Wir haben kürzlich eine neue Support-Website gestartet, auf der Sie Fragen stellen, Produkt-Feedback oder Funktionsanfragen senden oder Support-Tickets öffnen können. Ein Teil des Ziels war es, alle Orte zu zentralisieren, an denen wir der Gemeinschaft Hilfe anboten. Dazu gehörte die Q&A-Site SQLPerformance.com, auf der Paul White, Hugo Kornelis und viele andere geholfen haben, Ihre kompliziertesten Fragen zur Abfrageoptimierung und zum Ausführungsplan zu lösen, und zwar seit Februar 2013. Ich sage Ihnen mit gemischten Gefühlen, dass die Die Q&A-Site wurde geschlossen.
Es gibt jedoch einen Vorteil. Sie können diese schwierigen Fragen jetzt im neuen Support-Forum stellen. Wenn Sie nach den alten Inhalten suchen, nun, sie sind immer noch da, aber sie sehen ein wenig anders aus. Aus einer Vielzahl von Gründen, auf die ich heute nicht näher eingehen werde, entschieden wir uns, nachdem wir uns entschieden hatten, die ursprüngliche Q&A-Site einzustellen, letztendlich dafür, alle vorhandenen Inhalte einfach auf einer schreibgeschützten WordPress-Site zu hosten, anstatt sie in das Backend zu migrieren der neuen Website.
In diesem Beitrag geht es nicht um die Gründe für diese Entscheidung.
Ich fühlte mich wirklich schlecht darüber, wie schnell die Antworten-Site offline gehen, das DNS umgestellt und die Inhalte migriert werden mussten. Da auf der Seite ein Warnbanner implementiert war, der aber von AnswerHub nicht sichtbar gemacht wurde, war dies für viele Nutzer ein Schock. Also wollte ich sicherstellen, dass ich so viel Inhalt wie möglich richtig behalte, und ich wollte, dass es richtig ist. Dieser Beitrag ist hier, weil ich dachte, es wäre interessant, über den eigentlichen Prozess zu sprechen, wie viele verschiedene Technologien daran beteiligt waren, und das Ergebnis zu zeigen. Ich erwarte nicht, dass irgendjemand von Ihnen von diesem End-to-End profitieren wird, da dies ein relativ obskurer Migrationspfad ist, sondern eher als Beispiel für die Verknüpfung einer Reihe von Technologien, um eine Aufgabe zu erfüllen. Es dient auch als gute Erinnerung für mich selbst, dass viele Dinge am Ende nicht so einfach sind, wie es sich anhört, bevor Sie anfangen.
Die TL;DR ist dies:Ich habe viel Zeit und Mühe darauf verwendet, den archivierten Inhalt gut aussehen zu lassen, obwohl ich immer noch versuche, die letzten paar Posts wiederherzustellen, die gegen Ende eingegangen sind. Ich habe diese Technologien verwendet:
- Perl
- SQL-Server
- PowerShell
- Übertragen (FTP)
- HTML
- CSS
- C#
- MarkdownSharp
- phpMyAdmin
- MySQL
Daher der Titel. Wenn Sie einen großen Teil der blutigen Details wollen, hier sind sie. Wenn Sie Fragen oder Feedback haben, wenden Sie sich bitte an oder kommentieren Sie unten.
AnswerHub stellte eine 665 MB große Speicherauszugsdatei aus der MySQL-Datenbank bereit, in der die Q&A-Inhalte gehostet wurden. Jeder Editor, den ich ausprobierte, verschluckte sich daran, also musste ich es zuerst mit diesem praktischen Perl-Skript von Jared Cheney in eine Datei pro Tabelle aufteilen. Die Tabellen, die ich brauchte, hießen network11_nodes (Fragen, Antworten und Kommentare), network11_authoritables (Benutzer) und network11_managed_files (alle Anhänge, einschließlich Plan-Uploads):perl extract_sql.pl -t network11_nodes -r dump.sql>> nodes.sql
perl extract_sql.pl -t network11_authoritables -r dump.sql>> users.sql
perl extract_sql.pl -t network11_managed_files -r dump.sql>> files.sql
Nun waren diese in SSMS nicht extrem schnell zu laden, aber zumindest dort konnte ich Ctrl verwenden +H um (zum Beispiel) dies zu ändern:
CREATE TABLE `network11_managed_files` ( `c_id` bigint(20) NOT NULL, ... ); INSERT INTO `network11_managed_files` (`c_id`, ...) VALUES (1, ...);
Dazu:
CREATE TABLE dbo.files ( c_id bigint NOT NULL, ... ); INSERT dbo.files (c_id, ...) VALUES (1, ...);
Dann konnte ich die Daten in SQL Server laden, damit ich sie bearbeiten konnte. Und glauben Sie mir, ich habe es manipuliert.
