Einführung
Erreichen von minimaler Protokollierung mit INSERT...SELECT kann eine komplizierte Angelegenheit sein. Die im Data Loading Performance Guide aufgeführten Überlegungen sind immer noch ziemlich umfassend, obwohl man auch SQL Server 2016, Minimale Protokollierung und Auswirkungen der Batchsize in Massenladevorgängen von Parikshit Savjani vom SQL Server Tiger Team lesen muss, um das aktualisierte Bild zu erhalten SQL Server 2016 und höher beim Massenladen in geclusterte Rowstore-Tabellen. Allerdings geht es in diesem Artikel ausschließlich darum, neue Details bereitzustellen über minimale Protokollierung beim Massenladen traditioneller (nicht „speicheroptimierter“) Heap-Tabellen mit INSERT...SELECT . Tabellen mit einem B-Baum-Cluster-Index werden im zweiten Teil dieser Serie separat behandelt.
Heap-Tabellen
Beim Einfügen von Zeilen mit INSERT...SELECT in einen Heap ohne Nonclustered-Indizes, gibt die Dokumentation allgemein an, dass solche Einfügungen minimal protokolliert werden solange ein TABLOCK Hinweis ist vorhanden. Dies spiegelt sich in den Übersichtstabellen wider, die im Leitfaden zur Leistung beim Laden von Daten enthalten sind und der Post des Tiger-Teams. Die Zusammenfassungszeilen für Heap-Tabellen ohne Indizes sind in beiden Dokumenten gleich (keine Änderungen für SQL Server 2016):

Ein expliziter TABLOCK hint ist nicht die einzige Möglichkeit, die Anforderung für Sperren auf Tabellenebene zu erfüllen . Wir können auch die "Tabellensperre beim Massenladen" setzen Option für die Zieltabelle mit sp_tableoption oder durch Aktivieren des dokumentierten Trace-Flags 715. (Hinweis:Diese Optionen reichen nicht aus, um eine minimale Protokollierung zu aktivieren, wenn INSERT...SELECT verwendet wird weil INSERT...SELECT unterstützt keine Bulk-Update-Sperren).
Das „gleichzeitig möglich“ Spalte in der Zusammenfassung gilt nur für Massenlademethoden außer INSERT...SELECT . Das gleichzeitige Laden einer Heap-Tabelle ist nicht möglich mit INSERT...SELECT . Wie im Leitfaden zur Leistung beim Laden von Daten angegeben , Massenladen mit INSERT...SELECT nimmt ein exklusives X die Tabelle sperren, nicht die Massenaktualisierung BU Sperre für gleichzeitige Massenladevorgänge erforderlich.
All das beiseite – und vorausgesetzt, es gibt keinen anderen Grund, beim Massenladen eines nicht indizierten Heaps mit TABLOCK keine minimale Protokollierung zu erwarten (oder gleichwertig) – die Einfügung möglicherweise nicht minimal protokolliert werden…
Eine Ausnahme von der Regel
Das folgende Demoskript sollte auf einer Entwicklungsinstanz in einer neuen Testdatenbank ausgeführt werden eingestellt, um den SIMPLE zu verwenden Wiederherstellungsmodell. Es lädt mit INSERT...SELECT eine Reihe von Zeilen in eine Heap-Tabelle mit TABLOCK , und Berichte zu den generierten Transaktionsprotokolldatensätzen:
CREATE TABLE dbo.TestHeap
(
id integer NOT NULL IDENTITY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- Clear the log
CHECKPOINT;
GO
-- Insert rows
INSERT dbo.TestHeap WITH (TABLOCK)
(c1)
SELECT TOP (897)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_HEAP'
AND FD.AllocUnitName = N'dbo.TestHeap'; Die Ausgabe zeigt, dass alle 897 Zeilen vollständig protokolliert wurden obwohl anscheinend alle Bedingungen für eine minimale Protokollierung erfüllt sind (aus Platzgründen werden nur einige Protokollaufzeichnungen gezeigt):
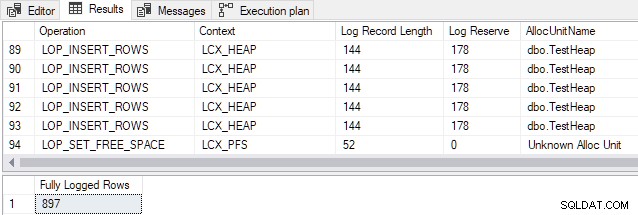
Das gleiche Ergebnis wird gesehen, wenn die Einfügung wiederholt wird (d. h. es spielt keine Rolle, ob die Heap-Tabelle leer ist oder nicht). Dieses Ergebnis widerspricht der Dokumentation.
