Einführung
In SQL Server 2012 konnte die gruppierte (Vektor-)Aggregation die Ausführung im parallelen Batchmodus verwenden, jedoch nur für das partielle Aggregat (pro Thread). Das zugehörige globale Aggregat lief nach einem Repartition Streams immer im Zeilenmodus Austausch.
SQL Server 2014 fügte die Möglichkeit hinzu, eine gruppierte Aggregation im parallelen Stapelmodus innerhalb eines einzigen Hash-Match-Aggregats durchzuführen Operator. Dies eliminierte unnötige Verarbeitung im Zeilenmodus und machte einen Austausch überflüssig.
SQL Server 2016 führte die Verarbeitung im seriellen Batchmodus und Aggregat-Pushdown ein . Wenn Pushdown erfolgreich ist, wird die Aggregation innerhalb des Columnstore Scan durchgeführt Betreiber selbst, der möglicherweise direkt mit komprimierten Daten arbeitet und SIMD-CPU-Anweisungen nutzt.
Die mit Aggregat-Pushdown möglichen Leistungsverbesserungen können sehr beträchtlich sein. Die Dokumentation listet einige der Bedingungen auf, die erforderlich sind, um Pushdown zu erreichen, aber es gibt Fälle, in denen das Fehlen von „lokal aggregierten Zeilen“ allein aus diesen Details nicht vollständig erklärt werden kann.
In diesem Artikel werden zusätzliche Faktoren behandelt, die sich auf das aggregierte Pushdown für GROUP BY auswirken Nur Abfragen . Skalarer Aggregat-Pushdown (Aggregation ohne GROUP BY -Klausel), Filter-Pushdown und Ausdrucks-Pushdown können in einem zukünftigen Beitrag behandelt werden.
Columnstore-Speicher
Als erstes ist zu sagen, dass aggregierter Pushdown nur für komprimierte Daten gilt, also Zeilen in einem Deltaspeicher sind nicht förderfähig. Darüber hinaus kann Pushdown von der Art der verwendeten Komprimierung abhängen. Um dies zu verstehen, ist es notwendig, sich zunächst anzusehen, wie Columnstore-Speicher auf hoher Ebene funktioniert:
Eine komprimierte Zeilengruppe enthält ein Spaltensegment für jede Spalte. Die Rohspaltenwerte sind kodiert in einer 4-Byte- oder 8-Byte-Ganzzahl mit Wert oder Wörterbuch Codierung.
Wertcodierung kann die Anzahl der für die Speicherung erforderlichen Bits reduzieren, indem Rohwerte mit einem Basis-Offset und einem Magnituden-Modifikator übersetzt werden. Beispielsweise können die Werte {1100, 1200, 1300} als (0, 1, 2) gespeichert werden, indem zuerst mit einem Faktor von 0,01 skaliert wird, um {11, 12, 13} zu erhalten, und dann auf 11 umbasiert wird, um {0 zu erhalten, 1, 2}.
Wörterbuchkodierung wird verwendet, wenn es doppelte Werte gibt. Es kann mit nicht numerischen Daten verwendet werden. Jeder eindeutige Wert wird in einem Wörterbuch gespeichert und einer ganzzahligen ID zugewiesen. Die Segmentdaten referenzieren dann ID-Nummern im Wörterbuch anstelle der ursprünglichen Werte.
Nach der Codierung können die Segmentdaten unter Verwendung von Lauflängencodierung (RLE) und Bitpacking weiter komprimiert werden:
RLE ersetzt sich wiederholende Elemente durch die Daten und die Anzahl der Wiederholungen, zum Beispiel könnte {1, 1, 1, 1, 1, 2, 2, 2} durch {5×1, 3×2} ersetzt werden. RLE-Platzeinsparungen nehmen mit der Länge der sich wiederholenden Läufe zu. Kleine Auflagen können kontraproduktiv sein.
Bit-Packing speichert die binäre Form der Daten in einem möglichst schmalen gemeinsamen Fenster. Beispielsweise werden die Zahlen {7, 9, 15} in binären Ganzzahlen (Einzelbyte für Leerzeichen) als {00000111, 00001001, 00001111} gespeichert. Das Packen dieser Bits in ein festes Vier-Bit-Fenster ergibt den Stream {011110011111}. Wenn Sie wissen, dass es eine feste Fenstergröße gibt, ist kein Trennzeichen erforderlich.
Codierung und Komprimierung sind separate Schritte, sodass RLE und Bitpacking auf das Ergebnis der Wertcodierung oder Wörterbuchcodierung der Rohdaten angewendet werden. Außerdem können Daten innerhalb desselben Spaltensegments eine Mischung aufweisen von RLE und Bit-Packing-Komprimierung. RLE-komprimierte Daten werden als rein bezeichnet , und bitgepackte komprimierte Daten werden als unrein bezeichnet . Ein Spaltensegment kann sowohl reine als auch unreine Daten enthalten.
