Lücken- und Inselaufgaben sind klassische Abfrageherausforderungen, bei denen Sie Bereiche fehlender Werte und Bereiche vorhandener Werte in einer Sequenz identifizieren müssen. Die Reihenfolge basiert oft auf einigen Datums- oder Datums- und Uhrzeitwerten, die normalerweise in regelmäßigen Abständen erscheinen sollten, aber einige Einträge fehlen. Die Lückenaufgabe sucht nach den fehlenden Zeiträumen und die Inselaufgabe sucht nach den vorhandenen Zeiträumen. Ich habe in der Vergangenheit viele Lösungen für Lücken und Inselaufgaben in meinen Büchern und Artikeln behandelt. Kürzlich wurde ich von meinem Freund Adam Machanic mit einer neuen besonderen Inselherausforderung konfrontiert, und die Lösung erforderte ein wenig Kreativität. In diesem Artikel stelle ich die Herausforderung und die Lösung vor, die ich gefunden habe.
Die Herausforderung
In Ihrer Datenbank verfolgen Sie die von Ihrem Unternehmen unterstützten Dienste in einer Tabelle namens CompanyServices, und jeder Dienst meldet normalerweise etwa einmal pro Minute in einer Tabelle namens EventLog, dass er online ist. Der folgende Code erstellt diese Tabellen und füllt sie mit kleinen Sätzen von Beispieldaten:
SET NOCOUNT ON; USE tempdb; IF OBJECT_ID(N'dbo.EventLog') IS NOT NULL DROP TABLE dbo.EventLog; IF OBJECT_ID(N'dbo.CompanyServices') IS NOT NULL DROP TABLE dbo.CompanyServices; CREATE TABLE dbo.CompanyServices ( serviceid INT NOT NULL, CONSTRAINT PK_CompanyServices PRIMARY KEY(serviceid) ); GO INSERT INTO dbo.CompanyServices(serviceid) VALUES(1), (2), (3); CREATE TABLE dbo.EventLog ( logid INT NOT NULL IDENTITY, serviceid INT NOT NULL, logtime DATETIME2(0) NOT NULL, CONSTRAINT PK_EventLog PRIMARY KEY(logid) ); GO INSERT INTO dbo.EventLog(serviceid, logtime) VALUES (1, '20180912 08:00:00'), (1, '20180912 08:01:01'), (1, '20180912 08:01:59'), (1, '20180912 08:03:00'), (1, '20180912 08:05:00'), (1, '20180912 08:06:02'), (2, '20180912 08:00:02'), (2, '20180912 08:01:03'), (2, '20180912 08:02:01'), (2, '20180912 08:03:00'), (2, '20180912 08:03:59'), (2, '20180912 08:05:01'), (2, '20180912 08:06:01'), (3, '20180912 08:00:01'), (3, '20180912 08:03:01'), (3, '20180912 08:04:02'), (3, '20180912 08:06:00'); SELECT * FROM dbo.EventLog;
Die EventLog-Tabelle ist derzeit mit den folgenden Daten gefüllt:
logid serviceid logtime ----------- ----------- --------------------------- 1 1 2018-09-12 08:00:00 2 1 2018-09-12 08:01:01 3 1 2018-09-12 08:01:59 4 1 2018-09-12 08:03:00 5 1 2018-09-12 08:05:00 6 1 2018-09-12 08:06:02 7 2 2018-09-12 08:00:02 8 2 2018-09-12 08:01:03 9 2 2018-09-12 08:02:01 10 2 2018-09-12 08:03:00 11 2 2018-09-12 08:03:59 12 2 2018-09-12 08:05:01 13 2 2018-09-12 08:06:01 14 3 2018-09-12 08:00:01 15 3 2018-09-12 08:03:01 16 3 2018-09-12 08:04:02 17 3 2018-09-12 08:06:00
