Dieser Artikel ist der zweite in einer Reihe über T-SQL-Bugs, Fallstricke und Best Practices. Dieses Mal konzentriere ich mich auf klassische Fehler, die Unterabfragen betreffen. Insbesondere behandle ich Substitutionsfehler und dreiwertige Logikprobleme. Einige der Themen, die ich in der Serie behandle, wurden von anderen MVPs in einer Diskussion vorgeschlagen, die wir zu diesem Thema hatten. Danke an Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man und Paul White für Ihre Vorschläge!
Substitutionsfehler
Um den klassischen Substitutionsfehler zu demonstrieren, verwende ich ein einfaches Kundenbestellungsszenario. Führen Sie den folgenden Code aus, um eine Hilfsfunktion namens GetNums zu erstellen und die Tabellen Customers und Orders zu erstellen und zu füllen:
SET NOCOUNT ON;
USE tempdb;
GO
DROP TABLE IF EXISTS dbo.Orders;
DROP TABLE IF EXISTS dbo.Customers;
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
CREATE TABLE dbo.Customers
(
custid INT NOT NULL
CONSTRAINT PK_Customers PRIMARY KEY,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100);
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
customerid INT NOT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (customerid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_customerid ON dbo.Orders(customerid); Derzeit enthält die Customers-Tabelle 100 Kunden mit aufeinanderfolgenden Kunden-IDs im Bereich von 1 bis 100. 98 dieser Kunden haben entsprechende Bestellungen in der Orders-Tabelle. Kunden mit den IDs 17 und 59 haben noch keine Bestellungen aufgegeben und sind daher nicht in der Tabelle „Bestellungen“ enthalten.
Sie suchen nur nach Kunden, die Bestellungen aufgegeben haben, und Sie versuchen, dies mit der folgenden Abfrage zu erreichen (nennen Sie sie Abfrage 1):
SET NOCOUNT OFF; SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT custid FROM dbo.Orders);
Sie sollten 98 Kunden zurückgewinnen, aber stattdessen erhalten Sie alle 100 Kunden, einschließlich derer mit den IDs 17 und 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 17 Cust 17 18 Cust 18 ... 58 Cust 58 59 Cust 59 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (100 rows affected)
Kannst du herausfinden, was falsch ist?
Um die Verwirrung noch zu verstärken, sehen Sie sich den Plan für Abfrage 1 an, wie in Abbildung 1 gezeigt.
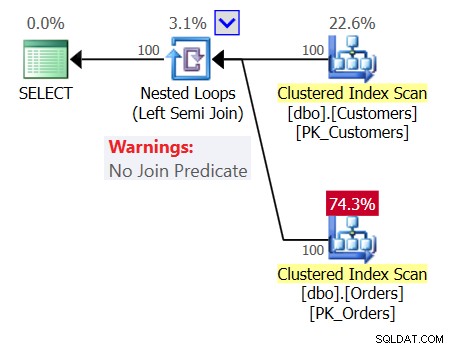 Abbildung 1:Plan für Abfrage 1
Abbildung 1:Plan für Abfrage 1
Der Plan zeigt einen Nested Loops (Left Semi Join)-Operator ohne Join-Prädikat, was bedeutet, dass die einzige Bedingung für die Rückgabe eines Kunden eine nicht leere Orders-Tabelle ist, als ob die von Ihnen geschriebene Abfrage die folgende wäre:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Sie haben wahrscheinlich einen ähnlichen Plan wie in Abbildung 2 erwartet.
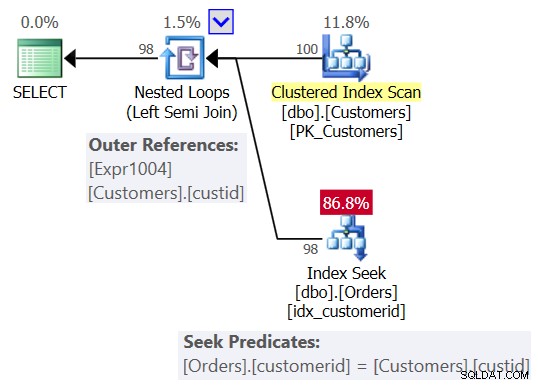 Abbildung 2:Erwarteter Plan für Abfrage 1
Abbildung 2:Erwarteter Plan für Abfrage 1
In diesem Plan sehen Sie einen Nested Loops (Left Semi Join)-Operator mit einem Scan des gruppierten Indexes für Kunden als äußere Eingabe und einer Suche im Index für die Spalte customerid in den Bestellungen als innere Eingabe. Sie sehen auch eine äußere Referenz (korrelierter Parameter) basierend auf der Spalte custid in Customers und das Suchprädikat Orders.customerid =Customers.custid.
