[ Teil 1 | Teil 2 | Teil 3 ]
Kürzlich bat jemand bei der Arbeit um mehr Platz, um einen schnell wachsenden Tisch unterzubringen. Zu dieser Zeit hatte es 3,75 Milliarden Zeilen, die auf 143 Millionen Seiten präsentiert wurden und ~1,14 TB belegten. Natürlich können wir immer mehr Festplatten auf einen Tisch werfen, aber ich wollte sehen, ob wir dies effizienter skalieren können als den aktuellen linearen Trend. Klingt nach einer großartigen Aufgabe für die Komprimierung, oder? Aber ich wollte auch einige andere Lösungen ausprobieren, einschließlich Columnstore – die die Leute überraschenderweise nur ungern ausprobieren. Ich bin kein Niko, aber ich wollte mich bemühen zu sehen, was es hier für uns tun könnte.
Beachten Sie, dass ich mich derzeit nicht darauf konzentriere, die Arbeitslast oder die Leistung anderer Leseabfragen zu melden – ich möchte lediglich sehen, welche Auswirkungen ich auf den Speicherbedarf (und Arbeitsspeicher) dieser Daten haben kann.
Hier ist die Originaltabelle. Ich habe Tabellen- und Spaltennamen geändert, um Unschuldige zu schützen, aber alles andere ist relativ genau.
CREATE TABLE dbo.tblOriginal
(
OID bigint IDENTITY(1,1) NOT NULL PRIMARY KEY, -- there are gaps!
IN1 int NOT NULL,
IN2 int NOT NULL,
VC1 varchar(3) NULL,
BI1 bigint NULL,
IN3 int NULL,
VC2 varchar(128) NOT NULL,
VC3 varchar(128) NOT NULL,
VC4 varchar(128) NULL,
NM1 numeric(24,12) NULL,
NM2 numeric(24,12) NULL,
NM3 numeric(24,12) NULL,
BI2 bigint NULL,
IN4 int NULL,
BI3 bigint NULL,
NM4 numeric(24,12) NULL,
IN5 int NULL,
NM5 numeric(24,12) NULL,
DT1 date NULL,
VC5 varchar(128) NULL,
BI4 bigint NULL,
BI5 bigint NULL,
BI6 bigint NULL,
BT1 bit NOT NULL,
NV1 nvarchar(512) NULL,
VB1 AS (HASHBYTES('MD5',VC2+VC3)),
IN6 int NULL,
IN7 int NULL,
IN8 int NULL
);
Es gibt einige andere kleine Dinge darin, die breiter sind, als sie sein sollten, und/oder die die Zeilenkomprimierung aufräumen könnten, wie diese numeric(24,12) und bigint Spalten, die möglicherweise vorzeitig überdimensioniert sind, aber ich werde nicht zum Anwendungsteam zurückkehren und herausfinden, ob es dort wenig Effizienz gibt, und ich werde die Zeilenkomprimierung für diese Übung überspringen und mich auf die Seiten- und Columnstore-Komprimierung konzentrieren.
