Dieser Artikel ist der zweite in einer Reihe über Optimierungsschwellenwerte im Zusammenhang mit der Gruppierung und Aggregation von Daten. In Teil 1 habe ich die nachentwickelte Formel für die Betreiberkosten von Stream Aggregate bereitgestellt. Ich habe erklärt, dass dieser Operator die Zeilen verbrauchen muss, die nach dem Gruppierungssatz geordnet sind (beliebige Reihenfolge seiner Mitglieder), und dass Sie, wenn die Daten vorgeordnet aus einem Index abgerufen werden, eine lineare Skalierung in Bezug auf die Anzahl der Zeilen und die Anzahl der Zeilen erhalten Gruppen. Außerdem ist in einem solchen Fall keine Speicherzuweisung erforderlich.
In diesem Artikel konzentriere ich mich auf die Kostenberechnung und Skalierung eines Stream-Aggregat-basierten Vorgangs, wenn die Daten nicht vorgeordnet aus einem Index bezogen werden, sondern erst sortiert werden müssen.
In meinen Beispielen verwende ich die PerformanceV3-Beispieldatenbank wie in Teil 1. Sie können das Skript zum Erstellen und Füllen dieser Datenbank hier herunterladen. Bevor Sie die Beispiele aus diesem Artikel ausführen, stellen Sie sicher, dass Sie zuerst den folgenden Code ausführen, um einige nicht benötigte Indizes zu löschen:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders;DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Die einzigen beiden Indizes, die in dieser Tabelle verbleiben sollten, sind idx_cl_od (geclustert mit orderdate als Schlüssel) und PK_Orders (nicht gruppiert mit orderid als Schlüssel).
Sortieren + Stream-Aggregat
Der Schwerpunkt dieses Artikels liegt darauf herauszufinden, wie ein Streamaggregationsvorgang skaliert wird, wenn die Daten nicht durch den Gruppierungssatz vorgeordnet werden. Da der Stream Aggregate-Operator die geordneten Zeilen verarbeiten muss, muss der Plan einen expliziten Sort-Operator enthalten, wenn sie nicht in einem Index vorgeordnet sind. Die Kosten der Aggregatoperation, die Sie berücksichtigen sollten, sind also die Summe der Kosten der Sort + Stream Aggregate-Operatoren.
Ich verwende die folgende Abfrage (wir nennen sie Abfrage 1), um einen Plan zu demonstrieren, der eine solche Optimierung beinhaltet:
SELECT shipperid, MAX(orderdate) AS maxod FROM (SELECT TOP (100) * FROM dbo.Orders) AS D GROUP BY shipperid;
Der Plan für diese Abfrage ist in Abbildung 1 dargestellt.

Abbildung 1:Plan für Abfrage 1
Der Grund, warum ich einen Tabellenausdruck mit einem TOP-Filter verwende, besteht darin, die genaue Anzahl der (geschätzten) Zeilen zu steuern, die an der Gruppierung und Aggregation beteiligt sind. Das Anwenden von kontrollierten Änderungen macht es einfacher, die Kalkulationsformeln zu versuchen und zurückzuentwickeln.
Wenn Sie sich fragen, warum in diesem Beispiel eine so kleine Anzahl von Zeilen gefiltert wird, hat dies mit den Optimierungsschwellenwerten zu tun, die diese Strategie dem Hash-Aggregate-Algorithmus vorziehen. In Teil 3 beschreibe ich die Kosten und Skalierung der Hash-Alternative. In Fällen, in denen der Optimierer nicht selbst eine Stream-Aggregat-Operation auswählt, z. B. wenn eine große Anzahl von Zeilen beteiligt ist, können Sie dies während des Rechercheprozesses immer mit dem Hinweis OPTION(ORDER GROUP) erzwingen. Wenn Sie sich auf die Kostenkalkulation von Serienplänen konzentrieren, können Sie natürlich einen MAXDOP 1-Hinweis hinzufügen, um Parallelität zu eliminieren.
