Wenn SQL Server eine Abfrage optimiert, erstellt es während einer Explorationsphase Kandidatenpläne und wählt unter ihnen den Plan mit den niedrigsten Kosten aus. Der gewählte Plan soll die niedrigste Laufzeit unter den untersuchten Plänen haben. Die Sache ist die, dass der Optimierer nur zwischen Strategien wählen kann, die in ihn einkodiert wurden. Zum Beispiel kann der Optimierer bei der Optimierung von Gruppierung und Aggregation zum Zeitpunkt der Erstellung dieses Artikels nur zwischen den Strategien „Stream Aggregate“ und „Hash Aggregate“ wählen. Ich habe die verfügbaren Strategien in früheren Teilen dieser Serie behandelt. In Teil 1 behandelte ich die vorbestellte Stream Aggregate-Strategie, in Teil 2 die Sort + Stream Aggregate-Strategie, in Teil 3 die Hash Aggregate-Strategie und in Teil 4 Überlegungen zur Parallelität.
Was der SQL Server-Optimierer derzeit nicht unterstützt, sind Anpassung und künstliche Intelligenz. Das heißt, wenn Sie eine Strategie finden, die unter bestimmten Bedingungen optimaler ist als die, die der Optimierer unterstützt, können Sie den Optimierer nicht erweitern, um sie zu unterstützen, und der Optimierer kann nicht lernen, sie zu verwenden. Was Sie jedoch tun können, ist, die Abfrage mit alternativen Abfrageelementen neu zu schreiben, die mit der Strategie optimiert werden können, die Sie im Sinn haben. In diesem fünften und letzten Teil der Serie demonstriere ich diese Technik der Abfrageoptimierung mithilfe von Abfragerevisionen.
Vielen Dank an Paul White (@SQL_Kiwi) für seine Hilfe bei einigen der in diesem Artikel vorgestellten Kostenberechnungen!
Wie in den vorherigen Teilen der Serie verwende ich die PerformanceV3-Beispieldatenbank. Verwenden Sie den folgenden Code, um nicht benötigte Indizes aus der Orders-Tabelle zu löschen:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Standardoptimierungsstrategie
Beachten Sie die folgenden grundlegenden Gruppierungs- und Aggregationsaufgaben:
Geben Sie das maximale Bestelldatum für jeden Versender, Mitarbeiter und Kunden zurück.
Für eine optimale Leistung erstellen Sie die folgenden unterstützenden Indizes:
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate); CREATE INDEX idx_eid_od ON dbo.Orders(empid, orderdate); CREATE INDEX idx_cid_od ON dbo.Orders(custid, orderdate);
Im Folgenden finden Sie die drei Abfragen, die Sie verwenden würden, um diese Aufgaben zu erledigen, zusammen mit den geschätzten Unterbaumkosten sowie den Statistiken zu E/A, CPU und verstrichener Zeit:
-- Query 1 -- Estimated Subtree Cost: 3.5344 -- logical reads: 2484, CPU time: 281 ms, elapsed time: 279 ms SELECT shipperid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY shipperid; -- Query 2 -- Estimated Subtree Cost: 3.62798 -- logical reads: 2610, CPU time: 250 ms, elapsed time: 283 ms SELECT empid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY empid; -- Query 3 -- Estimated Subtree Cost: 4.27624 -- logical reads: 3479, CPU time: 406 ms, elapsed time: 506 ms SELECT custid, MAX(orderdate) AS maxod FROM dbo.Orders GROUP BY custid;
Abbildung 1 zeigt die Pläne für diese Abfragen:
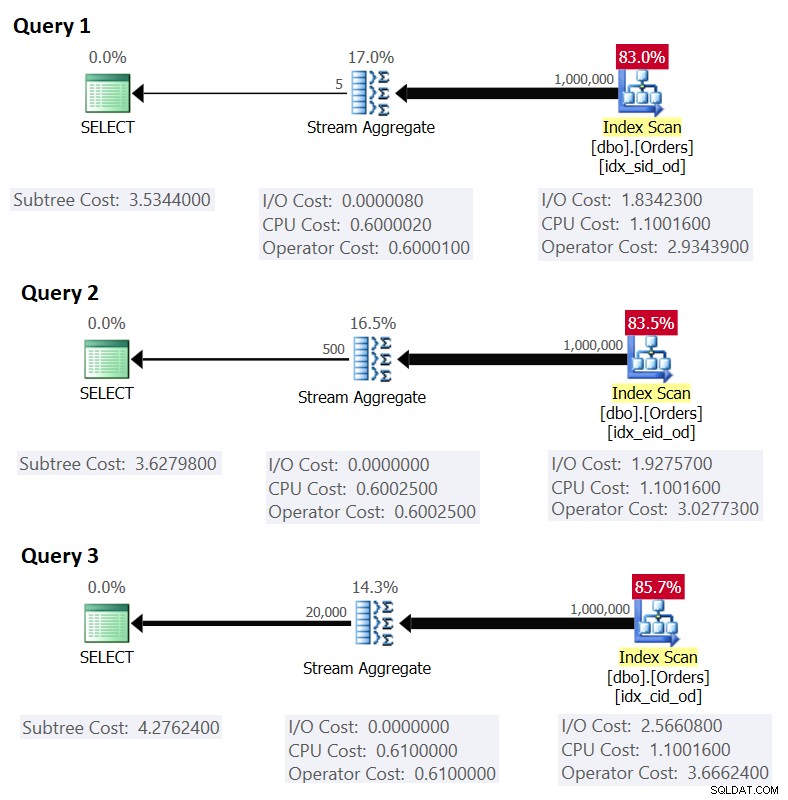 Abbildung 1:Pläne für gruppierte Abfragen
Abbildung 1:Pläne für gruppierte Abfragen
Denken Sie daran, dass, wenn Sie einen abdeckenden Index eingerichtet haben, mit den Gruppierungssatzspalten als führende Schlüsselspalten, gefolgt von der Aggregationsspalte, SQL Server wahrscheinlich einen Plan auswählt, der einen geordneten Scan des abdeckenden Index durchführt, der die Stream Aggregate-Strategie unterstützt . Wie aus den Plänen in Abbildung 1 hervorgeht, ist der Index-Scan-Operator für den größten Teil der Plankosten verantwortlich, und darin ist der E/A-Teil am wichtigsten.