Dies ist eine Kopie der Daten auf einem inaktiven Server (8 Kerne, 64 GB RAM) mit viel Speicherplatz (weit über 6 TB). Lassen Sie uns also zuerst ein paar Dateigruppen hinzufügen, eine für den standardmäßigen gruppierten Columnstore und eine für eine partitionierte Version der Tabelle (wobei alle außer der neuesten Partition mit COLUMNSTORE_ARCHIVE komprimiert werden , da all diese älteren Daten jetzt "nur und selten gelesen werden"):
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_PARTITIONED;
Und dann einige Dateien für diese Dateigruppen (eine Datei pro Kern, schön und einheitlich groß bei 256 GB):
ALTER DATABASE OCopy ADD FILE (name = N'CCI_1', size = 250000, filename = 'K:\Data\o_cci_1.mdf') TO FILEGROUP FG_CCI; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_8', size = 250000, filename = 'K:\Data\o_cci_8.mdf') TO FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_1', size = 250000, filename = 'K:\Data\o_p_1.mdf') TO FILEGROUP FG_CCI_PARTITIONED; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_8', size = 250000, filename = 'K:\Data\o_p_8.mdf') TO FILEGROUP FG_CCI_PARTITIONED;
Auf dieser speziellen Hardware (YMMV!) dauerte dies etwa 10 Sekunden pro Datei und ergab Folgendes:
Um die Partitionen zu erzeugen, habe ich die Daten naiv „gleichmäßig“ aufgeteilt – dachte ich jedenfalls. Ich habe einfach die 3,75 Milliarden Zeilen genommen und in etwas partitioniert, von dem ich dachte, dass es überschaubar wäre:38 Partitionen mit 100 Millionen Zeilen in den ersten 37 Partitionen und der Rest in der letzten. (Denken Sie daran, dies ist nur Teil 1! Es gibt hier eine inhärente Annahme über die gleichmäßige Verteilung von Werten in der Quelltabelle und auch um das, was für die Zeilengruppenauffüllung in der Zieltabelle optimal ist.) Das Erstellen des Partitionsschemas und der Funktion dafür ist wie folgt folgt:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES (100000000, 200000000, /* ... 33 more ... */ , 3600000000, 3700000000); CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID ALL TO (FG_CCI_PARTITIONED);
Ich benutze RANGE LEFT denn, wie Cathrine Wilhelmsen mich immer wieder daran erinnert, bedeutet dies, dass der Grenzwert ein Teil der Partition zu seiner Linken ist. Mit anderen Worten, die von mir angegebenen Werte sind die Maximalwerte in jeder Partition (bei Datumsangaben möchten Sie normalerweise RANGE RIGHT ).
Dann habe ich zwei Kopien der Tabelle erstellt, eine für jede Dateigruppe. Der erste hatte einen standardmäßigen gruppierten Columnstore-Index, die einzigen Unterschiede waren die OID Spalte ist keine IDENTITY und die berechnete Spalte ist nur ein varbinary(8000) :
CREATE TABLE dbo.tblCCI ( OID bigint NOT NULL, -- ... other columns ... ) ON FG_CCI; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_IX ON dbo.tblCCI;
Der zweite wurde auf dem Partitionsschema aufgebaut, benötigte also zuerst einen benannten PK, der dann durch einen gruppierten Columnstore-Index ersetzt werden musste (obwohl Brent Ozar in diesem kurzen Beitrag zeigt, dass es eine nicht intuitive Syntax gibt, die dies in weniger Schritten bewerkstelligt ):