Wie bereits erwähnt, müssen Sie zur Bewertung der Kosten und Skalierung eines nicht vorbestellten Stream-Aggregatalgorithmus die Summe der Sort + Stream Aggregate-Operatoren berücksichtigen. Die Kalkulationsformel für den Stream Aggregate-Operator kennen Sie bereits aus Teil 1:
@AnzahlZeilen * 0,0000006 + @AnzahlGruppen * 0,0000005In unserer Abfrage haben wir 100 geschätzte Eingabezeilen und 5 geschätzte Ausgabegruppen (5 unterschiedliche Versender-IDs, geschätzt basierend auf Dichteinformationen). Die Kosten für den Stream Aggregate-Operator in unserem Plan betragen also:
100 * 0,0000006 + 5 * 0,0000005 =0,0000625Lassen Sie uns versuchen, die Kostenformel für den Sort-Operator herauszufinden. Denken Sie daran, dass unser Fokus auf den geschätzten Kosten und der Skalierung liegt, da unser ultimatives Ziel darin besteht, Optimierungsschwellenwerte herauszufinden, bei denen der Optimierer seine Entscheidungen von einer Strategie zur anderen ändert.
Die E/A-Kostenschätzung scheint fest zu sein:0,0112613. Ich erhalte die gleichen E/A-Kosten, unabhängig von Faktoren wie Anzahl der Zeilen, Anzahl der Sortierspalten, Datentyp usw. Dies ist wahrscheinlich auf einige erwartete E/A-Arbeiten zurückzuführen.
Was die CPU-Kosten angeht, macht Microsoft die genauen Algorithmen, die sie zum Sortieren verwenden, leider nicht öffentlich. Zu den gängigen Algorithmen, die zum Sortieren durch Datenbank-Engines im Allgemeinen verwendet werden, gehören jedoch verschiedene Implementierungen von Mergesort und Quicksort. Dank der Bemühungen von Paul White, der sich gerne mit Windows-Debugger-Stack-Traces befasst (dafür haben wir nicht alle den Mumm), haben wir etwas mehr Einblick in das Thema, veröffentlicht in seiner Serie „Internals of the Seven SQL Server Sortiert.“ Nach den Erkenntnissen von Paul verwendet die allgemeine Sort-Klasse (die im obigen Plan verwendet wird) Merge-Sort (zuerst intern, dann Übergang zu extern). Im Durchschnitt erfordert dieser Algorithmus n log n Vergleiche, um n Elemente zu sortieren. Vor diesem Hintergrund ist es wahrscheinlich ein guter Ausgangspunkt, anzunehmen, dass der CPU-Anteil der Betreiberkosten auf einer Formel wie der folgenden basiert:
Operator-CPU-Kosten =Natürlich könnte dies eine zu starke Vereinfachung der tatsächlichen Kostenformel sein, die Microsoft verwendet, aber in Ermangelung jeglicher Dokumentation zu diesem Thema handelt es sich hier um eine anfängliche bestmögliche Schätzung.
Als Nächstes können Sie die CPU-Kosten für das Sortieren aus zwei Abfrageplänen erhalten, die zum Sortieren unterschiedlicher Zeilenzahlen erstellt wurden, z. B. 1000 und 2000, und basierend auf diesen und der obigen Formel die Vergleichskosten und die Startkosten zurückentwickeln. Zu diesem Zweck müssen Sie keine gruppierte Abfrage verwenden; Es reicht aus, nur ein einfaches ORDER BY zu machen. Ich werde die folgenden zwei Abfragen verwenden (wir nennen sie Abfrage 2 und Abfrage 3):
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid;
Der Punkt beim Sortieren nach dem Ergebnis einer Berechnung besteht darin, die Verwendung eines Sort-Operators im Plan zu erzwingen.
