Letztes Jahr habe ich einen Tipp namens Improve SQL Server Efficiency by Switching to INSTEAD OF Triggers gepostet.
Der Hauptgrund, warum ich dazu neige, einen INSTEAD OF-Trigger zu bevorzugen, insbesondere in Fällen, in denen ich viele Verletzungen der Geschäftslogik erwarte, ist, dass es intuitiv erscheint, dass es billiger wäre, eine Aktion insgesamt zu verhindern, als fortzufahren und sie auszuführen (und protokollieren!), nur um einen AFTER-Trigger zu verwenden, um die anstößigen Zeilen zu löschen (oder den gesamten Vorgang rückgängig zu machen). Die in diesem Tipp gezeigten Ergebnisse zeigten, dass dies tatsächlich der Fall war – und ich vermute, dass sie noch ausgeprägter wären, wenn mehr nicht gruppierte Indizes von der Operation betroffen wären.
Das war jedoch auf einer langsamen Festplatte und auf einem frühen CTP von SQL Server 2014. Bei der Vorbereitung einer Folie für eine neue Präsentation, die ich dieses Jahr über Trigger machen werde, fand ich das auf einem neueren Build von SQL Server 2014 – kombiniert mit aktualisierter Hardware – es war etwas schwieriger, das gleiche Leistungsdelta zwischen einem AFTER- und INSTEAD OF-Trigger zu demonstrieren. Also machte ich mich auf die Suche nach dem Grund, obwohl mir sofort klar war, dass dies mehr Arbeit bedeuten würde, als ich je für eine einzelne Folie aufgewendet hätte.
Eine Sache, die ich erwähnen möchte, ist, dass Trigger tempdb verwenden können auf unterschiedliche Weise, und dies könnte einige dieser Unterschiede erklären. Ein AFTER-Trigger verwendet den Versionsspeicher für die eingefügten und gelöschten Pseudotabellen, während ein INSTEAD OF-Trigger eine Kopie dieser Daten in einer internen Arbeitstabelle erstellt. Der Unterschied ist subtil, aber erwähnenswert.
Die Variablen
Ich werde verschiedene Szenarien testen, darunter:
- Drei verschiedene Auslöser:
- Ein AFTER-Trigger, der bestimmte fehlgeschlagene Zeilen löscht
- Ein AFTER-Trigger, der die gesamte Transaktion zurücksetzt, wenn eine Zeile fehlschlägt
- Ein INSTEAD OF-Trigger, der nur die Zeilen einfügt, die bestehen
- Verschiedene Wiederherstellungsmodelle und Snapshot-Isolationseinstellungen:
- VOLLSTÄNDIG mit aktiviertem SNAPSHOT
- VOLLSTÄNDIG mit deaktiviertem SNAPSHOT
- EINFACH mit aktiviertem SNAPSHOT
- EINFACH mit deaktiviertem SNAPSHOT
- Unterschiedliche Festplattenlayouts*:
- Daten auf SSD, Anmeldung auf 7200 RPM HDD
- Daten auf SSD, Anmeldung auf SSD
- Daten auf HDD mit 7200 U/min, Protokoll auf SSD
- Daten auf HDD mit 7200 U/min, Protokoll auf HDD mit 7200 U/min
- Unterschiedliche Ausfallraten:
- 10 %, 25 % und 50 % Ausfallrate über:
- Einzelstapeleinfügung von 20.000 Zeilen
- 10 Batches mit 2.000 Zeilen
- 100 Batches mit 200 Zeilen
- 1.000 Batches mit 20 Zeilen
- 20.000 Singleton-Einfügungen
*
tempdbist eine einzelne Datendatei auf einer langsamen Festplatte mit 7200 U/min. Dies ist beabsichtigt und soll alle Engpässe verstärken, die durch die verschiedenen Verwendungen vontempdbverursacht werden . Ich plane, diesen Test zu einem späteren Zeitpunkt erneut zu besuchen, wenntempdbbefindet sich auf einer schnelleren SSD. - 10 %, 25 % und 50 % Ausfallrate über:
Okay, TL;DR schon!
Wenn Sie nur die Ergebnisse wissen möchten, springen Sie nach unten. Alles in der Mitte ist nur Hintergrund und eine Erklärung, wie ich die Tests eingerichtet und durchgeführt habe. Ich bin nicht untröstlich, dass nicht jeder an allen Einzelheiten interessiert sein wird.
Das Szenario
Für diese spezielle Reihe von Tests ist das reale Szenario eines, in dem ein Benutzer einen Bildschirmnamen auswählt und der Auslöser darauf ausgelegt ist, Fälle zu erfassen, in denen der gewählte Name gegen einige Regeln verstößt. Zum Beispiel kann es keine Variation von "Ninny-Muggins" sein (hier können Sie sicherlich Ihrer Fantasie freien Lauf lassen).