Der minimale Logging-Schwellenwert für Heaps
Die Anzahl der Zeilen, die man in einem einzigen INSERT...SELECT hinzufügen muss -Anweisung, um eine minimale Protokollierung zu erreichen in einen nicht indizierten Heap mit aktivierter Tabellensperre, hängt von einer Berechnung ab, die SQL Server beim Schätzen der Gesamtgröße durchführt der einzufügenden Daten. Die Eingaben für diese Berechnung sind:
- Die Version von SQL Server.
- Die geschätzte Anzahl der Zeilen, die in die Einfügung führen Betreiber.
- Zeilengröße der Zieltabelle.
Für SQL Server 2012 und früher , der Übergangspunkt für diese bestimmte Tabelle ist 898 Zeilen . Ändern der Nummer im Demoskript TOP -Klausel von 897 bis 898 erzeugt die folgende Ausgabe:
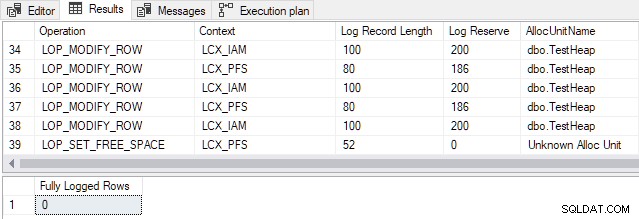
Die generierten Transaktionsprotokolleinträge betreffen die Seitenzuordnung und die Pflege der Indexzuordnungskarte (IAM) und Seitenfreier Speicherplatz (PFS)-Strukturen. Denken Sie an die minimale Protokollierung bedeutet, dass SQL Server nicht jede Zeileneinfügung einzeln protokolliert. Stattdessen werden nur Änderungen an Metadaten und Zuordnungsstrukturen protokolliert. Die Änderung von 897 auf 898 Zeilen ermöglicht eine minimale Protokollierung für diese spezielle Tabelle.
Für SQL Server 2014 und höher , liegt der Übergangspunkt bei 950 Zeilen für diesen Tisch. Ausführen von INSERT...SELECT mit TOP (949) verwendet vollständige Protokollierung – Wechsel zu TOP (950) erzeugt minimale Protokollierung .
Die Schwellenwerte sind nicht abhängig von der Kardinalitätsschätzung verwendetes Modell oder Kompatibilitätsgrad der Datenbank.
Die Berechnung der Datengröße
Ob SQL Server entscheidet, Rowset-Massenladen zu verwenden — und damit ob minimale Protokollierung verfügbar ist oder nicht – hängt vom Ergebnis einer Reihe von Berechnungen ab, die in einer Methode namens sqllang!CUpdUtil::FOptimizeInsert durchgeführt werden , die entweder true zurückgibt für minimale Protokollierung oder false für die vollständige Protokollierung. Ein Beispiel für eine Aufrufliste ist unten dargestellt:
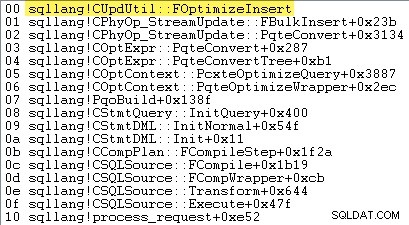
Die Essenz des Tests ist:
- Die Einfügung muss für mehr als 250 Zeilen sein .