Als nächstes musste ich alle Anhänge abrufen. Sehen Sie, die MySQL-Dump-Datei, die ich vom Anbieter erhalten habe, enthielt eine Unmenge von INSERT Anweisungen, aber keine der tatsächlichen Plandateien, die Benutzer hochgeladen hatten – die Datenbank hatte nur die relativen Pfade zu den Dateien. Ich habe T-SQL verwendet, um eine Reihe von PowerShell-Befehlen zu erstellen, die Invoke-WebRequest aufrufen würden um alle Dateien abzurufen und lokal zu speichern (viele Möglichkeiten, diese Katze zu häuten, aber das war kinderleicht). Daraus:
SELECT 'Invoke-WebRequest -Uri ' + '"$($url)' + RTRIM(c_id) + '-' + c_name + '"' + ' -OutFile "E:\s\temp\' + RTRIM(c_id) + '-' + c_name + '";' FROM dbo.files WHERE LOWER(c_mime_type) LIKE 'application/%';
Das ergab diesen Befehlssatz (zusammen mit einem Vorbefehl zur Behebung dieses TLS-Problems); Das Ganze lief ziemlich schnell, aber ich empfehle diesen Ansatz nicht für eine Kombination aus {massive Menge von Dateien} und/oder {niedriger Bandbreite}:
$AllProtocols = [System.Net.SecurityProtocolType]'Ssl3,Tls,Tls11,Tls12'; [System.Net.ServicePointManager]::SecurityProtocol = $AllProtocols; $u = "https://answers.sqlperformance.com/s/temp/"; Invoke-WebRequest -Uri "$($u)/1-proc.pesession" -OutFile "E:\s\temp\1-proc.pesession"; Invoke-WebRequest -Uri "$($u)/14-test.pesession" -OutFile "E:\s\temp\14-test.pesession"; Invoke-WebRequest -Uri "$($u)/15-a.QueryAnalysis" -OutFile "E:\s\temp\15-a.QueryAnalysis"; ...
Dadurch wurden fast alle Anhänge heruntergeladen, aber zugegebenermaßen wurden einige aufgrund von Fehlern auf der alten Website beim ersten Hochladen übersehen. Daher sehen Sie auf der neuen Website gelegentlich einen Verweis auf einen Anhang, der nicht vorhanden ist.
Dann habe ich Panic Transmit 5 verwendet, um den temp hochzuladen Ordner auf die neue Website, und jetzt, wenn der Inhalt hochgeladen wird, Links zu /s/temp/1-proc.pesession wird weiterhin funktionieren.
Als nächstes ging ich zu SSL über. Um ein Zertifikat auf der neuen WordPress-Site anzufordern, mussten wir den DNS für answers.sqlperformance.com aktualisieren, um auf den CNAME unseres WordPress-Hosts WPEngine zu verweisen. Es war hier eine Art Henne und Ei – wir mussten einige Ausfallzeiten für https-URLs hinnehmen, die ohne Zertifikat auf der neuen Website fehlschlagen würden. Das war in Ordnung, weil das Zertifikat auf der alten Seite abgelaufen war, also waren wir wirklich nicht schlechter dran. Außerdem musste ich damit warten, bis ich alle Dateien von der alten Seite heruntergeladen hatte, denn sobald das DNS umgedreht war, gab es keine Möglichkeit, an sie heranzukommen, außer durch eine Hintertür.
Während ich auf die Verbreitung von DNS wartete, begann ich an der Logik zu arbeiten, um alle Fragen, Antworten und Kommentare in etwas Verbrauchbares in WordPress zu packen. Nicht nur die Tabellenschemata waren anders als bei WordPress, auch die Arten von Entitäten sind ganz anders. Meine Vision war es, jede Frage – und alle Antworten und/oder Kommentare – in einem einzigen Beitrag zusammenzufassen.