Die durch Kodierung und Komprimierung erzielbare Platzersparnis kann von der Bestellung abhängen. Alle Spaltensegmente innerhalb einer Zeilengruppe müssen implizit auf die gleiche Weise sortiert werden, damit SQL Server vollständige Zeilen aus den Spaltensegmenten effizient rekonstruieren kann. Da die Zeile 123 in jedem Spaltensegment an derselben Position (123) gespeichert ist, muss die Zeilennummer nicht gespeichert werden.
Ein Nachteil dieser Anordnung ist die gemeinsame Sortierreihenfolge muss für alle Spaltensegmente einer Zeilengruppe gewählt werden. Eine bestimmte Reihenfolge könnte für eine Spalte sehr gut geeignet sein, verpasst aber wichtige Gelegenheiten in anderen Spalten. Dies ist am deutlichsten bei der RLE-Komprimierung der Fall. SQL Server verwendet die Vertipaq-Technologie, um eine gute Methode zum Sortieren von Spalten in jeder Zeilengruppe zu ermitteln, um ein gutes Gesamtkomprimierungsergebnis zu erzielen.
SQL Server verwendet derzeit nur RLE innerhalb eines Spaltensegments, wenn es ein Minimum von 64 gibt zusammenhängende sich wiederholende Werte. Die restlichen Werte im Segment sind bitgepackt. Wie bereits erwähnt, hängt es von der für die Zeilengruppe gewählten Reihenfolge ab, ob sich wiederholende Werte in einem Spaltensegment zusammenhängend erscheinen.
SQL Server unterstützt spezialisierte SIMD Bit-Entpacken für Bitbreiten von 1 bis einschließlich 10, 12 und 21 Bit. SQL Server kann auch standardmäßige ganzzahlige Größen verwenden, z. 16, 32 und 64 Bit mit Bit-Packing. Diese Zahlen wurden ausgewählt, weil sie gut passen in einem 64-Bit-Gerät. Beispielsweise kann eine Einheit drei 21-Bit-Untereinheiten oder 5 12-Bit-Untereinheiten enthalten. SQL Server nicht beim Packen von Bits eine 64-Bit-Grenze überschreiten.
SIMD verwendet 256-Bit-Register, wenn der Prozessor AVX2-Befehle unterstützt, und 128-Bit-Register, wenn SSE4.2-Befehle verfügbar sind. Andernfalls kann Nicht-SIMD-Entpacken verwendet werden.
Gruppierte aggregierte Pushdown-Bedingungen
Die meisten Pläne mit einem Hash Match Aggregate Operator direkt über einem Columnstore Scan Betreiber qualifiziert sich möglicherweise für gruppierten Aggregat-Pushdown, vorbehaltlich der allgemeinen Bedingungen, die in der Dokumentation angegeben sind.
Manchmal können auch zusätzliche Filter und Ausdrücke hinzugefügt werden, ohne dass der Pushdown für gruppierte Aggregate verhindert wird. Als allgemeine Regel gilt, dass der Filter oder Ausdruck auch Pushdown-fähig sein muss (obwohl kompatible Ausdrücke immer noch in einem separaten Compute Scalar erscheinen können ). Wie in der Einleitung erwähnt, können diese Aspekte in separaten Artikeln ausführlich behandelt werden.
Derzeit gibt es in den Ausführungsplänen keinen Hinweis darauf, ob ein bestimmtes Aggregat als allgemein kompatibel angesehen wurde mit gruppiertem Aggregat-Pushdown oder nicht. Dennoch, wenn der Plan allgemein qualifiziert ist für gruppiertes Pushdown-Aggregat werden sowohl Pushdown-Codepfade (schnell) als auch Nicht-Pushdown-Codepfade (langsam) verfügbar gemacht.
Jeder Scan-Ausgabestapel (mit bis zu 900 Zeilen) trifft eine Laufzeitentscheidung zwischen den schnellen und langsamen Codepfaden. Durch diese Flexibilität können so viele Chargen wie möglich vom Pushdown profitieren. Im schlimmsten Fall werden trotz „allgemein kompatiblem“ Plan keine Batches zur Laufzeit den schnellen Weg nutzen.
Der Ausführungsplan zeigt das Ergebnis der Fast-Path-Pushdown-Verarbeitung als „lokal aggregierte Zeilen“ ohne entsprechende Zeilenausgabe aus dem Scan. Slow-Path-Batches werden wie gewohnt als Ausgabezeilen aus dem Columnstore-Scan angezeigt, wobei die Aggregation von einem separaten Operator statt beim Scan durchgeführt wird.