Ich habe eine Tabelle mit 20.000 eindeutigen Benutzernamen erstellt:
USE model; GO -- 20,000 distinct, good Names ;WITH distinct_Names AS ( SELECT Name FROM sys.all_columns UNION SELECT Name FROM sys.all_objects ) SELECT TOP (20000) Name INTO dbo.GoodNamesSource FROM ( SELECT Name FROM distinct_Names UNION SELECT Name + 'x' FROM distinct_Names UNION SELECT Name + 'y' FROM distinct_Names UNION SELECT Name + 'z' FROM distinct_Names ) AS x; CREATE UNIQUE CLUSTERED INDEX x ON dbo.GoodNamesSource(Name);
Dann habe ich eine Tabelle erstellt, die die Quelle für meine "unanständigen Namen" zum Vergleichen sein würde. In diesem Fall ist es nur ninny-muggins-00001 durch ninny-muggins-10000 :
USE model;
GO
CREATE TABLE dbo.NaughtyUserNames
(
Name NVARCHAR(255) PRIMARY KEY
);
GO
-- 10,000 "bad" names
INSERT dbo.NaughtyUserNames(Name)
SELECT N'ninny-muggins-' + RIGHT(N'0000' + RTRIM(n),5)
FROM
(
SELECT TOP (10000) n = ROW_NUMBER() OVER (ORDER BY Name)
FROM dbo.GoodNamesSource
) AS x;
Ich habe diese Tabellen im model erstellt Datenbank, sodass sie jedes Mal, wenn ich eine Datenbank erstelle, lokal vorhanden ist, und ich plane, viele Datenbanken zu erstellen, um die oben aufgeführte Szenariomatrix zu testen (anstatt nur die Datenbankeinstellungen zu ändern, das Protokoll zu löschen usw.). Bitte beachten Sie, wenn Sie Objekte zu Testzwecken im Modell erstellen, stellen Sie sicher, dass Sie diese Objekte löschen, wenn Sie fertig sind.
Abgesehen davon werde ich Schlüsselverletzungen und andere Fehlerbehandlungen absichtlich auslassen, indem ich die naive Annahme mache, dass der gewählte Name auf Eindeutigkeit geprüft wird, lange bevor die Einfügung jemals versucht wird, aber innerhalb derselben Transaktion (genau wie die Prüfung gegen die ungezogene Namenstabelle hätte im Voraus erfolgen können).
Um dies zu unterstützen, habe ich auch die folgenden drei nahezu identischen Tabellen in model erstellt , für Testisolationszwecke:
USE model; GO -- AFTER (rollback) CREATE TABLE dbo.UserNames_After_Rollback ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Rollback(DateCreated) INCLUDE(Name); -- AFTER (delete) CREATE TABLE dbo.UserNames_After_Delete ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_After_Delete(DateCreated) INCLUDE(Name); -- INSTEAD CREATE TABLE dbo.UserNames_Instead ( UserID INT IDENTITY(1,1) PRIMARY KEY, Name NVARCHAR(255) NOT NULL UNIQUE, DateCreated DATE NOT NULL DEFAULT SYSDATETIME() ); CREATE INDEX x ON dbo.UserNames_Instead(DateCreated) INCLUDE(Name); GO
Und die folgenden drei Trigger, einen für jede Tabelle:
USE model;
GO
-- AFTER (rollback)
CREATE TRIGGER dbo.trUserNames_After_Rollback
ON dbo.UserNames_After_Rollback
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
IF EXISTS
(
SELECT 1 FROM inserted AS i
WHERE EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
)
)
BEGIN
ROLLBACK TRANSACTION;
END
END
GO
-- AFTER (delete)
CREATE TRIGGER dbo.trUserNames_After_Delete
ON dbo.UserNames_After_Delete
AFTER INSERT
AS
BEGIN
SET NOCOUNT ON;
DELETE d
FROM inserted AS i
INNER JOIN dbo.NaughtyUserNames AS n
ON i.Name = n.Name
INNER JOIN dbo.UserNames_After_Delete AS d
ON i.UserID = d.UserID;
END
GO
-- INSTEAD
CREATE TRIGGER dbo.trUserNames_Instead
ON dbo.UserNames_Instead
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserNames_Instead(Name)
SELECT i.Name
FROM inserted AS i
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.NaughtyUserNames
WHERE Name = i.Name
);
END
GO Wahrscheinlich möchten Sie eine zusätzliche Behandlung in Betracht ziehen, um den Benutzer darüber zu informieren, dass seine Auswahl rückgängig gemacht oder ignoriert wurde – aber auch dies wird der Einfachheit halber weggelassen.
