Karen Ly, Jr. Fixed Income Analyst bei RBC, gab mir eine T-SQL-Herausforderung, bei der es darum geht, die beste Übereinstimmung zu finden, anstatt eine genaue Übereinstimmung zu finden. In diesem Artikel behandle ich eine verallgemeinerte, vereinfachte Form der Herausforderung.
Die Herausforderung
Die Herausforderung besteht darin, Zeilen aus zwei Tabellen, T1 und T2, abzugleichen. Verwenden Sie den folgenden Code, um eine Beispieldatenbank namens testdb und darin die Tabellen T1 und T2 zu erstellen:
SET NOCOUNT ON;
IF DB_ID('testdb') IS NULL
CREATE DATABASE testdb;
GO
USE testdb;
DROP TABLE IF EXISTS dbo.T1, dbo.T2;
CREATE TABLE dbo.T1
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T1 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T1_col1 DEFAULT(0xAA)
);
CREATE TABLE dbo.T2
(
keycol INT NOT NULL IDENTITY
CONSTRAINT PK_T2 PRIMARY KEY,
val INT NOT NULL,
othercols BINARY(100) NOT NULL
CONSTRAINT DFT_T2_col1 DEFAULT(0xBB)
); Wie Sie sehen können, haben sowohl T1 als auch T2 eine numerische Spalte (in diesem Beispiel vom Typ INT) namens val. Die Herausforderung besteht darin, jeder Zeile von T1 die Zeile von T2 zuzuordnen, in der die absolute Differenz zwischen T2.val und T1.val am geringsten ist. Im Fall von Unentschieden (mehrere übereinstimmende Zeilen in T2) wird die oberste Zeile auf der Grundlage von val aufsteigend, keycol aufsteigend sortiert. Das heißt, die Zeile mit dem niedrigsten Wert in der val-Spalte, und wenn Sie immer noch Unentschieden haben, die Zeile mit dem niedrigsten keycol-Wert. Der Tiebreaker wird verwendet, um den Determinismus zu garantieren.
Verwenden Sie den folgenden Code, um T1 und T2 mit kleinen Sätzen von Beispieldaten zu füllen, um die Korrektheit Ihrer Lösungen überprüfen zu können:
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 (val)
VALUES(1),(1),(3),(3),(5),(8),(13),(16),(18),(20),(21);
INSERT INTO dbo.T2 (val)
VALUES(2),(2),(7),(3),(3),(11),(11),(13),(17),(19); Prüfen Sie den Inhalt von T1:
SELECT keycol, val, SUBSTRING(othercols, 1, 1) AS othercols FROM dbo.T1 ORDER BY val, keycol;
Dieser Code generiert die folgende Ausgabe:
keycol val othercols ----------- ----------- --------- 1 1 0xAA 2 1 0xAA 3 3 0xAA 4 3 0xAA 5 5 0xAA 6 8 0xAA 7 13 0xAA 8 16 0xAA 9 18 0xAA 10 20 0xAA 11 21 0xAA
Prüfen Sie den Inhalt von T2:
SELECT keycol, val, SUBSTRING(othercols, 1, 1) AS othercols FROM dbo.T2 ORDER BY val, keycol;
Dieser Code generiert die folgende Ausgabe:
keycol val othercols ----------- ----------- --------- 1 2 0xBB 2 2 0xBB 4 3 0xBB 5 3 0xBB 3 7 0xBB 6 11 0xBB 7 11 0xBB 8 13 0xBB 9 17 0xBB 10 19 0xBB
Hier ist das gewünschte Ergebnis für die angegebenen Beispieldaten:
keycol1 val1 othercols1 keycol2 val2 othercols2 ----------- ----------- ---------- ----------- ----------- ---------- 1 1 0xAA 1 2 0xBB 2 1 0xAA 1 2 0xBB 3 3 0xAA 4 3 0xBB 4 3 0xAA 4 3 0xBB 5 5 0xAA 4 3 0xBB 6 8 0xAA 3 7 0xBB 7 13 0xAA 8 13 0xBB 8 16 0xAA 9 17 0xBB 9 18 0xAA 9 17 0xBB 10 20 0xAA 10 19 0xBB 11 21 0xAA 10 19 0xBB
Bevor Sie mit der Arbeit an der Herausforderung beginnen, prüfen Sie das gewünschte Ergebnis und stellen Sie sicher, dass Sie die Matching-Logik verstehen, einschließlich der Tiebreak-Logik. Betrachten Sie beispielsweise die Zeile in T1, in der keycol 5 und val 5 ist. Diese Zeile hat mehrere engste Übereinstimmungen in T2:
keycol val othercols ----------- ----------- --------- 4 3 0xBB 5 3 0xBB 3 7 0xBB
In all diesen Zeilen ist die absolute Differenz zwischen T2.val und T1.val (5) 2. Unter Verwendung der Tiebreaking-Logik basierend auf der Reihenfolge val aufsteigend, ist keycol aufsteigend die oberste Zeile hier diejenige, in der val 3 und keycol 4 ist.