Eine einzelne gruppierte Aggregat- und Scan-Kombination kann einige Stapel auf den schnellen Pfad und einige auf den langsamen Pfad schicken, sodass es durchaus möglich ist, einige, aber nicht alle Zeilen lokal aggregiert zu sehen. Wenn der Pushdown für gruppierte Aggregate erfolgreich ist, enthält jeder Ausgabebatch des Scans Gruppierungsschlüssel und ein partielles Aggregat, das die beitragenden Zeilen darstellt.
Detaillierte Prüfungen
Es gibt eine Reihe von Laufzeitprüfungen, um festzustellen, ob die Pushdown-Verarbeitung verwendet werden kann. Zu den leicht dokumentierten Prüfungen gehören:
- Es darf keine Möglichkeit eines Aggregat-Überlaufs geben .
- Alle unreinen (Bit-gepackt) Gruppierungsschlüssel darf nicht breiter als 10 Bit sein . Reine (RLE-codierte) Gruppierungsschlüssel werden so behandelt, als hätten sie eine unreine Breite von Null, sodass diese normalerweise nur wenige Hindernisse darstellen.
- Pushdown-Verarbeitung muss weiterhin als lohnend angesehen werden , unter Verwendung eines „Nutzenmaßes“, das am Ende jeder Ausgabecharge aktualisiert wird.
Die Möglichkeit eines Aggregatüberlaufs wird für jede Charge basierend auf Aggregattyp, Ergebnisdatentyp, aktuellen Teilaggregationswerten und Informationen zu den Eingabedaten konservativ bewertet. Beispielsweise kennt SQL Server Mindest- und Höchstwerte aus Segmentmetadaten, wie sie in der DMV sys.column_store_segments verfügbar gemacht werden . Wenn die Gefahr eines Überlaufs besteht, verwendet der Stapel eine langsame Pfadverarbeitung. Dies ist vor allem ein Risiko für SUM aggregieren.
Die Beschränkung auf die unreine Gruppierungsschlüsselbreite ist hervorzuheben. Es gilt nur für Spalten in GROUP BY Klausel, die tatsächlich im Ausführungsplan als Grundlage für die Gruppierung verwendet werden. Diese Sätze sind nicht immer genau gleich, da der Optimierer die Freiheit hat, redundante Gruppierungsspalten zu entfernen oder Aggregate anderweitig neu zu schreiben, solange die endgültigen Abfrageergebnisse garantiert mit der ursprünglichen Abfragespezifikation übereinstimmen. Bei Abweichungen sind die im Ausführungsplan angezeigten Gruppierungsspalten ausschlaggebend.
Die größere Schwierigkeit besteht darin, zu wissen, ob eine der Gruppierungsspalten unter Verwendung von Bitpacking gespeichert ist, und wenn ja, welche Breite verwendet wurde. Es wäre auch nützlich zu wissen, wie viele Werte mit RLE codiert wurden. Diese Informationen könnten in den column_store_segments stehen DMV, aber das ist heute nicht mehr der Fall. Soweit ich weiß, gibt es derzeit keine dokumentierte Möglichkeit, Bitpacking- und RLE-Informationen aus Metadaten zu erhalten. Das lässt uns mit der Suche nach undokumentierten Alternativen zurück.
RLE- und Bitpacking-Informationen finden
Der undokumentierte DBCC CSINDEX kann uns die Informationen geben, die wir brauchen. Das Ablaufverfolgungsflag 3604 muss aktiviert sein, damit dieser Befehl eine Ausgabe auf der Registerkarte „SSMS-Meldungen“ erzeugt. Bei gegebenen Informationen über das Spaltensegment, an dem wir interessiert sind, gibt dieser Befehl Folgendes zurück:
- Segmentattribute (ähnlich wie
column_store_segments) - RLE-Informationen
- Lesezeichen in RLE-Daten
- Bitpack-Informationen
Da es nicht dokumentiert ist, gibt es ein paar Macken (z. B. das Hinzufügen von eins zu den Spalten-IDs für gruppierten Columnstore, aber nicht für nicht gruppierten Columnstore) und sogar ein paar kleinere Fehler. Sie sollten es nur auf einem persönlichen Testsystem verwenden. Hoffentlich wird stattdessen eines Tages eine unterstützte Methode für den Zugriff auf diese Daten bereitgestellt.