Die besondere Aufgabe der Inseln besteht darin, die Verfügbarkeitszeiträume (bereitgestellt, Startzeit, Endzeit) zu identifizieren. Ein Haken ist, dass es keine Garantie dafür gibt, dass ein Dienst genau jede Minute meldet, dass er online ist; Sie sollten ein Intervall von bis zu beispielsweise 66 Sekunden vom vorherigen Protokolleintrag tolerieren und es dennoch als Teil desselben Verfügbarkeitszeitraums (Insel) betrachten. Nach 66 Sekunden beginnt mit dem neuen Protokolleintrag ein neuer Verfügbarkeitszeitraum. Für die obigen Eingabebeispieldaten sollte Ihre Lösung also die folgende Ergebnismenge zurückgeben (nicht unbedingt in dieser Reihenfolge):
serviceid starttime endtime ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 2 2018-09-12 08:00:02 2018-09-12 08:06:01 3 2018-09-12 08:00:01 2018-09-12 08:00:01 3 2018-09-12 08:03:01 2018-09-12 08:04:02 3 2018-09-12 08:06:00 2018-09-12 08:06:00
Beachten Sie beispielsweise, wie Protokolleintrag 5 eine neue Insel beginnt, da das Intervall vom vorherigen Protokolleintrag 120 Sekunden (> 66) beträgt, während Protokolleintrag 6 keine neue Insel beginnt, da das Intervall vom vorherigen Eintrag 62 Sekunden beträgt ( <=66). Ein weiterer Haken ist, dass Adam wollte, dass die Lösung mit Umgebungen vor SQL Server 2012 kompatibel ist, was es zu einer viel schwierigeren Herausforderung macht, da Sie keine Fensteraggregatfunktionen mit einem Rahmen verwenden können, um laufende Summen zu berechnen und Fensterfunktionen zu versetzen wie LAG und LEAD. Wie üblich schlage ich vor, dass Sie versuchen, die Herausforderung selbst zu lösen, bevor Sie sich meine Lösungen ansehen. Verwenden Sie die kleinen Sätze von Beispieldaten, um die Gültigkeit Ihrer Lösungen zu überprüfen. Verwenden Sie den folgenden Code, um Ihre Tabellen mit großen Sätzen von Beispieldaten zu füllen (500 Dienste, ~10 Millionen Protokolleinträge, um die Leistung Ihrer Lösungen zu testen):
-- Helper function dbo.GetNums
IF OBJECT_ID(N'dbo.GetNums') IS NOT NULL DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
-- ~10,000,000 intervals
DECLARE
@numservices AS INT = 500,
@logsperservice AS INT = 20000,
@enddate AS DATETIME2(0) = '20180912',
@validinterval AS INT = 60, -- seconds
@normdifferential AS INT = 3, -- seconds
@percentmissing AS FLOAT = 0.01;
TRUNCATE TABLE dbo.EventLog;
TRUNCATE TABLE dbo.CompanyServices;
INSERT INTO dbo.CompanyServices(serviceid)
SELECT A.n AS serviceid
FROM dbo.GetNums(1, @numservices) AS A;
WITH C AS
(
SELECT S.n AS serviceid,
DATEADD(second, -L.n * @validinterval + CHECKSUM(NEWID()) % (@normdifferential + 1), @enddate) AS logtime,
RAND(CHECKSUM(NEWID())) AS rnd
FROM dbo.GetNums(1, @numservices) AS S
CROSS JOIN dbo.GetNums(1, @logsperservice) AS L
)
INSERT INTO dbo.EventLog WITH (TABLOCK) (serviceid, logtime)
SELECT serviceid, logtime
FROM C
WHERE rnd > @percentmissing; Die Ausgaben, die ich für die Schritte meiner Lösungen bereitstelle, gehen von den kleinen Sätzen von Beispieldaten aus, und die von mir bereitgestellten Leistungszahlen gehen von den großen Sätzen aus.
Alle Lösungen, die ich vorstellen werde, profitieren von folgendem Index:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Viel Glück!
Lösung 1 für SQL Server 2012+
Bevor ich eine Lösung behandle, die mit Umgebungen vor SQL Server 2012 kompatibel ist, werde ich eine behandeln, die mindestens SQL Server 2012 erfordert. Ich nenne sie Lösung 1.