CREATE TABLE dbo.tblCCI_Partitioned ( OID bigint NOT NULL, -- ... other columns ..., CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID (OID) ); GO ALTER TABLE dbo.tblCCI_Partitioned DROP CONSTRAINT PK_CCI_Part; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblCCI_Partitioned ON PS_OID (OID);
Dann habe ich Folgendes ausgeführt, um die Archivkomprimierung auf alle außer der letzten Partition anzuwenden:
ALTER TABLE dbo.tblCCI_Part
REBUILD PARTITION = ALL WITH
(
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (38),
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 37)
); Jetzt war ich bereit, diese Tabellen mit Daten zu füllen, die benötigte Zeit und die resultierende Größe zu messen und zu vergleichen. Ich habe ein hilfreiches Batching-Skript von Andy Mallon modifiziert und die Zeilen nacheinander in beide Tabellen eingefügt, mit einer Batchgröße von 10 Millionen Zeilen. Im eigentlichen Skript steckt viel mehr dahinter (einschließlich der Aktualisierung einer Warteschlangentabelle mit dem Fortschritt), aber im Wesentlichen:
DECLARE @BatchSize int = 10000000, @MaxID bigint, @LastID bigint = 0;
SELECT @MaxID = MAX(OID) FROM dbo.tblOriginal;
WHILE @LastID < @MaxID
BEGIN
INSERT dbo.tblCCI
(
-- all columns except the computed column
)
SELECT -- all columns except the computed column
FROM dbo.tblOriginal AS o
WHERE o.CostID >= @LastID
AND o.CostID < @LastID + @BatchSize;
SET @LastID += @BatchSize;
END Nachdem ich beide Columnstore-Tabellen aus der ursprünglichen (unkomprimierten) Quelle gefüllt hatte, erstellte ich diese Partitionen erneut, um jegliches Durcheinander von Zeilengruppen und Wörterbüchern zu beseitigen. Schließlich habe ich die Seitenkomprimierung auf die Quelltabelle angewendet. Hier waren die Zeiten und die Komprimierungsergebnisse für jeden Typ:
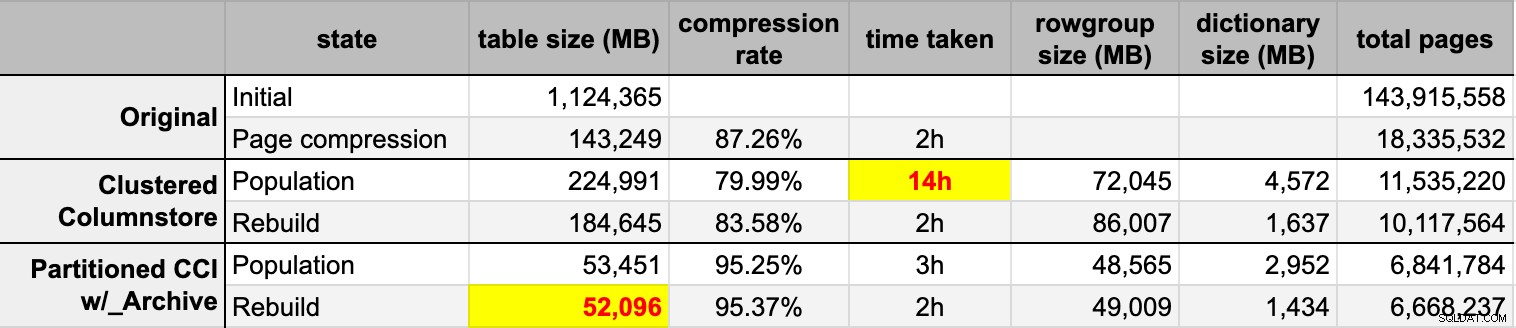
Ich bin sowohl beeindruckt als auch enttäuscht. Beeindruckt, weil diese Daten wirklich gut komprimiert werden – Es ist erstaunlich, den Speicherbedarf auf 5 % der ursprünglichen 1 TB zu reduzieren. Enttäuscht, weil:
- Ich habe diese Datendateien auf diese Weise erstellt zu groß.
- Ich verstehe nicht, was mit der anfänglichen Columnstore-Komprimierung von 14 Stunden passiert ist:
- Ich habe keinen Speicher- oder Protokolldruck beobachtet.
- Es gab keine Dateiwachstumsereignisse.
- Leider habe ich nicht daran gedacht, Wartezeiten zu verfolgen. Nein, ich werde es nicht noch einmal versuchen. :-)
- Die Seitenkomprimierung übertraf die normale Columnstore-Komprimierung – möglicherweise aufgrund der Daten.
- Die Wiederherstellung der Columnstore-Archivpartitionen verbrauchte viel CPU-Zeit und brachte fast keinen Gewinn.
In den kommenden Posts und nachdem ich meine Notizen von einer erstaunlichen Columnstore-Präsentation von Joe Obbish auf dem PASS Summit durchgesehen habe (auf die ich direkt verlinken würde, wenn PASS nur wüsste, wie die Benutzeroberfläche funktioniert), werde ich ein wenig über die Änderungen sprechen, die ich werde make an der Serverkonfiguration und meinem Populationsskript, um zu sehen, ob ich mit der Columnstore-Population eine bessere Leistung erzielen kann.
[ Teil 1 | Teil 2 | Teil 3 ]