1;
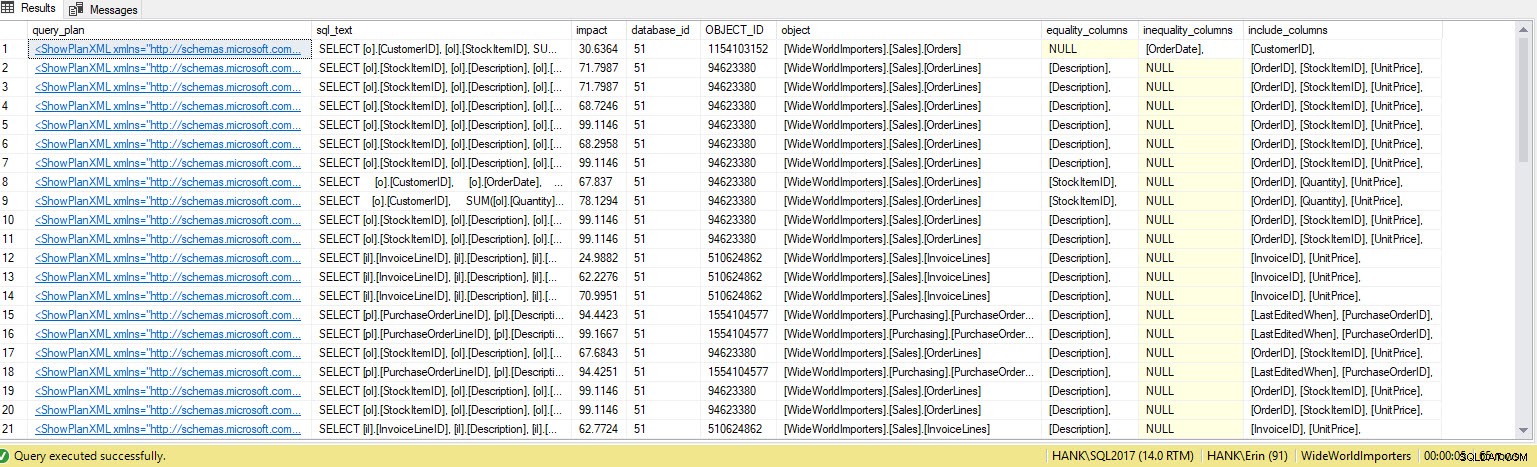
Ich bekomme viel mehr Zeilen in der Ausgabe. Auch hier stellen die Abfragespeicherdaten eine größere Ansicht der Abfragen dar, die für das System ausgeführt werden, und die Verwendung dieser Daten gibt uns eine umfassende Methode, um nicht nur zu bestimmen, welche Indizes fehlen, sondern auch, welche Abfragen diese Indizes unterstützen würden. Von hier aus können wir tiefer in den Abfragespeicher eintauchen und uns Leistungsmetriken und Ausführungshäufigkeit ansehen, um die Auswirkungen der Indexerstellung zu verstehen und zu entscheiden, ob die Abfrage oft genug ausgeführt wird, um den Index zu rechtfertigen.
