Die NULL-Behandlung ist einer der kniffligeren Aspekte der Datenmodellierung und Datenmanipulation mit SQL. Beginnen wir mit dem Versuch, genau zu erklären, was eine NULL ist ist an und für sich nicht trivial. Selbst unter Leuten, die sich gut mit relationaler Theorie und SQL auskennen, werden Sie sehr starke Meinungen sowohl für als auch gegen die Verwendung von NULL-Werten in Ihrer Datenbank hören. Ob Sie sie mögen oder nicht, als Datenbankpraktiker müssen Sie sich oft mit ihnen auseinandersetzen, und da NULLen die Komplexität Ihres SQL-Code-Schreibens erhöhen, ist es eine gute Idee, es zu einer Priorität zu machen, sie gut zu verstehen. Auf diese Weise können Sie unnötige Fehler und Fallstricke vermeiden.
Dieser Artikel ist der erste in einer Reihe über NULL-Komplexitäten. Ich beginne damit, was NULLs sind und wie sie sich in Vergleichen verhalten. Dann decke ich Inkonsistenzen in der NULL-Behandlung in verschiedenen Sprachelementen ab. Abschließend gehe ich auf fehlende Standardfunktionen im Zusammenhang mit der NULL-Behandlung in T-SQL ein und schlage Alternativen vor, die in T-SQL verfügbar sind.
Der größte Teil der Abdeckung ist für jede Plattform relevant, die einen Dialekt von SQL implementiert, aber in einigen Fällen erwähne ich Aspekte, die spezifisch für T-SQL sind.
In meinen Beispielen verwende ich eine Beispieldatenbank namens TSQLV5. Das Skript, das diese Datenbank erstellt und füllt, finden Sie hier und ihr ER-Diagramm hier.
NULL als Marker für einen fehlenden Wert
Beginnen wir damit, zu verstehen, was NULLen sind. In SQL ist NULL eine Markierung oder ein Platzhalter für einen fehlenden Wert. Es ist der Versuch von SQL, in Ihrer Datenbank eine Realität darzustellen, in der ein bestimmter Attributwert manchmal vorhanden ist und manchmal fehlt. Angenommen, Sie müssen Mitarbeiterdaten in einer Employees-Tabelle speichern. Sie haben Attribute für den Vornamen, den zweiten Vornamen und den Nachnamen. Die Attribute firstname und lastname sind obligatorisch, und daher definieren Sie sie so, dass sie keine NULL-Werte zulassen. Das Middlename-Attribut ist optional, und daher definieren Sie es so, dass es NULLen zulässt.
Wenn Sie sich fragen, was das relationale Modell über fehlende Werte zu sagen hat, hat der Schöpfer des Modells, Edgar F. Codd, an sie geglaubt. Tatsächlich unterschied er sogar zwischen zwei Arten von fehlenden Werten:Fehlend, aber anwendbar (A-Werte-Markierung) und Fehlend, aber nicht anwendbar (I-Werte-Markierung). Wenn wir das Attribut „Zweiter Vorname“ als Beispiel nehmen, würden Sie in einem Fall, in dem ein Mitarbeiter einen zweiten Vornamen hat, aber aus Datenschutzgründen beschließt, die Informationen nicht weiterzugeben, die Markierung „A-Werte“ verwenden. In einem Fall, in dem ein Mitarbeiter überhaupt keinen zweiten Vornamen hat, würden Sie die I-Werte-Markierung verwenden. Hier könnte das gleiche Attribut manchmal relevant und vorhanden sein, manchmal fehlt, aber anwendbar und manchmal fehlt, aber nicht anwendbar. Andere Fälle könnten klarer sein und nur eine Art von fehlenden Werten unterstützen. Angenommen, Sie haben eine Orders-Tabelle mit einem Attribut namens shippingdate, das das Versanddatum der Bestellung enthält. Eine versandte Bestellung hat immer ein aktuelles und relevantes Versanddatum. Der einzige Fall, in dem kein bekanntes Versanddatum vorliegt, sind Bestellungen, die noch nicht versandt wurden. Hier muss also entweder ein relevanter Versanddatumswert vorhanden sein, oder es sollte der I-Werte-Marker verwendet werden.
Die Designer von SQL haben sich entschieden, nicht auf die Unterscheidung zwischen zutreffenden und nicht zutreffenden fehlenden Werten einzugehen, und haben uns die NULL als Markierung für jede Art von fehlendem Wert zur Verfügung gestellt. Zum größten Teil wurde SQL so entwickelt, dass davon ausgegangen wird, dass NULLen die fehlenden, aber zutreffenden Werte darstellen. Folglich, insbesondere wenn Sie NULL als Platzhalter für einen nicht zutreffenden Wert verwenden, ist die standardmäßige SQL-NULL-Behandlung möglicherweise nicht diejenige, die Sie für richtig halten. Manchmal müssen Sie eine explizite NULL-Behandlungslogik hinzufügen, um die Behandlung zu erhalten, die Sie für richtig halten.