Der erste Schritt in der Lösung besteht darin, ein Flag namens isstart zu berechnen, das 0 ist, wenn das Ereignis keine neue Insel startet, und andernfalls 1. Dies kann erreicht werden, indem die LAG-Funktion verwendet wird, um die Protokollzeit des vorherigen Ereignisses abzurufen und zu prüfen, ob der Zeitunterschied in Sekunden zwischen dem vorherigen und dem aktuellen Ereignis kleiner oder gleich der zulässigen Lücke ist. Hier ist der Code, der diesen Schritt implementiert:
DECLARE @allowedgap AS INT = 66; -- in seconds
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog; Dieser Code generiert die folgende Ausgabe:
logid serviceid logtime isstart ----------- ----------- --------------------------- ----------- 1 1 2018-09-12 08:00:00 1 2 1 2018-09-12 08:01:01 0 3 1 2018-09-12 08:01:59 0 4 1 2018-09-12 08:03:00 0 5 1 2018-09-12 08:05:00 1 6 1 2018-09-12 08:06:02 0 7 2 2018-09-12 08:00:02 1 8 2 2018-09-12 08:01:03 0 9 2 2018-09-12 08:02:01 0 10 2 2018-09-12 08:03:00 0 11 2 2018-09-12 08:03:59 0 12 2 2018-09-12 08:05:01 0 13 2 2018-09-12 08:06:01 0 14 3 2018-09-12 08:00:01 1 15 3 2018-09-12 08:03:01 1 16 3 2018-09-12 08:04:02 0 17 3 2018-09-12 08:06:00 1
Als nächstes erzeugt eine einfache laufende Summe des isstart-Flags eine Inselkennung (ich nenne sie grp). Hier ist der Code, der diesen Schritt implementiert:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
)
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1; Dieser Code generiert die folgende Ausgabe:
logid serviceid logtime isstart grp ----------- ----------- --------------------------- ----------- ----------- 1 1 2018-09-12 08:00:00 1 1 2 1 2018-09-12 08:01:01 0 1 3 1 2018-09-12 08:01:59 0 1 4 1 2018-09-12 08:03:00 0 1 5 1 2018-09-12 08:05:00 1 2 6 1 2018-09-12 08:06:02 0 2 7 2 2018-09-12 08:00:02 1 1 8 2 2018-09-12 08:01:03 0 1 9 2 2018-09-12 08:02:01 0 1 10 2 2018-09-12 08:03:00 0 1 11 2 2018-09-12 08:03:59 0 1 12 2 2018-09-12 08:05:01 0 1 13 2 2018-09-12 08:06:01 0 1 14 3 2018-09-12 08:00:01 1 1 15 3 2018-09-12 08:03:01 1 2 16 3 2018-09-12 08:04:02 0 2 17 3 2018-09-12 08:06:00 1 3
Zuletzt gruppieren Sie die Zeilen nach Service-ID und Inselkennung und geben die minimalen und maximalen Protokollzeiten als Start- und Endzeit jeder Insel zurück. Hier ist die vollständige Lösung:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1
)
SELECT serviceid, MIN(logtime) AS starttime, MAX(logtime) AS endtime
FROM C2
GROUP BY serviceid, grp; Diese Lösung dauerte auf meinem System 41 Sekunden und führte zu dem in Abbildung 1 gezeigten Plan.
 Abbildung 1:Plan für Lösung 1
Abbildung 1:Plan für Lösung 1
Wie Sie sehen können, werden beide Fensterfunktionen basierend auf der Indexreihenfolge berechnet, ohne dass eine explizite Sortierung erforderlich ist.
Wenn Sie SQL Server 2016 oder höher verwenden, können Sie den Trick, den ich hier beschreibe, verwenden, um den Window Aggregate-Operator im Stapelmodus zu aktivieren, indem Sie einen leeren gefilterten Columnstore-Index wie folgt erstellen:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Dieselbe Lösung dauert jetzt nur noch 5 Sekunden auf meinem System und erzeugt den in Abbildung 2 gezeigten Plan.
 Abbildung 2:Plan für Lösung 1 mit dem Window Aggregate-Operator im Stapelmodus
Abbildung 2:Plan für Lösung 1 mit dem Window Aggregate-Operator im Stapelmodus
Das ist alles großartig, aber wie bereits erwähnt, suchte Adam nach einer Lösung, die auf Umgebungen vor 2012 ausgeführt werden kann.
Bevor Sie fortfahren, stellen Sie sicher, dass Sie den Columnstore-Index zur Bereinigung löschen:
DROP INDEX idx_cs ON dbo.EventLog;
Lösung 2 für Umgebungen vor SQL Server 2012
Leider hatten wir vor SQL Server 2012 keine Unterstützung für Offset-Fensterfunktionen wie LAG, noch hatten wir Unterstützung für die Berechnung laufender Summen mit Fensteraggregatfunktionen mit einem Frame. Das bedeutet, dass Sie viel härter arbeiten müssen, um eine vernünftige Lösung zu finden.