Abbildung 2 zeigt die relevanten Teile der beiden Pläne:
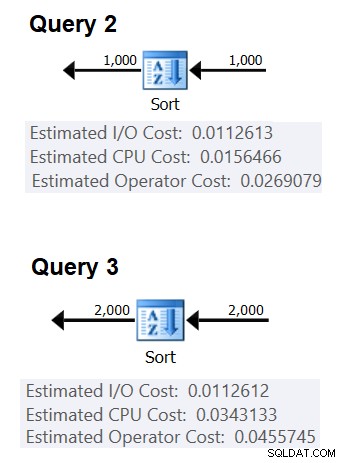
Abbildung 2:Pläne für Abfrage 2 und Abfrage 3
Um die Kosten eines Vergleichs abzuleiten, würden Sie die folgende Formel verwenden:
Vergleichskosten =
((
/ (
(0,0343133 – 0,0156466) / (2000*LOG(2000) – 1000*LOG(1000)) =2,25061348918698E-06
Was die Anlaufkosten anbelangt, können Sie sie auf der Grundlage eines der beiden Pläne ableiten, z. B. auf der Grundlage des Plans, der 2000 Zeilen sortiert:
Startkosten =0,0343133 – 2000*LOG(2000) * 2,25061348918698E-06 =9,99127891201865E-05
Und somit wird unsere Formel für die CPU-Kosten sortieren:
CPU-Kosten des Sortieroperators =9,99127891201865E-05 + @numrows * LOG(@numrows) * 2,25061348918698E-06Bei Verwendung ähnlicher Techniken werden Sie feststellen, dass Faktoren wie die durchschnittliche Zeilengröße, die Anzahl der sortierten Spalten und deren Datentypen die geschätzten CPU-Kosten für die Sortierung nicht beeinflussen. Der einzige Faktor, der relevant zu sein scheint, ist die geschätzte Anzahl der Zeilen. Beachten Sie, dass für die Sortierung eine Speicherzuweisung erforderlich ist und die Zuweisung proportional zur Anzahl der Zeilen (nicht Gruppen) und der durchschnittlichen Zeilengröße ist. Unser Fokus liegt derzeit jedoch auf den geschätzten Operatorkosten, und es scheint, dass diese Schätzung nur von der geschätzten Anzahl von Zeilen beeinflusst wird.
Diese Formel scheint die CPU-Kosten bis zu einem Schwellenwert von etwa 5.000 Zeilen gut vorherzusagen. Probieren Sie es mit folgenden Zahlen aus:100, 200, 300, 400, 500, 1000, 2000, 3000, 4000, 5000:
SELECT numrows, 9.99127891201865E-05 + numrows * LOG(numrows) * 2.25061348918698E-06 AS vorhergesagte Kosten FROM (VALUES(100), (200), (300), (400), (500), (1000) , (2000), (3000), (4000), (5000)) AS D(Zahlen);
Vergleichen Sie die Vorhersagen der Formel mit den geschätzten CPU-Kosten, die die Pläne für die folgenden Abfragen zeigen:
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (100) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (200) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (300) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (400) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (500) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (2000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (3000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (4000) * FROM dbo.Orders) AS D ORDER BY myorderid; SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (5000) * FROM dbo.Orders) AS D ORDER BY myorderid;
Ich habe die folgenden Ergebnisse:
numrows vorhergesagte Kosten geschätztes Kostenverhältnis ----------- --------------- -------------- --- ---- 100 0.0011363 0.0011365 1.00018 200 0.0024848 0.0024849 1.00004 300 0.0039510 0.0039511 1.00003 400 0.0054937 0.0054938 1.00002 500 0.0070933 0.0070933 1.00000 1000 0.0156466 0.0156466 1.00000 2000 0.0343133 0.0343133 1.00000 3000 0.0541576 0.0541576 1.00000 4000 0.0747667 0.0747665 1.00000 5000 0.0959445 0.0959442 1.00000
Die Spalte „prognostizierte Kosten“ zeigt die Vorhersage basierend auf unserer nachgebauten Formel, die Spalte „schätzungsweise Kosten“ zeigt die geschätzten Kosten, die im Plan erscheinen, und die Spalte „Verhältnis“ zeigt das Verhältnis zwischen den letzteren und den ersteren.