Warum erhalten Sie also den Plan in Abbildung 1 und nicht den in Abbildung 2? Wenn Sie es noch nicht herausgefunden haben, sehen Sie sich die Definitionen beider Tabellen – insbesondere die Spaltennamen – und die in der Abfrage verwendeten Spaltennamen genau an. Sie werden feststellen, dass die Customers-Tabelle Kunden-IDs in einer Spalte namens custid und die Orders-Tabelle Kunden-IDs in einer Spalte namens customerid enthält. Der Code verwendet jedoch custid sowohl in der äußeren als auch in der inneren Abfrage. Da der Verweis auf custid in der inneren Abfrage nicht qualifiziert ist, muss SQL Server auflösen, aus welcher Tabelle die Spalte stammt. Gemäß dem SQL-Standard soll SQL Server zuerst nach der Spalte in der Tabelle suchen, die im selben Bereich abgefragt wird, aber da es in Orders keine Spalte namens custid gibt, soll er sie dann in der äußeren Tabelle suchen Umfang, und dieses Mal gibt es eine Übereinstimmung. So wird der Verweis auf custid unbeabsichtigt implizit zu einem korrelierten Verweis, als ob Sie die folgende Abfrage geschrieben hätten:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT Customers.custid FROM dbo.Orders);
Vorausgesetzt, dass Orders nicht leer ist und dass der äußere Custid-Wert nicht NULL ist (kann in unserem Fall nicht sein, da die Spalte als NOT NULL definiert ist), erhalten Sie immer eine Übereinstimmung, weil Sie den Wert mit sich selbst vergleichen . Abfrage 1 wird also zum Äquivalent von:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Wenn die äußere Tabelle NULL-Werte in der Spalte custid unterstützen würde, wäre Abfrage 1 äquivalent gewesen zu:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders) AND custid IS NOT NULL;
Jetzt verstehen Sie, warum Abfrage 1 mit dem Plan in Abbildung 1 optimiert wurde und warum Sie alle 100 Kunden zurückgewonnen haben.
Vor einiger Zeit besuchte ich einen Kunden, der einen ähnlichen Fehler hatte, aber leider mit einer DELETE-Anweisung. Denken Sie einen Moment darüber nach, was das bedeutet. Alle Tabellenzeilen wurden gelöscht und nicht nur die, die ursprünglich gelöscht werden sollten!
Was die bewährten Methoden betrifft, die Ihnen helfen können, solche Fehler zu vermeiden, gibt es zwei Hauptmethoden. Stellen Sie zunächst sicher, dass Sie, soweit Sie dies kontrollieren können, konsistente Spaltennamen in allen Tabellen für Attribute verwenden, die dasselbe darstellen. Stellen Sie zweitens sicher, dass Sie Spaltenreferenzen in Unterabfragen als Tabelle qualifizieren, auch in eigenständigen Abfragen, wo dies nicht üblich ist. Natürlich können Sie Tabellenaliase verwenden, wenn Sie lieber keine vollständigen Tabellennamen verwenden möchten. Wenn Sie diese Vorgehensweise auf unsere Abfrage anwenden, nehmen Sie an, dass Ihr erster Versuch den folgenden Code verwendet hat:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.custid FROM dbo.Orders AS O);
Hier erlauben Sie keine implizite Auflösung von Spaltennamen und daher generiert SQL Server den folgenden Fehler:
Msg 207, Level 16, State 1, Line 108 Invalid column name 'custid'.
Sie gehen und überprüfen die Metadaten für die Orders-Tabelle, stellen fest, dass Sie den falschen Spaltennamen verwendet haben, und korrigieren die Abfrage (nennen Sie diese Abfrage 2), wie folgt:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.customerid FROM dbo.Orders AS O);
Diesmal erhalten Sie die richtige Ausgabe mit 98 Kunden, ausgenommen die Kunden mit den IDs 17 und 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 18 Cust 18 .. 58 Cust 58 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (98 rows affected)
Sie erhalten auch den erwarteten Plan, der zuvor in Abbildung 2 gezeigt wurde.