- Die Gesamtgröße der eingefügten Daten muss mit mindestens 8 Seiten berechnet werden .
Die Prüfung auf mehr als 250 Zeilen hängt ausschließlich von der geschätzten Anzahl der Zeilen ab, die beim Table Insert ankommen Operator. Dies wird im Ausführungsplan als ‘Geschätzte Anzahl an Zeilen’ angezeigt . Seien Sie vorsichtig damit. Es ist einfach, einen Plan mit einer niedrigen geschätzten Anzahl von Zeilen zu erstellen, indem Sie beispielsweise eine Variable im TOP verwenden Klausel ohne OPTION (RECOMPILE) . In diesem Fall schätzt der Optimierer 100 Zeilen, die den Schwellenwert nicht erreichen, und verhindert so Massenladen und minimale Protokollierung.
Die Berechnung der Gesamtdatengröße ist komplexer und stimmt nicht überein die "Geschätzte Zeilengröße" fließt in die Tabelleneinlage Operator. Die Art und Weise, wie die Berechnung durchgeführt wird, unterscheidet sich geringfügig in SQL Server 2012 und früher im Vergleich zu SQL Server 2014 und höher. Dennoch erzeugen beide ein Zeilengrößenergebnis, das sich von dem unterscheidet, was im Ausführungsplan angezeigt wird.
Die Zeilengrößenberechnung
Die Gesamtgröße der eingefügten Daten wird durch Multiplizieren der geschätzten Anzahl von Zeilen berechnet durch die erwartete maximale Zeilengröße . Die Berechnung der Zeilengröße ist der Punkt, der sich zwischen den SQL Server-Versionen unterscheidet.
In SQL Server 2012 und früher wird die Berechnung von sqllang!OptimizerUtil::ComputeRowLength durchgeführt . Für die Test-Heap-Tabelle (absichtlich mit einfachen Nicht-Null-Spalten mit fester Länge unter Verwendung der ursprünglichen FixedVar Zeilenspeicherformat) ein Überblick über die Berechnung:
- Initialisieren Sie eine FixedVar Metadatengenerator.
- Erhalten Sie Typ- und Attributinformationen für jede Spalte in der Tabelleneinlage Eingabestrom.
- Typisierte Spalten und Attribute zu den Metadaten hinzufügen.
- Stellen Sie den Generator fertig und fragen Sie ihn nach der maximalen Zeilengröße.
- Overhead für die Null-Bitmap hinzufügen und Anzahl der Spalten.
- Fügen Sie vier Bytes für die Zeile Statusbits hinzu und Zeilenoffset auf die Anzahl der Spaltendaten.
Physische Zeilengröße
Es kann erwartet werden, dass das Ergebnis dieser Berechnung mit der physischen Zeilengröße übereinstimmt, dies ist jedoch nicht der Fall. Beispielsweise mit deaktivierter Zeilenversionierung für die Datenbank:
SELECT
DDIPS.index_type_desc,
DDIPS.alloc_unit_type_desc,
DDIPS.page_count,
DDIPS.record_count,
DDIPS.min_record_size_in_bytes,
DDIPS.max_record_size_in_bytes,
DDIPS.avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats
(
DB_ID(),
OBJECT_ID(N'dbo.TestHeap', N'U'),
0, -- heap
NULL, -- all partitions
'DETAILED'
) AS DDIPS; …ergibt eine Datensatzgröße von 60 Byte in jeder Zeile der Testtabelle:

Dies ist wie unter Schätzen der Größe eines Heaps beschrieben:
- Gesamtbytegröße aller fester Länge Spalten =53 Byte:
id integer NOT NULL=4 Bytec1 integer NOT NULL=4 Bytepadding char(45) NOT NULL=45 Byte.