Die Vorhersage scheint bis zu 5.000 Zeilen ziemlich genau zu sein. Bei Zahlen über 5.000 funktioniert unsere Reverse-Engineering-Formel jedoch nicht mehr gut. Die folgende Abfrage gibt Ihnen die Vorhersagen für 6.000, 7.000, 10.000, 20.000, 100.000 und 200.000 Zeilen:
SELECT numrows, 9.99127891201865E-05 + numrows * LOG(numrows) * 2.25061348918698E-06 AS vorhergesagte Kosten FROM (VALUES(6000), (7000), (10000), (20000), (100000), (200000) ) AS D(Zahlen);
Verwenden Sie die folgenden Abfragen, um die geschätzten CPU-Kosten aus den Plänen abzurufen (beachten Sie den Hinweis, einen seriellen Plan zu erzwingen, da es bei einer größeren Anzahl von Zeilen wahrscheinlicher ist, dass Sie einen parallelen Plan erhalten, bei dem die Kostenformeln für Parallelität angepasst sind):
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (6000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (7000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (10000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (20000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1);
Ich habe die folgenden Ergebnisse:
numrows vorhergesagte Kosten geschätztes Kostenverhältnis ----------- --------------- -------------- --- --- 6000 0,117575 0,160970 1,3691 7000 0,139583 0,244848 1.7541 10000 0,207389 0,603420 2.9096 20000 0,445878 1.311710 2.9419 100000 2.591210.Wie Sie sehen können, wird unsere Formel über 5.000 Zeilen hinaus immer ungenauer, aber merkwürdigerweise stabilisiert sich das Genauigkeitsverhältnis bei etwa 2,94 bei etwa 20.000 Zeilen. Das bedeutet, dass unsere Formel bei großen Zahlen immer noch gilt, nur bei höheren Vergleichskosten, und dass sie etwa zwischen 5.000 und 20.000 Zeilen allmählich von den niedrigeren Vergleichskosten zu den höheren übergeht. Aber was könnte den Unterschied zwischen dem kleinen und dem großen Maßstab erklären? Die gute Nachricht ist, dass die Antwort nicht so komplex ist, wie die Quantenmechanik und die allgemeine Relativitätstheorie mit der Stringtheorie in Einklang zu bringen. Es ist nur so, dass Microsoft im kleineren Maßstab berücksichtigen wollte, dass der CPU-Cache wahrscheinlich verwendet wird, und aus Kostengründen von einer festen Cache-Größe ausgeht.
Um also die Vergleichskosten im großen Maßstab zu ermitteln, möchten Sie die Sortier-CPU-Kosten aus zwei Plänen für Zahlen über 20.000 verwenden. Ich verwende 100.000 und 200.000 Zeilen (die letzten beiden Zeilen in der obigen Tabelle). Hier ist die Formel, um die Vergleichskosten abzuleiten:
Vergleichskosten =
(16,1657 – 7,62392) / (200000*LOG(200000) – 100000*LOG(100000)) =6,62193536908588E-06Als Nächstes ist hier die Formel zum Ableiten der Startkosten basierend auf dem Plan für 200.000 Zeilen:
Anlaufkosten =
16,1657 – 200000*LOG(200000) * 6,62193536908588E-06 =1,35166186417734E-04Es könnte sehr gut sein, dass die Anlaufkosten für die kleine und die große Waage gleich sind und dass die Differenz, die wir erhalten haben, auf Rundungsfehler zurückzuführen ist. Auf jeden Fall werden die Startkosten bei einer großen Anzahl von Zeilen im Vergleich zu den Vergleichskosten vernachlässigbar.
Zusammenfassend ist hier die Formel für die CPU-Kosten des Sort-Operators für große Zahlen (>=20000):
Operator-CPU-Kosten =1,35166186417734E-04 + @numrows * LOG(@numrows) * 6,62193536908588E-06Lassen Sie uns die Genauigkeit der Formel mit 500.000, 1 Mio. und 10 Mio. Zeilen testen. Der folgende Code gibt Ihnen die Vorhersagen unserer Formel:
SELECT numrows, 1.35166186417734E-04 + numrows * LOG(numrows) * 6.62193536908588E-06 AS predicatedcost FROM (VALUES(500000), (1000000), (10000000)) AS D(numrows);Verwenden Sie die folgenden Abfragen, um die geschätzten CPU-Kosten abzurufen:
SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT orderid % 1000000000 as myorderid FROM (SELECT TOP (1000000) * FROM dbo.Orders) AS D ORDER BY myorderid OPTION(MAXDOP 1); SELECT CHECKSUM(NEWID()) as myorderid FROM (SELECT TOP (10000000) O1.orderid FROM dbo.Orders AS O1 CROSS JOIN dbo.Orders AS O2) AS D ORDER BY myorderid OPTION(MAXDOP 1);Ich habe die folgenden Ergebnisse:
numrows vorhergesagte Kosten geschätztes Kostenverhältnis ----------- --------------- -------------- --- --- 500000 43,4479 43,448 1,0000 1000000 91,4856 91,486 1,0000 10000000 1067,3300 1067,340 1,0000Sieht so aus, als würde unsere Formel für große Zahlen ziemlich gut funktionieren.