Wenn Sie Query Store nicht, aber SentryOne verwenden, können Sie dieselben Informationen aus der SentryOne-Datenbank extrahieren. Der Abfrageplan wird in der Tabelle dbo.PerformanceAnalysisPlan in einem komprimierten Format gespeichert, daher ist die von uns verwendete Abfrage eine ähnliche Variante wie die obige, aber Sie werden feststellen, dass auch die DECOMPRESS-Funktion verwendet wird:
USE SentryOne;
GO
WITH XMLNAMESPACES
(DEFAULT 'https://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
query_plan,
n.value('(@StatementText)[1]', 'VARCHAR(4000)') AS sql_text,
n.value('(//MissingIndexGroup/@Impact)[1]', 'FLOAT') AS impact,
DB_ID(PARSENAME(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)'),1)) AS database_id,
OBJECT_ID(n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')) AS OBJECT_ID,
n.value('(//MissingIndex/@Database)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Schema)[1]', 'VARCHAR(128)') + '.' +
n.value('(//MissingIndex/@Table)[1]', 'VARCHAR(128)')
AS object,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'EQUALITY'
FOR XML PATH('')
) AS equality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INEQUALITY'
FOR XML PATH('')
) AS inequality_columns,
( SELECT DISTINCT c.value('(@Name)[1]', 'VARCHAR(128)') + ', '
FROM n.nodes('//ColumnGroup') AS t(cg)
CROSS APPLY cg.nodes('Column') AS r(c)
WHERE cg.value('(@Usage)[1]', 'VARCHAR(128)') = 'INCLUDE'
FOR XML PATH('')
) AS include_columns
FROM (
SELECT query_plan
FROM
(
SELECT -- need to decompress the gzipped xml here:
CONVERT(xml, CONVERT(nvarchar(max), CONVERT(varchar(max), DECOMPRESS(PlanTextGZ)))) AS [query_plan]
FROM dbo.PerformanceAnalysisPlan) tp
WHERE tp.query_plan.exist('//MissingIndex')=1
) AS tab (query_plan)
CROSS APPLY query_plan.nodes('//StmtSimple') AS q(n)
WHERE n.exist('QueryPlan/MissingIndexes') = 1; Auf einem SentryOne-System hatte ich die folgende Ausgabe (und natürlich öffnet das Klicken auf einen der query_plan-Werte den grafischen Plan):

Einige Vorteile, die SentryOne gegenüber Query Store bietet, sind, dass Sie diese Art der Sammlung nicht pro Datenbank aktivieren müssen und die überwachte Datenbank die Speicheranforderungen nicht unterstützen muss, da alle Daten im Repository gespeichert werden. Sie können diese Informationen auch in allen unterstützten Versionen von SQL Server erfassen, nicht nur in denen, die den Abfragespeicher unterstützen. Beachten Sie jedoch, dass SentryOne nur Abfragen sammelt, die Schwellenwerte wie Dauer und Lesevorgänge überschreiten. Sie können diese Standardschwellenwerte anpassen, aber es ist ein Punkt, den Sie beim Mining der SentryOne-Datenbank beachten sollten:Möglicherweise werden nicht alle Abfragen erfasst. Außerdem ist die DECOMPRESS-Funktion erst ab SQL Server 2016 verfügbar; für ältere Versionen von SQL Server möchten Sie entweder:
- Sichern Sie die SentryOne-Datenbank und stellen Sie sie auf SQL Server 2016 oder höher wieder her, um die Abfragen auszuführen;
- Bcp die Daten aus der Tabelle dbo.PerformanceAnalysisPlan und importiere sie in eine neue Tabelle auf einer SQL Server 2016-Instanz;
- die SentryOne-Datenbank über einen Verbindungsserver von einer SQL Server 2016-Instanz abfragen; oder,
- Die Datenbank vom Anwendungscode abfragen, der nach dem Dekomprimieren nach bestimmten Dingen suchen kann.
Mit SentryOne haben Sie die Möglichkeit, nicht nur den Plan-Cache zu minen, sondern auch die im SentryOne-Repository gespeicherten Daten. Wenn Sie SQL Server 2016 oder höher ausführen und den Abfragespeicher aktiviert haben, finden Sie diese Informationen auch in sys.query_store_plan . Sie sind nicht auf dieses Beispiel zum Auffinden fehlender Indizes beschränkt; Alle Abfragen von Jonathans anderen Plan-Cache-Posts können geändert werden, um zum Mining von Daten aus SentryOne oder aus dem Query Store verwendet zu werden. Wenn Sie außerdem mit XQuery vertraut sind (oder bereit sind, es zu lernen), können Sie das Showplan-Schema verwenden, um herauszufinden, wie Sie den Plan parsen, um die gewünschten Informationen zu finden. Dies gibt Ihnen die Möglichkeit, Muster und Antimuster in Ihren Abfrageplänen zu finden, die Ihr Team beheben kann, bevor sie zu einem Problem werden.