Beispiele
Der beste Weg, um DBCC CSINDEX anzuzeigen und die bisher in diesem Text angesprochenen Punkte zu demonstrieren, besteht darin, einige Beispiele durchzuarbeiten. Die folgenden Skripte gehen davon aus, dass es eine Tabelle mit dem Namen dbo.Numbers gibt in der aktuellen Datenbank, die ganze Zahlen von 1 bis mindestens 16.384 enthält. Hier ist ein Skript, um meine Standardversion dieser Tabelle mit zehn Millionen Ganzzahlen zu erstellen:
IF OBJECT_ID(N'dbo.Numbers', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Numbers;
END;
GO
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1
)
SELECT
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten AS T10
CROSS JOIN Ten AS T100
CROSS JOIN Ten AS T1000
CROSS JOIN Ten AS T10000
CROSS JOIN Ten AS T100000
CROSS JOIN Ten AS T1000000
CROSS JOIN Ten AS T10000000
ORDER BY n
OFFSET 0 ROWS
FETCH FIRST 10 * 1000 * 1000 ROWS ONLY
OPTION
(MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT [PK dbo.Numbers n]
PRIMARY KEY CLUSTERED (n)
WITH
(
SORT_IN_TEMPDB = ON,
MAXDOP = 1,
FILLFACTOR = 100
);
Die Beispiele verwenden alle dieselbe grundlegende Testtabelle:Die erste Spalte c1 enthält eine eindeutige Nummer für jede Zeile. Die zweite Spalte c2 ist mit einer Reihe von Duplikaten für jeden einer kleinen Anzahl unterschiedlicher Werte gefüllt.
Ein gruppierter Columnstore-Index wird nach der Datenauffüllung erstellt, sodass alle Testdaten in einer einzigen komprimierten Zeilengruppe landen (kein Deltaspeicher). Es wird erstellt und ersetzt einen b-Tree-Clustered-Index in Spalte c2 um den VertiPaq-Algorithmus zu ermutigen, die Nützlichkeit des Sortierens nach dieser Spalte frühzeitig zu berücksichtigen. Dies ist der grundlegende Testaufbau:
USE Sandpit;
GO
DROP TABLE IF EXISTS dbo.Test;
GO
CREATE TABLE dbo.Test
(
c1 integer NOT NULL,
c2 integer NOT NULL
);
GO
DECLARE
@values integer = 512,
@dupes integer = 63;
INSERT dbo.Test
(c1, c2)
SELECT
N.n,
N.n % @values
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND @values * @dupes;
GO
-- Encourage VertiPaq
CREATE CLUSTERED INDEX CCSI ON dbo.Test (c2);
GO
CREATE CLUSTERED COLUMNSTORE INDEX CCSI
ON dbo.Test
WITH (MAXDOP = 1, DROP_EXISTING = ON);
Die beiden Variablen sind für die Anzahl unterschiedlicher Werte, die in Spalte c2 eingefügt werden sollen , und die Anzahl der Duplikate für jeden dieser Werte.
Die Testabfrage ist eine sehr einfache gruppierte COUNT_BIG Aggregation mit Spalte c2 als Schlüssel:
-- The test query
SELECT
T.c2,
numrows = COUNT_BIG(*)
FROM dbo.Test AS T
GROUP BY
T.c2;
Columnstore-Indexinformationen werden mit DBCC CSINDEX angezeigt nach jeder Testabfrageausführung:
DECLARE
@dbname sysname = DB_NAME(),
@objectid integer = OBJECT_ID(N'dbo.Test', N'U');
DECLARE
@rowsetid bigint =
(
SELECT
P.hobt_id
FROM sys.partitions AS P
WHERE
P.[object_id] = @objectid
AND P.index_id = 1
AND P.partition_number = 1
),
@rowgroupid integer = 0,
@columnid integer =
COLUMNPROPERTY(@objectid, N'c2', 'ColumnId') + 1;
DBCC CSINDEX
(
@dbname,
@rowsetid,
@columnid,
@rowgroupid,
1, -- show segment data
2, -- print option
0, -- start bitpack unit (inclusive)
2 -- end bitpack unit (exclusive)
); Tests wurden mit der neuesten veröffentlichten Version von SQL Server durchgeführt, die zum Zeitpunkt des Schreibens verfügbar war:Microsoft SQL Server 2017 RTM-CU13-OD Build 14.0.3049 Developer Edition (64-Bit) unter Windows 10 Pro. Die Dinge sollten auch auf dem neuesten Build von SQL Server 2016 gut funktionieren.
Test 1:Pushdown, 9-bit unreine Tasten
Dieser Test verwendet das Skript zum Auffüllen der Testdaten genau wie oben geschrieben und erzeugt eine Tabelle mit 32.256 Zeilen. Spalte c1 enthält Zahlen von 1 bis 32.256.
Spalte c2 enthält 512 eindeutige Werte von 0 bis einschließlich 511. Jeder Wert in c2 wird 63 Mal dupliziert , aber sie erscheinen nicht als zusammenhängende Blöcke, wenn sie in c1 betrachtet werden Befehl; Sie durchlaufen 63 Mal die Werte 0 bis 511.
Angesichts der vorangegangenen Diskussion erwarten wir, dass SQL Server den c2 speichert Spaltendaten mit:
- Wörterbuchkodierung da es eine beträchtliche Anzahl doppelter Werte gibt.