Der knifflige Teil besteht darin, dass die nodes-Tabelle nur alle drei Inhaltstypen in derselben Tabelle enthält, mit übergeordneten und ursprünglichen („Master“) übergeordneten Referenzen. Ihr Front-End-Code verwendet wahrscheinlich eine Art Cursor, um den Inhalt in einer hierarchischen und chronologischen Reihenfolge durchzugehen und anzuzeigen. In WordPress hätte ich diesen Luxus nicht, also musste ich den HTML-Code in einem Rutsch aneinanderreihen. Nur als Beispiel sehen die Daten wie folgt aus:
SELECT c_type, c_id, c_parent, oParent = c_originalParent, c_creation_date, c_title FROM dbo.nodes WHERE c_originalParent = 285; /* c_type c_id c_parent oParent c_creation_date accepted c_title ---------- ------ -------- ------- ---------------- -------- ------------------------- question 285 NULL 285 2013-02-13 16:30 why is the MERGE JOIN ... answer 287 285 285 2013-02-14 01:15 1 NULL comment 289 285 285 2013-02-14 13:35 NULL answer 293 285 285 2013-02-14 18:22 NULL comment 294 287 285 2013-02-14 18:29 NULL comment 298 285 285 2013-02-14 20:40 NULL comment 299 298 285 2013-02-14 18:29 NULL */
Ich konnte nicht nach ID oder Typ oder nach Eltern sortieren, da manchmal ein Kommentar später zu einer früheren Antwort kam, die erste Antwort nicht immer die akzeptierte Antwort war und so weiter. Ich wollte diese Ausgabe (wobei ++ stellt eine Einzugsebene dar):
/* c_type c_id c_parent oParent c_creation_date reason ---------- ------ -------- ------- ---------------- ------------------------- question 285 NULL 285 2013-02-13 16:30 question is ALWAYS first ++comment 289 285 285 2013-02-14 13:35 comments on the question before answers answer 287 285 285 2013-02-14 01:15 first answer (accepted = 1) ++comment 294 287 285 2013-02-14 18:29 first comment on first answer ++comment 298 287 285 2013-02-14 20:40 second comment on first answer ++++comment 299 298 285 2013-02-14 18:29 reply to second comment on first answer answer 293 285 285 2013-02-14 18:22 second answer */
Ich fing an, einen rekursiven CTE zu schreiben und
DECLARE @foo TABLE
(
c_type varchar(255),
c_id int,
c_parent int,
oParent int,
accepted bit
);
INSERT @foo(c_type, c_id, c_parent, oParent, accepted) VALUES
('question', 285, NULL, 285, 0),
('answer', 287, 285 , 285, 1),
('comment', 289, 285 , 285, 0),
('comment', 294, 287 , 285, 0),
('comment', 298, 287 , 285, 0),
('comment', 299, 298 , 285, 0),
('answer', 293, 285 , 285, 0);
;WITH cte AS
(
SELECT
lvl = 0,
f.c_type,
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f WHERE f.c_parent IS NULL
UNION ALL
SELECT
lvl = c.lvl + 1,
c_type = CONVERT(varchar(255), CASE
WHEN f.accepted = 1 THEN 'accepted answer'
WHEN f.c_type = 'comment' THEN c.c_type + ' ' + f.c_type
ELSE f.c_type
END),
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),c.Sort + RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f INNER JOIN cte AS c ON c.c_id = f.c_parent
)
SELECT lvl = CASE lvl WHEN 0 THEN 1 ELSE lvl END, c_type, c_id, c_parent, oParent, Sort
FROM cte
ORDER BY
oParent,
CASE
WHEN c_type LIKE 'question%' THEN 1 -- it's a question *or* a comment on the question
WHEN c_type LIKE 'accepted answer%' THEN 2 -- accepted answer *or* comment on accepted answer
ELSE 3 END,
Sort; Ergebnisse:
/* lvl c_type c_id c_parent oParent Sort ---- --------------------------------- ----------- ----------- ----------- -------------------- 1 question 285 NULL 285 00285 1 question comment 289 285 285 0028500289 1 accepted answer 287 285 285 0028500287 2 accepted answer comment 294 287 285 002850028700294 2 accepted answer comment 298 287 285 002850028700298 3 accepted answer comment comment 299 298 285 00285002870029800299 1 answer 293 285 285 0028500293 */
Genius. Ich habe ungefähr ein Dutzend andere stichprobenartig überprüft und war froh, mit dem nächsten Schritt fortzufahren. Ich habe Andy mehrmals ausgiebig gedankt, aber lass es mich noch einmal tun:Danke Andy!