Alles zusammenfügen
Die Gesamtkosten für die Anwendung eines Stream-Aggregats mit expliziter Sortierung für eine kleine Anzahl von Zeilen (<=5.000 Zeilen) betragen:
+ + =
0,0112613
+ 9,99127891201865E-05 + @numrows * LOG(@ numrows) * 2.25061348918698E-06
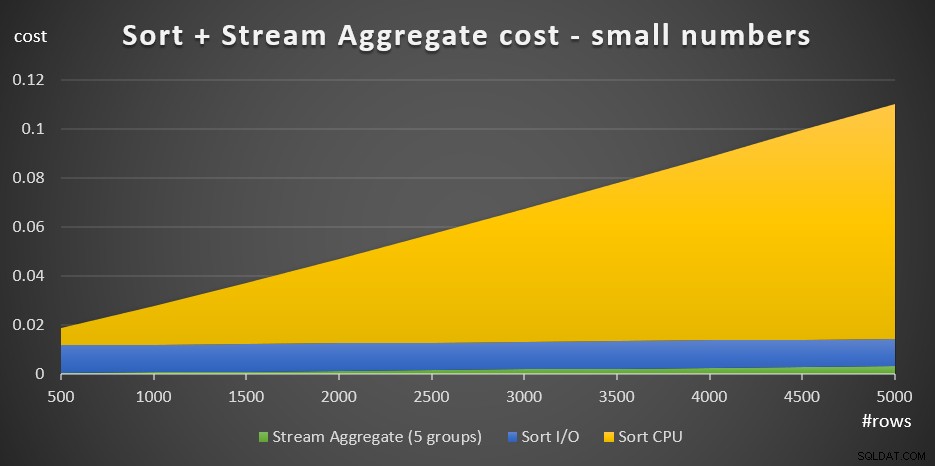
+ @numrows * 0.0000006 + @numgroups * 0.0000005Abbildung 3 zeigt ein Flächendiagramm, das zeigt, wie sich diese Kosten skalieren.
Abbildung 3:Cost of Sort + Stream Aggregate für kleine Anzahlen von ZeilenDie Sortier-CPU-Kosten sind der bedeutendste Teil der Gesamtkosten von Sort + Stream. Dennoch sind bei einer kleinen Anzahl von Zeilen die Stream-Aggregate-Kosten und der Sort-I/O-Teil der Kosten nicht ganz zu vernachlässigen. Optisch sind alle drei Teile im Diagramm gut zu erkennen.
Bei einer großen Anzahl von Zeilen (>=20.000) lautet die Kostenformel:
0.0112613
+ 1.35166186417734E-04 + @numrows * LOG(@numrows) * 6.62193536908588E-06
+ @numrows * 0.0000006 + @numgroups * 0.0000005Ich sah keinen großen Wert darin, genau zu verfolgen, wie die Vergleichskosten vom kleinen zum großen Maßstab übergehen.
