Der ANY Aggregat können wir nicht direkt in Transact SQL schreiben. Es handelt sich um eine ausschließlich interne Funktion, die vom Abfrageoptimierer und der Ausführungs-Engine verwendet wird.
Ich persönlich mag ANY sehr Aggregat, daher war es ein bisschen enttäuschend zu erfahren, dass es auf ziemlich grundlegende Weise kaputt ist. Der besondere Geschmack von „kaputt“, auf den ich mich hier beziehe, ist die Variante mit falschen Ergebnissen.
In diesem Beitrag schaue ich mir zwei bestimmte Stellen an, an denen der ANY Aggregat häufig auftaucht, zeigt das Problem mit falschen Ergebnissen und schlägt gegebenenfalls Problemumgehungen vor.
Für Hintergrundinformationen zu ANY Aggregat finden Sie in meinem vorherigen Beitrag Undocumented Query Plans:The ANY Aggregate.
1. Eine Zeile pro Gruppenabfrage
Dies muss eine der häufigsten täglichen Abfrageanforderungen mit einer sehr bekannten Lösung sein. Wahrscheinlich schreiben Sie diese Art von Abfrage jeden Tag automatisch nach dem Muster, ohne wirklich darüber nachzudenken.
Die Idee ist, den Eingabesatz von Zeilen mit ROW_NUMBER zu nummerieren Fensterfunktion, partitioniert durch die Gruppierungsspalte oder -spalten. Das ist in einen allgemeinen Tabellenausdruck verpackt oder abgeleitete Tabelle , und nach unten zu Zeilen gefiltert, bei denen die berechnete Zeilennummer gleich eins ist. Seit ROW_NUMBER beginnt bei eins für jede Gruppe neu, dies gibt uns die erforderliche eine Zeile pro Gruppe.
Es gibt kein Problem mit diesem allgemeinen Muster. Der Typ einer Zeile pro Gruppenabfrage, die dem ANY unterliegt Das Gesamtproblem ist dasjenige, bei dem es uns egal ist, welche Zeile ausgewählt wird aus jeder Gruppe.
In diesem Fall ist nicht klar, welche Spalte im obligatorischen ORDER BY verwendet werden soll -Klausel von ROW_NUMBER Fensterfunktion. Schließlich ist es uns ausdrücklich egal welche Zeile ausgewählt ist. Ein gängiger Ansatz ist die Wiederverwendung von PARTITION BY Spalte(n) in ORDER BY Klausel. Hier könnte das Problem auftreten.
Beispiel
Sehen wir uns ein Beispiel mit einem Spielzeugdatensatz an:
CREATE TABLE #Data
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL
);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, NULL, 1),
(1, 1, NULL),
(1, 111, 111),
-- Group 2
(2, NULL, 2),
(2, 2, NULL),
(2, 222, 222);
Die Anforderung besteht darin, eine vollständige Datenzeile aus jeder Gruppe zurückzugeben, wobei die Gruppenmitgliedschaft durch den Wert in Spalte c1 definiert ist .

Nach ROW_NUMBER Muster, könnten wir eine Abfrage wie die folgende schreiben (beachten Sie die ORDER BY -Klausel von ROW_NUMBER Fensterfunktion stimmt mit PARTITION BY überein Klausel):
WITH
Numbered AS
(
SELECT
D.*,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM #Data AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Wie dargestellt, wird diese Abfrage erfolgreich mit korrekten Ergebnissen ausgeführt. Die Ergebnisse sind technisch gesehen nicht deterministisch da SQL Server jede der Zeilen in jeder Gruppe gültig zurückgeben könnte. Wenn Sie diese Abfrage jedoch selbst ausführen, sehen Sie höchstwahrscheinlich das gleiche Ergebnis wie ich:
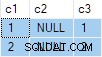
Der Ausführungsplan hängt von der verwendeten Version von SQL Server ab und nicht vom Kompatibilitätsgrad der Datenbank.