Abgesehen davon ist klar, warum Customers.custid eine äußere Referenz (korrelierter Parameter) im Operator Nested Loops (Left Semi Join) in Abbildung 2 ist. Weniger offensichtlich ist, warum Expr1004 im Plan auch als äußere Referenz erscheint. Paul White, MVP von SQL Server, vermutet, dass dies damit zusammenhängen könnte, dass Informationen aus dem Blatt der äußeren Eingabe verwendet werden, um der Speicher-Engine Hinweise zu geben, um doppelten Aufwand durch die Read-Ahead-Mechanismen zu vermeiden. Die Details finden Sie hier.
Problem mit dreiwertiger Logik
Ein häufiger Fehler bei Unterabfragen hat mit Fällen zu tun, in denen die äußere Abfrage das NOT IN-Prädikat verwendet und die Unterabfrage möglicherweise NULL-Werte unter ihren Werten zurückgeben kann. Angenommen, Sie müssen in der Lage sein, Bestellungen in unserer Orders-Tabelle mit einer NULL als Kunden-ID zu speichern. Ein solcher Fall würde eine Bestellung darstellen, die keinem Kunden zugeordnet ist; zum Beispiel eine Bestellung, die Inkonsistenzen zwischen den tatsächlichen Produktzählungen und den in der Datenbank aufgezeichneten Zählungen ausgleicht.
Verwenden Sie den folgenden Code, um die Orders-Tabelle mit der custid-Spalte neu zu erstellen, die NULL-Werte zulässt, und füllen Sie sie vorerst mit den gleichen Beispieldaten wie zuvor (mit Bestellungen nach Kunden-IDs 1 bis 100, außer 17 und 59):
DROP TABLE IF EXISTS dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
custid INT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (custid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_custid ON dbo.Orders(custid); Beachten Sie, dass ich, wo wir gerade dabei sind, die im vorherigen Abschnitt besprochene bewährte Methode befolgt habe, um konsistente Spaltennamen in allen Tabellen für dieselben Attribute zu verwenden, und die Spalte in der Orders-Tabelle custid genauso wie in der Customers-Tabelle benannt habe.
Angenommen, Sie müssen eine Abfrage schreiben, die Kunden zurückgibt, die keine Bestellungen aufgegeben haben. Sie finden die folgende vereinfachte Lösung mit dem Prädikat NOT IN (nennen Sie es Abfrage 3, erste Ausführung):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Diese Abfrage gibt die erwartete Ausgabe mit den Kunden 17 und 59 zurück:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Im Lager des Unternehmens wird eine Bestandsaufnahme durchgeführt, und es wird eine Inkonsistenz zwischen der tatsächlichen Menge eines Produkts und der in der Datenbank erfassten Menge festgestellt. Sie fügen also einen Dummy-Kompensationsauftrag hinzu, um die Inkonsistenz zu berücksichtigen. Da der Bestellung kein tatsächlicher Kunde zugeordnet ist, verwenden Sie NULL als Kunden-ID. Führen Sie den folgenden Code aus, um einen solchen Bestellkopf hinzuzufügen:
INSERT INTO dbo.Orders(custid) VALUES(NULL);
Führen Sie Abfrage 3 zum zweiten Mal aus:
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Dieses Mal erhalten Sie ein leeres Ergebnis:
custid companyname ------- ------------ (0 rows affected)
Offensichtlich stimmt etwas nicht. Sie wissen, dass die Kunden 17 und 59 keine Bestellungen aufgegeben haben, und sie erscheinen tatsächlich in der Tabelle „Kunden“, aber nicht in der Tabelle „Bestellungen“. Das Abfrageergebnis behauptet jedoch, dass es keinen Kunden gibt, der keine Bestellungen aufgegeben hat. Können Sie herausfinden, wo der Fehler liegt und wie Sie ihn beheben können?