Der Trick, den ich verwendet habe, besteht darin, jeden Protokolleintrag in ein künstliches Intervall zu verwandeln, dessen Startzeit die Protokollzeit des Eintrags und dessen Endzeit die Protokollzeit des Eintrags plus die zulässige Lücke ist. Sie können die Aufgabe dann als klassische Intervallpackaufgabe behandeln.
Der erste Schritt in der Lösung berechnet die künstlichen Intervallbegrenzer und die Zeilennummern, die die Positionen der einzelnen Ereignisarten markieren (counteach). Hier ist der Code, der diesen Schritt implementiert:
DECLARE @allowedgap AS INT = 66; SELECT logid, serviceid, logtime AS s, -- important, 's' > 'e', for later ordering DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog;
Dieser Code generiert die folgende Ausgabe:
logid serviceid s e counteach ------ ---------- -------------------- -------------------- ---------- 1 1 2018-09-12 08:00:00 2018-09-12 08:01:06 1 2 1 2018-09-12 08:01:01 2018-09-12 08:02:07 2 3 1 2018-09-12 08:01:59 2018-09-12 08:03:05 3 4 1 2018-09-12 08:03:00 2018-09-12 08:04:06 4 5 1 2018-09-12 08:05:00 2018-09-12 08:06:06 5 6 1 2018-09-12 08:06:02 2018-09-12 08:07:08 6 7 2 2018-09-12 08:00:02 2018-09-12 08:01:08 1 8 2 2018-09-12 08:01:03 2018-09-12 08:02:09 2 9 2 2018-09-12 08:02:01 2018-09-12 08:03:07 3 10 2 2018-09-12 08:03:00 2018-09-12 08:04:06 4 11 2 2018-09-12 08:03:59 2018-09-12 08:05:05 5 12 2 2018-09-12 08:05:01 2018-09-12 08:06:07 6 13 2 2018-09-12 08:06:01 2018-09-12 08:07:07 7 14 3 2018-09-12 08:00:01 2018-09-12 08:01:07 1 15 3 2018-09-12 08:03:01 2018-09-12 08:04:07 2 16 3 2018-09-12 08:04:02 2018-09-12 08:05:08 3 17 3 2018-09-12 08:06:00 2018-09-12 08:07:06 4
Der nächste Schritt besteht darin, die Intervalle in eine chronologische Abfolge von Start- und Endereignissen zu entschwenken, die als Ereignistypen „s“ bzw. „e“ identifiziert werden. Beachten Sie, dass die Wahl der Buchstaben s und e wichtig ist ('s' > 'e' ). Dieser Schritt berechnet Zeilennummern, die die korrekte chronologische Reihenfolge beider Ereignisarten markieren, die nun verschachtelt sind (beide zählen). Falls ein Intervall genau dort endet, wo ein anderes beginnt, packen Sie sie zusammen, indem Sie das Startereignis vor dem Endereignis positionieren. Hier ist der Code, der diesen Schritt implementiert:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
)
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U; Dieser Code generiert die folgende Ausgabe:
logid serviceid logtime eventtype counteach countboth ------ ---------- -------------------- ---------- ---------- ---------- 1 1 2018-09-12 08:00:00 s 1 1 2 1 2018-09-12 08:01:01 s 2 2 1 1 2018-09-12 08:01:06 e 1 3 3 1 2018-09-12 08:01:59 s 3 4 2 1 2018-09-12 08:02:07 e 2 5 4 1 2018-09-12 08:03:00 s 4 6 3 1 2018-09-12 08:03:05 e 3 7 4 1 2018-09-12 08:04:06 e 4 8 5 1 2018-09-12 08:05:00 s 5 9 6 1 2018-09-12 08:06:02 s 6 10 5 1 2018-09-12 08:06:06 e 5 11 6 1 2018-09-12 08:07:08 e 6 12 7 2 2018-09-12 08:00:02 s 1 1 8 2 2018-09-12 08:01:03 s 2 2 7 2 2018-09-12 08:01:08 e 1 3 9 2 2018-09-12 08:02:01 s 3 4 8 2 2018-09-12 08:02:09 e 2 5 10 2 2018-09-12 08:03:00 s 4 6 9 2 2018-09-12 08:03:07 e 3 7 11 2 2018-09-12 08:03:59 s 5 8 10 2 2018-09-12 08:04:06 e 4 9 12 2 2018-09-12 08:05:01 s 6 10 11 2 2018-09-12 08:05:05 e 5 11 13 2 2018-09-12 08:06:01 s 7 12 12 2 2018-09-12 08:06:07 e 6 13 13 2 2018-09-12 08:07:07 e 7 14 14 3 2018-09-12 08:00:01 s 1 1 14 3 2018-09-12 08:01:07 e 1 2 15 3 2018-09-12 08:03:01 s 2 3 16 3 2018-09-12 08:04:02 s 3 4 15 3 2018-09-12 08:04:07 e 2 5 16 3 2018-09-12 08:05:08 e 3 6 17 3 2018-09-12 08:06:00 s 4 7 17 3 2018-09-12 08:07:06 e 4 8
Wie bereits erwähnt, markiert counteach die Position des Ereignisses nur unter den Ereignissen derselben Art, und countboth markiert die Position des Ereignisses unter den kombinierten, verschachtelten Ereignissen beider Arten.