Auf SQL Server 2014 und früher lautet der Plan:

Für SQL Server 2016 oder höher sehen Sie:

Beide Pläne sind sicher, aber aus unterschiedlichen Gründen. Die Eindeutige Sortierung Plan enthält einen ANY aggregiert, sondern die Distinct Sort Operatorimplementierung zeigt den Fehler nicht.
Der komplexere Plan für SQL Server 2016+ verwendet den ANY nicht überhaupt aggregieren. Die Sortierung bringt die Zeilen in die für die Zeilennummerierung benötigte Reihenfolge. Das Segment Der Operator setzt am Anfang jeder neuen Gruppe ein Flag. Das Sequenzprojekt berechnet die Zeilennummer. Schließlich der Filter -Operator übergibt nur die Zeilen, die eine berechnete Zeilennummer von eins haben.
Der Fehler
Um mit diesem Datensatz falsche Ergebnisse zu erhalten, müssen wir SQL Server 2014 oder früher und den ANY verwenden Aggregate müssen in einem Stream Aggregate implementiert werden oder Eager Hash Aggregate Operator (Flow Distinct Hash Match Aggregate erzeugt den Fehler nicht).
Eine Möglichkeit, den Optimierer zu ermutigen, ein Stream-Aggregat auszuwählen statt Eindeutige Sortierung besteht darin, einen gruppierten Index hinzuzufügen, um eine Sortierung nach Spalte c1 bereitzustellen :
CREATE CLUSTERED INDEX c ON #Data (c1);ERSTELLEN
Nach dieser Änderung wird der Ausführungsplan zu:

Der ANY Aggregate sind in den Eigenschaften sichtbar Fenster, wenn das Stream Aggregate Betreiber ist ausgewählt:

Das Ergebnis der Abfrage ist:
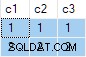
Das ist falsch . SQL Server hat Zeilen zurückgegeben, die nicht vorhanden sind in den Quelldaten. Es gibt keine Quellzeilen mit c2 = 1 und c3 = 1 zum Beispiel. Zur Erinnerung, die Quelldaten sind:
Der Ausführungsplan berechnet fälschlicherweise separate ANY Aggregate für c2 und c3 Spalten, wobei Nullen ignoriert werden. Jedes aggregiert unabhängig gibt die erste Nicht-Null zurück Wert, auf den es stößt, was ein Ergebnis liefert, bei dem die Werte für c2 und c3 stammen aus verschiedenen Quellzeilen . Dies ist nicht das, was die ursprüngliche SQL-Abfragespezifikation verlangt hat.
Dasselbe falsche Ergebnis kann mit oder ohne erzeugt werden den Clustered-Index durch Hinzufügen einer OPTION (HASH GROUP) Hinweis zum Erstellen eines Plans mit einem Eager Hash Aggregate anstelle eines Stream-Aggregats .
Bedingungen
Dieses Problem kann nur auftreten, wenn mehrere ANY Aggregate vorhanden sind und die aggregierten Daten Nullen enthalten. Wie bereits erwähnt, betrifft das Problem nur Stream Aggregate und Eager Hash Aggregate Operatoren; Eindeutige Sortierung und Flow Distinct sind nicht betroffen.
Ab SQL Server 2016 wird versucht, die Einführung mehrerer ANY zu vermeiden Aggregate für das Abfragemuster für die Zeilennummerierung einer Zeile pro Gruppe, wenn die Quellspalten nullfähig sind. In diesem Fall enthält der Ausführungsplan Segment , Sequenzprojekt und Filtern Operatoren anstelle eines Aggregats. Diese Planform ist immer sicher, da kein ANY Aggregate verwendet werden.
Reproduktion des Fehlers in SQL Server 2016+
Der SQL Server-Optimierer ist nicht perfekt darin, zu erkennen, wann eine Spalte ursprünglich auf NOT NULL beschränkt war kann durch Datenmanipulationen immer noch einen Null-Zwischenwert erzeugen.