Sie werden die kleinen Sätze von Beispieldaten verwenden, um die Gültigkeit Ihrer Lösungen zu überprüfen. Um die Leistung zu überprüfen, benötigen Sie größere Sets. Verwenden Sie den folgenden Code, um eine Hilfsfunktion namens GetNums zu erstellen, die eine Folge von Ganzzahlen in einem angeforderten Bereich generiert:
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE OR ALTER FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO Verwenden Sie den folgenden Code, um T1 und T2 mit großen Sätzen von Beispieldaten zu füllen:
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 10000000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 10000000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; Die Variablen @numrowsT1 und @numrowsT2 steuern die Anzahl der Zeilen, mit denen die Tabellen gefüllt werden sollen. Die Variablen @maxvalT1 und @maxvalT2 steuern den Bereich unterschiedlicher Werte in der val-Spalte und beeinflussen daher die Dichte der Spalte. Der obige Code füllt die Tabellen mit jeweils 1.000.000 Zeilen und verwendet den Bereich von 1 – 10.000.000 für die Val-Spalte in beiden Tabellen. Dies führt zu einer geringen Dichte in der Spalte (große Anzahl unterschiedlicher Werte bei einer geringen Anzahl von Duplikaten). Die Verwendung niedrigerer Maximalwerte führt zu einer höheren Dichte (kleinere Anzahl unterschiedlicher Werte und daher mehr Duplikate).
Lösung 1 mit einer TOP-Unterabfrage
Die einfachste und naheliegendste Lösung ist wahrscheinlich eine, die T1 abfragt und mit dem CROSS APPLY-Operator eine Abfrage mit einem TOP (1)-Filter anwendet, wobei die Zeilen mit T2.val nach der absoluten Differenz zwischen T1.val und T2.val sortiert werden , T2.keycol als Tiebreaker. Hier ist der Lösungscode:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) T2.*
FROM dbo.T2
ORDER BY ABS(T2.val - T1.val), T2.val, T2.keycol ) AS A; Denken Sie daran, dass jede Tabelle 1.000.000 Zeilen enthält. Und die Dichte der val-Spalte ist in beiden Tabellen gering. Da es in der angewendeten Abfrage kein Filterprädikat gibt und die Reihenfolge einen Ausdruck beinhaltet, der Spalten manipuliert, gibt es hier leider keine Möglichkeit, unterstützende Indizes zu erstellen. Diese Abfrage generiert den Plan in Abbildung 1.