Bevor ich eine alternative Strategie vorstelle und die Umstände erkläre, unter denen sie optimaler als die Standardstrategie ist, lassen Sie uns die Kosten der bestehenden Strategie bewerten. Da der E/A-Teil bei der Bestimmung der Plankosten dieser Standardstrategie am dominantesten ist, lassen Sie uns zunächst abschätzen, wie viele logische Seitenlesevorgänge erforderlich sein werden. Später schätzen wir auch die Plankosten.
Um die Anzahl der logischen Lesevorgänge abzuschätzen, die der Index-Scan-Operator benötigt, müssen Sie wissen, wie viele Zeilen Sie in der Tabelle haben und wie viele Zeilen basierend auf der Zeilengröße auf eine Seite passen. Sobald Sie diese beiden Operanden haben, lautet Ihre Formel für die erforderliche Anzahl von Seiten in der Blattebene des Index dann CEILING(1e0 * @numrows / @rowsperpage). Wenn Sie nur die Tabellenstruktur und keine vorhandenen Beispieldaten haben, mit denen Sie arbeiten können, können Sie diesen Artikel verwenden, um die Anzahl der Seiten zu schätzen, die Sie auf der Blattebene des unterstützenden Index haben würden. Wenn Sie gute repräsentative Beispieldaten haben, auch wenn sie nicht im gleichen Umfang wie in der Produktionsumgebung vorliegen, können Sie die durchschnittliche Anzahl von Zeilen berechnen, die auf eine Seite passen, indem Sie Katalog- und dynamische Verwaltungsobjekte wie folgt abfragen:
SELECT I.name, row_count, in_row_data_page_count,
CAST(ROUND(1e0 * row_count / in_row_data_page_count, 0) AS INT) AS avgrowsperpage
FROM sys.indexes AS I
INNER JOIN sys.dm_db_partition_stats AS P
ON I.object_id = P.object_id
AND I.index_id = P.index_id
WHERE I.object_id = OBJECT_ID('dbo.Orders')
AND I.name IN ('idx_sid_od', 'idx_eid_od', 'idx_cid_od'); Diese Abfrage generiert die folgende Ausgabe in unserer Beispieldatenbank:
name row_count in_row_data_page_count avgrowsperpage ----------- ---------- ---------------------- --------------- idx_sid_od 1000000 2473 404 idx_eid_od 1000000 2599 385 idx_cid_od 1000000 3461 289
Nachdem Sie nun die Anzahl der Zeilen haben, die in eine Blattseite des Index passen, können Sie die Gesamtzahl der Blattseiten im Index basierend auf der erwarteten Anzahl von Zeilen in Ihrer Produktionstabelle schätzen. Dies ist auch die erwartete Anzahl von logischen Lesevorgängen, die vom Index-Scan-Operator angewendet werden. In der Praxis kann die Anzahl der Lesevorgänge mehr umfassen als nur die Anzahl der Seiten auf der Blattebene des Index, z. B. zusätzliche Lesevorgänge, die vom Read-Ahead-Mechanismus erzeugt werden, aber ich werde diese ignorieren, um unsere Diskussion einfach zu halten .
Beispielsweise ist die geschätzte Anzahl logischer Lesevorgänge für Abfrage 1 in Bezug auf die erwartete Anzahl von Zeilen CEILING(1e0 * @numorws / 404). Bei 1.000.000 Zeilen beträgt die erwartete Anzahl logischer Lesevorgänge 2476. Der Unterschied zwischen 2476 und der gemeldeten Zeilenanzahl von 2473 kann auf die Rundung zurückgeführt werden, die ich bei der Berechnung der durchschnittlichen Zeilenanzahl pro Seite vorgenommen habe.
In Bezug auf die Plankosten habe ich in Teil 1 der Serie erklärt, wie man die Kosten des Stream Aggregate-Betreibers zurückentwickeln kann. Auf ähnliche Weise können Sie die Kosten des Index-Scan-Operators zurückentwickeln. Die Plankosten sind dann die Summe der Kosten der Index-Scan- und Stream-Aggregate-Operatoren.
Um die Kosten des Index-Scan-Operators zu berechnen, sollten Sie mit dem Reverse Engineering einiger wichtiger Kostenmodellkonstanten beginnen:
@randomio = 0.003125 -- Random I/O cost @seqio = 0.000740740740741 -- Sequential I/O cost @cpubase = 0.000157 -- CPU base cost @cpurow = 0.0000011 -- CPU cost per row
Nachdem Sie die obigen Kostenmodellkonstanten ermittelt haben, können Sie mit dem Reverse Engineering der Formeln für die E/A-Kosten, die CPU-Kosten und die gesamten Operatorkosten für den Index-Scan-Operator fortfahren:
I/O cost: @randomio + (@numpages - 1e0) * @seqio = 0.003125 + (@numpages - 1e0) * 0.000740740740741 CPU cost: @cpubase + @numrows * @cpurow = 0.000157 + @numrows * 0.0000011 Operator cost: 0.002541259259259 + @numpages * 0.000740740740741 + @numrows * 0.0000011
Beispielsweise betragen die Index-Scan-Operatorkosten für Abfrage 1 mit 2473 Seiten und 1.000.000 Zeilen:
0.002541259259259 + 2473 * 0.000740740740741 + 1000000 * 0.0000011 = 2.93439
Im Folgenden finden Sie die Reverse-Engineering-Formel für die Betreiberkosten von Stream Aggregate:
0.000008 + @numrows * 0.0000006 + @numgroups * 0.0000005
Als Beispiel haben wir für Abfrage 1 1.000.000 Zeilen und 5 Gruppen, daher betragen die geschätzten Kosten 0,6000105.