- Kein RLE . Die Anzahl der Duplikate (63) pro Wert erreicht nicht den für RLE erforderlichen Schwellenwert von 64.
- Bit-Packungsgröße 9 . Die 512 unterschiedlichen Wörterbucheinträge passen genau in 9 Bits (2^9 =512). Jede 64-Bit-Einheit enthält bis zu sieben 9-Bit-Untereinheiten.
All dies wird mit dem DBCC CSINDEX als korrekt bestätigt Abfrage:
Die Segmentattribute Abschnitt der Ausgabe zeigt Wörterbuchkodierung (Typ 2; die Werte für encodingType sind wie unter sys.column_store_segments dokumentiert ).
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =511
NullValue =-1 OnDiskSize =37944 Zeilenanzahl =32256
Der RLE-Abschnitt zeigt keine RLE-Daten , nur ein Zeiger auf den bitgepackten Bereich und ein leerer Eintrag für den Wert Null:
RLE-Header:
Lob-Typ =3 RLE-Array-Anzahl (in Bezug auf native Einheiten) =2
RLE-Array-Eintragsgröße =8
RLE-Daten:
Index =0 Bitpack Array Index =0 Anzahl =32256
Index =1 Wert =0 Anzahl =0
Der Bitpack Data Header Abschnitt zeigt Bitpackgröße 9 und 4.608 verwendete Bitpack-Einheiten:
Bitpack-Datenheader:
Bitpack Entry Size =9 Bitpack Unit Count =4608 Bitpack MinId =3
Bitpack DataSize =36864
Die Bitpack-Daten Abschnitt zeigt die Werte, die in den ersten beiden Bitpack-Einheiten gespeichert sind, wie von den letzten beiden Parametern für DBCC CSINDEX angefordert Befehl. Denken Sie daran, dass jede 64-Bit-Einheit 7 Untereinheiten (nummeriert von 0 bis 6) mit jeweils 9 Bit (7 x 9 =63 Bit) enthalten kann. Die 4.608 Einheiten enthalten insgesamt 4.608 * 7 =32.256 Zeilen:
Einheit 0 Untereinheit 0 =383
Einheit 0 Untereinheit 1 =255
Einheit 0 Untereinheit 2 =127
Einheit 0 Untereinheit 3 =510
Einheit 0 Untereinheit 4 =381
Einheit 0 Untereinheit 5 =253
Einheit 0 Untereinheit 6 =125
Einheit 1 Untereinheit 0 =508
Einheit 1 Untereinheit 1 =379
Einheit 1 Untereinheit 2 =251
Einheit 1 Untereinheit 3 =123
Einheit 1 Untereinheit 4 =506
Einheit 1 Untereinheit 5 =377
Einheit 1 Untereinheit 6 =249
Da die Gruppierungsschlüssel Bit-Packing verwenden mit einer Größe kleiner oder gleich 10 , erwarten wir einen gruppierten zusammengefassten Pushdown hier zu arbeiten. Tatsächlich zeigt der Ausführungsplan, dass alle Zeilen beim Columnstore Index Scan lokal aggregiert wurden Betreiber:

Die Plan-XML enthält ActualLocallyAggregatedRows="32256" in den Laufzeitinformationen für den Index-Scan.
Test 2:Kein Pushdown, 12-Bit Impure Keys
Dieser Test ändert die @values Parameter auf 1025, wobei @dupes beibehalten wird bei 63. Dies ergibt eine Tabelle mit 64.575 Zeilen mit 1.025 unterschiedlichen Werten in Spalte c2 läuft von 0 bis einschließlich 1024. Jeder Wert in c2 wird 63 Mal dupliziert .
SQL Server speichert den c2 Spaltendaten mit:
- Wörterbuchkodierung da es eine beträchtliche Anzahl doppelter Werte gibt.
- Kein RLE . Die Anzahl der Duplikate (63) pro Wert erreicht nicht den für RLE erforderlichen Schwellenwert von 64.
- Bit-gepackt mit Größe 12 . Die 1.025 unterschiedlichen Wörterbucheinträge passen nicht ganz in 10 Bit (2^10 =1.024). Sie würden in 11 Bit passen, aber SQL Server unterstützt diese Bit-Packing-Größe nicht, wie bereits erwähnt. Die nächstkleinere Größe ist 12 Bit. Bei Verwendung von 64-Bit-Einheiten mit harten Grenzen zum Bit-Packing konnten nicht mehr 11-Bit-Untereinheiten in 64 Bit passen als 12-Bit-Untereinheiten. In jedem Fall passen 5 Untereinheiten in eine 64-Bit-Einheit.