Der Fehler hat natürlich mit der NULL in der Orders-Tabelle zu tun. Für SQL ist NULL ein Marker für einen fehlenden Wert, der einen zutreffenden Kunden darstellen könnte. SQL weiß nicht, dass NULL für uns einen fehlenden und nicht zutreffenden (irrelevanten) Kunden darstellt. Für alle Kunden in der Customers-Tabelle, die in der Orders-Tabelle vorhanden sind, findet das IN-Prädikat eine Übereinstimmung, die TRUE ergibt, und der NOT IN-Teil macht es zu FALSE, daher wird die Kundenzeile verworfen. So weit, ist es gut. Aber für die Kunden 17 und 59 ergibt das IN-Prädikat UNKNOWN, da alle Vergleiche mit Nicht-NULL-Werten FALSE ergeben und der Vergleich mit den NULL-Werten UNKNOWN ergibt. Denken Sie daran, dass SQL davon ausgeht, dass NULL jeden anwendbaren Kunden darstellen könnte, sodass der logische Wert UNKNOWN angibt, dass unbekannt ist, ob die äußere Kunden-ID gleich der inneren NULL-Kunden-ID ist. FALSCH ODER FALSCH … ODER UNBEKANNT ist UNBEKANNT. Dann ergibt der auf UNKNOWN angewendete NOT IN-Teil immer noch UNKNOWN.
In einfacheren englischen Worten haben Sie darum gebeten, Kunden zurückzugeben, die keine Bestellungen aufgegeben haben. Daher verwirft die Abfrage natürlich alle Kunden aus der Customers-Tabelle, die in der Orders-Tabelle vorhanden sind, da mit Sicherheit bekannt ist, dass sie Bestellungen aufgegeben haben. Was den Rest (17 und 59 in unserem Fall) betrifft, verwirft die Abfrage sie seit SQL, genauso wie es unbekannt ist, ob sie Bestellungen aufgegeben haben, es ist genauso unbekannt, ob sie keine Bestellungen aufgegeben haben, und der Filter braucht Gewissheit (TRUE) in um eine Zeile zurückzugeben. Was für eine Gurke!
Sobald also die erste NULL in die Orders-Tabelle gelangt, erhalten Sie von diesem Moment an immer ein leeres Ergebnis von der NOT IN-Abfrage zurück. Was ist mit Fällen, in denen Sie keine NULL-Werte in den Daten haben, aber die Spalte NULL-Werte zulässt? Wie Sie bei der ersten Ausführung von Abfrage 3 gesehen haben, erhalten Sie in einem solchen Fall das richtige Ergebnis. Vielleicht denken Sie, dass die Anwendung niemals NULL-Werte in die Daten einfügt, sodass Sie sich keine Sorgen machen müssen. Das ist aus mehreren Gründen eine schlechte Praxis. Zum einen, wenn eine Spalte so definiert ist, dass sie NULLen zulässt, ist es ziemlich sicher, dass die NULLen irgendwann dort ankommen, auch wenn sie es nicht sollen; es ist nur eine Frage der Zeit. Dies kann das Ergebnis des Imports fehlerhafter Daten, eines Fehlers in der Anwendung und anderer Gründe sein. Zum anderen muss der Optimierer, selbst wenn die Daten keine NULL-Werte enthalten, wenn die Spalte dies zulässt, die Möglichkeit berücksichtigen, dass NULL-Werte vorhanden sind, wenn er den Abfrageplan erstellt, und in unserer NOT IN-Abfrage führt dies zu einer Leistungseinbuße . Um dies zu demonstrieren, betrachten Sie den Plan für die erste Ausführung von Abfrage 3, bevor Sie die Zeile mit NULL hinzugefügt haben, wie in Abbildung 3 gezeigt.