Kombinieren Sie die Kosten der beiden Betreiber, hier ist die Formel für die gesamten Plankosten:
0.002549259259259 + @numpages * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
Für Abfrage 1 mit 2473 Seiten, 1.000.000 Zeilen und 5 Gruppen erhalten Sie:
0.002549259259259 + 2473 * 0.000740740740741 + 1000000 * 0.0000017 + 5 * 0.0000005 = 3.5344
Dies stimmt mit dem überein, was Abbildung 1 als geschätzte Kosten für Abfrage 1 zeigt.
Wenn Sie sich auf eine geschätzte Anzahl von Zeilen pro Seite verlassen, lautet Ihre Formel:
0.002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
Beispiel:Für Abfrage 1 mit 1.000.000 Zeilen, 404 Zeilen pro Seite und 5 Gruppen betragen die geschätzten Kosten:
0.002549259259259 + CEILING(1e0 * 1000000 / 404) * 0.000740740740741 + 1000000 * 0.0000017 + 5 * 0.0000005 = 3.5366
Als Übung können Sie die Zahlen für Abfrage 2 (1.000.000 Zeilen, 385 Zeilen pro Seite, 500 Gruppen) und Abfrage 3 (1.000.000 Zeilen, 289 Zeilen pro Seite, 20.000 Gruppen) in unsere Formel anwenden und sehen, dass die Ergebnisse mit was übereinstimmen Abbildung 1 zeigt.
Abfrageoptimierung mit Abfrageumschreibungen
Die standardmäßige vorgeordnete Stream Aggregate-Strategie zum Berechnen eines MIN/MAX-Aggregats pro Gruppe beruht auf einem geordneten Scan eines unterstützenden abdeckenden Index (oder einer anderen vorläufigen Aktivität, die die geordneten Zeilen ausgibt). Eine alternative Strategie, bei der ein unterstützender abdeckender Index vorhanden ist, wäre die Durchführung einer Indexsuche pro Gruppe. Hier ist eine Beschreibung eines Pseudoplans, der auf einer solchen Strategie für eine Abfrage basiert, die nach grpcol gruppiert und ein MAX(aggcol) anwendet:
set @curgrpcol = grpcol from first row obtained by a scan of the index, ordered forward;
while end of index not reached
begin
set @curagg = aggcol from row obtained by a seek to the last point
where grpcol = @curgrpcol, ordered backward;
emit row (@curgrpcol, @curagg);
set @curgrpcol = grpcol from row to the right of last row for current group;
end; Wenn Sie darüber nachdenken, ist die Scan-basierte Standardstrategie optimal, wenn der Gruppierungssatz eine geringe Dichte hat (große Anzahl von Gruppen, mit einer kleinen Anzahl von Zeilen pro Gruppe im Durchschnitt). Die suchbasierte Strategie ist optimal, wenn der Gruppierungssatz eine hohe Dichte hat (kleine Anzahl von Gruppen, mit einer großen Anzahl von Zeilen pro Gruppe im Durchschnitt). Abbildung 2 veranschaulicht beide Strategien und zeigt, wann jede optimal ist.
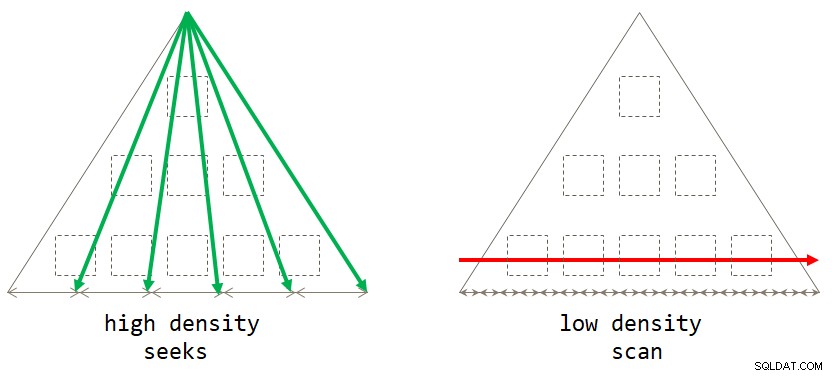 Abbildung 2:Optimale Strategie basierend auf Gruppierungssatzdichte
Abbildung 2:Optimale Strategie basierend auf Gruppierungssatzdichte
Solange Sie die Lösung in Form einer gruppierten Abfrage schreiben, berücksichtigt SQL Server derzeit nur die Scan-Strategie. Dies funktioniert gut für Sie, wenn der Gruppierungssatz eine geringe Dichte hat. Wenn Sie eine hohe Dichte haben, müssen Sie eine Abfrageumschreibung anwenden, um die Suchstrategie zu erhalten. Eine Möglichkeit, dies zu erreichen, besteht darin, die Tabelle abzufragen, die die Gruppen enthält, und eine Skalaraggregat-Unterabfrage für die Haupttabelle zu verwenden, um das Aggregat zu erhalten. Um beispielsweise das maximale Bestelldatum für jeden Versender zu berechnen, würden Sie den folgenden Code verwenden:
SELECT shipperid,
( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC ) AS maxod
FROM dbo.Shippers AS S; Die Indizierungsrichtlinien für die Haupttabelle sind die gleichen wie die zur Unterstützung der Standardstrategie. Wir haben diese Indizes bereits für die drei oben genannten Aufgaben eingerichtet. Sie möchten wahrscheinlich auch einen unterstützenden Index für die Spalten des Gruppierungssatzes in der Tabelle, die die Gruppen enthält, um die E/A-Kosten für diese Tabelle zu minimieren. Verwenden Sie den folgenden Code, um solche unterstützenden Indizes für unsere drei Aufgaben zu erstellen:
CREATE INDEX idx_sid ON dbo.Shippers(shipperid); CREATE INDEX idx_eid ON dbo.Employees(empid); CREATE INDEX idx_cid ON dbo.Customers(custid);
Ein kleines Problem besteht jedoch darin, dass die auf der Unterabfrage basierende Lösung kein exaktes logisches Äquivalent der auf der gruppierten Abfrage basierenden Lösung ist. Wenn Sie eine Gruppe ohne Präsenz in der Haupttabelle haben, gibt Ersteres die Gruppe mit NULL als Aggregat zurück, während Letzteres die Gruppe überhaupt nicht zurückgibt. Eine einfache Möglichkeit, ein echtes logisches Äquivalent zur gruppierten Abfrage zu erreichen, besteht darin, die Unterabfrage mit dem CROSS APPLY-Operator in der FROM-Klausel aufzurufen, anstatt eine skalare Unterabfrage in der SELECT-Klausel zu verwenden. Denken Sie daran, dass CROSS APPLY keine linke Zeile zurückgibt, wenn die angewendete Abfrage eine leere Menge zurückgibt. Hier sind die drei Lösungsabfragen, die diese Strategie für unsere drei Aufgaben implementieren, zusammen mit ihren Leistungsstatistiken:
-- Query 4
-- Estimated Subtree Cost: 0.0072299
-- logical reads: 2 + 15, CPU time: 0 ms, elapsed time: 43 ms
SELECT S.shipperid, A.orderdate AS maxod
FROM dbo.Shippers AS S
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.shipperid = S.shipperid
ORDER BY O.orderdate DESC ) AS A;
-- Query 5
-- Estimated Subtree Cost: 0.089694
-- logical reads: 2 + 1620, CPU time: 0 ms, elapsed time: 148 ms
SELECT E.empid, A.orderdate AS maxod
FROM dbo.Employees AS E
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.empid = E.empid
ORDER BY O.orderdate DESC ) AS A;
-- Query 6
-- Estimated Subtree Cost: 3.5227
-- logical reads: 45 + 63777, CPU time: 171 ms, elapsed time: 306 ms
SELECT C.custid, A.orderdate AS maxod
FROM dbo.Customers AS C
CROSS APPLY ( SELECT TOP (1) O.orderdate
FROM dbo.Orders AS O
WHERE O.custid = C.custid
ORDER BY O.orderdate DESC ) AS A; Die Pläne für diese Abfragen sind in Abbildung 3 dargestellt.
