Ein Performance-Tuning-Engagement kann viele Wendungen nehmen, während Sie es durcharbeiten – es hängt alles davon ab, was sich als Problem herausstellt und was die Daten Ihnen sagen. An manchen Tagen landet es bei einer bestimmten Abfrage oder einer Reihe von Abfragen, die mit Indizes verbessert werden können – entweder neue oder Änderungen an bestehenden Indizes. Einer meiner Lieblingsbereiche beim Tuning ist die Arbeit mit Indizes, und als ich über diesen Beitrag nachdachte, war ich versucht, das Index-Tuning als eine „einfachere“ Aufgabe zu bezeichnen … aber das ist es wirklich nicht.
Ich betrachte das Index-Tuning als eine Kunst und eine Wissenschaft. Sie müssen versuchen, wie der Optimierer zu denken, und Sie müssen das Tabellenschema und die Abfrage (oder Abfragen) verstehen, die Sie optimieren möchten. Beide sind datengetrieben und damit in der Kategorie Wissenschaft. Die Kunstkomponente kommt ins Spiel, wenn man an den Anderen denkt Indizes für die Tabelle und all der andere Abfragen, die die Tabelle betreffen, die von Indexänderungen betroffen sein könnte.
Schritt 1:Identifizieren Sie die Abfrage und überprüfen Sie den Plan
Wenn ich eine Abfrage entdecke, die von einem Index profitieren könnte, erhalte ich sofort ihren Plan. Ich rufe den Ausführungsplan häufig aus dem Plan-Cache oder dem Abfragespeicher ab und verwende dann SSMS, um den Ausführungsplan plus Laufzeitstatistik (auch bekannt als tatsächlicher Ausführungsplan) abzurufen. Oft ist die Form dieser beiden Pläne gleich; aber es ist keine Garantie, weshalb ich gerne beides sehe.
Der Plan enthält möglicherweise eine fehlende Indexempfehlung, er enthält möglicherweise einen Clustered-Index-Scan (oder einen Heap-Scan, wenn kein Clustered-Index vorhanden ist), er verwendet möglicherweise einen Nonclustered-Index, hat dann aber eine Suche zum Abrufen zusätzlicher Spalten. Jedes dieser Probleme einzeln zu beheben, klingt ziemlich einfach. Fügen Sie einfach den fehlenden Index hinzu, richtig? Wenn ein Clustered-Index oder Heap gescannt wird, den Index erstellen, den ich für die Abfrage benötige, und fertig? Oder wenn ein Index verwendet wird, dieser aber zur Tabelle geht, um die zusätzlichen Spalten zu erhalten, fügen Sie einfach die Spalten zu diesem Index hinzu?
Es ist normalerweise nicht so einfach, und selbst wenn es so ist, gehe ich immer noch durch den Prozess, den ich hier skizziere.
Schritt 2:Bestimmen Sie, welche Tabelle(n) überprüft werden sollen
Jetzt, da ich meine Abfrage habe, muss ich herausfinden, welche Tabellen nicht richtig indiziert sind. Zusätzlich zur Überprüfung des Plans aktiviere ich auch IO- und TIME-Statistiken in SSMS. Das ist wahrscheinlich altmodisch von mir, da Ausführungspläne mit jedem Release immer mehr Informationen enthalten – einschließlich Dauer und IO-Nummern pro Operator –, aber ich mag die IO-Statistiken, weil ich schnell die Lesevorgänge für jede Tabelle sehen kann. Für komplexe Abfragen mit mehreren Verknüpfungen oder Unterabfragen oder CTEs oder verschachtelten Ansichten, um zu verstehen, wo die E/A und/oder Zeit in den Abfragelaufwerken verbracht wird, wo ich meine Zeit verbringe. Wann immer möglich, nehme ich von diesem Punkt an die größere, komplexe Abfrage und reduziere sie auf den Teil, der das größte Problem verursacht.
Wenn es beispielsweise eine Abfrage gibt, die mit 10 Tabellen verknüpft ist und zwei Unterabfragen hat, hilft mir der Plan (zusammen mit IO- und Dauerinformationen) zu identifizieren, wo das Problem besteht. Dann ziehe ich diesen Teil der Abfrage heraus – die problematische Tabelle und vielleicht ein paar andere, mit denen sie verbunden ist – und konzentriere mich darauf. Manchmal ist es nur die Unterabfrage, also fange ich dort an.