Um dies zu reproduzieren, beginnen wir mit einer Tabelle, in der alle Spalten als NOT NULL deklariert sind :
IF OBJECT_ID(N'tempdb..#Data', N'U') IS NOT NULL
BEGIN
DROP TABLE #Data;
END;
CREATE TABLE #Data
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL
);
CREATE CLUSTERED INDEX c ON #Data (c1);
INSERT #Data
(c1, c2, c3)
VALUES
-- Group 1
(1, 1, 1),
(1, 2, 2),
(1, 3, 3),
-- Group 2
(2, 1, 1),
(2, 2, 2),
(2, 3, 3);
Wir können aus diesem Datensatz auf viele Arten Nullen erzeugen, von denen der Optimierer die meisten erfolgreich erkennen kann, und vermeiden so die Einführung von ANY Aggregate während der Optimierung.
Eine Möglichkeit, Nullen hinzuzufügen, die zufällig unter das Radar rutschen, wird unten gezeigt:
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2; Diese Abfrage erzeugt die folgende Ausgabe:
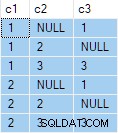
Der nächste Schritt besteht darin, diese Abfragespezifikation als Quelldaten für die Standardabfrage „jede Zeile pro Gruppe“ zu verwenden:
WITH
SneakyNulls AS
(
-- Introduce nulls the optimizer can't see
SELECT
D.c1,
OA1.c2,
OA2.c3
FROM #Data AS D
OUTER APPLY (SELECT D.c2 WHERE D.c2 <> 1) AS OA1
OUTER APPLY (SELECT D.c3 WHERE D.c3 <> 2) AS OA2
),
Numbered AS
(
SELECT
D.c1,
D.c2,
D.c3,
rn = ROW_NUMBER() OVER (
PARTITION BY D.c1
ORDER BY D.c1)
FROM SneakyNulls AS D
)
SELECT
N.c1,
N.c2,
N.c3
FROM Numbered AS N
WHERE
N.rn = 1; Auf jeder Version von SQL Server, der den folgenden Plan erstellt:
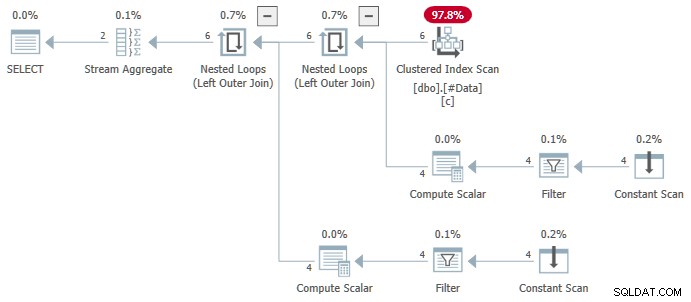
Das Stream-Aggregat enthält mehrere ANY aggregiert, und das Ergebnis ist falsch . Keine der zurückgegebenen Zeilen erscheint im Quelldatensatz:
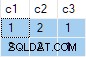
db<>Fiddle-Online-Demo
Problemumgehung
Die einzige vollständig zuverlässige Problemumgehung, bis dieser Fehler behoben ist, besteht darin, das Muster zu vermeiden, bei dem die ROW_NUMBER hat dieselbe Spalte in ORDER BY -Klausel wie in PARTITION BY Klausel.
Wenn es uns egal ist, welche eine Zeile aus jeder Gruppe ausgewählt ist, ist es bedauerlich, dass ein ORDER BY Klausel ist überhaupt erforderlich. Eine Möglichkeit, das Problem zu umgehen, besteht darin, eine Laufzeitkonstante wie ORDER BY @@SPID zu verwenden in der Fensterfunktion.