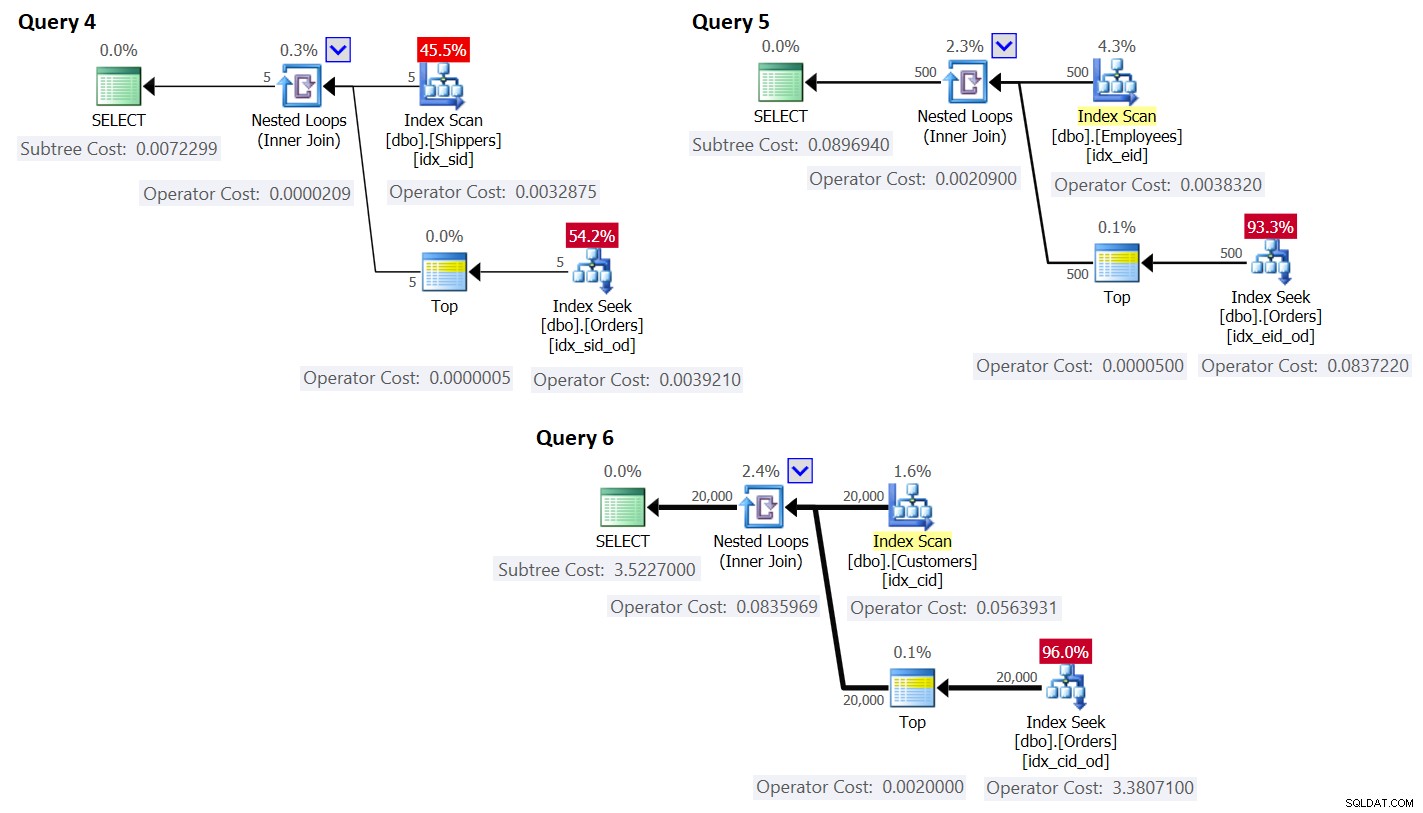 Abbildung 3:Pläne für Abfragen mit Rewrite
Abbildung 3:Pläne für Abfragen mit Rewrite
Wie Sie sehen können, werden die Gruppen erhalten, indem der Index in der Gruppentabelle gescannt wird, und das Aggregat wird durch Anwenden einer Suche im Index in der Haupttabelle erhalten. Je höher die Dichte des Gruppierungssatzes ist, desto optimaler ist dieser Plan im Vergleich zur Standardstrategie für die gruppierte Abfrage.