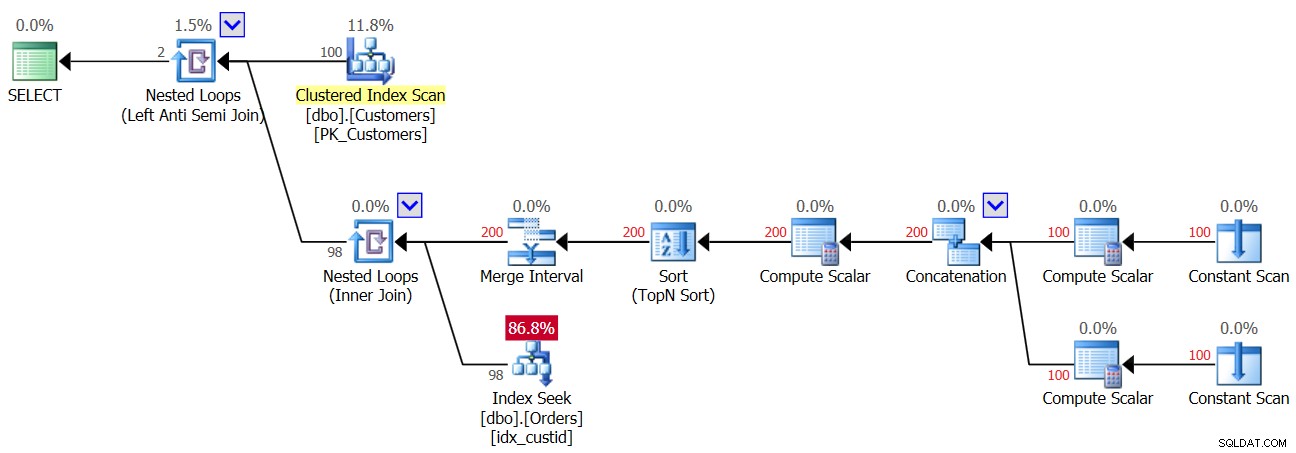 Abbildung 3:Plan für die erste Ausführung von Abfrage 3
Abbildung 3:Plan für die erste Ausführung von Abfrage 3
Der oberste Nested-Loops-Operator verarbeitet die Left-Anti-Semi-Join-Logik. Dabei geht es im Wesentlichen darum, Nichtübereinstimmungen zu identifizieren und die innere Aktivität kurzzuschließen, sobald eine Übereinstimmung gefunden wird. Der äußere Teil der Schleife zieht alle 100 Kunden aus der Customers-Tabelle, daher wird der innere Teil der Schleife 100 Mal ausgeführt.
Der innere Teil der oberen Schleife führt einen Nested Loops (Inner Join)-Operator aus. Der äußere Teil der unteren Schleife erstellt zwei Zeilen pro Kunde – eine für einen NULL-Fall und eine weitere für die aktuelle Kunden-ID, in dieser Reihenfolge. Lassen Sie sich nicht vom Merge-Intervall-Operator verwirren. Es wird normalerweise verwendet, um überlappende Intervalle zusammenzuführen, z. B. wird ein Prädikat wie col1 BETWEEN 20 AND 30 OR col1 BETWEEN 25 AND 35 in col1 BETWEEN 20 AND 35 konvertiert. Diese Idee kann verallgemeinert werden, um Duplikate in einem IN-Prädikat zu entfernen. In unserem Fall kann es eigentlich keine Duplikate geben. Vereinfacht ausgedrückt können Sie sich den äußeren Teil der Schleife, wie bereits erwähnt, so vorstellen, dass zwei Zeilen pro Kunde erstellt werden – die erste für einen NULL-Fall und die zweite für die aktuelle Kunden-ID. Dann sucht der innere Teil der Schleife zuerst im Index idx_custid nach Orders, um nach NULL zu suchen. Wenn eine NULL gefunden wird, wird die zweite Suche nach der aktuellen Kunden-ID nicht aktiviert (denken Sie an den Kurzschluss, der von der oberen Anti-Semi-Join-Schleife behandelt wird). In einem solchen Fall wird der äußere Kunde verworfen. Wenn jedoch keine NULL gefunden wird, aktiviert die untere Schleife eine zweite Suche, um nach der aktuellen Kunden-ID in Bestellungen zu suchen. Wenn er gefunden wird, wird der äußere Kunde verworfen. Wenn es nicht gefunden wird, wird der äußere Kunde zurückgegeben. Dies bedeutet, dass dieser Plan zwei Suchen pro Kunde durchführt, wenn keine NULLen in Bestellungen vorhanden sind! Dies kann im Plan als Reihenzahl 200 im äußeren Eingang der unteren Schleife beobachtet werden. Folglich sind hier die E/A-Statistiken, die für die erste Ausführung gemeldet werden:
Table 'Orders'. Scan count 200, logical reads 603
Der Plan für die zweite Ausführung von Abfrage 3, nachdem eine Zeile mit NULL zur Orders-Tabelle hinzugefügt wurde, ist in Abbildung 4 dargestellt.