- Null-Bitmap =3 Byte :
- =2 + int((Num_Cols + 7) / 8)
- =2 + int((3 + 7) / 8)
- =3 Byte.
- Zeilenkopf =4 Byte .
- Insgesamt 53 + 3 + 4 =60 Byte .
Es entspricht auch der geschätzten Zeilengröße, die im Ausführungsplan angezeigt wird:

Interne Berechnungsdetails
Die interne Berechnung, die verwendet wird, um zu bestimmen, ob Bulk Load verwendet wird, kommt zu einem anderen Ergebnis, basierend auf dem folgenden insert stream Spalteninformationen, die mit einem Debugger abgerufen wurden. Die verwendeten Typnummern stimmen mit sys.types überein :
- Gesamtzahl fester Länge Spaltengröße =66 Byte :
- Geben Sie die ID 173
binary(8)ein =8 Bytes (intern). - Geben Sie id 56
integerein =4 Bytes (intern). - Geben Sie id 104
bitein =1 Byte (intern). - Geben Sie id 56
integerein =4 Bytes (idSpalte). - Geben Sie id 56
integerein =4 Bytes (c1Spalte). - Geben Sie id 175
char(45)ein =45 Bytes (paddingSpalte).
- Geben Sie die ID 173
- Null-Bitmap =3 Byte (wie zuvor).
- Zeilenkopf Overhead =4 Bytes (wie zuvor).
- Berechnete Zeilengröße =66 + 3 + 4 =73 Byte .
Der Unterschied besteht darin, dass der Eingabestrom die Tabelleneinfügung speist Operator enthält drei zusätzliche interne Spalten . Diese werden entfernt, wenn Showplan generiert wird. Die zusätzlichen Spalten bilden den Locator für Tabelleneinfügungen , die das Lesezeichen (RID oder Zeilenlokator) als erste Komponente enthält. Es sind Metadaten für die Einfügung und wird nicht zur Tabelle hinzugefügt.
Die zusätzlichen Spalten erklären die Diskrepanz zwischen der von OptimizerUtil::ComputeRowLength durchgeführten Berechnung und die physische Größe der Zeilen. Dies könnte als Fehler angesehen werden :SQL Server sollte Metadatenspalten im Einfügungsstrom nicht zur endgültigen physischen Größe der Zeile zählen. Andererseits kann die Berechnung einfach eine Best-Effort-Schätzung sein, die das generische Update verwendet Betreiber.
Die Berechnung berücksichtigt auch keine anderen Faktoren wie den 14-Byte-Overhead der Zeilenversionierung. Dies kann getestet werden, indem das Demo-Skript mit einer der Snapshot-Isolierungen erneut ausgeführt wird oder festgeschriebene Snapshot-Isolation lesen Datenbankoptionen aktiviert. Die physische Größe der Zeile wird um 14 Byte erhöht (von 60 Byte auf 74 Byte), aber der Schwellenwert für minimale Protokollierung bleibt unverändert bei 898 Zeilen.
Schwellenwertberechnung
Wir haben jetzt alle Details, die wir brauchen, um zu sehen, warum der Schwellenwert für diese Tabelle auf SQL Server 2012 und früher 898 Zeilen beträgt:
- 898 Zeilen erfüllen die erste Anforderung für mehr als 250 Zeilen .
- Berechnete Zeilengröße =73 Byte.
- Geschätzte Zeilenanzahl =897.
- Gesamtdatengröße =73 Byte * 897 Zeilen =65481 Byte.
- Gesamtseiten =65481 / 8192 =7.9932861328125.
- Dies ist knapp unter der zweiten Anforderung für>=8 Seiten.
- Bei 898 Zeilen beträgt die Anzahl der Seiten 8.002197265625.