Der Testaufbau
Ich habe Beispieldaten erstellt, die die drei Fehlerraten darstellen, die ich testen wollte, indem ich 10 Prozent auf 25 und dann 50 geändert habe und diese Tabellen auch zu model hinzugefügt habe :
USE model;
GO
DECLARE @pct INT = 10, @cap INT = 20000;
-- change this ----^^ to 25 and 50
DECLARE @good INT = @cap - (@cap*(@pct/100.0));
SELECT Name, rn = ROW_NUMBER() OVER (ORDER BY NEWID())
INTO dbo.Source10Percent FROM
-- change this ^^ to 25 and 50
(
SELECT Name FROM
(
SELECT TOP (@good) Name FROM dbo.GoodNamesSource ORDER BY NEWID()
) AS g
UNION ALL
SELECT Name FROM
(
SELECT TOP (@cap-@good) Name FROM dbo.NaughtyUserNames ORDER BY NEWID()
) AS b
) AS x;
CREATE UNIQUE CLUSTERED INDEX x ON dbo.Source10Percent(rn);
-- and here as well -------------------------^^ Jede Tabelle hat 20.000 Zeilen mit einer anderen Mischung aus Namen, die bestehen und durchfallen, und die Spalte mit den Zeilennummern erleichtert die Aufteilung der Daten in verschiedene Stapelgrößen für verschiedene Tests, jedoch mit wiederholbaren Fehlerraten für alle Tests.
Natürlich brauchen wir einen Ort, um die Ergebnisse festzuhalten. Ich habe mich dafür entschieden, eine separate Datenbank dafür zu verwenden, jeden Test mehrmals auszuführen und einfach die Dauer zu erfassen.
CREATE DATABASE ControlDB; GO USE ControlDB; GO CREATE TABLE dbo.Tests ( TestID INT, DiskLayout VARCHAR(15), RecoveryModel VARCHAR(6), TriggerType VARCHAR(14), [snapshot] VARCHAR(3), FailureRate INT, [sql] NVARCHAR(MAX) ); CREATE TABLE dbo.TestResults ( TestID INT, BatchDescription VARCHAR(15), Duration INT );
Ich habe die dbo.Tests gefüllt Tabelle mit dem folgenden Skript, sodass ich verschiedene Teile ausführen konnte, um die vier Datenbanken so einzurichten, dass sie mit den aktuellen Testparametern übereinstimmen. Beachten Sie, dass D:\ eine SSD ist, während G:\ eine Festplatte mit 7200 U/min ist:
TRUNCATE TABLE dbo.Tests;
TRUNCATE TABLE dbo.TestResults;
;WITH d AS
(
SELECT DiskLayout FROM (VALUES
('DataSSD_LogHDD'),
('DataSSD_LogSSD'),
('DataHDD_LogHDD'),
('DataHDD_LogSSD')) AS d(DiskLayout)
),
t AS
(
SELECT TriggerType FROM (VALUES
('After_Delete'),
('After_Rollback'),
('Instead')) AS t(TriggerType)
),
m AS
(
SELECT RecoveryModel = 'FULL'
UNION ALL SELECT 'SIMPLE'
),
s AS
(
SELECT IsSnapshot = 0
UNION ALL SELECT 1
),
p AS
(
SELECT FailureRate = 10
UNION ALL SELECT 25
UNION ALL SELECT 50
)
INSERT ControlDB.dbo.Tests
(
TestID,
DiskLayout,
RecoveryModel,
TriggerType,
IsSnapshot,
FailureRate,
Command
)
SELECT
TestID = ROW_NUMBER() OVER
(
ORDER BY d.DiskLayout, t.TriggerType, m.RecoveryModel, s.IsSnapshot, p.FailureRate
),
d.DiskLayout,
m.RecoveryModel,
t.TriggerType,
s.IsSnapshot,
p.FailureRate,
[sql]= N'SET NOCOUNT ON;
CREATE DATABASE ' + QUOTENAME(d.DiskLayout)
+ N' ON (name = N''data'', filename = N''' + CASE d.DiskLayout
WHEN 'DataSSD_LogHDD' THEN N'D:\data\data1.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data1.ldf'');'
WHEN 'DataSSD_LogSSD' THEN N'D:\data\data2.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data2.ldf'');'
WHEN 'DataHDD_LogHDD' THEN N'G:\data\data3.mdf'')
LOG ON (name = N''log'', filename = N''G:\log\data3.ldf'');'