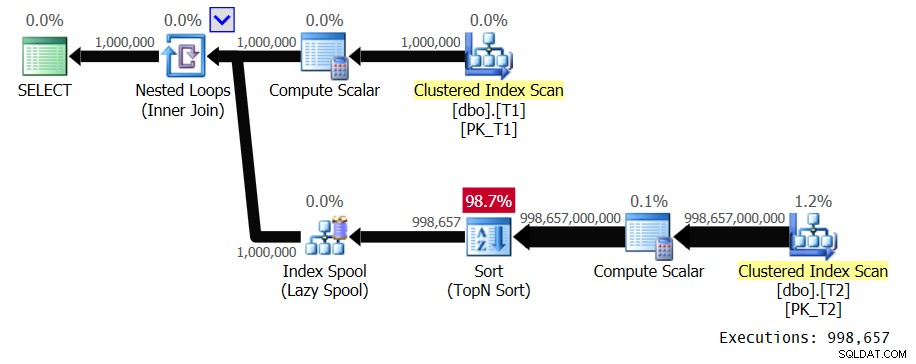 Abbildung 1:Plan für Lösung 1
Abbildung 1:Plan für Lösung 1
Der äußere Eingang der Schleife scannt 1.000.000 Zeilen von T1. Der innere Eingang der Schleife führt einen vollständigen Scan von T2 und eine TopN-Sortierung für jeden unterschiedlichen T1.val-Wert durch. In unserem Plan geschieht dies 998.657 Mal, da wir eine sehr geringe Dichte haben. Es platziert die Zeilen in einem Index-Spool, der durch T1.val verschlüsselt ist, sodass es diese für doppelte Vorkommen von T1.val-Werten wiederverwenden kann, aber wir haben sehr wenige Duplikate. Dieser Plan hat quadratische Komplexität. Zwischen allen erwarteten Ausführungen des inneren Zweigs der Schleife werden voraussichtlich fast eine Billion Zeilen verarbeitet. Wenn Sie über eine große Anzahl von Zeilen sprechen, die eine Abfrage verarbeiten muss, wissen die Leute bereits, dass Sie es mit einer teuren Abfrage zu tun haben, sobald Sie anfangen, Milliarden von Zeilen zu erwähnen. Normalerweise sprechen die Leute keine Begriffe wie Billionen, es sei denn, sie diskutieren über die US-Staatsverschuldung oder Börsencrashs. Im Zusammenhang mit der Abfrageverarbeitung haben Sie normalerweise nicht mit solchen Zahlen zu tun. Aber Pläne mit quadratischer Komplexität können schnell mit solchen Zahlen enden. Das Ausführen der Abfrage in SSMS mit aktivierter Live-Abfragestatistik einschließen dauerte 39,6 Sekunden, um nur 100 Zeilen von T1 auf meinem Laptop zu verarbeiten. Dies bedeutet, dass diese Abfrage etwa 4,5 Tage dauern sollte. Die Frage ist, ob Sie wirklich Binge-Watching von Live-Abfrageplänen mögen? Könnte ein interessanter Guinness-Rekord sein, den es zu versuchen gilt.
Lösung 2 mit zwei TOP-Unterabfragen
Angenommen, Sie sind auf der Suche nach einer Lösung, deren Fertigstellung Sekunden und nicht Tage dauert, hier ist eine Idee. Vereinheitlichen Sie im angewendeten Tabellenausdruck zwei innere TOP-Abfragen (1) – eine filtert eine Zeile mit T2.val
Hier sind die empfohlenen Indizes zur Unterstützung dieser Lösung:
CREATE INDEX idx_val_key ON dbo.T1(val, keycol) INCLUDE(othercols); CREATE INDEX idx_val_key ON dbo.T2(val, keycol) INCLUDE(othercols); CREATE INDEX idx_valD_key ON dbo.T2(val DESC, keycol) INCLUDE(othercols);
Hier ist der vollständige Lösungscode:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; Denken Sie daran, dass wir 1.000.000 Zeilen in jeder Tabelle haben, wobei die val-Spalte Werte im Bereich von 1 bis 10.000.000 (geringe Dichte) und optimale Indizes enthält.
Der Plan für diese Abfrage ist in Abbildung 2 dargestellt.
