Als Berater, der mit SQL Server arbeitet, werde ich oft gebeten, mir einen Server anzusehen, der Leistungsprobleme zu haben scheint. Während der Triage auf dem Server stelle ich bestimmte Fragen, wie z. B.:Wie hoch ist Ihre normale CPU-Auslastung, wie hoch sind Ihre durchschnittlichen Festplattenlatenzen, wie hoch ist Ihre normale Arbeitsspeicherauslastung und so weiter? Die Antwort lautet normalerweise:„Wir wissen es nicht“ oder „Wir erfassen diese Informationen nicht regelmäßig“. Wenn Sie keine aktuelle Baseline haben, ist es sehr schwierig zu wissen, wie abnormales Verhalten aussieht. Wenn Sie nicht wissen, was normales Verhalten ist, wie wissen Sie dann sicher, ob die Dinge besser oder schlechter sind? Ich verwende oft die Ausdrücke „Wenn Sie es nicht überwachen, können Sie es nicht messen“ und „Wenn Sie es nicht messen, können Sie es nicht verwalten“.
Aus Sicht der Überwachung sollten Unternehmen zumindest auf fehlgeschlagene Jobs wie Sicherungen, Indexwartung, DBCC CHECKDB und alle anderen wichtigen Jobs überwachen. Es ist einfach, für diese Fehlerbenachrichtigungen einzurichten; Sie benötigen jedoch auch einen Prozess, um sicherzustellen, dass die Jobs wie erwartet ausgeführt werden. Ich habe Jobs gesehen, die aufgehängt und nie abgeschlossen wurden. Eine Fehlerbenachrichtigung würde keinen Alarm auslösen, da der Job niemals erfolgreich ist oder fehlschlägt.
Ausgehend von einer Leistungsbaseline gibt es mehrere Schlüsselmetriken, die erfasst werden sollten. Ich habe einen Prozess erstellt, den ich mit Kunden verwende, der regelmäßig wichtige Kennzahlen erfasst und diese Werte in einer Benutzerdatenbank speichert. Mein Prozess ist einfach:eine dedizierte Datenbank mit gespeicherten Prozeduren, die allgemeine Skripte verwenden, die die Ergebnismengen in Tabellen einfügen. Ich habe SQL Agent-Jobs, um die gespeicherten Prozeduren in regelmäßigen Abständen auszuführen, und ein Bereinigungsskript, um Daten zu löschen, die älter als X Tage sind. Zu den Metriken, die ich immer erfasse, gehören:
Lebenserwartung der Seite :PLE ist wahrscheinlich eine der besten Möglichkeiten, um festzustellen, ob Ihr System unter internem Speicherdruck steht. Die meisten Systeme haben PLE-Werte, die während normaler Arbeitsbelastung schwanken. Ich mag es, diese Werte zu trenden, um zu wissen, was die minimalen, durchschnittlichen und maximalen Werte sind. Ich versuche gerne zu verstehen, was dazu geführt hat, dass PLE zu bestimmten Tageszeiten abgefallen ist, um zu sehen, ob diese Prozesse optimiert werden können. Oft führt jemand einen Tabellenscan durch und leert den Pufferpool. Es kann hilfreich sein, diese Abfragen richtig zu indizieren. Stellen Sie einfach sicher, dass Sie den richtigen PLE-Zähler überwachen – siehe hier .
CPU-Auslastung :Wenn Sie eine Baseline für die CPU-Auslastung haben, wissen Sie, ob Ihr System plötzlich unter CPU-Last steht. Wenn sich ein Benutzer über Leistungsprobleme beschwert, stellt er häufig fest, dass die CPU hoch aussieht. Wenn zum Beispiel die CPU um 80 % schwankt, könnten sie das als besorgniserregend empfinden, aber wenn die CPU zur gleichen Zeit in den vorangegangenen Wochen, als keine Probleme gemeldet wurden, ebenfalls 80 % betrug, ist die Wahrscheinlichkeit, dass die CPU das Problem ist, sehr gering. Trending CPU dient nicht nur dazu, CPU-Spitzen zu erfassen und auf einem konstant hohen Wert zu bleiben. Ich habe viele Geschichten darüber, wie ich in eine „Severe One Conference Bridge“ gebracht wurde, weil es ein Problem mit einer Bewerbung gab. Als DBA trug ich den Hut des „Default Blame Acceptor“. Als das Anwendungsteam sagte, dass es ein Problem mit der Datenbank gab, musste ich beweisen, dass dies nicht der Fall war, der Datenbankserver war schuldig, bis seine Unschuld bewiesen war. Ich erinnere mich lebhaft an einen Vorfall, bei dem das Anwendungsteam zuversichtlich war, dass der Datenbankserver Probleme hatte, weil Benutzer keine Verbindung herstellen konnten. Sie hatten im Internet gelesen, dass SQL Server unter Thread-Pool-Hunger leiden könnte, wenn er Verbindungen ablehnte. Ich sprang auf den Server und begann, mir die Ressourcen anzusehen und welche Prozesse gerade ausgeführt wurden. Innerhalb weniger Minuten meldete ich zurück, dass der betreffende Server sehr gelangweilt war. Basierend auf unseren Basismetriken war die CPU normalerweise zu 60 % und zu etwa 20 % im Leerlauf, die Lebenserwartung der Seiten war merklich höher als normal, und es gab keine Sperren oder Blockierungen, die E/A sah gut aus, es gab keine Fehler in Protokollen und die Sitzungszahlen betrugen etwa 1/3 ihrer normalen Zahl. Ich machte dann den Kommentar:„Es scheint, dass die Benutzer nicht einmal den Datenbankserver erreichen.“ Das erregte die Aufmerksamkeit der Netzwerkleute und sie stellten fest, dass eine Änderung, die sie am Load Balancer vorgenommen hatten, nicht richtig funktionierte, und sie stellten fest, dass über 50 % der Verbindungen falsch geroutet wurden und es nicht zum Datenbankserver schafften. Hätte ich die Grundlinie nicht gewusst, hätten wir viel länger gebraucht, um die Lösung zu erreichen.