2. Nicht deterministisches Update
Das Problem mit mehreren ANY Aggregate für Nullable-Eingaben ist nicht auf das Abfragemuster „Eine Zeile pro Gruppe“ beschränkt. Der Abfrageoptimierer kann einen internen ANY einführen aggregieren in einer Reihe von Umständen. Einer dieser Fälle ist ein nicht-deterministisches Update.
Eine nicht deterministische update ist, wo die Anweisung nicht garantiert, dass jede Zielzeile höchstens einmal aktualisiert wird. Mit anderen Worten, es gibt mehrere Quellzeilen für mindestens eine Zielzeile. Die Dokumentation warnt ausdrücklich davor:
Seien Sie vorsichtig, wenn Sie die FROM-Klausel angeben, um die Kriterien für den Aktualisierungsvorgang bereitzustellen.Die Ergebnisse einer UPDATE-Anweisung sind undefiniert, wenn die Anweisung eine FROM-Klausel enthält, die nicht so angegeben ist, dass nur ein Wert für jedes aktualisierte Spaltenvorkommen verfügbar ist, d ist, wenn die UPDATE-Anweisung nicht deterministisch ist.
Um eine nicht deterministische Aktualisierung zu handhaben, gruppiert der Optimierer die Zeilen nach einem Schlüssel (Index oder RID) und wendet ANY an Aggregate zu den verbleibenden Spalten. Die Grundidee besteht darin, eine Zeile aus mehreren Kandidaten auszuwählen und Werte aus dieser Zeile zu verwenden, um die Aktualisierung durchzuführen. Es gibt offensichtliche Parallelen zum vorherigen ROW_NUMBER Daher ist es nicht verwunderlich, dass es recht einfach ist, ein falsches Update nachzuweisen.
Im Gegensatz zur vorherigen Ausgabe unternimmt SQL Server derzeit keine besonderen Schritte um mehrfaches ANY zu vermeiden Aggregate für Nullable-Spalten, wenn eine nicht deterministische Aktualisierung durchgeführt wird. Das Folgende bezieht sich daher auf alle SQL-Server-Versionen , einschließlich SQL Server 2019 CTP 3.0.
Beispiel
DECLARE @Target table
(
c1 integer PRIMARY KEY,
c2 integer NOT NULL,
c3 integer NOT NULL
);
DECLARE @Source table
(
c1 integer NULL,
c2 integer NULL,
c3 integer NULL,
INDEX c CLUSTERED (c1)
);
INSERT @Target
(c1, c2, c3)
VALUES
(1, 0, 0);
INSERT @Source
(c1, c2, c3)
VALUES
(1, 2, NULL),
(1, NULL, 3);
UPDATE T
SET T.c2 = S.c2,
T.c3 = S.c3
FROM @Target AS T
JOIN @Source AS S
ON S.c1 = T.c1;
SELECT * FROM @Target AS T; db<>Fiddle-Online-Demo
Logischerweise sollte dieses Update immer einen Fehler erzeugen:Die Zieltabelle erlaubt in keiner Spalte Nullen. Unabhängig davon, welche übereinstimmende Zeile aus der Quelltabelle ausgewählt wird, wird versucht, die Spalte c2 zu aktualisieren oder c3 auf null muss auftreten.
Leider ist die Aktualisierung erfolgreich und der Endzustand der Zieltabelle stimmt nicht mit den bereitgestellten Daten überein:
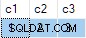
Ich habe dies als Fehler gemeldet. Die Problemumgehung besteht darin, das Schreiben von nicht deterministischem UPDATE zu vermeiden Anweisungen, also ANY Aggregate werden nicht benötigt, um die Mehrdeutigkeit aufzulösen.
Wie bereits erwähnt, kann SQL Server ANY einführen Aggregate unter mehr Umständen als in den beiden hier angegebenen Beispielen. Wenn dies passiert, wenn die aggregierte Spalte Nullen enthält, besteht die Möglichkeit falscher Ergebnisse.