Abbildung 2:Plan für Lösung 2
Beobachten Sie die optimale Verwendung der Indizes auf T2, was zu einem Plan mit linearer Skalierung führt. Dieser Plan verwendet eine Indexspule auf die gleiche Weise wie der vorherige Plan, d. h. um zu vermeiden, dass die Arbeit im inneren Zweig der Schleife für doppelte T1.val-Werte wiederholt wird. Hier sind die Leistungsstatistiken, die ich für die Ausführung dieser Abfrage auf meinem System erhalten habe:
Elapsed: 27.7 sec, CPU: 27.6 sec, logical reads: 17,304,674
Lösung 2, mit deaktiviertem Spoolen
Man fragt sich unweigerlich, ob die Indexspule hier wirklich von Vorteil ist. Der Punkt ist, die Wiederholung der Arbeit für doppelte T1.val-Werte zu vermeiden, aber in einer Situation wie der unseren, wo wir eine sehr geringe Dichte haben, gibt es sehr wenige Duplikate. Das bedeutet, dass der Arbeitsaufwand beim Spoolen höchstwahrscheinlich größer ist, als nur die Arbeit für Duplikate zu wiederholen. Es gibt eine einfache Möglichkeit, dies zu überprüfen – mit dem Trace-Flag 8690 können Sie das Spooling im Plan wie folgt deaktivieren:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A
OPTION(QUERYTRACEON 8690); Ich habe den in Abbildung 3 gezeigten Plan für diese Ausführung erhalten:
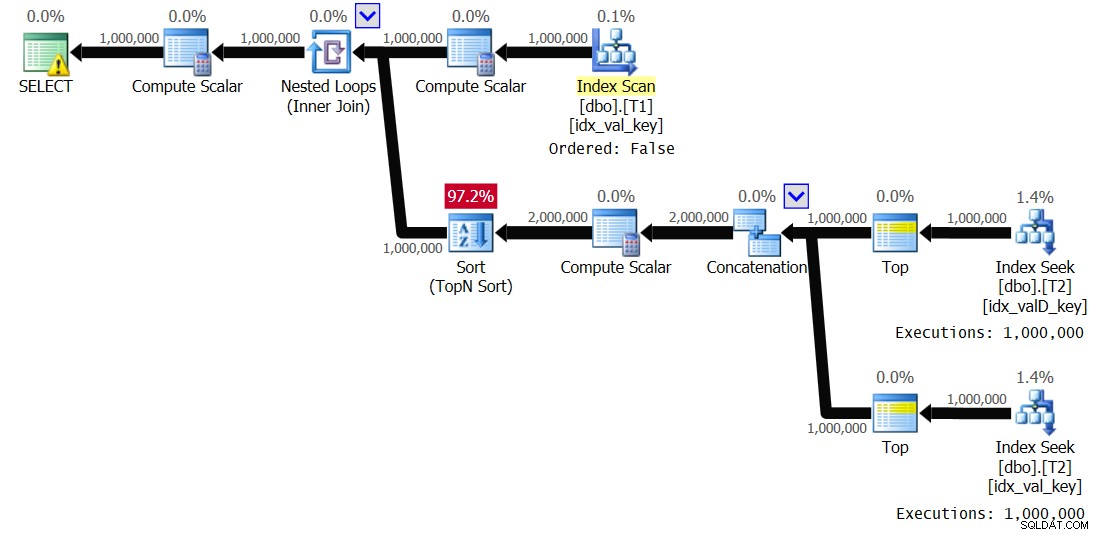 Abbildung 3:Plan für Lösung 2 mit deaktiviertem Spooling
Abbildung 3:Plan für Lösung 2 mit deaktiviertem Spooling
Beachten Sie, dass die Indexspule verschwunden ist und dieses Mal der innere Zweig der Schleife 1.000.000 Mal ausgeführt wird. Hier sind die Leistungsstatistiken, die ich für diese Ausführung erhalten habe:
Elapsed: 19.18 sec, CPU: 19.17 sec, logical reads: 6,042,148
Das ist eine Reduzierung der Ausführungszeit um 44 Prozent.