WHEN 'DataHDD_LogSSD' THEN N'G:\data\data4.mdf'')
LOG ON (name = N''log'', filename = N''D:\log\data4.ldf'');' END
+ '
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET RECOVERY ' + m.RecoveryModel + ';'';'
+ CASE WHEN s.IsSnapshot = 1 THEN
'
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET ALLOW_SNAPSHOT_ISOLATION ON;'';
EXEC sp_executesql N''ALTER DATABASE ' + QUOTENAME(d.DiskLayout)
+ ' SET READ_COMMITTED_SNAPSHOT ON;'';'
ELSE '' END
+ '
DECLARE @d DATETIME2(7), @i INT, @LoopID INT, @loops INT, @perloop INT;
DECLARE c CURSOR LOCAL FAST_FORWARD FOR
SELECT LoopID, loops, perloop FROM dbo.Loops;
OPEN c;
FETCH c INTO @LoopID, @loops, @perloop;
WHILE @@FETCH_STATUS <> -1
BEGIN
EXEC sp_executesql N''TRUNCATE TABLE '
+ QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + ';'';
SELECT @d = SYSDATETIME(), @i = 1;
WHILE @i <= @loops
BEGIN
BEGIN TRY
INSERT ' + QUOTENAME(d.DiskLayout) + '.dbo.UserNames_' + t.TriggerType + '(Name)
SELECT Name FROM ' + QUOTENAME(d.DiskLayout) + '.dbo.Source' + RTRIM(p.FailureRate) + 'Percent
WHERE rn > (@i-1)*@perloop AND rn <= @i*@perloop;
END TRY
BEGIN CATCH
SET @TestID = @TestID;
END CATCH
SET @i += 1;
END
INSERT ControlDB.dbo.TestResults(TestID, LoopID, Duration)
SELECT @TestID, @LoopID, DATEDIFF(MILLISECOND, @d, SYSDATETIME());
FETCH c INTO @LoopID, @loops, @perloop;
END
CLOSE c;
DEALLOCATE c;
DROP DATABASE ' + QUOTENAME(d.DiskLayout) + ';'
FROM d, t, m, s, p; -- implicit CROSS JOIN! Do as I say, not as I do! :-) Dann war es einfach, alle Tests mehrmals auszuführen:
USE ControlDB;
GO
SET NOCOUNT ON;
DECLARE @TestID INT, @Command NVARCHAR(MAX), @msg VARCHAR(32);
DECLARE d CURSOR LOCAL FAST_FORWARD FOR
SELECT TestID, Command
FROM ControlDB.dbo.Tests ORDER BY TestID;
OPEN d;
FETCH d INTO @TestID, @Command;
WHILE @@FETCH_STATUS <> -1
BEGIN
SET @msg = 'Starting ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
EXEC sp_executesql @Command, N'@TestID INT', @TestID;
SET @msg = 'Finished ' + RTRIM(@TestID);
RAISERROR(@msg, 0, 1) WITH NOWAIT;
FETCH d INTO @TestID, @Command;
END
CLOSE d;
DEALLOCATE d;
GO 10
Auf meinem System dauerte dies fast 6 Stunden, seien Sie also darauf vorbereitet, dies ununterbrochen ablaufen zu lassen. Stellen Sie außerdem sicher, dass keine aktiven Verbindungen oder Abfragefenster für das model geöffnet sind Datenbank, andernfalls erhalten Sie möglicherweise diesen Fehler, wenn das Skript versucht, eine Datenbank zu erstellen:
Exklusive Sperre für Datenbank „Modell“ konnte nicht erlangt werden. Wiederholen Sie den Vorgang später.
Ergebnisse
Es gibt viele Datenpunkte, die betrachtet werden müssen (und auf alle Abfragen, die zum Ableiten der Daten verwendet wurden, wird im Anhang verwiesen). Denken Sie daran, dass jede hier angegebene durchschnittliche Dauer über 10 Tests liegt und insgesamt 100.000 Zeilen in die Zieltabelle einfügt.
Grafik 1 – Gesamtaggregate
Das erste Diagramm zeigt Gesamtaggregate (durchschnittliche Dauer) für die verschiedenen Variablen isoliert (also *alle* Tests mit einem AFTER-Trigger, der löscht, *alle* Tests mit einem AFTER-Trigger, der zurückgesetzt wird usw.).