Lassen Sie uns, genau wie zuvor für die Standard-Scan-Strategie, die Anzahl der logischen Lesevorgänge schätzen und die Kosten für die Suchstrategie planen. Die geschätzte Anzahl logischer Lesevorgänge ist die Anzahl der Lesevorgänge für die einzelne Ausführung des Operators „Index Scan“, der die Gruppen abruft, plus die Lesevorgänge für alle Ausführungen des Operators „Index Seek“.
Die geschätzte Anzahl logischer Lesevorgänge für den Operator Index Scan ist im Vergleich zu den Suchvorgängen vernachlässigbar; dennoch ist es CEILING(1e0 * @numgroups / @rowsperpage). Nehmen Sie Abfrage 4 als Beispiel; Angenommen, der Index idx_sid passt etwa 600 Zeilen pro Blattseite (die tatsächliche Anzahl hängt von den tatsächlichen shipperid-Werten ab, da der Datentyp VARCHAR (5) ist). Bei 5 Gruppen passen alle Zeilen auf eine einzelne Blattseite. Wenn Sie 5.000 Gruppen hätten, würden sie auf 9 Seiten passen.
Die geschätzte Anzahl logischer Lesevorgänge für alle Ausführungen des Indexsuchoperators ist @numgroups * @indexdepth. Die Tiefe des Index kann wie folgt berechnet werden:
CEILING(LOG(CEILING(1e0 * @numrows / @rowsperleafpage), @rowspernonleafpage)) + 1
Nehmen wir zum Beispiel Abfrage 4 an, dass wir ungefähr 404 Zeilen pro Blattseite des Indexes idx_sid_od und ungefähr 352 Zeilen pro Nichtblattseite anpassen können. Auch hier hängen die tatsächlichen Zahlen von den tatsächlichen Werten ab, die in der shipperid-Spalte gespeichert sind, da ihr Datentyp VARCHAR(5)) ist. Denken Sie für Schätzungen daran, dass Sie die hier beschriebenen Berechnungen verwenden können. Wenn gute repräsentative Beispieldaten verfügbar sind, können Sie die folgende Abfrage verwenden, um die Anzahl der Zeilen herauszufinden, die in die Blatt- und Nicht-Blatt-Seiten des gegebenen Index passen:
SELECT
CASE P.index_level WHEN 0 THEN 'leaf' WHEN 1 THEN 'nonleaf' END AS pagetype,
FLOOR(8096 / (P.avg_record_size_in_bytes + 2)) AS rowsperpage
FROM (SELECT *
FROM sys.indexes
WHERE object_id = OBJECT_ID('dbo.Orders')
AND name = 'idx_sid_od') AS I
CROSS APPLY sys.dm_db_index_physical_stats
(DB_ID('PerformanceV3'), I.object_id, I.index_id, NULL, 'DETAILED') AS P
WHERE P.index_level <= 1; Ich habe die folgende Ausgabe:
pagetype rowsperpage -------- ---------------------- leaf 404 nonleaf 352
Mit diesen Zahlen ist die Tiefe des Index in Bezug auf die Anzahl der Zeilen in der Tabelle:
CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1
Bei 1.000.000 Zeilen in der Tabelle ergibt dies eine Indextiefe von 3. Bei etwa 50 Millionen Zeilen erhöht sich die Indextiefe auf 4 Ebenen und bei etwa 17,62 Milliarden Zeilen auf 5 Ebenen.
In Bezug auf die Anzahl der Gruppen und die Anzahl der Zeilen berechnet die folgende Formel auf jeden Fall die geschätzte Anzahl der logischen Lesevorgänge für Abfrage 4, wenn die obige Anzahl von Zeilen pro Seite angenommen wird:
CEILING(1e0 * @numgroups / 600) + @numgroups * (CEILING(LOG(CEILING(1e0 * @numrows / 404), 352)) + 1)
Bei 5 Gruppen und 1.000.000 Zeilen erhalten Sie beispielsweise insgesamt nur 16 Lesevorgänge! Denken Sie daran, dass die scanbasierte Standardstrategie für die gruppierte Abfrage so viele logische Lesevorgänge wie CEILING(1e0 * @numrows / @rowsperpage) umfasst. Wenn Sie Abfrage 1 als Beispiel verwenden und etwa 404 Zeilen pro Blattseite des Indexes idx_sid_od annehmen, erhalten Sie bei derselben Anzahl von Zeilen von 1.000.000 etwa 2.476 Lesevorgänge. Erhöhen Sie die Anzahl der Zeilen in der Tabelle um den Faktor 1.000 auf 1.000.000.000, aber behalten Sie die Anzahl der Gruppen bei. Die Anzahl der erforderlichen Lesevorgänge bei der Suchstrategie ändert sich nur geringfügig auf 21, während die Anzahl der erforderlichen Lesevorgänge bei der Scan-Strategie linear auf 2.475.248 ansteigt.
Das Schöne an der Suchstrategie ist, dass sie, solange die Anzahl der Gruppen klein und fest ist, eine nahezu konstante Skalierung in Bezug auf die Anzahl der Zeilen in der Tabelle aufweist. Das liegt daran, dass die Anzahl der Suchvorgänge durch die Anzahl der Gruppen bestimmt wird und die Tiefe des Index sich logarithmisch auf die Anzahl der Zeilen in der Tabelle bezieht, wobei die Log-Basis die Anzahl der Zeilen ist, die auf eine Nichtblattseite passen. Umgekehrt hat die Scan-basierte Strategie eine lineare Skalierung in Bezug auf die Anzahl der beteiligten Zeilen.
Abbildung 4 zeigt die geschätzte Anzahl von Lesevorgängen für die beiden Strategien, die von Abfrage 1 und Abfrage 4 angewendet werden, bei einer festen Anzahl von Gruppen von 5 und einer unterschiedlichen Anzahl von Zeilen in der Haupttabelle.
