Ich hatte das Vergnügen, letzte Woche am PGDay UK teilzunehmen – eine sehr schöne Veranstaltung, hoffentlich habe ich die Chance, nächstes Jahr wiederzukommen. Es gab viele interessante Vorträge, aber einer, der meine Aufmerksamkeit besonders erregte, war Performace for querys with grouping von Alexey Bashtanov.
Ich habe in der Vergangenheit eine ganze Reihe ähnlicher leistungsorientierter Vorträge gehalten, daher weiß ich, wie schwierig es ist, Benchmark-Ergebnisse auf verständliche und interessante Weise zu präsentieren, und Alexey hat einen ziemlich guten Job gemacht, denke ich. Wenn Sie sich also mit Datenaggregation befassen (z. B. BI, Analytik oder ähnliche Workloads), empfehle ich, die Folien durchzugehen, und wenn Sie die Möglichkeit haben, an dem Vortrag auf einer anderen Konferenz teilzunehmen, empfehle ich dies sehr.
Aber es gibt einen Punkt, an dem ich dem Gerede nicht zustimme. An einigen Stellen schlug der Vortrag vor, dass Sie HashAggregate im Allgemeinen bevorzugen sollten, da die Sortierung langsam ist.
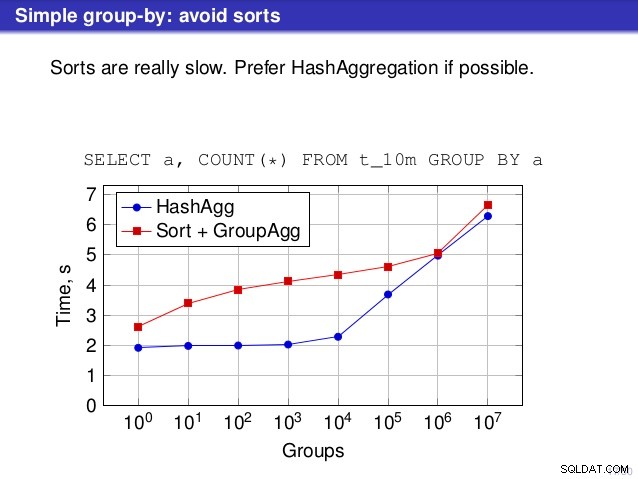
Ich halte das für etwas irreführend, denn eine Alternative zu HashAggregate ist GroupAggregate, nicht Sort. Die Empfehlung geht also davon aus, dass jedes GroupAggregate eine verschachtelte Sortierung hat, aber das ist nicht ganz richtig. GroupAggregate erfordert sortierte Eingaben, und eine explizite Sortierung ist nicht die einzige Möglichkeit, dies zu tun – wir haben auch IndexScan- und IndexOnlyScan-Knoten, die die Sortierkosten eliminieren und die anderen Vorteile von sortierten Pfaden (insbesondere IndexOnlyScan) beibehalten.
Lassen Sie mich die Leistung von (IndexOnlyScan+GroupAggregate) im Vergleich zu HashAggregate und (Sort+GroupAggregate) demonstrieren – das Skript, das ich für die Messungen verwendet habe, ist hier. Es erstellt vier einfache Tabellen mit jeweils 100 Millionen Zeilen und einer unterschiedlichen Anzahl von Gruppen in der Spalte „branch_id“ (die die Größe der Hash-Tabelle bestimmt). Die kleinste hat 10.000 Gruppen
-- table with 10k groups create table t_10000 (branch_id bigint, amount numeric); insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
und drei weitere Tische haben 100k-, 1M- und 5M-Gruppen. Lassen Sie uns diese einfache Abfrage ausführen, die die Daten aggregiert:
SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1
und überzeugen Sie dann die Datenbank, drei verschiedene Pläne zu verwenden:
1) HashAggregat
SET enable_sort = off;
SET enable_hashagg = on;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
----------------------------------------------------------------------------
HashAggregate (cost=2136943.00..2137067.99 rows=9999 width=40)
Group Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 width=19)
(3 rows) 2) GroupAggregate (mit Sortierung)
SET enable_sort = on;
SET enable_hashagg = off;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
-------------------------------------------------------------------------------
GroupAggregate (cost=16975438.38..17725563.37 rows=9999 width=40)
Group Key: branch_id
-> Sort (cost=16975438.38..17225438.38 rows=100000000 width=19)
Sort Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 ...)