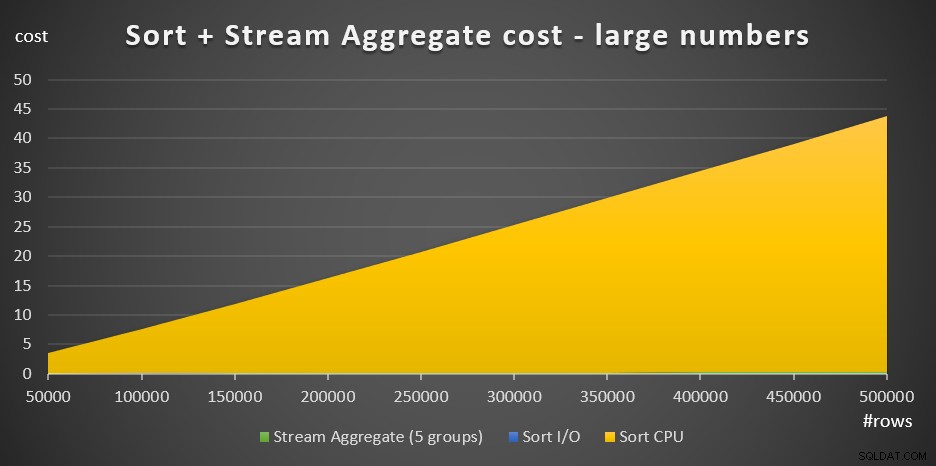
Abbildung 4 zeigt ein Flächendiagramm, das zeigt, wie sich die Kosten für große Zahlen skalieren.
Abbildung 4:Cost of Sort + Stream Aggregate für eine große Anzahl von ZeilenBei einer großen Anzahl von Zeilen sind die Stream Aggregate-Kosten und die Sort-I/O-Kosten im Vergleich zu den Sort-CPU-Kosten so vernachlässigbar, dass sie im Diagramm nicht einmal mit bloßem Auge sichtbar sind. Außerdem ist der Teil der Sort-CPU-Kosten, der der Startarbeit zugeschrieben wird, ebenfalls vernachlässigbar. Daher ist der einzige Teil der Kostenberechnung, der wirklich aussagekräftig ist, der gesamte Vergleichsaufwand:
@numrows * LOG(@numrows) *Wenn Sie also die Skalierung der Sort + Stream Aggregate-Strategie bewerten müssen, können Sie sie allein auf diesen dominanten Teil vereinfachen. Wenn Sie beispielsweise auswerten müssen, wie sich die Kosten von 100.000 Zeilen auf 100.000.000 Zeilen skalieren würden, können Sie die Formel verwenden (beachten Sie, dass die Vergleichskosten irrelevant sind):
(100000000 * LOG(100000000)*) / (100000 * LOG(100000)*) =1600Dies sagt Ihnen, dass, wenn die Anzahl der Zeilen von 100.000 um den Faktor 1.000 auf 100.000.000 erhöht wird, die geschätzten Kosten um den Faktor 1.600 steigen.
Die Skalierung von 1.000.000 auf 1.000.000.000 Zeilen wird wie folgt berechnet:
(1000000000 * LOG(1000000000)) / (1000000 * LOG(1000000)) =1500Das heißt, wenn die Anzahl der Zeilen von 1.000.000 um den Faktor 1.000 erhöht wird, steigen die geschätzten Kosten um den Faktor 1.500.
Dies sind interessante Beobachtungen zur Art und Weise, wie die Sort + Stream Aggregate-Strategie skaliert. Aufgrund der sehr niedrigen Startkosten und der zusätzlichen linearen Skalierung würden Sie erwarten, dass diese Strategie mit einer sehr kleinen Anzahl von Zeilen gut funktioniert, aber nicht so gut mit einer großen Anzahl. Auch die Tatsache, dass der Stream Aggregate-Operator allein einen so kleinen Bruchteil der Kosten im Vergleich dazu ausmacht, wenn auch eine Sortierung benötigt wird, sagt Ihnen, dass Sie eine deutlich bessere Leistung erzielen können, wenn die Situation so ist, dass Sie in der Lage sind, einen unterstützenden Index zu erstellen .
Im nächsten Teil der Serie werde ich die Skalierung des Hash-Aggregate-Algorithmus behandeln. Wenn Ihnen diese Übung gefällt, Kostenformeln herauszufinden, versuchen Sie, ob Sie es für diesen Algorithmus herausfinden können. Wichtig ist, die Faktoren herauszufinden, die ihn beeinflussen, wie er skaliert und unter welchen Bedingungen er besser abschneidet als die anderen Algorithmen.