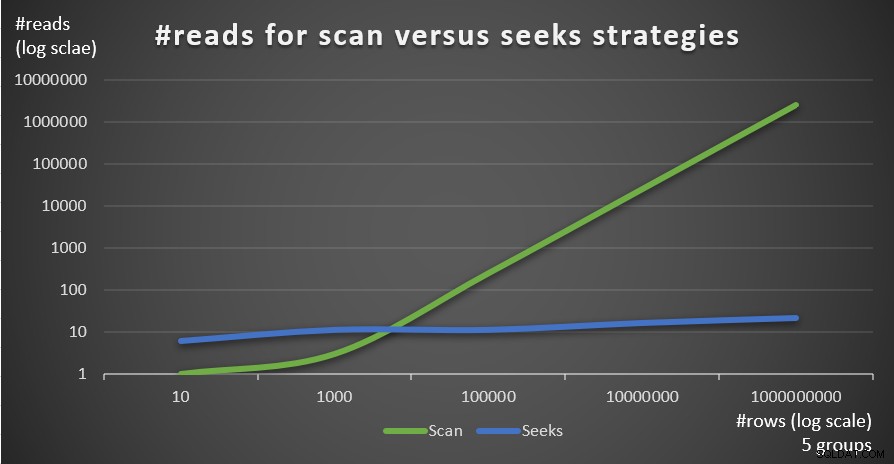 Abbildung 4:#reads für Scan versus Suchstrategien (5 Gruppen)
Abbildung 4:#reads für Scan versus Suchstrategien (5 Gruppen)
Abbildung 5 zeigt die Anzahl der geschätzten Lesevorgänge für die beiden Strategien bei einer festen Anzahl von Zeilen von 1.000.000 in der Haupttabelle und einer unterschiedlichen Anzahl von Gruppen.
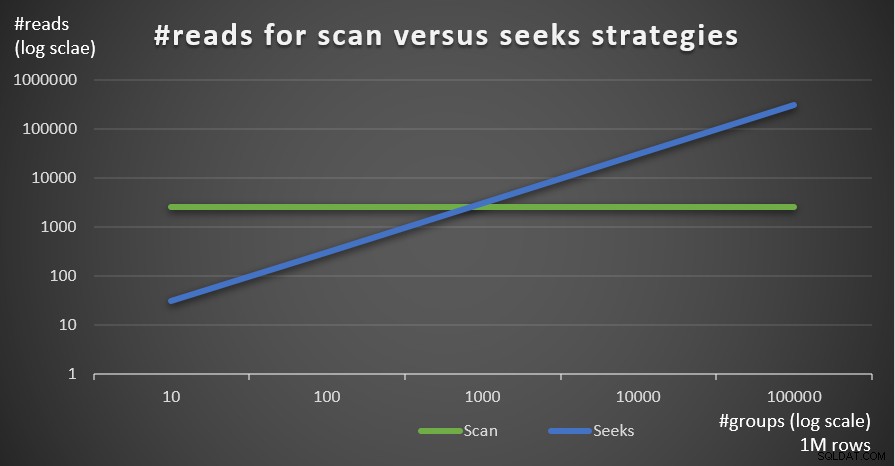 Abbildung 5:#reads für Scan-versus-Suchstrategien (1 Mio. Zeilen)
Abbildung 5:#reads für Scan-versus-Suchstrategien (1 Mio. Zeilen)
Man sieht sehr deutlich, dass je höher die Dichte des Gruppierungssatzes (geringere Anzahl an Gruppen) und je größer die Haupttabelle ist, desto mehr wird die Seeks-Strategie in Bezug auf die Anzahl der Reads bevorzugt. Wenn Sie sich über das I/O-Muster wundern, das von jeder Strategie verwendet wird; Natürlich führen Indexsuchoperationen zufällige E/A durch, während eine Indexsuchoperation sequentielle E/A ausführt. Dennoch ist es ziemlich klar, welche Strategie in den extremeren Fällen optimaler ist.
Was die Kosten des Abfrageplans anbelangt, lassen Sie uns erneut den Plan für Abfrage 4 in Abbildung 3 als Beispiel auf die einzelnen Operatoren im Plan herunterbrechen.
Die Reverse-Engineering-Formel für die Kosten des Index-Scan-Operators lautet:
0.002541259259259 + @numpages * 0.000740740740741 + @numgroups * 0.0000011
In unserem Fall mit 5 Gruppen, die alle auf eine Seite passen, betragen die Kosten:
0.002541259259259 + 1 * 0.000740740740741 + 5 * 0.0000011 = 0.0032875
Die im Plan angezeigten Kosten sind die gleichen.
Wie zuvor könnten Sie die Anzahl der Seiten auf der Blattebene des Index basierend auf der geschätzten Anzahl von Zeilen pro Seite mit der Formel CEILING(1e0 * @numrows / @rowsperpage) schätzen, was in unserem Fall CEILING(1e0 * @ numgroups / @groupsperpage). Angenommen, der Index idx_sid passt etwa 600 Zeilen pro Blattseite, mit 5 Gruppen müssten Sie eine Seite lesen. Die Kalkulationsformel für den Index-Scan-Operator lautet dann jedenfalls:
0.002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage) * 0.000740740740741 + @numgroups * 0.0000011
Die Reverse-Engineering-Kostenformel für den Nested-Loops-Operator lautet:
@executions * 0.00000418
In unserem Fall bedeutet dies:
@numgroups * 0.00000418
Für Abfrage 4 mit 5 Gruppen erhalten Sie:
5 * 0.00000418 = 0.0000209
Die im Plan angezeigten Kosten sind die gleichen.
Die Reverse-Engineering-Kostenformel für den Top-Operator lautet:
@executions * @toprows * 0.00000001
In unserem Fall bedeutet dies:
@numgroups * 1 * 0.00000001
Mit 5 Gruppen erhalten Sie:
5 * 0.0000001 = 0.0000005
Die im Plan angezeigten Kosten sind die gleichen.