Wenn Sie wissen, dass ein Attribut keine NULL-Werte zulassen soll, stellen Sie als Best Practice sicher, dass Sie dies mit einer NOT NULL-Einschränkung als Teil der Spaltendefinition erzwingen. Dafür gibt es ein paar wichtige Gründe. Ein Grund dafür ist, dass, wenn Sie dies nicht erzwingen, an der einen oder anderen Stelle NULLen ankommen. Es könnte das Ergebnis eines Fehlers in der Anwendung oder des Imports fehlerhafter Daten sein. Wenn Sie eine Einschränkung verwenden, wissen Sie, dass NULLs niemals in die Tabelle gelangen. Ein weiterer Grund ist, dass der Optimierer Einschränkungen wie NOT NULL für eine bessere Optimierung auswertet, unnötige Arbeit beim Suchen nach NULL-Werten vermeidet und bestimmte Transformationsregeln aktiviert.
Vergleiche mit NULLen
Es gibt einige Tricks bei der Auswertung von Prädikaten durch SQL, wenn NULLs beteiligt sind. Ich werde zuerst Vergleiche mit Konstanten behandeln. Später werde ich Vergleiche mit Variablen, Parametern und Spalten behandeln.
Wenn Sie Prädikate verwenden, die Operanden in Abfrageelementen wie WHERE, ON und HAVING vergleichen, hängen die möglichen Ergebnisse des Vergleichs davon ab, ob einer der Operanden NULL sein kann. Wenn Sie mit Sicherheit wissen, dass keiner der Operanden NULL sein kann, ist das Ergebnis des Prädikats immer entweder TRUE oder FALSE. Das ist die sogenannte zweiwertige Prädikatenlogik oder kurz zweiwertige Logik. Dies ist beispielsweise der Fall, wenn Sie eine Spalte vergleichen, die so definiert ist, dass sie keine NULL-Werte zulässt, mit einem anderen Nicht-NULL-Operanden.
Wenn einer der Operanden im Vergleich eine NULL sein kann, sagen wir, eine Spalte, die NULLen zulässt, sind Sie es nun der dreiwertigen Prädikatenlogik ausgeliefert. Wenn bei einem bestimmten Vergleich die beiden Operanden zufällig Nicht-NULL-Werte sind, erhalten Sie immer noch entweder TRUE oder FALSE als Ergebnis. Wenn jedoch einer der Operanden NULL ist, erhalten Sie einen dritten logischen Wert namens UNKNOWN. Beachten Sie, dass dies auch beim Vergleich zweier NULLen der Fall ist. Die Behandlung von TRUE und FALSE durch die meisten Elemente von SQL ist ziemlich intuitiv. Die Behandlung von UNKNOWN ist nicht immer so intuitiv. Darüber hinaus behandeln verschiedene Elemente von SQL den UNKNOWN-Fall unterschiedlich, wie ich später in diesem Artikel unter „Inkonsistenzen bei der NULL-Behandlung“ ausführlich erläutern werde.
Angenommen, Sie müssen die Tabelle „Sales.Orders“ in der TSQLV5-Beispieldatenbank abfragen und Bestellungen zurücksenden, die am 2. Januar 2019 versandt wurden. Sie verwenden die folgende Abfrage:
TSQLV5 VERWENDEN; WÄHLEN Sie Bestell-ID, VersanddatumFROM Sales.OrdersWHERE Versanddatum ='20190102';
Es ist klar, dass das Filterprädikat für Zeilen, deren Versanddatum der 2. Januar 2019 ist, TRUE ergibt und dass diese Zeilen zurückgegeben werden sollten. Es ist auch klar, dass das Prädikat für Zeilen, in denen das Versanddatum vorhanden ist, aber nicht der 2. Januar 2019 ist, FALSE ergibt und dass diese Zeilen verworfen werden sollten. Aber was ist mit Zeilen mit einem NULL-Versanddatum? Denken Sie daran, dass sowohl auf Gleichheit basierende Prädikate als auch auf Ungleichheit basierende Prädikate UNKNOWN zurückgeben, wenn einer der Operanden NULL ist. Der WHERE-Filter wurde entwickelt, um solche Zeilen zu verwerfen. Denken Sie daran, dass der WHERE-Filter Zeilen zurückgibt, für die das Filterprädikat TRUE ergibt, und Zeilen verwirft, für die das Prädikat FALSE oder UNKNOWN ergibt.