Jetzt, da ich den gesamten Satz in der gewünschten Reihenfolge zurückgeben konnte, musste ich einige Manipulationen an der Ausgabe vornehmen, um HTML-Elemente und Klassennamen anzuwenden, mit denen ich Fragen, Antworten, Kommentare und Einrückungen sinnvoll markieren konnte. Das Endziel war eine Ausgabe, die so aussah (und denken Sie daran, dies ist einer der einfacheren Fälle):
<div class="question">
<span class="authorq" title=" Author : author name ">
<i class="fas fa-user"></i>Author name</span>
<span class="createdq" title=" February 13th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-13 16:30:36</span>
<div class=mainbodyq>I don't understand why the merge operator is passing over 4million
rows to the hash match operator when there is only 41K and 19K from other operators.
<div class=attach><i class="fas fa-file"></i>
<a target="_blank" href="/s/temp/254-tmp4DA0.queryanalysis" rel="noopener noreferrer">
/s/temp/254-tmp4DA0.queryanalysis</a>
</div>
</div>
<div class="comment indent1 ">
<div class=linecomment>
<span class="authorc" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createdc" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 13:35:39</span>
</div>
<div class=mainbodyc>
I am still trying to understand the significant amount of rows from the MERGE operator.
Unless it's a result of a Cartesian product from the two inputs then finally the WHERE
predicate is applied to filter out the unmatched rows leaving the 4 million row count.
</div>
</div>
<div class="answer indent1 [accepted]">
<div class=lineanswer>
<span class="authora" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createda" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 01:15:42</span>
</div>
<div class=mainbodya>
The reason for the large number of rows can be seen in the Plan Explorer tool tip for
the Merge Join operator:
<img src="/s/temp/259-sp.png" alt="Merge Join tool tip" />
...
</div>
</div>
</div>
Ich werde nicht die lächerliche Anzahl von Iterationen durchgehen, die ich durchlaufen musste, um auf einer zuverlässigen Form dieser Ausgabe für alle über 5.000 Elemente zu landen (was fast 1.000 Posts bedeutet, sobald alles zusammengeklebt war). Darüber hinaus musste ich diese in Form von INSERT generieren Anweisungen, die ich dann in phpMyAdmin auf der WordPress-Seite einfügen konnte, was bedeutete, mich an ihr bizarres Syntaxdiagramm zu halten. Diese Aussagen mussten andere zusätzliche Informationen enthalten, die von WordPress benötigt werden, aber in den Quelldaten nicht vorhanden oder korrekt sind (wie post_type ). Und diese Verwaltungskonsole würde bei zu vielen Daten ablaufen, also musste ich sie in ~750 Einfügungen auf einmal aufteilen. Hier ist das Verfahren, mit dem ich endete (dies soll nicht wirklich etwas Besonderes lernen, sondern nur eine Demonstration dessen, wie viel Manipulation der importierten Daten erforderlich war):
CREATE /* OR ALTER */ PROCEDURE dbo.BuildMySQLInserts
@LowerBound int = 1,
@UpperBound int = 750
AS
BEGIN
SET NOCOUNT ON;
;WITH CTE AS
(
SELECT lvl = 0,
[type] = CONVERT(varchar(100),f.[type]),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
WHERE f.type = 'question'
AND master_parent BETWEEN @LowerBound AND @UpperBound
UNION ALL
SELECT lvl = c.lvl + 1,
CONVERT(varchar(100),CASE
WHEN f.[state] = '[accepted]' THEN 'accepted answer'