Was den Index Seek-Operator betrifft, so habe ich hier große Hilfe von Paul White erhalten; danke mein Freund! Die Berechnung unterscheidet sich für die erste Ausführung und für die Rebinds (Nicht-Erstausführungen, die das Ergebnis der vorherigen Ausführung nicht wiederverwenden). Beginnen wir wie beim Index-Scan-Operator damit, die Konstanten des Kostenmodells zu identifizieren:
@randomio = 0.003125 -- Random I/O cost @seqio = 0.000740740740741 -- Sequential I/O cost @cpubase = 0.000157 -- CPU base cost @cpurow = 0.0000011 -- CPU cost per row
Für eine Ausführung ohne angewendetes Zeilenziel betragen die E/A- und CPU-Kosten:
I/O cost: @randomio + (@numpages - 1e0) * @seqio = 0.002384259259259 + @numpages * 0.000740740740741 CPU cost: @cpubase + @numrows * @cpurow = 0.000157 + @numrows * 0.0000011
Da wir TOP (1) verwenden, haben wir nur eine Seite und eine Zeile involviert, also betragen die Kosten:
I/O cost: 0.002384259259259 + 1 * 0.000740740740741 = 0.003125 CPU cost: 0.000157 + 1 * 0.0000011 = 0.0001581
Die Kosten für die erste Ausführung des Index Seek-Operators betragen in unserem Fall also:
@firstexecution = 0.003125 + 0.0001581 = 0.0032831
Die Kosten für die Rebinds setzen sich wie üblich aus CPU- und I/O-Kosten zusammen. Nennen wir sie @rebindcpu bzw. @rebindio. Bei Abfrage 4 mit 5 Gruppen haben wir 4 Rebinds (nennen Sie es @rebinds). Die @rebindcpu-Kosten sind der einfache Teil. Die Formel lautet:
@rebindcpu = @rebinds * (@cpubase + @cpurow)
In unserem Fall bedeutet dies:
@rebindcpu = 4 * (0.000157 + 0.0000011) = 0.0006324
Der @rebindio-Teil ist etwas komplexer. Hier berechnet die Kalkulationsformel statistisch die erwartete Anzahl unterschiedlicher Seiten, die die erneuten Bindungen voraussichtlich lesen werden, indem Stichproben mit Ersetzung verwendet werden. Wir nennen dieses Element @pswr (für unterschiedliche Seiten, die mit Ersetzung abgetastet werden). Die Idee ist, dass wir @indexdatapages Anzahl von Seiten im Index (in unserem Fall 2.473) und @rebinds Anzahl von Rebinds (in unserem Fall 4) haben. Angenommen, wir haben die gleiche Wahrscheinlichkeit, eine bestimmte Seite bei jeder erneuten Bindung zu lesen, wie viele verschiedene Seiten werden wir voraussichtlich insgesamt lesen? Das ist vergleichbar damit, eine Tasche mit 2.473 Bällen zu haben und viermal blind einen Ball aus der Tasche zu ziehen und ihn dann wieder in die Tasche zu legen. Wie viele unterschiedliche Bälle werden Sie statistisch gesehen insgesamt ziehen? Die Formel dafür mit unseren Operanden lautet:
@pswr = @indexdatapages * (1e0 - POWER((@indexdatapages - 1e0) / @indexdatapages, @rebinds))
Mit unseren Nummern erhalten Sie:
@pswr = 2473 * (1e0 - POWER((2473 - 1e0) / 2473, 4)) = 3.99757445099277
Als Nächstes berechnen Sie die Anzahl der Zeilen und Seiten, die Sie im Durchschnitt pro Gruppe haben:
@grouprows = @cardinality * @density @grouppages = CEILING(@indexdatapages * @density)
In unserer Abfrage 4 beträgt die Kardinalität 1.000.000 und die Dichte 1/5 =0,2. Sie erhalten also:
@grouprows = 1000000 * 0.2 = 200000 @numpages = CEILING(2473 * 0.2) = 495
Dann berechnen Sie die E/A-Kosten ohne Filterung (nennen Sie es @io) als:
@io = @randomio + (@seqio * (@grouppages - 1e0))
In unserem Fall erhalten Sie:
@io = 0.003125 + (0.000740740740741 * (495 - 1e0)) = 0.369050925926054
Und schließlich, da die Suche bei jeder Neubindung nur eine Zeile extrahiert, berechnen Sie @rebindio mit der folgenden Formel:
@rebindio = (1e0 / @grouprows) * ((@pswr - 1e0) * @io)
In unserem Fall erhalten Sie:
@rebindio = (1e0 / 200000) * ((3.99757445099277 - 1e0) * 0.369050925926054) = 0.000005531288
Schließlich betragen die Kosten des Betreibers:
Operator cost: @firstexecution + @rebindcpu + @rebindio = 0.0032831 + 0.0006324 + 0.000005531288 = 0.003921031288
Dies entspricht den im Plan für Abfrage 4 angezeigten Operatorkosten für die Indexsuche.
Sie können jetzt die Kosten aller Operatoren aggregieren, um die vollständigen Abfrageplankosten zu erhalten. Sie erhalten:
Query plan cost: 0.002541259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00000418
+ @numgroups * 0.00000001
+ 0.0032831 + (@numgroups - 1e0) * 0.0001581
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0))) Nach der Vereinfachung erhalten Sie die folgende vollständige Kalkulationsformel für unsere Seeks-Strategie:
0.005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00016229
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0))) Hier ist als Beispiel unter Verwendung von T-SQL die Berechnung der Abfrageplankosten mit unserer Seeks-Strategie für Abfrage 4:
DECLARE
@numrows AS FLOAT = 1000000,
@numgroups AS FLOAT = 5,
@rowsperpage AS FLOAT = 404,
@groupsperpage AS FLOAT = 600;
SELECT
0.005666259259259 + CEILING(1e0 * @numgroups / @groupsperpage)
* 0.000740740740741 + @numgroups * 0.0000011
+ @numgroups * 0.00016229
+ (1e0 / (@numrows / @numgroups)) * (CEILING(1e0 * @numrows / @rowsperpage)
* (1e0 - POWER((CEILING(1e0 * @numrows / @rowsperpage) - 1e0)
/ CEILING(1e0 * @numrows / @rowsperpage), @numgroups - 1e0)) - 1e0)
* (0.003125 + (0.000740740740741 * (CEILING((@numrows / @rowsperpage)
* (1e0 / @numgroups)) - 1e0)))
AS seeksplancost; Diese Berechnung berechnet die Kosten 0,0072295 für Abfrage 4. Die in Abbildung 3 gezeigten geschätzten Kosten betragen 0,0072299. Das ist ziemlich nah! Berechnen Sie als Übung die Kosten für Abfrage 5 und Abfrage 6 mit dieser Formel und vergewissern Sie sich, dass Sie Zahlen erhalten, die denen in Abbildung 3 nahe kommen.