Schritt 3:Sehen Sie sich vorhandene Indizes an
Nachdem die Abfrage (oder ein Teil der Abfrage) definiert ist, konzentriere ich mich auf die vorhandenen Indizes für die beteiligten Tabellen. Für diesen Schritt verlasse ich mich auf Kimberlys Version von sp_helpindex. Ich bevorzuge ihre Version gegenüber dem Standard sp_helpindex, weil sie auch INCLUDEd-Spalten und die Filterdefinition (falls vorhanden) auflistet. Abhängig von der Anzahl der Indizes, die für eine Tabelle angezeigt werden, kopiere ich diese häufig und füge sie in Excel ein und sortiere dann basierend auf dem Indexschlüssel und dann den enthaltenen Spalten. Dadurch kann ich Redundanzen schnell finden.
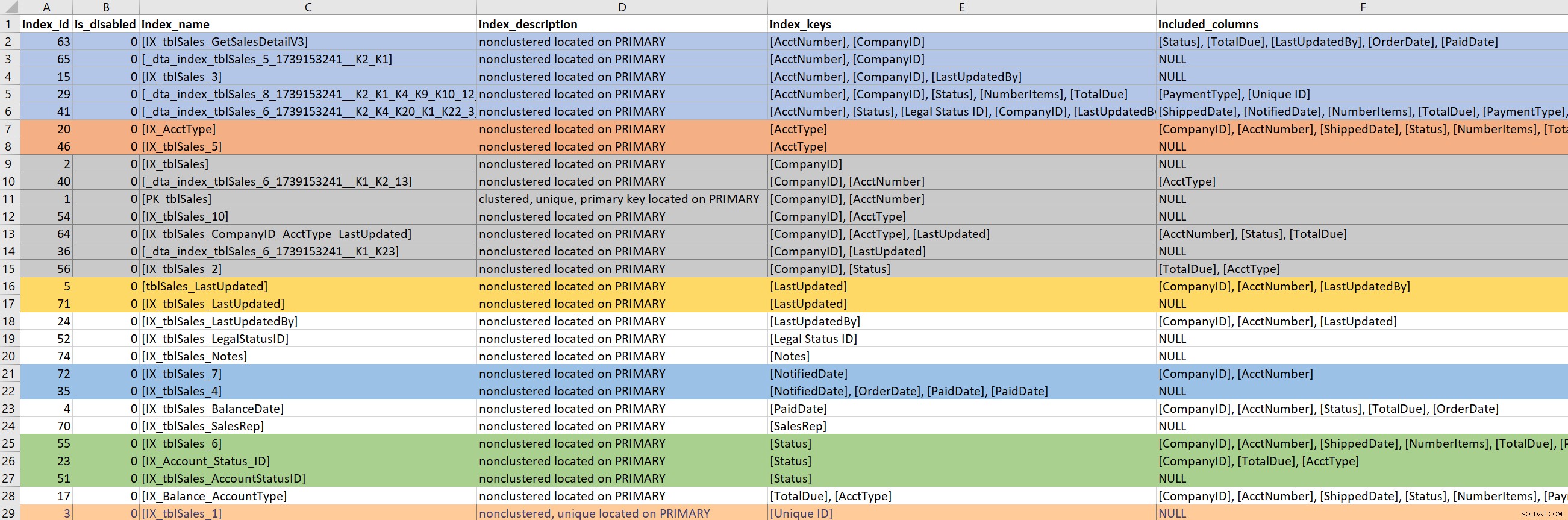
Basierend auf der obigen Beispielausgabe gibt es sieben Indizes, die mit CompanyID beginnen, fünf, die mit AcctNumber beginnen, und einige andere potenzielle Redundanzen. Obwohl es ideal erscheint, nur einen zu haben Index, der auf eine bestimmte Spalte führt (z. B. CompanyID), für einige Abfragemuster reicht das nicht aus.