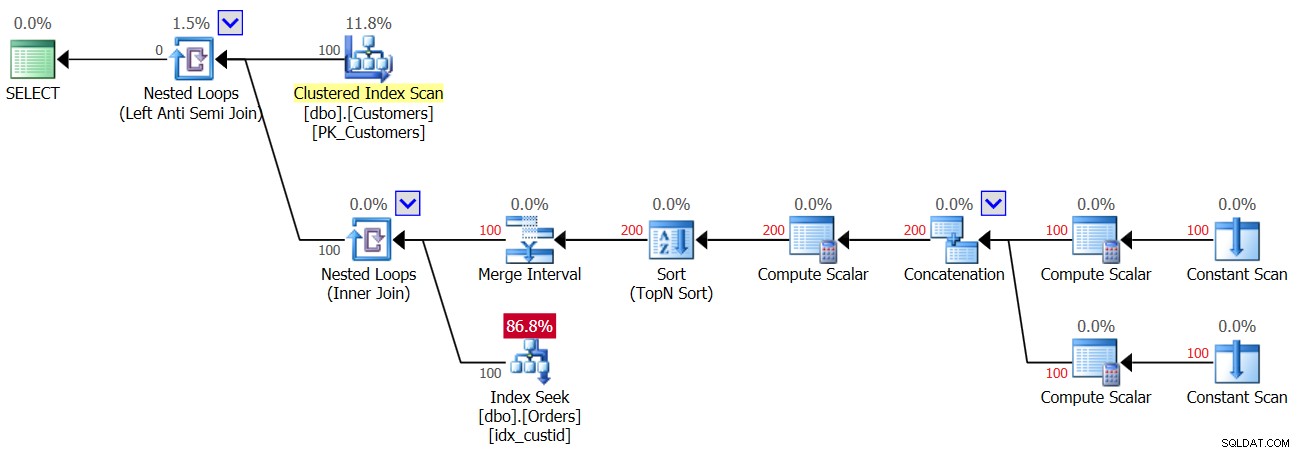 Abbildung 4:Plan für die zweite Ausführung von Abfrage 3
Abbildung 4:Plan für die zweite Ausführung von Abfrage 3
Da in der Tabelle NULL vorhanden ist, findet die erste Ausführung des Operators Index Seek für alle Kunden eine Übereinstimmung, und daher werden alle Kunden verworfen. Also juhu, wir machen nur eine Suche pro Kunde und nicht zwei, also bekommst du dieses Mal 100 Suchen und nicht 200; Dies bedeutet jedoch gleichzeitig, dass Sie ein leeres Ergebnis zurückgeben!
Hier sind die E/A-Statistiken, die für die zweite Ausführung gemeldet werden:
Table 'Orders'. Scan count 100, logical reads 300
Eine Lösung für diese Aufgabe, wenn NULLen unter den zurückgegebenen Werten in der Unterabfrage möglich sind, besteht darin, diese einfach herauszufiltern, etwa so (nennen Sie es Lösung 1/Abfrage 4):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O WHERE O.custid IS NOT NULL);
Dieser Code generiert die erwartete Ausgabe:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Der Nachteil dieser Lösung ist, dass Sie daran denken müssen, den Filter hinzuzufügen. Ich bevorzuge eine Lösung mit dem Prädikat NOT EXISTS, bei der die Unterabfrage eine explizite Korrelation hat, die die Kunden-ID der Bestellung mit der Kunden-ID vergleicht, etwa so (nennen wir es Lösung 2/Abfrage 5):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE NOT EXISTS (SELECT * FROM dbo.Orders AS O WHERE O.custid = C.custid);
Denken Sie daran, dass ein auf Gleichheit basierender Vergleich zwischen NULL und irgendetwas UNKNOWN ergibt und UNKNOWN von einem WHERE-Filter verworfen wird. Wenn also NULLen in Bestellungen vorhanden sind, werden sie vom Filter der inneren Abfrage eliminiert, ohne dass Sie eine explizite NULL-Behandlung hinzufügen müssen, und Sie müssen sich daher keine Gedanken darüber machen, ob NULLen in den Daten vorhanden sind oder nicht.
Diese Abfrage generiert die erwartete Ausgabe:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Die Pläne für beide Lösungen sind in Abbildung 5 dargestellt.