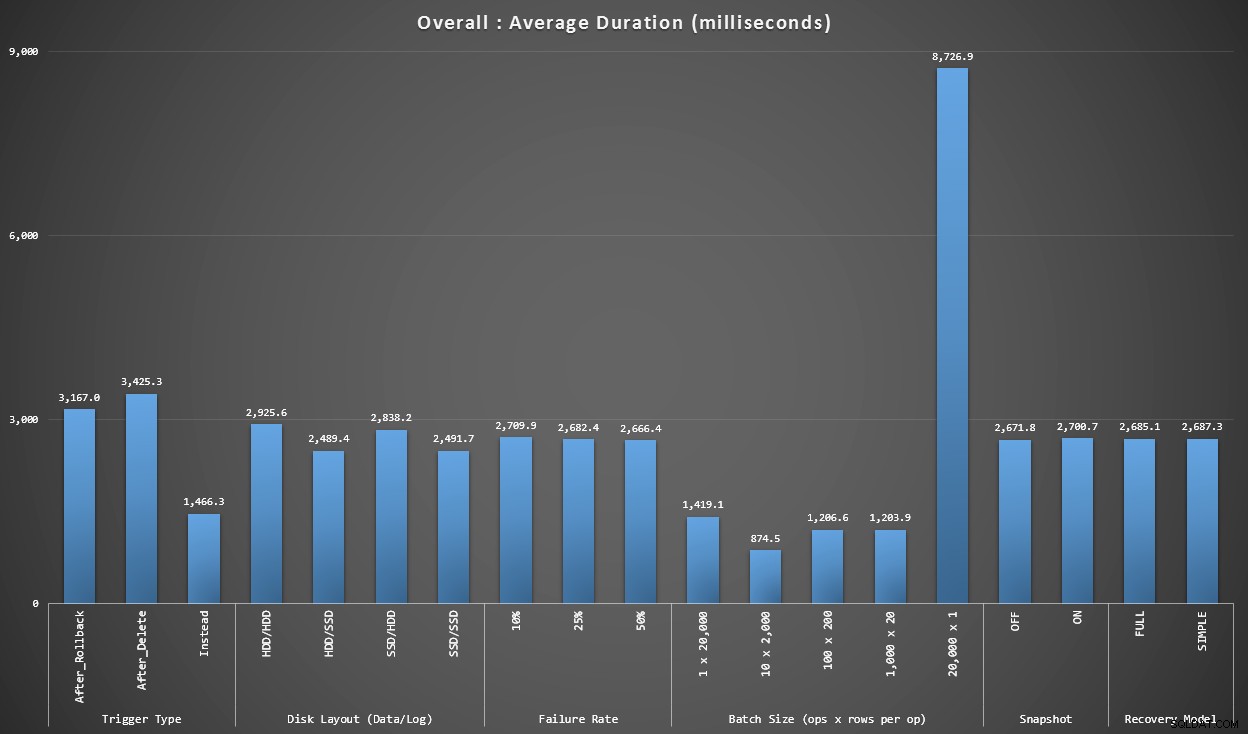
Durchschnittliche Dauer in Millisekunden für jede einzelne Variable
Ein paar Dinge springen uns sofort ins Auge:
- Der INSTEAD OF-Trigger ist hier doppelt so schnell wie die beiden AFTER-Trigger.
- Das Transaktionsprotokoll auf SSD zu haben, machte einen kleinen Unterschied. Speicherort der Datendatei viel weniger.
- Der Stapel von 20.000 Einzelbeilagen war 7- bis 8-mal langsamer als jede andere Stapelverteilung.
- Das einzelne Stapeleinfügen von 20.000 Zeilen war langsamer als jede der Nicht-Singleton-Verteilungen.
- Fehlerrate, Snapshot-Isolation und Wiederherstellungsmodell hatten wenig oder gar keine Auswirkungen auf die Leistung.
Grafik 2 – Beste 10 insgesamt
Dieses Diagramm zeigt die 10 schnellsten Ergebnisse, wenn alle Variablen berücksichtigt werden. Dies sind alles INSTEAD OF-Trigger, bei denen der größte Prozentsatz der Zeilen fehlschlägt (50 %). Überraschenderweise hatte der schnellste (wenn auch nicht viel) sowohl Daten als auch Protokoll auf derselben Festplatte (nicht SSD). Hier gibt es eine Mischung aus Festplattenlayouts und Wiederherstellungsmodellen, aber bei allen 10 war die Snapshot-Isolation aktiviert, und die besten 7 Ergebnisse betrafen alle die Stapelgröße von 10 x 2.000 Zeilen.