Diese Abfrage generiert die folgende Ausgabe:
Bestell-ID Versanddatum---------- -----------10771 2019-01-0210794 2019-01-0210802 2019-01-02
Angenommen, Sie müssen Bestellungen zurücksenden, die am 2. Januar 2019 nicht versendet wurden. Bestellungen, die noch nicht versendet wurden, sollten Ihrer Meinung nach in die Ausgabe aufgenommen werden. Sie verwenden eine ähnliche Abfrage wie die letzte und negieren nur das Prädikat, etwa so:
SELECT orderid, shippingdateFROM Sales.OrdersWHERE NOT (shippeddate ='20190102');
Diese Abfrage gibt die folgende Ausgabe zurück:
Die Ausgabe schließt natürlich die Zeilen mit dem Versanddatum 2. Januar 2019 aus, schließt aber auch die Zeilen mit einem NULL-Versanddatum aus. Was hier kontraintuitiv sein könnte, ist, was passiert, wenn Sie den NOT-Operator verwenden, um ein Prädikat zu negieren, das UNKNOWN ergibt. Offensichtlich ist NICHT WAHR FALSCH und NICHT FALSCH ist WAHR. NICHT UNBEKANNT bleibt jedoch UNBEKANNT. Die Logik von SQL hinter diesem Design ist, dass Sie, wenn Sie nicht wissen, ob eine Proposition wahr ist, auch nicht wissen, ob die Proposition nicht wahr ist. Das bedeutet, dass bei Verwendung von Gleichheits- und Ungleichheitsoperatoren im Filterprädikat weder die positive noch die negative Form des Prädikats die Zeilen mit NULLen zurückgibt.
Dieses Beispiel ist ziemlich einfach. Es gibt schwierigere Fälle mit Unterabfragen. Es gibt einen häufigen Fehler, wenn Sie das Prädikat NOT IN mit einer Unterabfrage verwenden, wenn die Unterabfrage eine NULL unter den zurückgegebenen Werten zurückgibt. Die Abfrage gibt immer ein leeres Ergebnis zurück. Der Grund dafür ist, dass die positive Form des Prädikats (der IN-Teil) ein TRUE zurückgibt, wenn der äußere Wert gefunden wird, und UNKNOWN, wenn er aufgrund des Vergleichs mit NULL nicht gefunden wird. Dann liefert die Negation des Prädikats mit dem NOT-Operator immer FALSE bzw. UNKNOWN – niemals TRUE. Ich behandle diesen Fehler ausführlich in T-SQL-Fehler, Fallstricke und Best Practices – Unterabfragen, einschließlich vorgeschlagener Lösungen, Optimierungsüberlegungen und Best Practices. Wenn Sie mit diesem klassischen Fehler noch nicht vertraut sind, lesen Sie unbedingt diesen Artikel, da der Fehler recht häufig vorkommt und es einfache Maßnahmen gibt, die Sie ergreifen können, um ihn zu vermeiden.
Zurück zu unserem Bedarf, was ist mit dem Versuch, Bestellungen mit einem anderen Versanddatum als dem 2. Januar 2019 zurückzugeben, indem Sie den Operator „anders als“ (<>) verwenden:
SELECT Bestell-ID, VersanddatumFROM Sales.OrdersWHERE Versanddatum <> '20190102';
Unglücklicherweise liefern sowohl Gleichheits- als auch Ungleichheitsoperatoren UNKNOWN, wenn einer der Operanden NULL ist, sodass diese Abfrage wie die vorherige Abfrage die folgende Ausgabe generiert, ausschließlich der NULLen:
Um das Problem von Vergleichen mit NULL-Werten zu isolieren, die UNBEKANNT ergeben, wenn Gleichheit, Ungleichheit und Negation der beiden Arten von Operatoren verwendet werden, geben alle folgenden Abfragen eine leere Ergebnismenge zurück:
SELECT Bestell-ID, VersanddatumFROM Sales.OrdersWHERE Versanddatum =NULL; SELECT orderid, shippingdateFROM Sales.OrdersWHERE NOT (shippeddate =NULL); SELECT Bestell-ID, VersanddatumFROM Sales.OrdersWHERE Versanddatum <> NULL; SELECT orderid, shippingdateFROM Sales.OrdersWHERE NOT (shippeddate <> NULL);
Laut SQL soll man nicht prüfen, ob etwas gleich NULL oder ungleich NULL ist, sondern ob etwas NULL oder nicht NULL ist, indem man die speziellen Operatoren IS NULL bzw. IS NOT NULL verwendet. Diese Operatoren verwenden zweiwertige Logik und geben immer entweder TRUE oder FALSE zurück. Verwenden Sie beispielsweise den IS NULL-Operator, um unversendete Bestellungen wie folgt zurückzugeben:
SELECT Bestell-ID, VersanddatumFROM Sales.OrdersWHERE Versanddatum NULL;
Diese Abfrage generiert die folgende Ausgabe:
Bestell-ID Versanddatum----------- -----------11008 NULL11019 NULL11039 NULL...(21 Zeilen betroffen)
Verwenden Sie den IS NOT NULL-Operator, um versendete Bestellungen wie folgt zurückzugeben:
SELECT Bestell-ID, VersanddatumFROM Sales.OrdersWHERE Versanddatum NICHT NULL;
Diese Abfrage generiert die folgende Ausgabe:
Verwenden Sie den folgenden Code, um Bestellungen zurückzugeben, die an einem anderen Datum als dem 2. Januar 2019 versandt wurden, sowie nicht versandte Bestellungen:
SELECT Bestell-ID, LieferdatumFROM Sales.OrdersWHERE Lieferdatum <> '20190102' ODER Lieferdatum IST NULL;
Diese Abfrage generiert die folgende Ausgabe:
orderid shippingdate----------- -----------11008 NULL11019 NULL11039 NULL...10249 2017-07-1010252 2017-07-1110250 2017-07-12 ...11050 2019-05-0511055 2019-05-0511063 2019-05-0611067 2019-05-0611069 2019-05-06(827 Zeilen betroffen)
In einem späteren Teil der Serie behandle ich Standardfunktionen für die NULL-Behandlung, die derzeit in T-SQL fehlen, einschließlich des DISTINCT-Prädikats , die das NULL-Handling erheblich vereinfachen können.