Datenträger-E/A :Das Erfassen von Datenträgermetriken ist sehr wichtig. Die DMV sys.dm_io_virtual_file_stats ist seit dem letzten Serverneustart kumulativ. Die Erfassung Ihrer E/A-Latenzen über ein Zeitintervall gibt Ihnen eine Basislinie dessen, was während dieser Zeit normal ist. Wenn Sie sich auf den kumulativen Wert verlassen, können Sie verzerrte Daten von Aktivitäten nach Geschäftsschluss oder langen Perioden, in denen das System im Leerlauf war, erhalten. Paul hat das hier besprochen .
Datenbankdateigrößen :Eine Bestandsaufnahme Ihrer Datenbanken, die Dateigröße, verwendete Größe, freien Speicherplatz und mehr enthält, kann Ihnen helfen, das Datenbankwachstum vorherzusagen. Oft werde ich gebeten, vorherzusagen, wie viel Speicherplatz für einen Datenbankserver im kommenden Jahr benötigt wird. Ohne den wöchentlichen oder monatlichen Wachstumstrend zu kennen, habe ich keine Möglichkeit, intelligent auf eine Zahl zu kommen. Sobald ich anfange, diese Werte zu verfolgen, kann ich dies richtig trenden. Zusätzlich zu den Trends konnte ich auch feststellen, wann es ein unerwartetes Datenbankwachstum gab. Wenn ich unerwartetes Wachstum sehe und nachforsche, stelle ich normalerweise fest, dass jemand entweder eine Tabelle dupliziert hat, um einige Tests durchzuführen (ja, in der Produktion!) oder einen anderen einmaligen Prozess durchgeführt hat. Das Verfolgen dieser Art von Daten und die Möglichkeit, auf Anomalien zu reagieren, zeigt, dass Sie proaktiv sind und Ihre Systeme im Auge behalten.
Wartestatistik :Die Überwachung von Wartestatistiken kann Ihnen dabei helfen, die Ursache bestimmter Leistungsprobleme herauszufinden. Viele neue DBAs machen sich Sorgen, wenn sie zum ersten Mal mit der Recherche von Wartestatistiken beginnen und nicht erkennen, dass es immer zu Wartezeiten kommt, und genau so funktioniert das Planungssystem von SQL Server. Es gibt auch viele Wartezeiten, die als gutartig oder größtenteils harmlos angesehen werden können. Paul Randal schließt diese meist harmlosen Wartezeiten in seinem beliebten Wartestatistik-Skript aus. Paul hat auch eine riesige Bibliothek der verschiedenen Wartetypen aufgebaut und Latch-Klassen mit Beschreibungen und anderen Informationen zur Fehlerbehebung bei Waits und Latches.
Ich habe meinen Datenerfassungsprozess dokumentiert und Sie finden den Code in meinem Blog . Je nach Situation und Art der Probleme, die ein Kunde möglicherweise hat, möchte ich möglicherweise auch zusätzliche Metriken erfassen. Glenn Berry über einen von ihm zusammengestellten Prozess gebloggt, der die durchschnittliche Anzahl von Aufgaben, die durchschnittliche Anzahl von ausführbaren Aufgaben, die durchschnittliche Anzahl von ausstehenden E/A, die CPU-Auslastung von SQL Server-Prozessen und die durchschnittliche Lebenserwartung von Seiten über alle NUMA-Knoten hinweg erfasst. Eine schnelle Internetsuche wird mehrere andere Datenerfassungsprozesse aufdecken, die von Leuten geteilt wurden, sogar vom SQL Server Tiger Team hat einen Prozess, der T-SQL und PowerShell verwendet.