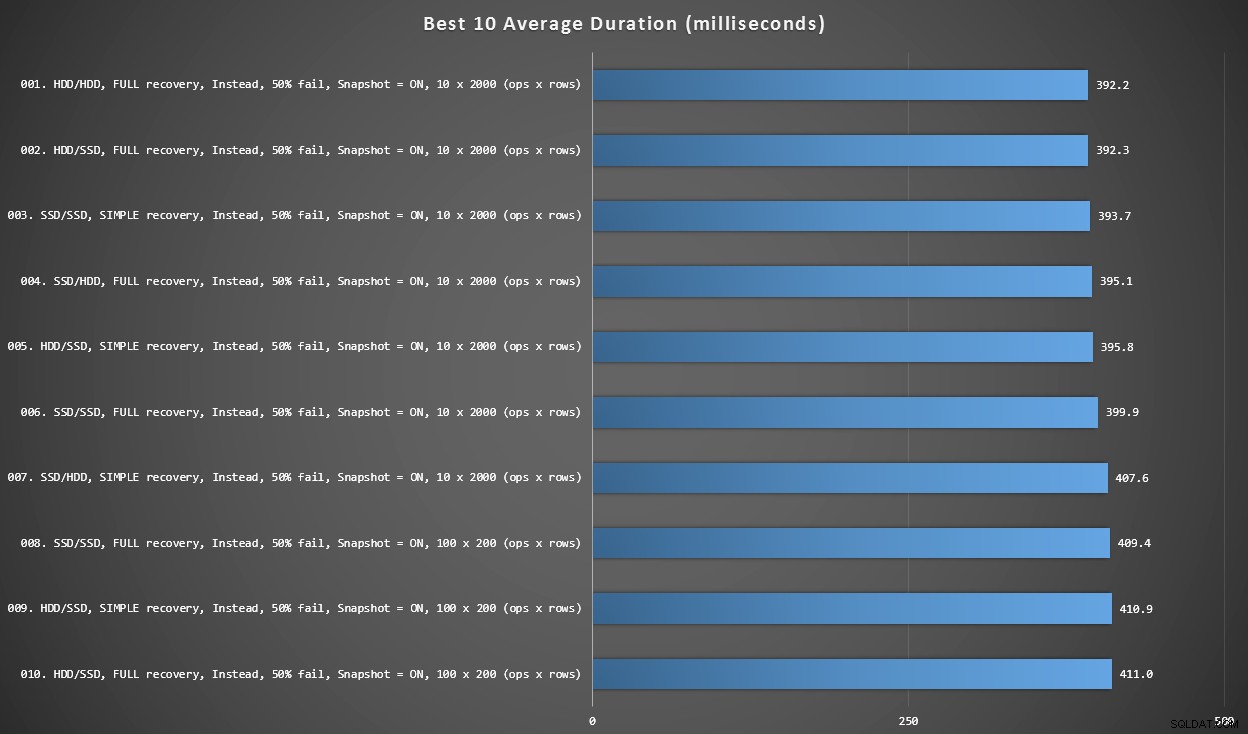
Die 10 besten Dauern in Millisekunden unter Berücksichtigung aller Variablen
Der schnellste AFTER-Trigger – eine ROLLBACK-Variante mit 10 % Fehlerrate bei der Stapelgröße von 100 x 200 Zeilen – kam auf Position #144 (806 ms).
Grafik 3 – Schlechteste 10 insgesamt
Dieses Diagramm zeigt die 10 langsamsten Ergebnisse, wenn alle Variablen berücksichtigt werden; alle sind AFTER-Varianten, alle beinhalten die 20.000 Singleton-Einfügungen, und alle haben Daten und Protokolle auf derselben langsamen Festplatte.
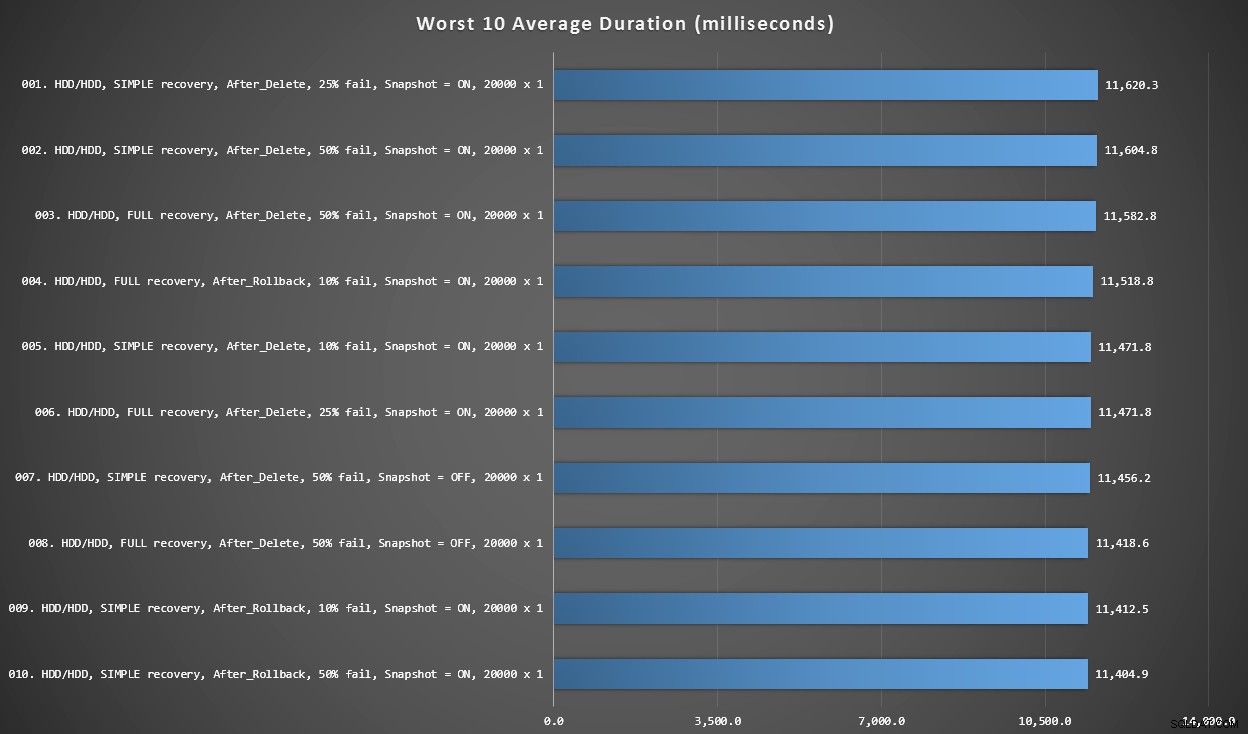
Die 10 schlechtesten Dauern in Millisekunden unter Berücksichtigung aller Variablen
Der langsamste INSTEAD OF-Test war auf Position #97 bei 5.680 ms – ein 20.000-Singleton-Insert-Test, bei dem 10 % fehlschlagen. Es ist auch interessant zu beobachten, dass kein einziger AFTER-Trigger mit der 20.000-Singleton-Insert-Batchgröße besser abschneidet – tatsächlich war das 96. schlechteste Ergebnis ein AFTER-Test (Löschen), der bei 10.219 ms eintraf – fast das Doppelte des zweitlangsamsten Ergebnisses.