Die Magie wird dann durch den nächsten Schritt gehandhabt – das Berechnen der Anzahl aktiver Intervalle nach jedem Ereignis basierend auf counteach und countboth. Die Anzahl der aktiven Intervalle ist die Anzahl der bisher aufgetretenen Startereignisse minus der Anzahl der bisher aufgetretenen Endereignisse. Bei Startereignissen teilt Ihnen counteach mit, wie viele Startereignisse bisher stattgefunden haben, und Sie können herausfinden, wie viele bisher geendet haben, indem Sie counteach von countboth subtrahieren. Der vollständige Ausdruck, der Ihnen sagt, wie viele Intervalle aktiv sind, lautet also:
counteach - (countboth - counteach)
Bei Endereignissen teilt Ihnen counteach mit, wie viele Endereignisse bisher stattgefunden haben, und Sie können herausfinden, wie viele bisher begonnen haben, indem Sie counteach von countboth subtrahieren. Der vollständige Ausdruck, der Ihnen sagt, wie viele Intervalle aktiv sind, lautet also:
(countboth - counteach) - counteach
Mit dem folgenden CASE-Ausdruck berechnen Sie die countactive-Spalte basierend auf dem Ereignistyp:
CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END Im selben Schritt filtern Sie nur Ereignisse, die den Beginn und das Ende von gepackten Intervallen darstellen. Anfänge von gepackten Intervallen haben einen Typ 's' und eine Zählwert 1. Enden von gepackten Intervallen haben einen Typ 'e' und eine Zählwert 0.
Nach dem Filtern verbleiben Paare von Start-End-Ereignissen mit gepackten Intervallen, aber jedes Paar ist in zwei Zeilen aufgeteilt – eine für das Startereignis und eine andere für das Endereignis. Daher berechnet derselbe Schritt die Paarkennung mithilfe der Zeilennummern mit der Formel (rownum – 1) / 2 + 1.
Hier ist der Code, der diesen Schritt implementiert:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
)
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0); Dieser Code generiert die folgende Ausgabe:
serviceid eventtype logtime grp ----------- ---------- -------------------- ---- 1 s 2018-09-12 08:00:00 1 1 e 2018-09-12 08:04:06 1 1 s 2018-09-12 08:05:00 2 1 e 2018-09-12 08:07:08 2 2 s 2018-09-12 08:00:02 1 2 e 2018-09-12 08:07:07 1 3 s 2018-09-12 08:00:01 1 3 e 2018-09-12 08:01:07 1 3 s 2018-09-12 08:03:01 2 3 e 2018-09-12 08:05:08 2 3 s 2018-09-12 08:06:00 3 3 e 2018-09-12 08:07:06 3
Der letzte Schritt schwenkt die Ereignispaare in eine Zeile pro Intervall und subtrahiert die zulässige Lücke von der Endzeit, um die korrekte Ereigniszeit neu zu generieren. Hier ist der Code der vollständigen Lösung:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
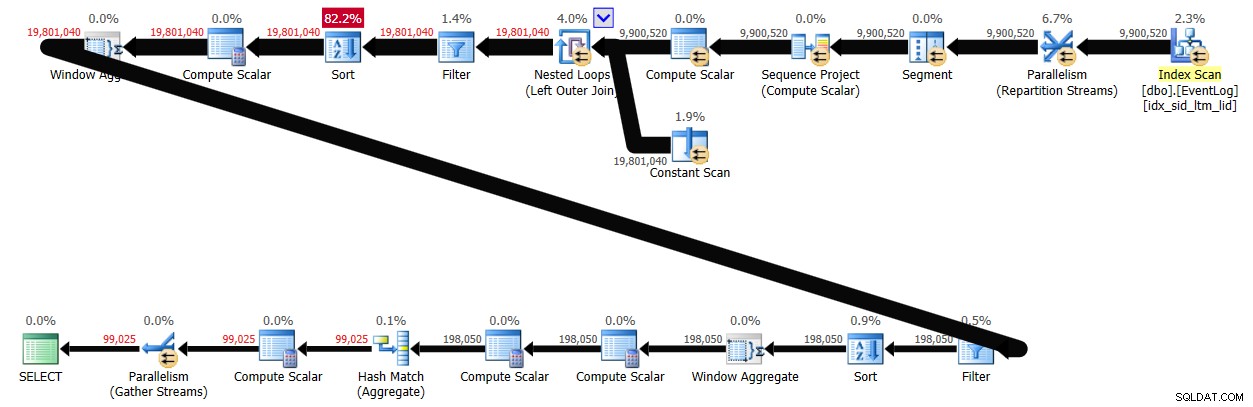
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; Diese Lösung dauerte auf meinem System 43 Sekunden und generierte den in Abbildung 3 gezeigten Plan.