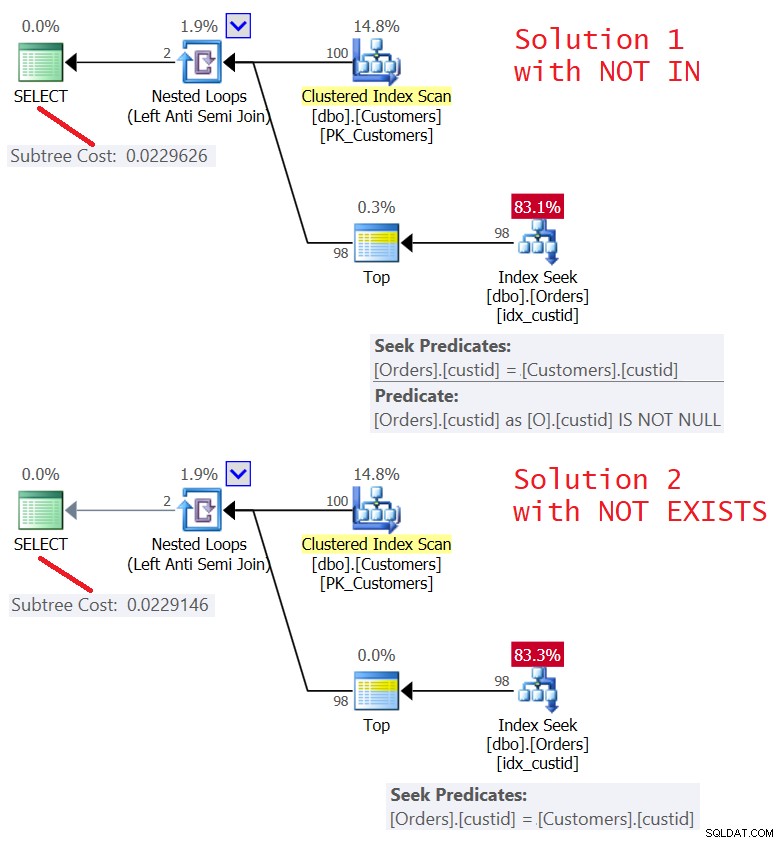 Abbildung 5:Pläne für Abfrage 4 (Lösung 1) und Abfrage 5 (Lösung 2). )
Abbildung 5:Pläne für Abfrage 4 (Lösung 1) und Abfrage 5 (Lösung 2). )
Wie Sie sehen können, sind die Pläne fast identisch. Sie sind auch ziemlich effizient, indem sie eine Left Semi Join-Optimierung mit einem Kurzschluss verwenden. Beide führen nur 100 Suchvorgänge im Index idx_custid auf Orders aus und wenden mit dem Top-Operator einen Kurzschluss an, nachdem eine Zeile im Blatt berührt wurde.
Die E/A-Statistiken für beide Abfragen sind gleich:
Table 'Orders'. Scan count 100, logical reads 348
Eine zu berücksichtigende Sache ist jedoch, ob die äußere Tabelle möglicherweise NULL-Werte in der korrelierten Spalte enthält (in unserem Fall custid). Es ist sehr unwahrscheinlich, dass es in einem Szenario wie Kundenbestellungen relevant ist, könnte aber in anderen Szenarien relevant sein. Wenn das tatsächlich der Fall ist, behandeln beide Lösungen eine äußere NULL falsch.
Um dies zu demonstrieren, löschen Sie die Customers-Tabelle und erstellen Sie sie mit NULL als eine der Kunden-IDs neu, indem Sie den folgenden Code ausführen:
DROP TABLE IF EXISTS dbo.Customers;
GO
CREATE TABLE dbo.Customers
(
custid INT NULL
CONSTRAINT UNQ_Customers_custid UNIQUE CLUSTERED,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT CAST(NULL AS INT) AS custid, 'Cust NULL' AS companyname
UNION ALL
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100); Lösung 1 gibt keine äußere NULL zurück, unabhängig davon, ob eine innere NULL vorhanden ist oder nicht.
Lösung 2 gibt eine äußere NULL zurück, unabhängig davon, ob eine innere NULL vorhanden ist oder nicht.