Vergleiche mit Variablen, Parametern und Spalten
Der vorherige Abschnitt konzentrierte sich auf Prädikate, die eine Spalte mit einer Konstanten vergleichen. In der Realität werden Sie jedoch eine Spalte meistens mit Variablen/Parametern oder mit anderen Spalten vergleichen. Solche Vergleiche beinhalten weitere Komplexitäten.
Aus Sicht der NULL-Behandlung werden Variablen und Parameter gleich behandelt. Ich werde in meinen Beispielen Variablen verwenden, aber die Punkte, die ich zu ihrer Handhabung mache, sind für Parameter genauso relevant.
Betrachten Sie die folgende grundlegende Abfrage (ich nenne sie Abfrage 1), die Bestellungen filtert, die an einem bestimmten Datum versandt wurden:
DECLARE @dt AS DATE ='20190212'; WÄHLEN Sie Bestell-ID, VersanddatumFROM Sales.OrdersWHERE Versanddatum =@dt;
Ich verwende in diesem Beispiel eine Variable und initialisiere sie mit einem Beispieldatum, aber dies hätte genauso gut eine parametrisierte Abfrage in einer gespeicherten Prozedur oder eine benutzerdefinierte Funktion sein können.
Diese Abfrageausführung generiert die folgende Ausgabe:
Bestell-ID Versanddatum----------- -----------10865 2019-02-1210866 2019-02-1210876 2019-02-1210878 2019-02-1210879 2019- 02-12
Der Plan für Abfrage 1 ist in Abbildung 1 dargestellt.
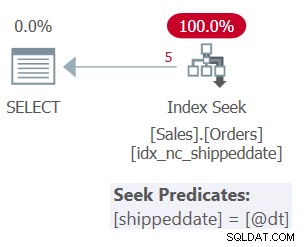 Abbildung 1:Plan für Abfrage 1
Abbildung 1:Plan für Abfrage 1
Die Tabelle hat einen abdeckenden Index, um diese Abfrage zu unterstützen. Der Index heißt idx_nc_shippeddate und wird mit der Schlüsselliste (shippeddate, orderid) definiert. Das Filterprädikat der Abfrage wird als Suchargument (SARG) ausgedrückt , was bedeutet, dass es dem Optimierer ermöglicht, eine Suchoperation im unterstützenden Index anzuwenden und direkt zum Bereich der qualifizierten Zeilen zu gehen. Was das Filterprädikat SARGable macht, ist, dass es einen Operator verwendet, der einen fortlaufenden Bereich qualifizierter Zeilen im Index darstellt, und dass es keine Manipulation auf die gefilterte Spalte anwendet. Der Plan, den Sie erhalten, ist der optimale Plan für diese Abfrage.
Aber was ist, wenn Sie Benutzern erlauben möchten, nach unversendeten Bestellungen zu fragen? Solche Bestellungen haben ein NULL-Versanddatum. Hier ist ein Versuch, NULL als Eingabedatum zu übergeben:
DECLARE @dt AS DATE =NULL; WÄHLEN Sie Bestell-ID, VersanddatumFROM Sales.OrdersWHERE Versanddatum =@dt;
Wie Sie bereits wissen, erzeugt ein Prädikat, das einen Gleichheitsoperator verwendet, UNKNOWN, wenn einer der Operanden NULL ist. Folglich gibt diese Abfrage ein leeres Ergebnis zurück:
Bestell-ID Versanddatum----------- -----------(0 Zeilen betroffen)
Obwohl T-SQL einen IS NULL-Operator unterstützt, unterstützt es keinen expliziten IS
DECLARE @dt AS DATE =NULL; SELECT orderid, shippingdateFROM Sales.OrdersWHERE ISNULL(shippeddate, '99991231') =ISNULL(@dt, '99991231');
Diese Abfrage generiert die korrekte Ausgabe:
Bestell-ID Versanddatum----------- -----------11008 NULL11019 NULL11039 NULL...11075 NULL11076 NULL11077 NULL(21 Zeilen betroffen)
Aber der Plan für diese Abfrage, wie in Abbildung 2 gezeigt, ist nicht optimal.