Wenn ich mir vorhandene Indizes anschaue, kann ich sehr leicht in ein Kaninchenloch geraten. Ich schaue mir die obige Ausgabe an und beginne sofort zu fragen, warum es sieben Indizes gibt, die mit CompanyID beginnen, und ich möchte wissen, wer sie erstellt hat, warum und für welche Abfrage. Aber … wenn meine problematische Abfrage keine CompanyID verwendet, sollte es mich interessieren? Ja … denn im Allgemeinen bin ich da, um die Leistung zu verbessern, und wenn das bedeutet, dass ich mir nebenbei auch andere Indizes in der Tabelle anschaue, dann sei es so. Aber hier ist es leicht, die Zeit (und den wahren Zweck) aus den Augen zu verlieren.
Wenn meine problematische Abfrage einen Index benötigt, der auf PaidDate führt, muss ich mich nur mit einem vorhandenen Index befassen. Wenn meine problematische Abfrage einen Index benötigt, der auf AcctNumber führt, wird es schwierig. Wenn vorhandene Indizes eine Abfrage abdecken und ich einen Index erweitern (mehr Spalten hinzufügen) oder konsolidieren (zwei oder vielleicht drei Indizes zu einem zusammenführen) möchte, muss ich mich einarbeiten.
Schritt 4:Nutzungsstatistiken für den Index
Ich finde, dass viele Leute die Indexnutzungsstatistiken nicht kontinuierlich erfassen. Das ist bedauerlich, denn ich finde die Daten hilfreich bei der Entscheidung, welche Indizes beibehalten und welche gelöscht oder zusammengeführt werden sollen. Falls ich keine historischen Nutzungsstatistiken habe, überprüfe ich zumindest, wie die Nutzung aktuell aussieht (seit dem letzten Dienstneustart):
SELECT
DB_NAME(ius.database_id),
OBJECT_NAME(i.object_id) [TableName],
i.name [IndexName],
ius.database_id,
i.object_id,
i.index_id,
ius.user_seeks,
ius.user_scans,
ius.user_lookups,
ius.user_updates
FROM sys.indexes i
INNER JOIN sys.dm_db_index_usage_stats ius
ON ius.index_id = i.index_id AND ius.object_id = i.object_id
WHERE ius.database_id = DB_ID(N'Sales2020')
AND i.object_id = OBJECT_ID('dbo.tblSales');
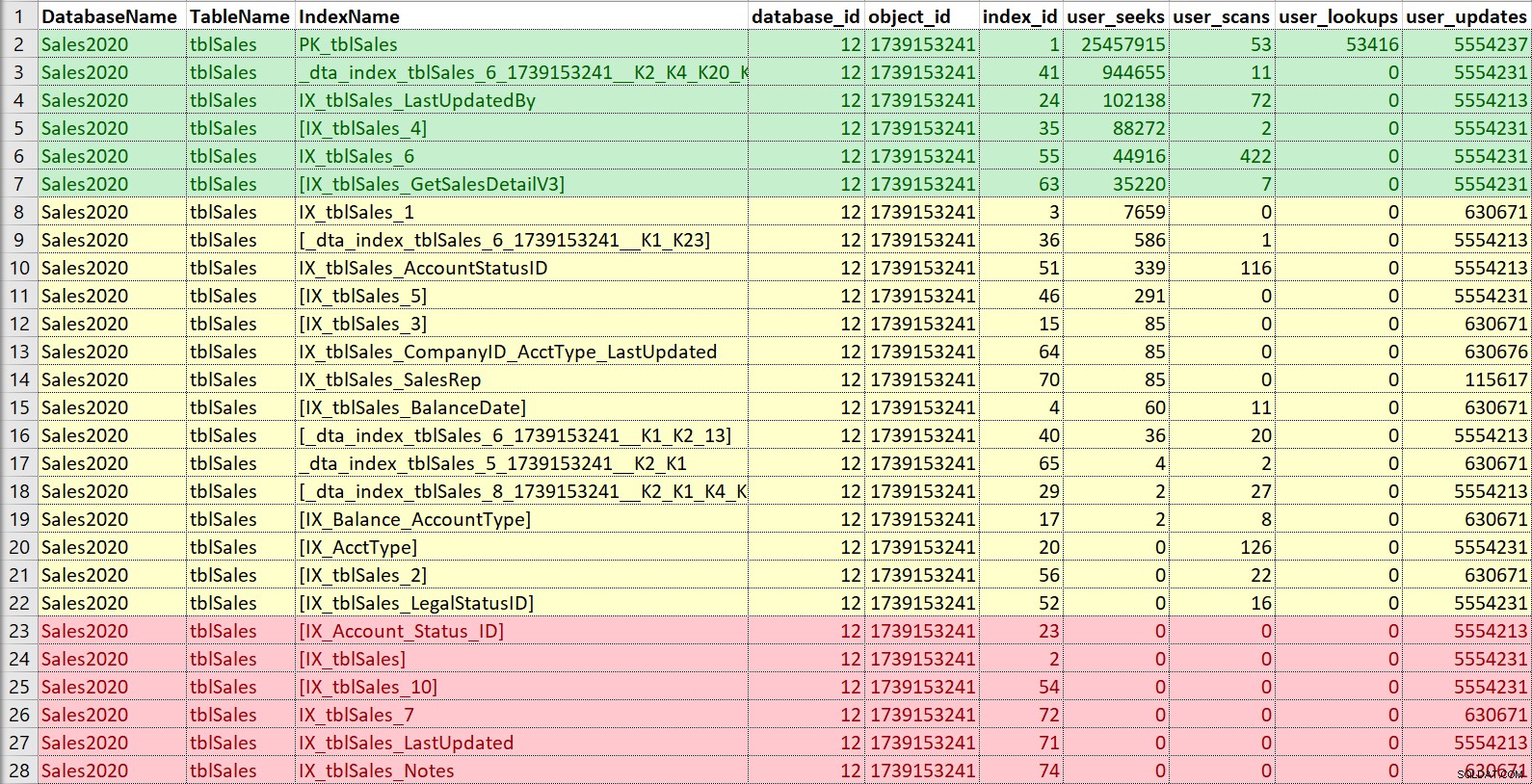