WHEN f.type = 'comment' THEN c.type + ' ' + f.type
ELSE f.type
END),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),c.sort + RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
JOIN CTE AS c ON c.id = f.parent
)
SELECT
master_parent,
prefix = CASE WHEN lvl = 0 THEN
CONVERT(varchar(11), master_parent) + ', 3, ''' + created + ''', '''
+ created + ''',''' END,
bodypre = '<div class="' + COALESCE(c_type, RTRIM(LEFT([type],8)))
+ CASE WHEN c_type <> 'question' THEN ' indent' + RTRIM(lvl)
+ COALESCE(' ' + [state], '') ELSE '' END + '">'
+ CASE WHEN c_type <> 'question' THEN
'<div class=line' + c_type + '>' ELSE '' END
+ '<span class="author' + LEFT(c_type, 1) + '" title=" Author : '
+ REPLACE(REPLACE(Fullname,'''','\'''),'"','')
+ ' "><i class="fas fa-user"></i>' + REPLACE(Fullname,'''','\''') --"
+ '</span> <span class="created' + LEFT(c_type,1) + '" title=" '
+ DATENAME(MONTH, c_creation_date) + ' ' + RTRIM(DAY(c_creation_date))
+ CASE
WHEN DAY(c_creation_date) IN (1,21,31) THEN 'st'
WHEN DAY(c_creation_date) IN (2,22) THEN 'nd'
WHEN DAY(c_creation_date) IN (3,23) THEN 'rd' ELSE 'th' END
+ ', ' + RTRIM(YEAR(c_creation_date))
+ ' "><i class="fas fa-calendar-alt"></i>' + created + '</span>'
+ CASE WHEN c_type <> 'question' THEN '</div>' ELSE '' END,
body = '<div class=mainbody' + left(c_type,1) + '>'
+ REPLACE(REPLACE(c_body, char(39), '\' + char(39)), '’', '\' + char(39)),
bodypost = COALESCE(urls, '') + '</div></div>',--'
+ CASE WHEN c_type = 'question' THEN '</div>' ELSE '' END,
suffix = ''',''' + REPLACE(n.c_title, '''', '\''') + ''','''',''publish'',
''closed'',''closed'','''',''' + REPLACE(n.c_plug, '''', '\''')
+ ''','''','''',''' + created + ''',''' + created + ''','''',0,
''https://answers.sqlperformance.com/?p=' + CONVERT(varchar(11), master_parent)
+ ''', 0, ''post'','''',0);',
rn = RTRIM(ROW_NUMBER() OVER (PARTITION BY master_parent
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort)),
c = RTRIM(COUNT(*) OVER (PARTITION BY master_parent))
FROM CTE
LEFT OUTER JOIN dbo.network11_nodes AS n
ON cte.id = n.c_id
LEFT OUTER JOIN dbo.Users AS u
ON n.c_author = u.UserID
LEFT OUTER JOIN
(
SELECT NodeID, urls = STRING_AGG('<div class=attach>
<i class="fas fa-file'
+ CASE WHEN c_mime_type IN ('image/jpeg','image/png')
THEN '-image' ELSE '' END
+ '"></i><a target="_blank" href=' + url + ' rel="noopener noreferrer">' + url + '</a></div>', '\n')
FROM dbo.Attachments
GROUP BY NodeID
) AS a
ON n.c_id = a.NodeID
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort;
END
GO Die Ausgabe davon ist noch nicht vollständig und kann noch nicht in WordPress eingefügt werden:
 Beispielausgabe (zum Vergrößern klicken)
Beispielausgabe (zum Vergrößern klicken)
Ich bräuchte zusätzliche Hilfe von C#, um den eigentlichen Inhalt (einschließlich Markdown) in HTML und CSS umzuwandeln, die ich besser kontrollieren könnte, und die Ausgabe zu schreiben (eine Reihe von INSERT Anweisungen, die zufällig eine Menge HTML-Code enthielten) in Dateien auf der Festplatte, die ich öffnen und in phpMyAdmin einfügen konnte. Für den HTML-Code, einfacher Text + Markdown, der so begann:
WÄHLEN Sie etwas aus dbo.sometable;
[1]:https://an anderer Stelle
Müsste das werden:
Es gibt einen Blogbeitrag hier , der darüber spricht, und auch diesen Beitrag .