Wenn Sie NULLen so behandeln möchten, wie Sie Nicht-NULL-Werte behandeln, d. h. die NULL zurückgeben, wenn sie in Kunden, aber nicht in Bestellungen vorhanden ist, und sie nicht zurückgeben, wenn sie in beiden vorhanden ist, müssen Sie die Logik der Lösung ändern, um eine Unterscheidbarkeit zu verwenden -basierter Vergleich anstelle eines gleichheitsbasierten Vergleichs. Dies kann erreicht werden, indem das EXISTS-Prädikat und der EXCEPT-Set-Operator wie folgt kombiniert werden (nennen Sie dies Lösung 3/Abfrage 6):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Da derzeit NULLen sowohl in Kunden als auch in Bestellungen vorhanden sind, gibt diese Abfrage korrekterweise keine NULL zurück. Hier ist die Abfrageausgabe:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Führen Sie den folgenden Code aus, um die Zeile mit NULL aus der Orders-Tabelle zu entfernen, und führen Sie Lösung 3 erneut aus:
DELETE FROM dbo.Orders WHERE custid IS NULL; SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Da diesmal eine NULL in Customers, aber nicht in Orders vorhanden ist, enthält das Ergebnis die NULL:
custid companyname ------- ------------ NULL Cust NULL 17 Cust 17 59 Cust 59 (3 rows affected)
Der Plan für diese Lösung ist in Abbildung 6 dargestellt:
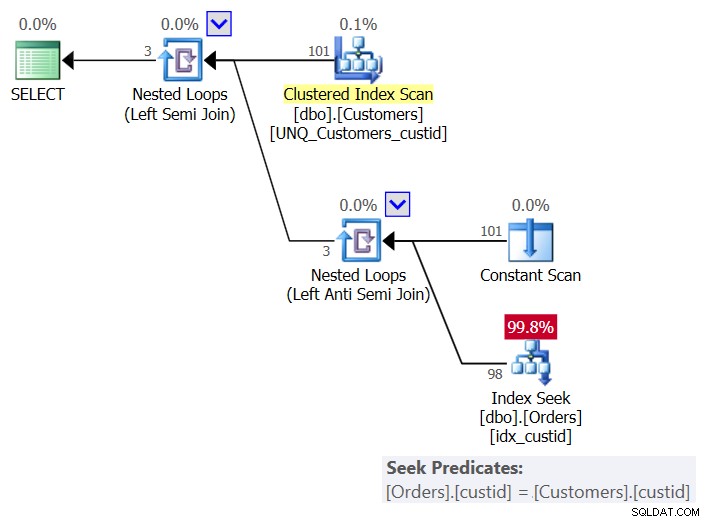 Abbildung 6:Plan für Abfrage 6 (Lösung 3)
Abbildung 6:Plan für Abfrage 6 (Lösung 3)
Der Plan verwendet pro Kunde einen Constant Scan-Operator, um eine Zeile mit dem aktuellen Kunden zu erstellen, und wendet eine einzelne Suche im Index idx_custid auf Orders an, um zu prüfen, ob der Kunde in Orders vorhanden ist. Am Ende haben Sie eine Suche pro Kunde. Da wir derzeit 101 Kunden in der Tabelle haben, erhalten wir 101 Suchanfragen.
Hier sind die E/A-Statistiken für diese Abfrage:
Table 'Orders'. Scan count 101, logical reads 415
Schlussfolgerung
Diesen Monat habe ich Unterabfrage-bezogene Fehler, Fallstricke und Best Practices behandelt. Ich behandelte Substitutionsfehler und dreiwertige Logikprobleme. Denken Sie daran, tabellenübergreifend konsistente Spaltennamen zu verwenden und Spalten in Unterabfragen immer als Tabelle zu qualifizieren, auch wenn es sich um eigenständige Spalten handelt. Denken Sie auch daran, eine NOT NULL-Einschränkung zu erzwingen, wenn die Spalte keine NULL-Werte zulassen soll, und NULL-Werte immer zu berücksichtigen, wenn sie in Ihren Daten möglich sind. Stellen Sie sicher, dass Sie NULL-Werte in Ihre Beispieldaten aufnehmen, wenn dies zulässig ist, damit Sie Fehler in Ihrem Code beim Testen leichter erkennen können. Seien Sie vorsichtig mit dem Prädikat NOT IN, wenn es mit Unterabfragen kombiniert wird. Wenn NULLen im Ergebnis der inneren Abfrage möglich sind, ist das Prädikat NOT EXISTS normalerweise die bevorzugte Alternative.