Lösung 2, mit geändertem Wertebereich und Indizierung
Das Deaktivieren des Spooling ist sehr sinnvoll, wenn Sie eine niedrige Dichte in den T1.val-Werten haben; Das Spulen kann jedoch sehr vorteilhaft sein, wenn Sie eine hohe Dichte haben. Führen Sie beispielsweise den folgenden Code aus, um T1 und T2 mit Beispieldaten neu zu füllen, die @maxvalT1 und @maxvalT2 auf 1000 (1.000 maximale unterschiedliche Werte) setzen:
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 1000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 1000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; Führen Sie Lösung 2 erneut aus, zunächst ohne das Trace-Flag:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; Der Plan für diese Ausführung ist in Abbildung 4 dargestellt:
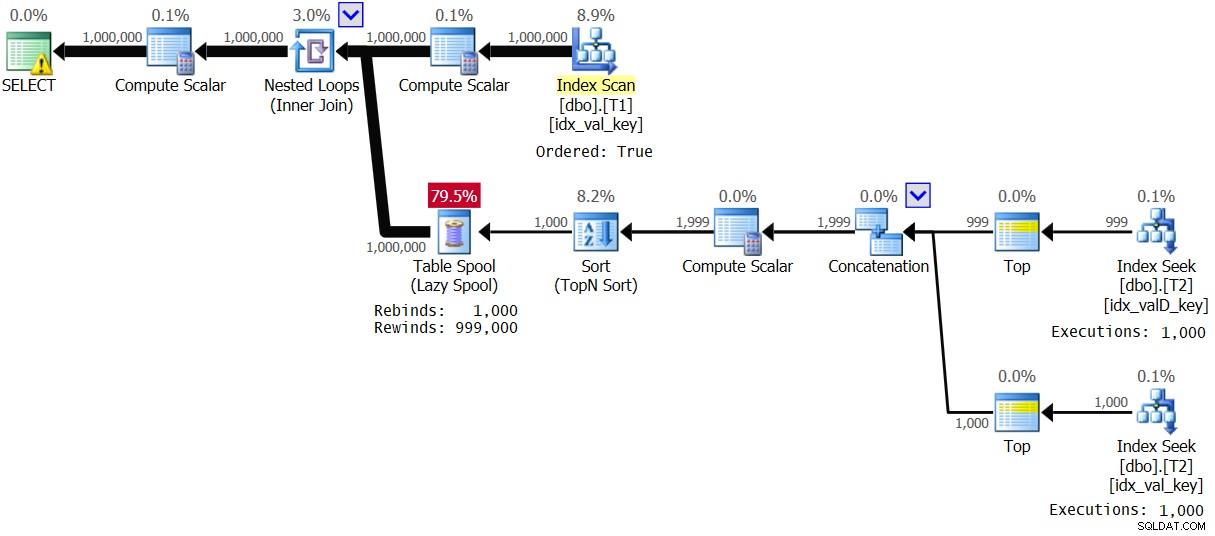 Abbildung 4:Plan für Lösung 2, mit Wertebereich 1 – 1000
Abbildung 4:Plan für Lösung 2, mit Wertebereich 1 – 1000
Der Optimierer entschied sich aufgrund der hohen Dichte in T1.val für einen anderen Plan. Beachten Sie, dass der Index auf T1 in Schlüsselreihenfolge gescannt wird. Für jedes erste Vorkommen eines unterschiedlichen T1.val-Werts wird also der innere Zweig der Schleife ausgeführt und das Ergebnis in einen regulären Tabellen-Spool (Rebind) gespoolt. Dann wird für jedes nicht erste Auftreten des Werts ein Zurückspulen angewendet. Bei 1.000 unterschiedlichen Werten wird der innere Zweig nur 1.000 Mal ausgeführt. Dies führt zu hervorragenden Leistungsstatistiken:
Elapsed: 1.16 sec, CPU: 1.14 sec, logical reads: 23,278
Versuchen Sie nun, die Lösung mit deaktiviertem Spooling auszuführen:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A
OPTION(QUERYTRACEON 8690); Ich habe den in Abbildung 5 gezeigten Plan erhalten.