WÄHLEN Sie etwas aus dbo.sometable; Um dies zu erreichen, habe ich die Hilfe von MarkdownSharp in Anspruch genommen, einer Open-Source-Bibliothek, die ihren Ursprung bei Stack Overflow hat und einen Großteil der Markdown-zu-HTML-Konvertierung übernimmt. Es war eine gute Passform für meine Bedürfnisse, aber nicht perfekt; Ich müsste noch weitere Manipulationen vornehmen:
- MarkdownSharp lässt Dinge wie
target=_blanknicht zu , also müsste ich diese nach der Verarbeitung selbst injizieren; - Code (alles mit vier Leerzeichen als Präfix) erbt
using System.Text; using System.Data; using System.Data.SqlClient; using MarkdownSharp; using System.IO; namespace AnswerHubMigrator { class Program { static void Main(string[] args) { StringBuilder output; string suffix = ""; string thisfile = ""; // pass two arguments on the command line, e.g. 1, 750 int LowerBound = int.Parse(args[0]); int UpperBound = int.Parse(args[1]); // auto-expand URLs, and only accept bold/italic markdown // when it completely surrounds an entire word var options = new MarkdownOptions { AutoHyperlink = true, StrictBoldItalic = true }; MarkdownSharp.Markdown mark = new MarkdownSharp.Markdown(options); using (var conn = new SqlConnection("Server=.\\SQL2017;Integrated Security=true")) using (var cmd = new SqlCommand("MigrateDB.dbo.BuildMySQLInserts", conn)) { cmd.CommandType = CommandType.StoredProcedure; cmd.Parameters.Add("@LowerBound", SqlDbType.Int).Value = LowerBound; cmd.Parameters.Add("@UpperBound", SqlDbType.Int).Value = UpperBound; conn.Open(); using (var reader = cmd.ExecuteReader()) { // use a StringBuilder to dump output to a file output = new StringBuilder(); while (reader.Read()) { // on first pass, make a new delete/insert // delete is to make the commands idempotent if (reader["rn"].Equals("1")) { // for each master parent, I would create a // new WordPress post, inheriting the parent ID output.Append("DELETE FROM `wp_posts` WHERE ID = "); output.Append(reader["master_parent"].ToString()); output.Append("; INSERT INTO `wp_posts` (`ID`, `post_author`, "); output.Append("`post_date`, `post_date_gmt`, `post_content`, "); output.Append("`post_title`, `post_excerpt`, `post_status`, "); output.Append("`comment_status`, `ping_status`, `post_password`,"); output.Append(" `post_name`, `to_ping`, `pinged`, `post_modified`,"); output.Append(" `post_modified_gmt`, `post_content_filtered`, "); output.Append("`post_parent`, `guid`, `menu_order`, `post_type`, "); output.Append("`post_mime_type`, `comment_count`) VALUES ("); // I'm sure some of the above columns are optional, but identifying // those would not be a valuable use of time IMHO output.Append(reader["prefix"]); // hold on to the additional values until last row suffix = reader["suffix"].ToString(); } // manipulate the body content to be WordPress and INSERT statement-friendly string body = reader["body"].ToString().Replace(@"\n", "\n"); body = mark.Transform(body).Replace("href=", "target=_blank href="); body = body.Replace("<p>", "").Replace("</p>", ""); body = body.Replace("<pre><code>", "<pre lang=\"tsql\">"); body = body.Replace("</code></"+"pre>", "</"+"pre>"); body = body.Replace(@"'", "\'").Replace(@"’", "\'"); body = reader["bodypre"].ToString() + body.Replace("\n", @"\n"); body += reader["bodypost"].ToString(); body = body.Replace("<", "<").Replace(">", ">"); output.Append(body); // if we are on the last row, add additional values from the first row if (reader["c"].Equals(reader["rn"])) { output.Append(suffix); } } thisfile = UpperBound.ToString(); using (StreamWriter w = new StreamWriter(@"C:\wp\" + thisfile + ".sql")) { w.WriteLine(output); w.Flush(); } } } } } }Ja, das ist ein hässlicher Haufen Code, aber es brachte mich schließlich zu der Menge an Ausgaben, die phpMyAdmin nicht zum Kotzen bringen würden, und die WordPress gut (genug) darstellen würde. Ich habe das C#-Programm einfach mehrfach mit den unterschiedlichen Parameterbereichen aufgerufen:
AnswerHubMigrator 1 750 AnswerHubMigrator 751 1500 AnswerHubMigrator 1501 2250 ...