(5 rows) 3) GroupAggregate (mit einem IndexOnlyScan)
SET enable_sort = on;
SET enable_hashagg = off;
CREATE INDEX ON t_10000 (branch_id, amount);
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
--------------------------------------------------------------------------
GroupAggregate (cost=0.57..3983129.56 rows=9999 width=40)
Group Key: branch_id
-> Index Only Scan using t_10000_branch_id_amount_idx on t_10000
(cost=0.57..3483004.57 rows=100000000 width=19)
(3 rows) Ergebnisse
Nach dem Messen der Zeiten für jeden Plan auf allen Tischen sehen die Ergebnisse so aus:
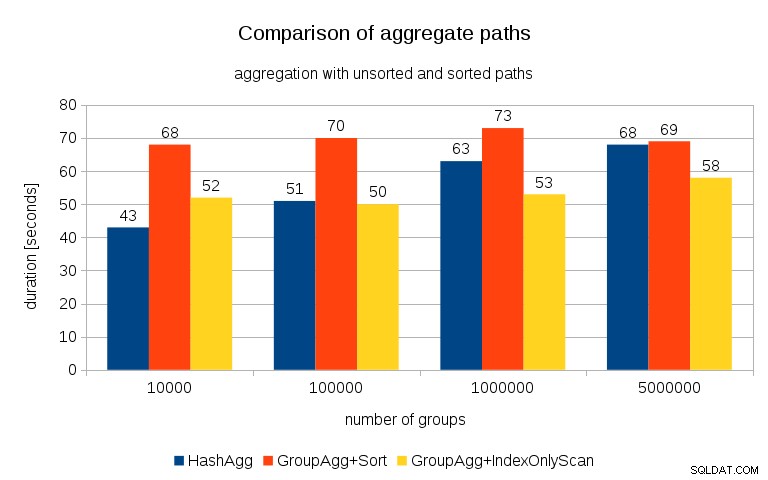
Für kleine Hash-Tabellen (die in den L3-Cache passen, der in diesem Fall 16 MB groß ist), ist der HashAggregate-Pfad deutlich schneller als beide sortierten Pfade. Aber bald wird GroupAgg+IndexOnlyScan genauso schnell oder sogar noch schneller – das liegt an der Cache-Effizienz, dem Hauptvorteil von GroupAggregate. Während HashAggregate die gesamte Hash-Tabelle auf einmal im Speicher halten muss, muss GroupAggregate nur die letzte Gruppe behalten. Und je weniger Speicher Sie verwenden, desto wahrscheinlicher passt er in den L3-Cache, der im Vergleich zum normalen RAM ungefähr eine Größenordnung schneller ist (bei den L1/L2-Caches ist der Unterschied sogar noch größer).
Obwohl mit IndexOnlyScan ein erheblicher Overhead verbunden ist (für den 10k-Fall ist es etwa 20 % langsamer als der HashAggregate-Pfad), sinkt die Trefferquote des L3-Cache schnell, wenn die Hash-Tabelle wächst, und der Unterschied macht GroupAggregate schließlich schneller. Und schließlich erreicht sogar GroupAggregate+Sort den HashAggregate-Pfad.
Sie könnten argumentieren, dass Ihre Daten im Allgemeinen eine relativ geringe Anzahl von Gruppen haben und daher die Hash-Tabelle immer in den L3-Cache passt. Bedenken Sie jedoch, dass der L3-Cache von allen Prozessen gemeinsam genutzt wird, die auf der CPU ausgeführt werden, und auch von allen Teilen des Abfrageplans. Obwohl wir derzeit etwa 20 MB L3-Cache pro Socket haben, erhält Ihre Abfrage nur einen Teil davon, und dieses Bit wird von allen Knoten in Ihrer (möglicherweise recht komplexen) Abfrage geteilt.