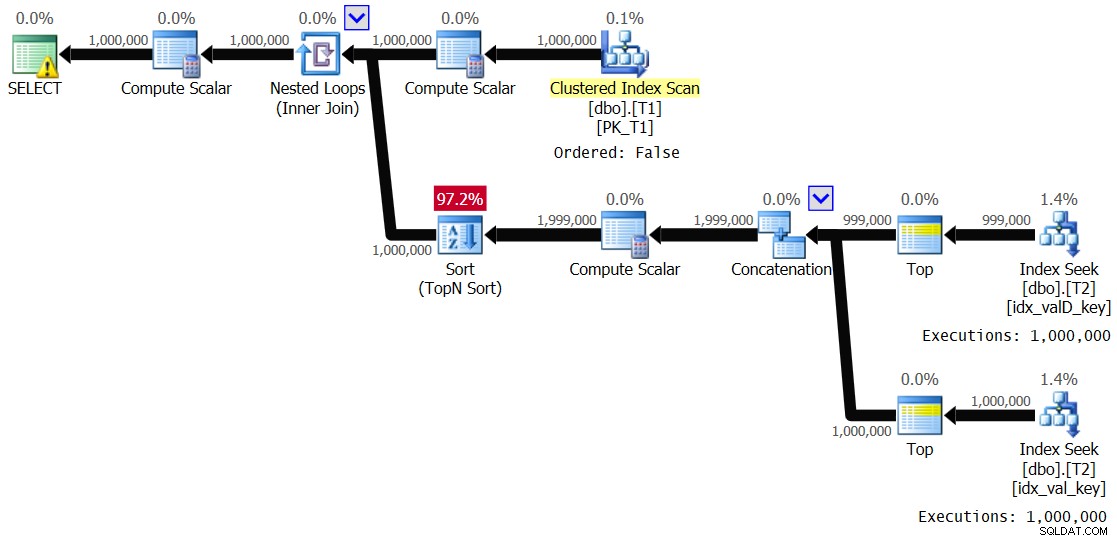 Abbildung 5:Plan für Lösung 2, mit Wertebereich 1–1.000 und Spooling deaktiviert
Abbildung 5:Plan für Lösung 2, mit Wertebereich 1–1.000 und Spooling deaktiviert
Es ist im Wesentlichen derselbe Plan, der zuvor in Abbildung 3 gezeigt wurde. Der innere Zweig der Schleife wird 1.000.000 Mal ausgeführt. Hier sind die Leistungsstatistiken, die ich für diese Ausführung erhalten habe:
Elapsed: 24.5 sec, CPU: 24.2 sec, logical reads: 8,012,548
Natürlich sollten Sie darauf achten, das Spoolen nicht zu deaktivieren, wenn Sie eine hohe Dichte in T1.val haben.
Das Leben ist gut, wenn Ihre Situation so einfach ist, dass Sie in der Lage sind, unterstützende Indizes zu erstellen. Die Realität ist, dass in einigen Fällen in der Praxis genügend zusätzliche Logik in der Abfrage vorhanden ist, die die Möglichkeit ausschließt, optimale unterstützende Indizes zu erstellen. In solchen Fällen wird Lösung 2 nicht gut funktionieren.
Um die Leistung von Lösung 2 ohne unterstützende Indizes zu demonstrieren, füllen Sie T1 und T2 wieder mit Beispieldaten auf, indem Sie @maxvalT1 und @maxvalT2 auf 10000000 (Wertebereich 1–10M) setzen und auch die unterstützenden Indizes entfernen:
DROP INDEX IF EXISTS idx_val_key ON dbo.T1;
DROP INDEX IF EXISTS idx_val_key ON dbo.T2;
DROP INDEX IF EXISTS idx_valD_key ON dbo.T2;
DECLARE
@numrowsT1 AS INT = 1000000,
@maxvalT1 AS INT = 10000000,
@numrowsT2 AS INT = 1000000,
@maxvalT2 AS INT = 10000000;
TRUNCATE TABLE dbo.T1;
TRUNCATE TABLE dbo.T2;
INSERT INTO dbo.T1 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT1 + 1 AS val
FROM dbo.GetNums(1, @numrowsT1) AS Nums;
INSERT INTO dbo.T2 WITH(TABLOCK) (val)
SELECT ABS(CHECKSUM(NEWID())) % @maxvalT2 + 1 AS val
FROM dbo.GetNums(1, @numrowsT2) AS Nums; Führen Sie Lösung 2 erneut aus, wobei Live-Abfragestatistiken in SSMS aktiviert sind:
SELECT
T1.keycol AS keycol1, T1.val AS val1, SUBSTRING(T1.othercols, 1, 1) AS othercols1,