Der DBCC CSINDEX Ausgabe bestätigt die obige Analyse:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1024
NullValue =-1 OnDiskSize =104400 Zeilenanzahl =64575
RLE-Header:
Lob-Typ =3 RLE-Array-Anzahl (in Bezug auf native Einheiten) =2
RLE-Array-Eintragsgröße =8
RLE-Daten:
Index =0 Bitpack Array Index =0 Anzahl =64575
Index =1 Wert =0 Anzahl =0
Bitpack-Datenheader:
Bitpack-Eintragsgröße =12 Bitpack-Einheitenanzahl =12915 Bitpack-MinId =3
Bitpack-Datengröße =103320
Bitpack-Daten:
Einheit 0 Untereinheit 0 =767
Einheit 0 Untereinheit 1 =510
Einheit 0 Untereinheit 2 =254
Einheit 0 Untereinheit 3 =1021
Einheit 0 Untereinheit 4 =765
Einheit 1 Untereinheit 0 =507
Einheit 1 Untereinheit 1 =250
Einheit 1 Untereinheit 2 =1019
Einheit 1 Untereinheit 3 =761
Einheit 1 Untereinheit 4 =505
Da die unreine Gruppierungsschlüssel haben eine Größe über 10 , erwarten wir einen gruppierten zusammengefassten Pushdown nicht arbeiten hier. Dies wird durch den Ausführungsplan bestätigt, der null Zeilen lokal aggregiert zeigt beim Columnstore Index Scan Betreiber:
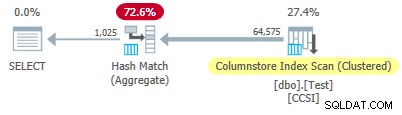
Alle 64.575 Zeilen werden (in Batches) vom Columnstore Index Scan ausgegeben und im Stapelmodus durch das Hash Match Aggregate aggregiert Operator. Die ActualLocallyAggregatedRows Attribut fehlt in den Laufzeitinformationen des XML-Plans für den Index-Scan.
Test 3:Pushdown, reine Tasten
Dieser Test ändert den @dupes Parameter von 63 bis 64, um RLE zuzulassen. Die @values Der Parameter wird auf 16.384 geändert (das Maximum für die Gesamtzahl der Zeilen, die noch in eine einzelne Zeilengruppe passen). Die genaue Zahl, die für @values gewählt wurde ist nicht wichtig – es geht darum, 64 Duplikate jedes eindeutigen Werts zu generieren, damit RLE verwendet werden kann.
SQL Server speichert den c2 Spaltendaten mit:
- Wörterbuchkodierung aufgrund der doppelten Werte.
- RLE. Wird für jeden eindeutigen Wert verwendet, da jeder den Schwellenwert von 64 erreicht.
- Keine bitgepackten Daten . Wenn es welche gäbe, würde es Größe 16 verwenden. Größe 12 ist nicht groß genug (2^12 =4.096 unterschiedliche Werte) und Größe 21 wäre verschwenderisch. Die 16.384 unterschiedlichen Werte würden in 14 Bit passen, aber wie zuvor passen nicht mehr davon in eine 64-Bit-Einheit als 16-Bit-Untereinheiten.
Der DBCC CSINDEX Ausgabe bestätigt obiges (aus Platzgründen werden nur wenige RLE-Einträge und Lesezeichen angezeigt):
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =16383
NullValue =-1 OnDiskSize =131648 Zeilenanzahl =1048576
RLE-Header:
Lob-Typ =3 RLE-Array-Anzahl (in Bezug auf native Einheiten) =16385
RLE-Array-Eintragsgröße =8
RLE-Daten:
Index =0 Wert =3 Anzahl =64
Index =1 Wert =1538 Anzahl =64
Index =2 Wert =3072 Anzahl =64
Index =3 Wert =4608 Anzahl =64
Index =4 Wert =6142 Anzahl =64
…
Index =16381 Wert =8954 Anzahl =64
Index =16382 Wert =10489 Anzahl =64
Index =16383 Wert =12025 Anzahl =64
Index =16384 Wert =0 Anzahl =0
Lesezeichen-Header:
Lesezeichenanzahl =65 Lesezeichenabstand =16384 Lesezeichengröße =520
Lesezeichendaten:
Position =0 Index =64
Position =512 Index =16448
Position =1024 Index =32832
…
Position =31744 Index =1015872
Position =32256 Index =1032256
Position =32768 Index =1048577
Bitpack-Datenheader:
Bitpack Entry Size =16 Bitpack Unit Count =0 Bitpack MinId =3
Bitpack DataSize =0
Da die Gruppierungsschlüssel rein sind (RLE wird verwendet), gruppierter Gesamt-Pushdown wird hier erwartet. Der Ausführungsplan bestätigt dies, indem er alle Zeilen lokal aggregiert anzeigt beim Columnstore Index Scan Betreiber:
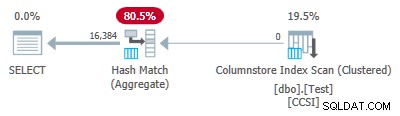
Die Plan-XML enthält ActualLocallyAggregatedRows="1048576" in den Laufzeitinformationen für den Index-Scan.