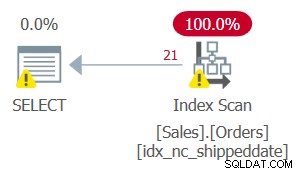 Abbildung 2:Plan für Abfrage 2
Abbildung 2:Plan für Abfrage 2
Da Sie die gefilterte Spalte manipuliert haben, wird das Filterprädikat nicht mehr als SARG betrachtet. Der Index ist noch deckend, kann also verwendet werden; Anstatt jedoch eine Suche im Index anzuwenden, die direkt zum Bereich der qualifizierenden Zeilen geht, wird das gesamte Indexblatt gescannt. Angenommen, die Tabelle enthält 50.000.000 Bestellungen, von denen nur 1.000 nicht versandte Bestellungen sind. Dieser Plan würde alle 50.000.000 Zeilen scannen, anstatt eine Suche durchzuführen, die direkt zu den qualifizierenden 1.000 Zeilen geht.
Eine Form eines Filterprädikats, das sowohl die richtige Bedeutung hat, nach der wir suchen, als auch als Suchargument betrachtet wird, ist (shippeddate =@dt OR (shippeddate IS NULL AND @dt IS NULL)). Hier ist eine Abfrage, die dieses SARGable-Prädikat verwendet (wir nennen es Abfrage 3):
DECLARE @dt AS DATE =NULL; SELECT orderid, shippingdateFROM Sales.OrdersWHERE (shippeddate =@dt OR (shippeddate IS NULL AND @dt IS NULL));
Der Plan für diese Abfrage ist in Abbildung 3 dargestellt.
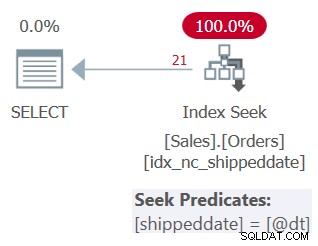 Abbildung 3:Plan für Abfrage 3
Abbildung 3:Plan für Abfrage 3
Wie Sie sehen können, wendet der Plan eine Suche im unterstützenden Index an. Das Suchprädikat lautet „shippeddate =@dt“, aber es ist intern so konzipiert, dass es NULL-Werte zum Zweck des Vergleichs genauso behandelt wie Nicht-NULL-Werte.
Diese Lösung wird allgemein als vernünftig angesehen. Es ist Standard, optimal und korrekt. Sein Hauptnachteil ist, dass es ausführlich ist. Was wäre, wenn Sie mehrere Filterprädikate basierend auf NULL-fähigen Spalten hätten? Sie würden schnell mit einer langwierigen und umständlichen WHERE-Klausel enden. Und es wird noch viel schlimmer, wenn Sie ein Filterprädikat schreiben müssen, das eine NULL-fähige Spalte enthält, die nach Zeilen sucht, in denen sich die Spalte vom Eingabeparameter unterscheidet. Das Prädikat wird dann zu:(Lieferdatum <> @dt UND ((Lieferdatum IST NULL UND @dt IST NICHT NULL) ODER (Lieferdatum IST NICHT NULL und @dt IST NULL))).
Sie sehen deutlich die Notwendigkeit einer eleganteren Lösung, die sowohl prägnant als auch optimal ist. Leider greifen einige auf eine nicht standardmäßige Lösung zurück, bei der Sie die Sitzungsoption ANSI_NULLS deaktivieren. Diese Option bewirkt, dass SQL Server eine nicht standardmäßige Behandlung der Gleichheits- (=) und Anders-als-Operatoren (<>) mit zweiwertiger statt dreiwertiger Logik verwendet und NULL-Werte zu Vergleichszwecken genauso behandelt wie Nicht-NULL-Werte. Das ist zumindest so lange der Fall, wie einer der Operanden ein Parameter/Variable oder ein Literal ist.
Führen Sie den folgenden Code aus, um die ANSI_NULLS-Option in der Sitzung zu deaktivieren:
SET ANSI_NULLS AUS;
Führen Sie die folgende Abfrage mit einem einfachen, auf Gleichheit basierenden Prädikat aus:
DECLARE @dt AS DATE =NULL; WÄHLEN Sie Bestell-ID, VersanddatumFROM Sales.OrdersWHERE Versanddatum =@dt;
Diese Abfrage gibt die 21 unversendeten Bestellungen zurück. Sie erhalten denselben Plan wie zuvor in Abbildung 3, der eine Suche im Index zeigt.
Führen Sie den folgenden Code aus, um zum Standardverhalten zurückzukehren, bei dem ANSI_NULLS aktiviert ist:
SET ANSI_NULLS ON;
Es wird dringend davon abgeraten, sich auf ein solches nicht standardmäßiges Verhalten zu verlassen. Die Dokumentation gibt außerdem an, dass die Unterstützung für diese Option in einigen zukünftigen Versionen von SQL Server entfernt wird. Darüber hinaus ist vielen nicht klar, dass diese Option nur anwendbar ist, wenn mindestens einer der Operanden ein Parameter/eine Variable oder eine Konstante ist, obwohl die Dokumentation darüber ziemlich klar ist. Es gilt nicht, wenn zwei Spalten verglichen werden, z. B. in einem Join.