Grafik 4 – Protokolldatenträgertyp, Singleton-Einfügungen
Die obigen Grafiken geben uns eine ungefähre Vorstellung von den größten Schmerzpunkten, aber sie sind entweder zu stark oder nicht ausreichend vergrößert. Dieses Diagramm filtert nach Daten, die auf der Realität basieren:In den meisten Fällen handelt es sich bei dieser Art von Operation um eine Singleton-Einfügung. Ich dachte, ich würde es nach Fehlerrate und Art der Festplatte aufschlüsseln, auf der sich das Protokoll befindet, aber nur Zeilen betrachten, in denen der Stapel aus 20.000 einzelnen Einfügungen besteht.
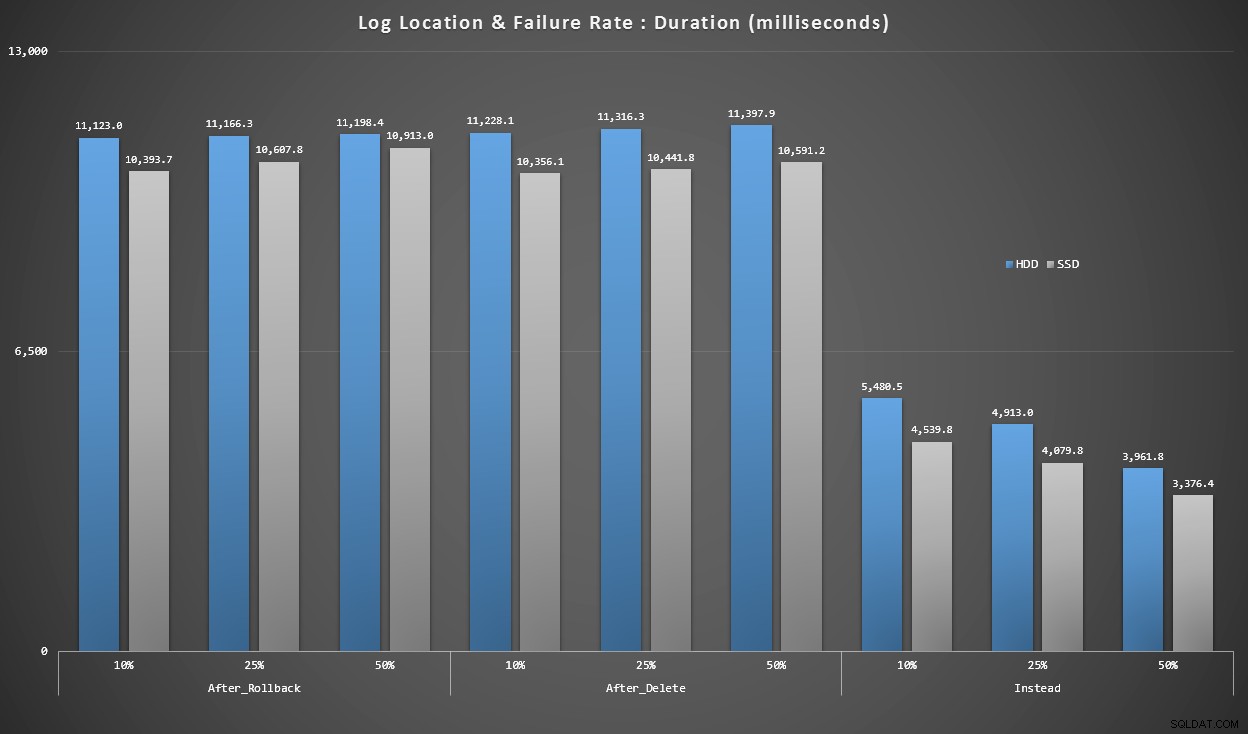
Dauer in Millisekunden, gruppiert nach Fehlerrate und Protokollspeicherort, für 20.000 Einzelbeilagen
Hier sehen wir, dass alle AFTER-Trigger im Durchschnitt im Bereich von 10 bis 11 Sekunden liegen (je nach Protokollspeicherort), während alle INSTEAD OF-Trigger deutlich unter der 6-Sekunden-Marke liegen.