Test 4:10-bit unreine Schlüssel
Dieser Test setzt @values bis 1024 und @dupes bis 63, was eine Tabelle mit 64.512 Zeilen mit 1.024 unterschiedlichen Werten ergibt in Spalte c2 mit Werten von 0 bis einschließlich 1.023. Jeder Wert in c2 wird 63 Mal dupliziert .
Am wichtigsten , wird der b-tree gruppierte Index jetzt in Spalte c1 erstellt statt Spalte c2 . Der gruppierte Columnstore ersetzt weiterhin den gruppierten b-Tree-Index. Dies ist der geänderte Teil des Skripts:
-- Note column c1 now! CREATE CLUSTERED INDEX CCSI ON dbo.Test (c1); GO CREATE CLUSTERED COLUMNSTORE INDEX CCSI ON dbo.Test WITH (MAXDOP = 1, DROP_EXISTING = ON);
SQL Server speichert den c2 Spaltendaten mit:
- Wörterbuchkodierung aufgrund der Duplikate.
- Kein RLE . Die Anzahl der Duplikate (63) pro Wert erreicht nicht den für RLE erforderlichen Schwellenwert von 64.
- Bit-Packing mit Größe 10 . Die 1.024 verschiedenen Wörterbucheinträge passen genau in 10 Bits (2^10 =1.024). In jeder 64-Bit-Einheit können sechs Untereinheiten zu je 10 Bit gespeichert werden.
Der DBCC CSINDEX Ausgabe ist:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1023
NullValue =-1 OnDiskSize =87096 Zeilenanzahl =64512
RLE-Header:
Lob-Typ =3 RLE-Array-Anzahl (in Bezug auf native Einheiten) =2
RLE-Array-Eintragsgröße =8
RLE-Daten:
Index =0 Bitpack Array Index =0 Anzahl =64512
Index =1 Wert =0 Anzahl =0
Bitpack-Datenheader:
Bitpack-Eintragsgröße =10 Bitpack-Einheitenanzahl =10752 Bitpack-MinId =3
Bitpack-Datengröße =86016
Bitpack-Daten:
Einheit 0 Untereinheit 0 =766
Einheit 0 Untereinheit 1 =509
Einheit 0 Untereinheit 2 =254
Einheit 0 Untereinheit 3 =1020
Einheit 0 Untereinheit 4 =764
Einheit 0 Untereinheit 5 =506
Einheit 1 Untereinheit 0 =250
Einheit 1 Untereinheit 1 =1018
Einheit 1 Untereinheit 2 =760
Einheit 1 Untereinheit 3 =504
Einheit 1 Untereinheit 4 =247
Einheit 1 Untereinheit 5 =1014
Da die unreine Gruppierungsschlüssel eine Größe kleiner oder gleich 10 verwenden, würden wir einen gruppierten Gesamt-Pushdown erwarten hier zu arbeiten. Aber das ist nicht, was passiert . Der Ausführungsplan zeigt, dass 54.612 der 64.512 Zeilen beim Hash Match Aggregate aggregiert wurden Betreiber:
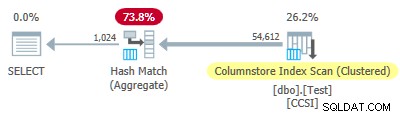
Die Plan-XML enthält ActualLocallyAggregatedRows="9900" in den Laufzeitinformationen für den Index-Scan. Dies bedeutet gruppiertes Gesamt-Pushdown wurde für 9.900 Zeilen verwendet, aber nicht für die anderen 54.612!
Der Feedback-Mechanismus
SQL Server begann mit Gruppiertem Aggregat-Pushdown für diese Ausführung, da die unreinen Gruppierungsschlüssel die 10-Bits-oder-weniger-Kriterien erfüllten. Dies dauerte insgesamt 11 Chargen (mit jeweils 900 Reihen =9.900 Reihen insgesamt). An diesem Punkt misst ein Feedback-Mechanismus die Effektivität von gruppiertem Aggregat-Pushdown entschied, dass es nicht funktionierte, und schaltete es aus . Die verbleibenden Stapel wurden alle mit deaktiviertem Pushdown verarbeitet.
Das Feedback vergleicht im Wesentlichen die Anzahl der aggregierten Zeilen mit der Anzahl der erzeugten Gruppen. Er beginnt mit einem Wert von 100 und wird am Ende jedes Pushdown-Ausgabestapels angepasst. Wenn der Wert auf 10 oder darunter fällt, wird Pushdown für den aktuellen Gruppierungsvorgang deaktiviert.