Wie gehen Sie also mit Joins um, die NULL-fähige Join-Spalten enthalten, wenn Sie eine Übereinstimmung erhalten möchten, wenn die beiden Seiten NULL sind? Verwenden Sie als Beispiel den folgenden Code, um die Tabellen T1 und T2 zu erstellen und zu füllen:
DROP TABLE IF EXISTS dbo.T1, dbo.T2;GO CREATE TABLE dbo.T1(k1 INT NULL, k2 INT NULL, k3 INT NULL, val1 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T1 UNIQUE CLUSTERED(k1, k2 , k3)); TABELLE ERSTELLEN dbo.T2(k1 INT NULL, k2 INT NULL, k3 INT NULL, val2 VARCHAR(10) NOT NULL, CONSTRAINT UNQ_T2 UNIQUE CLUSTERED(k1, k2, k3)); INSERT INTO dbo.T1(k1, k2, k3, val1) WERTE (1, NULL, 0, 'A'),(NULL, NULL, 1, 'B'),(0, NULL, NULL, 'C') ,(1, 1, 0, 'D'),(0, NULL, 1, 'F'); INSERT INTO dbo.T2(k1, k2, k3, val2) WERTE (0, 0, 0, 'G'),(1, 1, 1, 'H'),(0, NULL, NULL, 'I') ,(NULL, NULL, NULL, 'J'),(0, NULL, 1, 'K');
Der Code erstellt abdeckende Indizes für beide Tabellen, um einen Join basierend auf den Join-Schlüsseln (k1, k2, k3) auf beiden Seiten zu unterstützen.
Verwenden Sie den folgenden Code, um die Kardinalitätsstatistiken zu aktualisieren und die Zahlen aufzublähen, sodass der Optimierer denkt, dass Sie es mit größeren Tabellen zu tun haben:
STATISTIK dbo.T1(UNQ_T1) MIT ROWCOUNT =1000000 AKTUALISIEREN;STATISTIK dbo.T2(UNQ_T2) MIT ROWCOUNT =1000000 AKTUALISIEREN;
Verwenden Sie den folgenden Code, um zu versuchen, die beiden Tabellen mit einfachen, auf Gleichheit basierenden Prädikaten zu verknüpfen:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1 INNER JOIN dbo.T2 ON T1.k1 =T2.k1 AND T1.k2 =T2.k2 AND T1. k3 =T2.k3;
Genau wie bei früheren Filterbeispielen ergeben auch hier Vergleiche zwischen NULL-Werten mit einem Gleichheitsoperator UNBEKANNT, was zu Nichtübereinstimmungen führt. Diese Abfrage erzeugt eine leere Ausgabe:
k1 K2 K3 val1 val2----------- ----------- ----------- --------- - ----------(0 Zeilen betroffen)
Die Verwendung von ISNULL oder COALESCE wie in einem früheren Filterbeispiel, das Ersetzen einer NULL durch einen Wert, der normalerweise nicht in den Daten auf beiden Seiten erscheinen kann, führt zu einer korrekten Abfrage (ich bezeichne diese Abfrage als Abfrage 4):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1 INNER JOIN dbo.T2 ON ISNULL(T1.k1, -2147483648) =ISNULL(T2.k1, -2147483648 ) AND ISNULL(T1.k2, -2147483648) =ISNULL(T2.k2, -2147483648) AND ISNULL(T1.k3, -2147483648) =ISNULL(T2.k3, -2147483648);
Diese Abfrage generiert die folgende Ausgabe:
k1 K2 K3 val1 val2----------- ----------- ----------- --------- - ----------0 NULL NULL C I0 NULL 1 F K
Genauso wie die Manipulation einer gefilterten Spalte die SARGability des Filterprädikats unterbricht, verhindert die Manipulation einer Join-Spalte jedoch die Möglichkeit, sich auf die Indexreihenfolge zu verlassen. Dies ist im Plan für diese Abfrage zu sehen, wie in Abbildung 4 dargestellt.
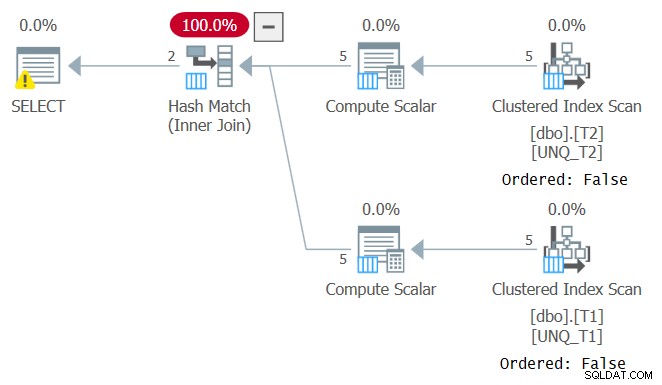 Abbildung 4:Plan für Abfrage 4
Abbildung 4:Plan für Abfrage 4
Ein optimaler Plan für diese Abfrage ist einer, der geordnete Scans der beiden abdeckenden Indizes anwendet, gefolgt von einem Merge-Join-Algorithmus ohne explizite Sortierung. Der Optimierer wählte einen anderen Plan, da er sich nicht auf die Indexreihenfolge verlassen konnte. Wenn Sie versuchen, einen Merge-Join-Algorithmus mit INNER MERGE JOIN zu erzwingen, stützt sich der Plan immer noch auf ungeordnete Scans der Indizes, gefolgt von einer expliziten Sortierung. Probieren Sie es aus!