Erinnern Sie sich, dass die Kostenformel für die scanbasierte Standardstrategie (nennen Sie sie Scan lautet Strategie):
0.002549259259259 + CEILING(1e0 * @numrows / @rowsperpage) * 0.000740740740741 + @numrows * 0.0000017 + @numgroups * 0.0000005
Anhand von Abfrage 1 als Beispiel und unter der Annahme von 1.000.000 Zeilen in der Tabelle, 404 Zeilen pro Seite und 5 Gruppen betragen die geschätzten Abfrageplankosten der Scanstrategie 3,5366.
Abbildung 6 zeigt die geschätzten Kosten des Abfrageplans für die beiden Strategien, die von Abfrage 1 (Scannen) und Abfrage 4 (Suchen) angewendet werden, bei einer festen Anzahl von Gruppen von 5 und einer unterschiedlichen Anzahl von Zeilen in der Haupttabelle.
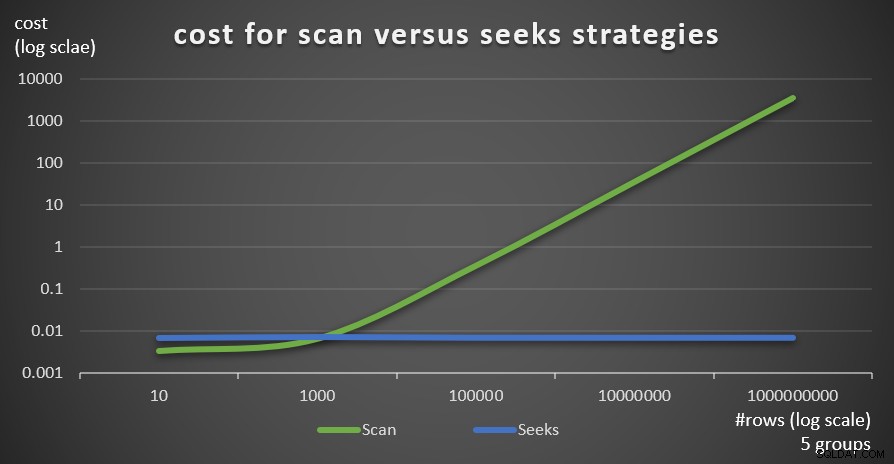 Abbildung 6:Kosten für Scan versus Suchstrategien (5 Gruppen)
Abbildung 6:Kosten für Scan versus Suchstrategien (5 Gruppen)
Abbildung 7 zeigt die geschätzten Abfrageplankosten für die beiden Strategien bei einer festen Anzahl von Zeilen in der Haupttabelle von 1.000.000 und einer unterschiedlichen Anzahl von Gruppen.
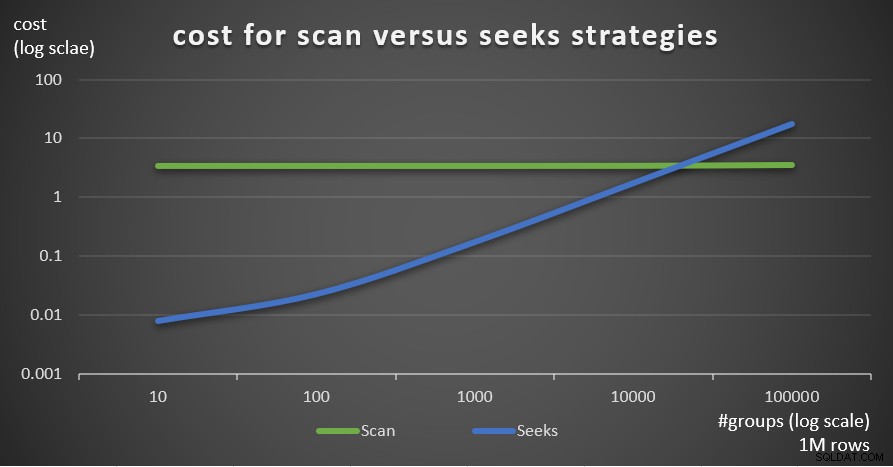 Abbildung 7:Kosten für Scan- versus Suchstrategien (1 Mio. Zeilen)
Abbildung 7:Kosten für Scan- versus Suchstrategien (1 Mio. Zeilen)
Wie aus diesen Ergebnissen hervorgeht, ist die Suchstrategie im Vergleich zur Scanstrategie umso optimaler, je höher die Gruppierungssatzdichte und je mehr Zeilen in der Haupttabelle vorhanden sind. Stellen Sie daher in Szenarien mit hoher Dichte sicher, dass Sie die APPLY-basierte Lösung ausprobieren. In der Zwischenzeit können wir hoffen, dass Microsoft diese Strategie als integrierte Option für gruppierte Abfragen hinzufügt.
Schlussfolgerung
Dieser Artikel schließt eine fünfteilige Reihe zu Abfrageoptimierungsschwellenwerten für Abfragen ab, die Daten gruppieren und aggregieren. Ein Ziel der Serie war es, die Besonderheiten der verschiedenen Algorithmen zu erörtern, die der Optimierer verwenden kann, die Bedingungen, unter denen jeder Algorithmus bevorzugt wird, und wann Sie mit Ihren eigenen Abfrageumschreibungen eingreifen sollten. Ein weiteres Ziel war es, den Prozess des Entdeckens und Vergleichens der verschiedenen Optionen zu erläutern. Offensichtlich kann derselbe Analyseprozess auf das Filtern, Verbinden, Windowing und viele andere Aspekte der Abfrageoptimierung angewendet werden. Hoffentlich fühlen Sie sich jetzt besser gerüstet, um mit der Abfrageoptimierung umzugehen als zuvor.