Das „Pushdown-Nutzenmaß“ wird mehr oder weniger reduziert, je nachdem, wie schlecht die Pushdown-Aggregationsbemühungen verlaufen. Wenn im Ausgabestapel im Durchschnitt weniger als 8 Zeilen pro Gruppierungsschlüssel vorhanden sind, verringert sich der aktuelle Nutzenwert um 22 %. Wenn es mehr als 8, aber weniger als 16 gibt, wird die Metrik um 11 % reduziert.
Wenn sich die Situation jedoch verbessert und anschließend 16 oder mehr Zeilen pro Gruppierungsschlüssel für einen Ausgabestapel gefunden werden, wird die Metrik auf 100 zurückgesetzt und weiterhin angepasst, wenn durch den Scan teilweise aggregierte Stapel erzeugt werden.
Die Daten in diesem Test wurden aufgrund des ursprünglichen b-tree gruppierten Indexes in Spalte c1 in einer besonders wenig hilfreichen Reihenfolge für Pushdown dargestellt . Bei dieser Darstellung werden die Werte in Spalte c2 Beginnen Sie bei 0 und erhöhen Sie um 1, bis sie 1.023 erreichen, dann beginnen sie den Zyklus erneut. Die 1.023 eindeutigen Werte sind mehr als genug, um sicherzustellen, dass jeder 900-Zeilen-Ausgabestapel nur eine teilweise aggregierte Zeile für jeden Schlüssel enthält. Das ist kein glücklicher Zustand.
Wenn statt 63 64 Duplikate pro Wert vorhanden gewesen wären, hätte SQL Server eine Sortierung nach c2 in Betracht gezogen beim Erstellen des Columnstore-Index und erzeugte so eine RLE-Komprimierung. So wie es ist, tritt die 22% Strafe nach jeder Charge ein. Beginnend bei 100 und unter Verwendung derselben Aufrundungs-Ganzzahlarithmetik lautet die Folge von Metrikwerten:
-- @metric := FLOOR(@metric * 0.78 + 0.5); -- 100, 78, 61, 48, 37, 29, 23, 18, 14, 11, *9*
Der elfte Batch reduziert die Metrik auf 10 oder weniger und Pushdown ist deaktiviert. Die 11 Batches von 900 Zeilen machen die 9.900 lokal aggregierten Zeilen aus, die im Ausführungsplan angezeigt werden.
Variante mit 900 unterschiedlichen Werten
Das gleiche Verhalten ist in Test 4 mit nur 901 unterschiedlichen Werten zu sehen, vorausgesetzt, die Zeilen werden zufällig in derselben nicht hilfreichen Reihenfolge angezeigt.
Ändern der @values Parameter auf 900 setzen, während alles andere gleich bleibt, hat einen dramatischen Effekt auf den Ausführungsplan:
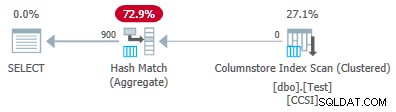
Jetzt werden alle 900 Gruppen beim Scan aggregiert! Die Eigenschaften des XML-Plans zeigen ActualLocallyAggregatedRows="56700" . Dies liegt daran, dass der Pushdown für gruppierte Aggregate 900 Gruppierungsschlüssel und Teilaggregate in einem einzigen Stapel verwaltet. Es trifft nie auf einen neuen Schlüsselwert, der nicht im Batch enthalten ist, daher gibt es keinen Grund, einen neuen Ausgabebatch zu starten.
Only ever producing one batch means the feedback mechanism never gets chance to reduce the “pushdown benefit measure” to the point where grouped aggregate pushdown is disabled. It never would anyway, since the pushdown is very successful — 56,700 rows for 900 grouping keys is 63 per key, well above the threshold for benefit measure reduction.
Extended Event
There is very little information available in execution plans to help determine why grouped aggregation pushdown was either not tried, or was not successful. There is, however, an Extended Event named query_execution_dynamic_push_down_statistics in the execution category of the Analytic channel.
It provides the following Event Fields:
rows_not_pushed_down_due_to_encoding
Description:Number of rows not pushed to scan because of the the total encoded key length.
This identifies impure data over the 10-bit limit as shown in test 2.
rows_not_pushed_down_due_to_possible_overflow
Description:Number of rows not pushed to scan because of a possible overflow
rows_not_pushed_down_due_to_pushdown_disabled
Description:Number of rows not pushed to scan (only) because dynamic pushdown was disabled
This occurs when the pushdown benefit measure drops below 10 as described in test 4.
rows_pushed_down_in_thread
Description:Number of locally aggregated rows in thread
This corresponds with the value for ‘locally aggregated rows’ shown in execution plans.
Note: No event is recorded if grouped aggregation pushdown is specifically disabled using trace flag 9373. All types of pushdown to a nonclustered columnstore index can be specifically disabled with trace flag 9386. All types of pushdown activity can be disabled with trace flag 9354.