Natürlich können Sie die langen Prädikate ähnlich den zuvor gezeigten SARGable-Prädikaten für Filteraufgaben verwenden:
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1 INNER JOIN dbo.T2 ON (T1.k1 =T2.k1 ODER (T1.k1 IST NULL UND T2. K1 IST NULL)) UND (T1.k2 =T2.k2 ODER (T1.k2 IST NULL UND T2.K2 IST NULL)) UND (T1.k3 =T2.k3 ODER (T1.k3 IST NULL UND T2.K3 IST NULL));
Diese Abfrage erzeugt das gewünschte Ergebnis und ermöglicht es dem Optimierer, sich auf die Indexreihenfolge zu verlassen. Wir hoffen jedoch, eine Lösung zu finden, die sowohl optimal als auch prägnant ist.
Es gibt eine wenig bekannte elegante und prägnante Technik, die Sie sowohl in Verknüpfungen als auch in Filtern verwenden können, sowohl zum Zweck der Identifizierung von Übereinstimmungen als auch zur Identifizierung von Nichtübereinstimmungen. Diese Technik wurde bereits vor Jahren entdeckt und dokumentiert, wie zum Beispiel in Paul Whites hervorragendem Artikel Undocumented Query Plans:Equality Comparisons aus dem Jahr 2011. Aber aus irgendeinem Grund scheinen sich immer noch viele Leute dessen nicht bewusst zu sein und am Ende leider suboptimal, langwierig und zu verwenden Nicht standardisierte Lösungen. Es verdient sicherlich mehr Aufmerksamkeit und Liebe.
Die Technik beruht auf der Tatsache, dass Mengenoperatoren wie INTERSECT und EXCEPT einen auf Unterscheidbarkeit basierenden Vergleichsansatz verwenden, wenn sie Werte vergleichen, und keinen auf Gleichheit oder Ungleichheit basierenden Vergleichsansatz.
Betrachten Sie unsere Join-Aufgabe als Beispiel. Wenn wir keine anderen Spalten als die Join-Schlüssel zurückgeben müssten, hätten wir eine einfache Abfrage (ich bezeichne sie als Abfrage 5) mit einem INTERSECT-Operator wie folgt verwendet:
SELECT k1, k2, k3 FROM dbo.T1INTERSECTSELECT k1, k2, k3 FROM dbo.T2;
Diese Abfrage generiert die folgende Ausgabe:
k1 k2 k3----------- ----------- -----------0 NULL NULL0 NULL 1
Der Plan für diese Abfrage ist in Abbildung 5 dargestellt und bestätigt, dass sich der Optimierer auf die Indexreihenfolge verlassen und einen Merge-Join-Algorithmus verwenden konnte.
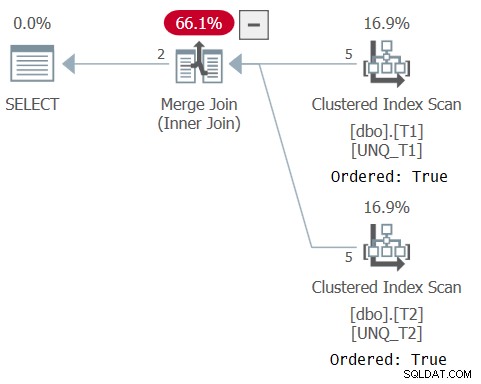 Abbildung 5:Plan für Abfrage 5
Abbildung 5:Plan für Abfrage 5
Wie Paul in seinem Artikel feststellt, verwendet der XML-Plan für den Set-Operator einen impliziten IS-Vergleichsoperator (CompareOp="IS" ) im Gegensatz zum EQ-Vergleichsoperator, der in einem normalen Join verwendet wird (CompareOp="EQ" ). Das Problem bei einer Lösung, die sich ausschließlich auf einen Set-Operator stützt, besteht darin, dass Sie darauf beschränkt sind, nur die Spalten zurückzugeben, die Sie vergleichen. Was wir wirklich brauchen, ist eine Art Hybrid zwischen einem Join- und einem Set-Operator, der es Ihnen ermöglicht, eine Teilmenge der Elemente zu vergleichen, während Sie zusätzliche Elemente zurückgeben, wie es ein Join tut, und einen unterscheidbarkeitsbasierten Vergleich (IS) wie ein Set-Operator verwenden. Dies kann erreicht werden, indem ein Join als äußeres Konstrukt und ein EXISTS-Prädikat in der ON-Klausel des Joins verwendet werden, das auf einer Abfrage mit einem INTERSECT-Operator basiert, der die Join-Schlüssel von beiden Seiten vergleicht (ich bezeichne diese Lösung als Query 6):
SELECT T1.k1, T1.K2, T1.K3, T1.val1, T2.val2FROM dbo.T1 INNER JOIN dbo.T2 ON EXISTS(SELECT T1.k1, T1.k2, T1.k3 INTERSECT SELECT T2. k1, T2.k2, T2.k3);
Der INTERSECT-Operator arbeitet mit zwei Abfragen, die jeweils einen Satz aus einer Zeile bilden, basierend auf den Join-Schlüsseln von beiden Seiten. Wenn die beiden Zeilen gleich sind, gibt die INTERSECT-Abfrage eine Zeile zurück; das EXISTS-Prädikat gibt TRUE zurück, was zu einer Übereinstimmung führt. Wenn die beiden Zeilen nicht identisch sind, gibt die INTERSECT-Abfrage eine leere Menge zurück; das EXISTS-Prädikat gibt FALSE zurück, was zu einer Nichtübereinstimmung führt.