Aktualisierung 26.07.2016 :Wie in den Kommentaren von Peter Geoghegan erwähnt, führt die Art und Weise, wie die Daten generiert wurden, wahrscheinlich zu einer Korrelation – nicht zu den Werten (oder besser zu Hashes der Werte), sondern zu Speicherzuweisungen. Ich habe die Abfragen mit ordnungsgemäß randomisierten Daten wiederholt, d. h. tun
insert into t_10000 select (10000*random())::bigint, random() from generate_series(1,100000000) s(i);
statt
insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
und die Ergebnisse sehen so aus:
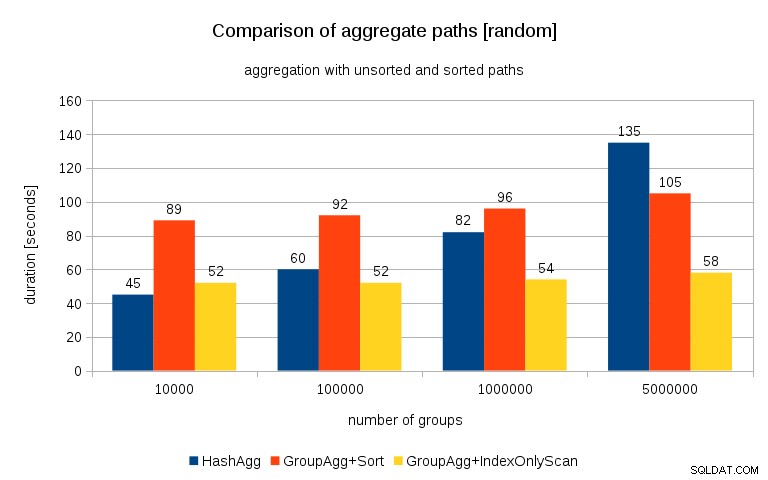
Wenn ich dies mit dem vorherigen Diagramm vergleiche, denke ich, dass es ziemlich klar ist, dass die Ergebnisse noch mehr für sortierte Pfade sprechen, insbesondere für den Datensatz mit 5 Millionen Gruppen. Der 5M-Datensatz zeigt auch, dass GroupAgg mit einer expliziten Sortierung möglicherweise schneller ist als HashAgg.
Zusammenfassung
Während HashAggregate mit einer expliziten Sortierung wahrscheinlich schneller ist als GroupAggregate (ich zögere jedoch zu sagen, dass dies immer der Fall ist), kann die Verwendung von GroupAggregate mit IndexOnlyScan schneller es leicht viel schneller machen als HashAggregate.
Natürlich können Sie den genauen Plan nicht direkt auswählen – das sollte der Planer für Sie erledigen. Aber Sie beeinflussen den Auswahlprozess, indem Sie (a) Indizes erstellen und (b) work_mem setzen . Deshalb senken Sie manchmal work_mem (und maintenance_work_mem )-Werte führen zu einer besseren Leistung.
Zusätzliche Indizes sind jedoch nicht kostenlos – sie kosten sowohl CPU-Zeit (beim Einfügen neuer Daten) als auch Speicherplatz. Für IndexOnlyScans können die Speicherplatzanforderungen ziemlich hoch sein, da der Index alle Spalten enthalten muss, auf die von der Abfrage verwiesen wird, und ein regulärer IndexScan Ihnen nicht die gleiche Leistung erbringen würde, da er viele zufällige E/A-Vorgänge für die Tabelle generiert (wodurch alle die potenziellen Gewinne).
Ein weiteres nettes Feature ist die Stabilität der Leistung – beachten Sie, wie sich die HashAggregate-Timings abhängig von der Anzahl der Gruppen ändern, während die GroupAggregate-Pfade meistens gleich funktionieren.