- Das sind >=8 Seiten also minimale Protokollierung aktiviert ist.
In SQL Server 2014 und höher , die Änderungen sind:
- Die Zeilengröße wird vom Metadatengenerator berechnet.
- Die interne Integer-Spalte im Tabellenfinder nicht mehr im Insert-Stream vorhanden ist. Dies repräsentiert den Uniquifier , was nur für Indizes gilt. Es scheint wahrscheinlich, dass dies als Fehlerbehebung entfernt wurde.
- Die erwartete Zeilengröße ändert sich von 73 auf 69 Byte aufgrund der weggelassenen Integer-Spalte (4 Bytes).
- Die physische Größe beträgt immer noch 60 Byte. Die verbleibende Differenz von 9 Byte wird durch die zusätzlichen 8-Byte-RID- und 1-Byte-Bit-internen Spalten im Einfügungsstrom berücksichtigt.
So erreichen Sie den Schwellenwert von 8 Seiten mit 69 Byte pro Zeile:
- 8 Seiten * 8192 Byte pro Seite =65536 Byte.
- 65535 Bytes / 69 Bytes pro Zeile =949,7971014492754 Zeilen.
- Wir erwarten daher mindestens 950 Zeilen um das Rowset-Massenladen zu aktivieren für diese Tabelle auf SQL Server 2014 und höher.
Zusammenfassung und abschließende Gedanken
Im Gegensatz zu Massenlademethoden, die Stapelgröße unterstützen , wie im Beitrag von Parikshit Savjani behandelt, INSERT...SELECT in einen nicht indizierten Heap (leer oder nicht) funktioniert nicht immer führen zu einer minimalen Protokollierung, wenn die Tabellensperre angegeben ist.
Minimale Protokollierung mit INSERT...SELECT aktivieren , muss SQL Server mit mehr als 250 Zeilen rechnen mit einer Gesamtgröße von mindestens einem Extent (8 Seiten).
Beim Berechnen der geschätzten Gesamteinfügungsgröße (zum Vergleich mit dem Schwellenwert von 8 Seiten) multipliziert SQL Server die geschätzte Anzahl von Zeilen mit einer berechneten maximalen Zeilengröße. SQL Server zählt interne Spalten im Einfügungsstrom vorhanden, wenn die Zeilengröße berechnet wird. Für SQL Server 2012 und früher werden dadurch 13 Bytes pro Zeile hinzugefügt. Für SQL Server 2014 und höher werden 9 Bytes pro Zeile hinzugefügt. Dies wirkt sich nur auf die Berechnung aus; es wirkt sich nicht auf die endgültige physische Größe der Zeilen aus.
Wenn das minimal protokollierte Heap-Massenladen aktiv ist, tut SQL Server dies nicht Zeilen einzeln einfügen. Extents werden im Voraus zugewiesen, und einzufügende Zeilen werden von sqlmin!RowsetBulk zu ganz neuen Seiten gesammelt bevor sie der bestehenden Struktur hinzugefügt werden. Ein Beispiel für eine Aufrufliste ist unten dargestellt:
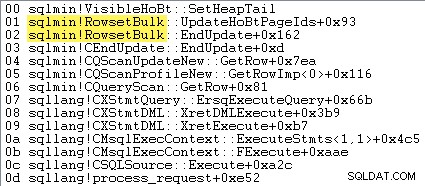
Logische Lesevorgänge werden nicht gemeldet für die Zieltabelle, wenn das minimal protokollierte Heap-Massenladen verwendet wird – die Table Insert Der Operator muss keine vorhandene Seite lesen, um den Einfügepunkt für jede neue Zeile zu finden.
Ausführungspläne werden derzeit nicht angezeigt wie viele Zeilen oder Seiten mit Rowset-Massenladen eingefügt wurden und minimale Protokollierung . Vielleicht werden diese nützlichen Informationen dem Produkt in einer zukünftigen Version hinzugefügt.