Schlussfolgerung
Bisher scheint mir klar, dass der INSTEAD OF-Trigger in den meisten Fällen ein Gewinner ist – in einigen Fällen mehr als in anderen (z. B. wenn die Fehlerrate steigt). Andere Faktoren wie das Wiederherstellungsmodell scheinen viel weniger Einfluss auf die Gesamtleistung zu haben.
Wenn Sie andere Ideen haben, wie Sie die Daten aufschlüsseln können, oder eine Kopie der Daten wünschen, um Ihr eigenes Slicing und Dicing durchzuführen, lassen Sie es mich bitte wissen. Wenn Sie Hilfe beim Einrichten dieser Umgebung benötigen, damit Sie Ihre eigenen Tests durchführen können, kann ich Ihnen auch dabei helfen.
Während dieser Test zeigt, dass STATT Trigger definitiv eine Überlegung wert sind, ist es nicht die ganze Geschichte. Ich habe diese Trigger buchstäblich mit der Logik zusammengefügt, die meiner Meinung nach für jedes Szenario am sinnvollsten war, aber der Triggercode kann – wie jede T-SQL-Anweisung – für optimale Pläne optimiert werden. In einem Folgebeitrag werde ich einen Blick auf eine potenzielle Optimierung werfen, die den AFTER-Trigger wettbewerbsfähiger machen könnte.
Anhang
Für den Ergebnisabschnitt verwendete Abfragen:
Grafik 1 – Gesamtaggregate
SELECT RTRIM(l.loops) + ' x ' + RTRIM(l.perloop), AVG(r.Duration*1.0) FROM dbo.TestResults AS r INNER JOIN dbo.Loops AS l ON r.LoopID = l.LoopID GROUP BY RTRIM(l.loops) + ' x ' + RTRIM(l.perloop); SELECT t.IsSnapshot, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.IsSnapshot; SELECT t.RecoveryModel, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.RecoveryModel; SELECT t.DiskLayout, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.DiskLayout; SELECT t.TriggerType, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.TriggerType; SELECT t.FailureRate, AVG(Duration*1.0) FROM dbo.TestResults AS tr INNER JOIN dbo.Tests AS t ON tr.TestID = t.TestID GROUP BY t.FailureRate;
Grafik 2 &3 – Beste &Schlechteste 10
;WITH src AS
(
SELECT DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
Batch = RTRIM(l.loops) + ' x ' + RTRIM(l.perloop),
Duration = AVG(Duration*1.0)
FROM dbo.Tests AS t
INNER JOIN dbo.TestResults AS tr
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON tr.LoopID = l.LoopID
GROUP BY DiskLayout, RecoveryModel, TriggerType, FailureRate, IsSnapshot,
RTRIM(l.loops) + ' x ' + RTRIM(l.perloop)
),
agg AS
(
SELECT label = REPLACE(REPLACE(DiskLayout,'Data',''),'_Log','/')
+ ', ' + RecoveryModel + ' recovery, ' + TriggerType
+ ', ' + RTRIM(FailureRate) + '% fail'
+ ', Snapshot = ' + CASE IsSnapshot WHEN 1 THEN 'ON' ELSE 'OFF' END
+ ', ' + Batch + ' (ops x rows)',
best10 = ROW_NUMBER() OVER (ORDER BY Duration),
worst10 = ROW_NUMBER() OVER (ORDER BY Duration DESC),
Duration
FROM src
)
SELECT grp, label, Duration FROM
(
SELECT TOP (20) grp = 'best', label = RIGHT('0' + RTRIM(best10),2) + '. ' + label, Duration
FROM agg WHERE best10 <= 10
ORDER BY best10 DESC
UNION ALL
SELECT TOP (20) grp = 'worst', label = RIGHT('0' + RTRIM(worst10),2) + '. ' + label, Duration
FROM agg WHERE worst10 <= 10
ORDER BY worst10 DESC
) AS b
ORDER BY grp; Grafik 4 – Protokolldatenträgertyp, Singleton-Einfügungen
;WITH x AS
(
SELECT
TriggerType,FailureRate,
LogLocation = RIGHT(DiskLayout,3),
Duration = AVG(Duration*1.0)
FROM dbo.TestResults AS tr
INNER JOIN dbo.Tests AS t
ON tr.TestID = t.TestID
INNER JOIN dbo.Loops AS l
ON l.LoopID = tr.LoopID
WHERE l.loops = 20000
GROUP BY RIGHT(DiskLayout,3), FailureRate, TriggerType
)
SELECT TriggerType, FailureRate,
HDDDuration = MAX(CASE WHEN LogLocation = 'HDD' THEN Duration END),
SSDDuration = MAX(CASE WHEN LogLocation = 'SSD' THEN Duration END)
FROM x
GROUP BY TriggerType, FailureRate
ORDER BY TriggerType, FailureRate;