A.keycol AS keycol2, A.val AS val2, SUBSTRING(A.othercols, 1, 1) AS othercols2
FROM dbo.T1
CROSS APPLY
( SELECT TOP (1) D.*
FROM ( SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val < T1.val
ORDER BY T2.val DESC, T2.keycol
UNION ALL
SELECT TOP (1) *
FROM dbo.T2
WHERE T2.val >= T1.val
ORDER BY T2.val, T2.keycol ) AS D
ORDER BY ABS(D.val - T1.val), D.val, D.keycol ) AS A; Ich habe den in Abbildung 6 gezeigten Plan für diese Abfrage erhalten:
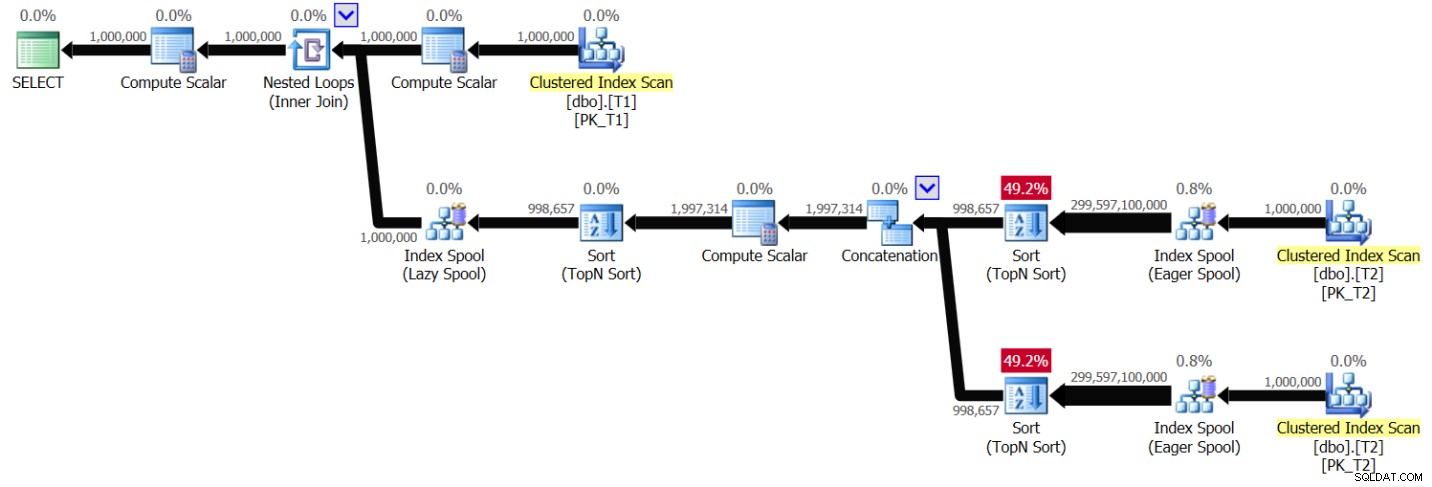 Abbildung 6:Plan für Lösung 2, ohne Indizierung, mit Wertebereich 1 – 1.000.000
Abbildung 6:Plan für Lösung 2, ohne Indizierung, mit Wertebereich 1 – 1.000.000
Sie können ein Muster sehen, das dem zuvor in Abbildung 1 gezeigten sehr ähnlich ist, nur dass der Plan dieses Mal T2 zweimal pro eindeutigem T1.val-Wert scannt. Auch hier wird die Plankomplexität quadratisch. Das Ausführen der Abfrage in SSMS mit aktivierter Live-Abfragestatistik einschließen dauerte 49,6 Sekunden, um 100 Zeilen von T1 auf meinem Laptop zu verarbeiten, was bedeutet, dass diese Abfrage ungefähr 5,7 Tage dauern sollte, bis sie abgeschlossen ist. Dies könnte natürlich gute Nachrichten bedeuten, wenn Sie versuchen, den Guinness-Weltrekord für das Binge-Watching eines Live-Abfrageplans zu brechen.
Schlussfolgerung
Ich möchte Karen Ly von RBC dafür danken, dass sie mir diese nette Challenge mit dem engsten Match präsentiert hat. Ich war ziemlich beeindruckt von ihrem Code für die Handhabung, der eine Menge zusätzlicher Logik enthielt, die spezifisch für ihr System war. In diesem Artikel habe ich vernünftig funktionierende Lösungen gezeigt, wenn Sie in der Lage sind, optimale unterstützende Indizes zu erstellen. Aber wie Sie sehen konnten, sind die Ausführungszeiten in Fällen, in denen dies keine Option ist, offensichtlich miserabel. Können Sie sich Lösungen vorstellen, die auch ohne optimal unterstützende Indizes gut funktionieren? Fortsetzung folgt…