Diese Lösung generiert die gewünschte Ausgabe:
k1 K2 K3 val1 val2----------- ----------- ----------- --------- - ----------0 NULL NULL C I0 NULL 1 F K
Der Plan für diese Abfrage ist in Abbildung 6 dargestellt und bestätigt, dass sich der Optimierer auf die Indexreihenfolge verlassen konnte.
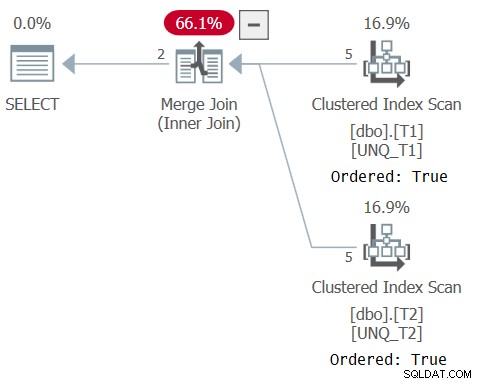 Abbildung 6:Plan für Abfrage 6
Abbildung 6:Plan für Abfrage 6
Sie können eine ähnliche Konstruktion als Filterprädikat verwenden, das eine Spalte und einen Parameter/eine Variable umfasst, um anhand der Unterscheidbarkeit nach Übereinstimmungen zu suchen, etwa so:
DECLARE @dt AS DATE =NULL; SELECT orderid, shippingdateFROM Sales.OrdersWHERE EXISTS(SELECT shippingdate INTERSECT SELECT @dt);
Der Plan ist derselbe wie der zuvor in Abbildung 3 gezeigte.
Sie können das Prädikat auch negieren, um nach Nichtübereinstimmungen zu suchen, wie folgt:
DECLARE @dt AS DATE ='20190212'; SELECT orderid, shippingdateFROM Sales.OrdersWHERE NOT EXISTS(SELECT shippingdate INTERSECT SELECT @dt);
Diese Abfrage generiert die folgende Ausgabe:
orderid shippingdate----------- -----------11008 NULL11019 NULL11039 NULL...10847 2019-02-1010856 2019-02-1010871 2019-02-1010867 2019-02-1110874 2019-02-1110870 2019-02-1310884 2019-02-1310840 2019-02-1610887 2019-02-16...(825 Zeilen betroffen)
Alternativ können Sie ein positives Prädikat verwenden, aber INTERSECT durch EXCEPT ersetzen, etwa so:
DECLARE @dt AS DATE ='20190212'; SELECT orderid, shippingdateFROM Sales.OrdersWHERE EXISTS(SELECT shippingdate EXCEPT SELECT @dt);
Beachten Sie, dass die Pläne in den beiden Fällen unterschiedlich sein können, also stellen Sie sicher, dass Sie mit großen Datenmengen in beide Richtungen experimentieren.
Schlussfolgerung
NULL-Werte erhöhen ihren Anteil an Komplexität beim Schreiben von SQL-Code. Sie sollten immer über das Potenzial für das Vorhandensein von NULL-Werten in den Daten nachdenken und sicherstellen, dass Sie die richtigen Abfragekonstrukte verwenden und Ihren Lösungen die relevante Logik hinzufügen, um NULL-Werte korrekt zu verarbeiten. Sie zu ignorieren ist ein sicherer Weg, um mit Fehlern in Ihrem Code zu enden. Diesen Monat habe ich mich darauf konzentriert, was NULL-Werte sind und wie sie in Vergleichen mit Konstanten, Variablen, Parametern und Spalten gehandhabt werden. Nächsten Monat werde ich die Berichterstattung fortsetzen, indem ich Inkonsistenzen bei der NULL-Behandlung in verschiedenen Sprachelementen und fehlende Standardfunktionen für die NULL-Behandlung bespreche.