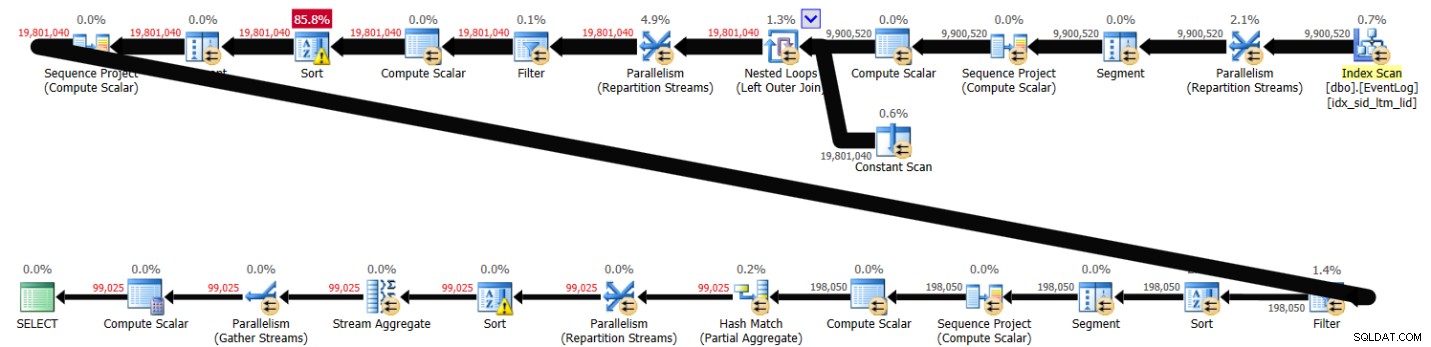 Abbildung 3:Plan für Lösung 2
Abbildung 3:Plan für Lösung 2
Wie Sie sehen können, wird die erste Zeilennummerberechnung basierend auf der Indexreihenfolge berechnet, aber die nächsten beiden beinhalten eine explizite Sortierung. Dennoch ist die Leistung nicht so schlecht, wenn man bedenkt, dass etwa 10.000.000 Zeilen beteiligt sind.
Obwohl es bei dieser Lösung darum geht, eine Umgebung vor SQL Server 2012 zu verwenden, habe ich ihre Leistung nur zum Spaß getestet, nachdem ich einen gefilterten Columnstore-Index erstellt hatte, um zu sehen, wie sie sich bei aktivierter Stapelverarbeitung verhält:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Bei aktivierter Stapelverarbeitung dauerte es 29 Sekunden, bis diese Lösung auf meinem System fertig war und den in Abbildung 4 gezeigten Plan erstellte.
Schlussfolgerung
Je begrenzter Ihre Umgebung ist, desto schwieriger wird es natürlich, Abfrageaufgaben zu lösen. Adams spezielle Inselherausforderung ist auf neueren Versionen von SQL Server viel einfacher zu lösen als auf älteren. Aber dann zwingst du dich, kreativere Techniken anzuwenden. Um Ihre Abfragefähigkeiten zu verbessern, könnten Sie also als Übung Herausforderungen angehen, mit denen Sie bereits vertraut sind, aber absichtlich bestimmte Einschränkungen auferlegen. Man weiß nie, auf welche interessanten Ideen man stoßen könnte!