Auch hier stecke ich das gerne in Excel, sortiere nach Suchvorgängen und dann Scans und notiere auch Aktualisierungen. In diesem Beispiel sind die Indizes in Rot diejenigen ohne Suchvorgänge, Scans oder Lookups ... nur Updates. Dies sind Kandidaten, die deaktiviert und möglicherweise gelöscht werden können, wenn sie wirklich nicht verwendet werden (auch hier würde ein Nutzungsverlauf helfen). Die Indizes in Grün werden definitiv verwendet, ich möchte diese behalten (obwohl sie in einigen Fällen vielleicht angepasst werden könnten). Die in Gelb ... einige werden irgendwie benutzt, andere werden kaum benutzt. Auch hier wäre der Verlauf oder der Kontext von anderen hilfreich – manchmal kann ein Index für einen Bericht oder Prozess, der nicht ständig ausgeführt wird, von entscheidender Bedeutung sein.
Wenn ich nur einen neuen Index ändern oder hinzufügen möchte, im Gegensatz zu einer echten Bereinigung und Konsolidierung, dann mache ich mir hauptsächlich Gedanken über alle Indizes, die dem ähneln, was ich hinzufügen oder ändern möchte. Ich werde jedoch darauf achten, den Kunden auf die Nutzungsinformationen hinzuweisen und, wenn es die Zeit erlaubt, bei der allgemeinen Indexierungsstrategie für die Tabelle behilflich zu sein.
Was kommt als Nächstes?
Wir sind noch nicht fertig! Dies ist Teil 1 meiner Herangehensweise an das Index-Tuning, und mein nächster Teil wird den Rest meiner Schritte auflisten. Wenn Sie in der Zwischenzeit keine Indexnutzungsstatistiken erfassen, können Sie dies mithilfe der obigen Abfrage oder einer anderen Variante einrichten. Ich würde empfehlen, Nutzungsstatistiken für alle Benutzerdatenbanken zu erfassen, nicht nur für eine bestimmte Tabelle und Datenbank, wie ich es oben getan habe, also ändern Sie das Prädikat nach Bedarf. Und vergessen Sie schließlich als Teil dieses geplanten Jobs zum Snapshot dieser Informationen in einer Tabelle nicht einen weiteren Schritt, um die Tabelle zu bereinigen, nachdem die Daten eine Weile dort waren (ich bewahre sie mindestens sechs Monate lang auf; manche sagen vielleicht a Jahr erforderlich).