Die Verwendung einer benutzerdefinierten Datenbank und das Erstellen Ihres eigenen Datenerfassungspakets ist eine gültige Lösung zum Erfassen einer Baseline, aber die meisten von uns sind nicht damit beschäftigt, umfassende SQL Server-Überwachungslösungen zu erstellen. Es gibt noch viel mehr, das zu erfassen hilfreich wäre, z. B. lang laufende Abfragen, Top-Abfragen und gespeicherte Prozeduren basierend auf Speicher, E/A und CPU, Deadlocks, Indexfragmentierung, Transaktionen pro Sekunde und vieles mehr. Aus diesem Grund empfehle ich Kunden immer, ein Überwachungstool eines Drittanbieters zu erwerben. Diese Anbieter sind darauf spezialisiert, über die neuesten Trends und Funktionen von SQL Server auf dem Laufenden zu bleiben, damit Sie sich darauf konzentrieren können, sicherzustellen, dass SQL Server so stabil und schnell wie möglich ist.
Lösungen wie SQL Sentry (für SQL Server) und DB Sentry (für Azure SQL-Datenbank) erfassen alle diese Metriken für Sie und ermöglichen Ihnen das einfache Erstellen verschiedener Baselines. Sie können eine normale Basislinie, ein Monatsende, ein Quartalsende und mehr haben. Sie können dann die Grundlinie anwenden und visuell sehen, wie die Dinge anders sind. Noch wichtiger ist, dass Sie eine beliebige Anzahl von Warnungen für verschiedene Bedingungen konfigurieren und benachrichtigt werden können, wenn Metriken Ihre Schwellenwerte überschreiten.
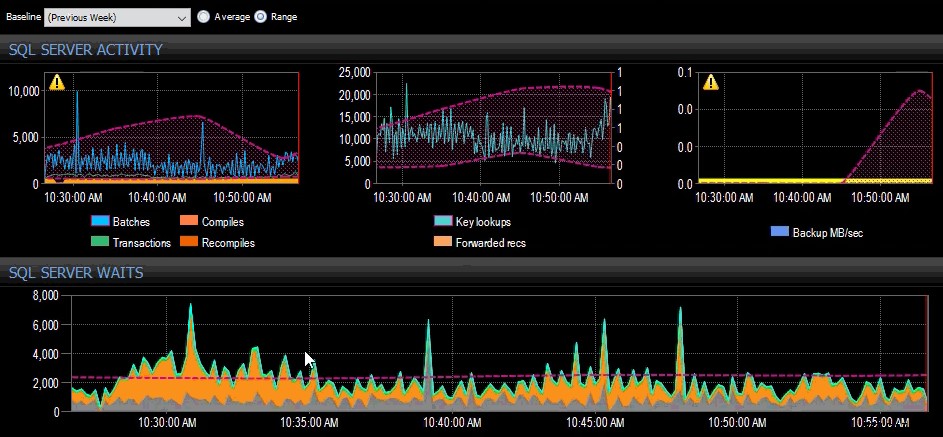 Die Baseline der letzten Woche wurde auf mehrere SQL Server-Metriken im SQL Sentry-Dashboard angewendet.
Die Baseline der letzten Woche wurde auf mehrere SQL Server-Metriken im SQL Sentry-Dashboard angewendet.
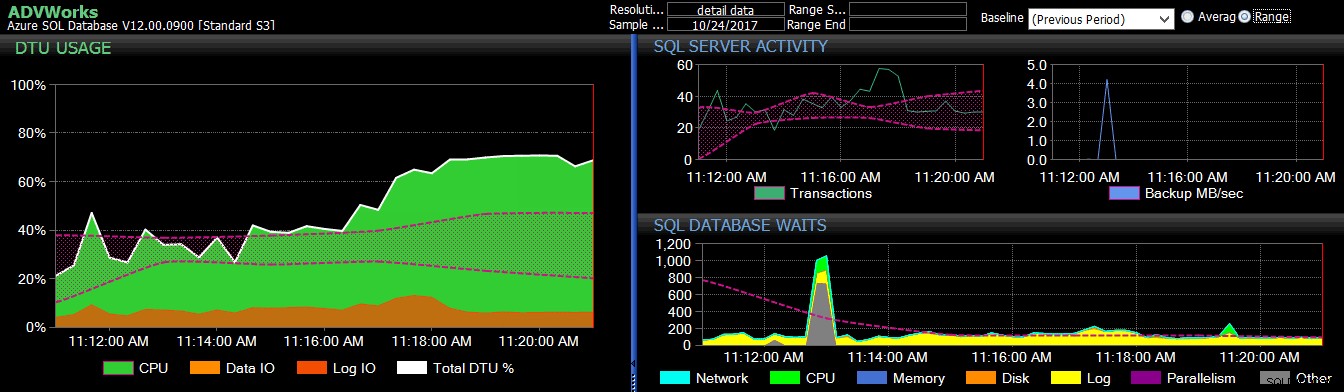 Die Baseline des vorherigen Zeitraums galt für mehrere Azure SQL-Datenbank-Metriken im DB Sentry-Dashboard.
Die Baseline des vorherigen Zeitraums galt für mehrere Azure SQL-Datenbank-Metriken im DB Sentry-Dashboard.
Weitere Informationen zu Baselines in SentryOne finden Sie in diesen Beiträgen auf ihrem Team-Blog oder in diesem 2-Minuten-Video vom Dienstag . Möchten Sie eine Testversion herunterladen? Dort sind sie auch für Sie da .