Dann öffnete ich jede der Dateien, fügte sie in phpMyAdmin ein und drückte GO:
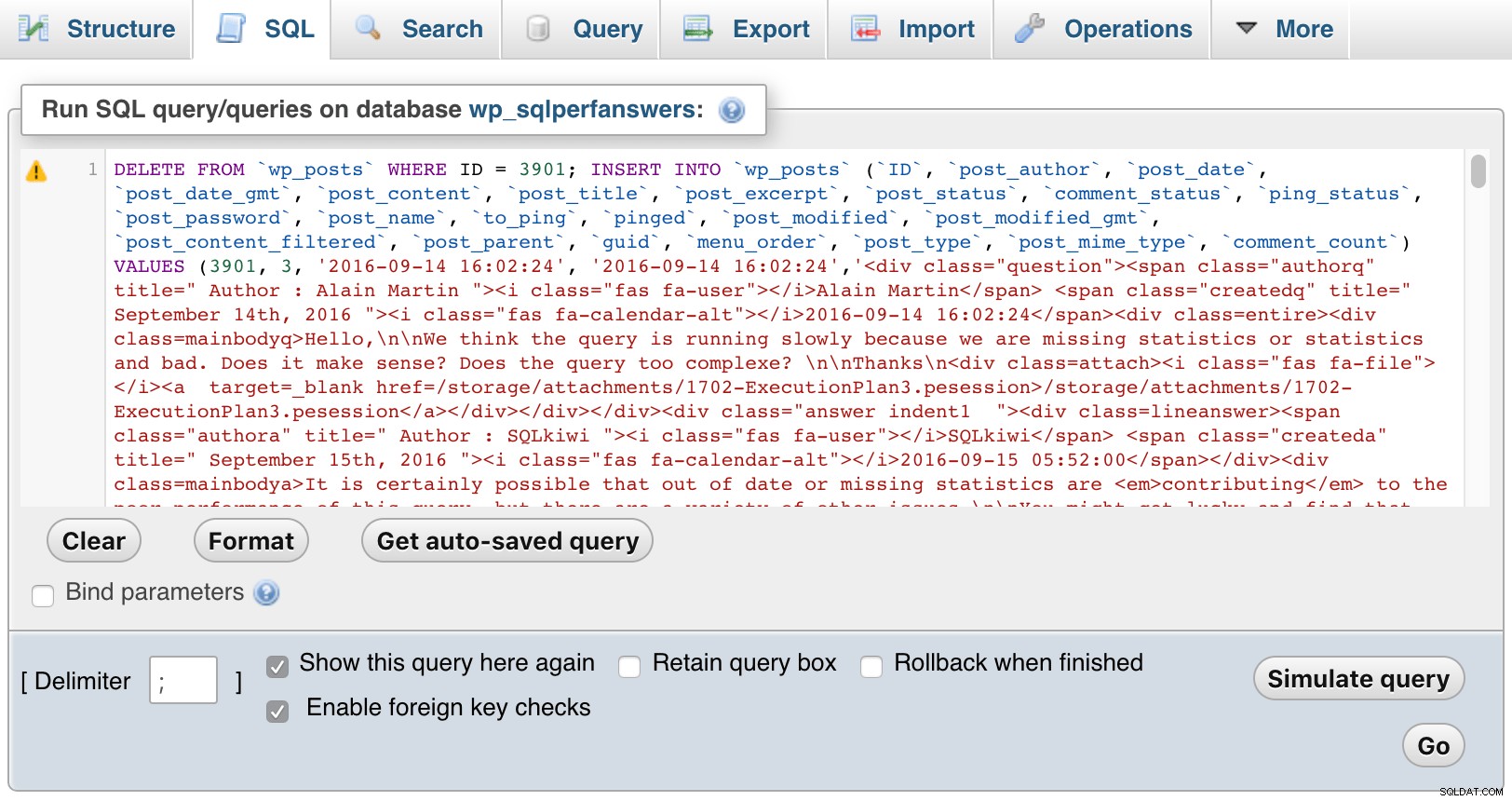 phpMyAdmin (zum Vergrößern klicken)
phpMyAdmin (zum Vergrößern klicken) Natürlich musste ich etwas CSS in WordPress hinzufügen, um die Unterscheidung zwischen Fragen, Kommentaren und Antworten zu erleichtern, und um auch Kommentare einzurücken, um Antworten auf Fragen und Antworten anzuzeigen, Kommentare zu verschachteln, die auf Kommentare antworten, und so weiter. So sieht ein Auszug aus, wenn Sie zu den Fragen eines Monats vordringen:
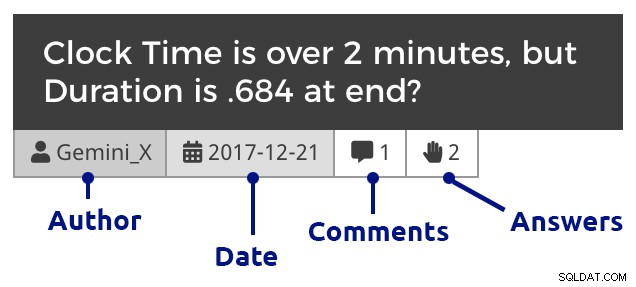 Fragekachel (zum Vergrößern klicken)
Fragekachel (zum Vergrößern klicken) Und dann ein Beispielbeitrag, der eingebettete Bilder, mehrere Anhänge, verschachtelte Kommentare und eine Antwort zeigt:
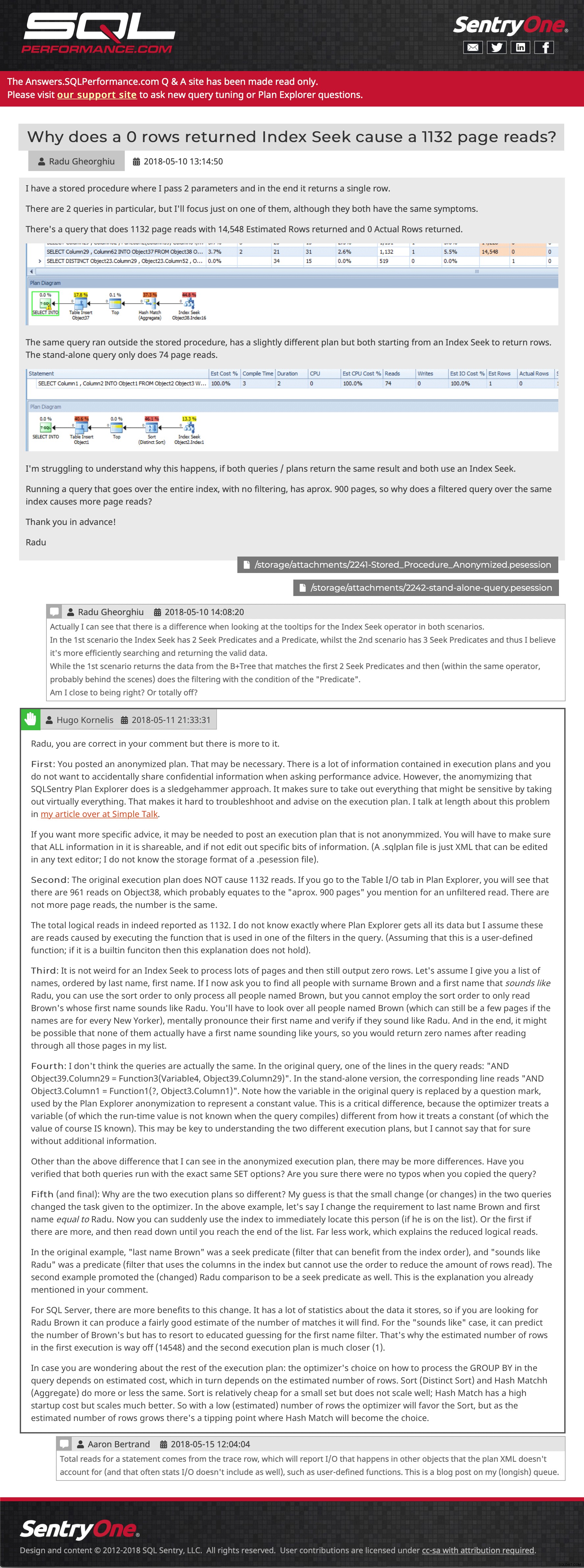 Beispielfrage und -antwort (klicken, um dorthin zu gelangen)
Beispielfrage und -antwort (klicken, um dorthin zu gelangen) Ich versuche immer noch, einige Posts wiederherzustellen, die nach der letzten Sicherung an die Website gesendet wurden, aber ich freue mich, wenn Sie sich umsehen. Bitte teilen Sie uns mit, wenn Ihnen etwas fehlt oder fehl am Platz ist, oder teilen Sie uns einfach mit, dass der Inhalt für Sie noch nützlich ist. Wir hoffen, die Plan-Upload-Funktion innerhalb des Plan-Explorers wieder einführen zu können, aber es wird einige API-Arbeiten auf der neuen Support-Website erfordern, daher habe ich heute keine ETA für Sie.
- Answers.SQLPerformance.com



