[ Teil 1 | Teil 2 | Teil 3 ]
Im Geiste von Grant Fritcheys jüngsten Tiraden und Erin Stellatos Bemühungen, seit ich glaube, bevor wir uns trafen, möchte ich auf den fahrenden Zug aufspringen und die Idee fördern, Trace zugunsten von Extended Events aufzugeben. Wenn jemand verfolgen sagt , denken die meisten sofort an Profiler . Obwohl der Profiler ein eigener Albtraum ist, wollte ich heute über die Standardablaufverfolgung von SQL Server sprechen.
In unserer Umgebung ist es auf allen über 200 Produktionsservern aktiviert und sammelt eine ganze Menge Müll, den wir nie untersuchen werden. Tatsächlich so viel Müll, dass wichtige Ereignisse, die wir für die Fehlerbehebung nützlich finden könnten, aus den Ablaufverfolgungsdateien verschwinden, bevor wir überhaupt die Gelegenheit dazu haben. Also fing ich an, darüber nachzudenken, es abzuschalten, weil:
- es ist nicht kostenlos (der Beobachter-Overhead der Ablaufverfolgungsaktivität selbst, die E/A, die mit dem Schreiben in die Ablaufverfolgungsdateien verbunden ist, und der Speicherplatz, den sie verbrauchen);
- Auf den meisten Servern wird es nie angesehen; bei anderen selten; und,
- Es ist einfach wieder einzuschalten für gezielte, isolierte Fehlersuche.
Ein paar andere Dinge wirken sich auf den Wert des Standard-Trace aus. Es ist in keiner Weise konfigurierbar – Sie können nicht ändern, welche Ereignisse es sammelt, Sie können keine Filter hinzufügen und Sie können nicht steuern, wie viele Dateien es speichert (5), wie groß sie werden können (jeweils 20 MB). , oder wo sie gespeichert sind (SERVERPROPERTY('ErrorLogFileName') ). Wir sind also vollständig der Arbeitslast ausgeliefert – auf einem bestimmten Server können wir nicht vorhersagen, wie weit die Daten zurückgehen (Ereignisse mit größeren TextData Werte können beispielsweise viel mehr Platz einnehmen und ältere Ereignisse schneller verdrängen). Manchmal kann es eine Woche zurückgehen, manchmal kann es nur Minuten zurückgehen.
Analyse des aktuellen Zustands
Ich habe den folgenden Code für 224 Produktionsinstanzen ausgeführt, nur um zu verstehen, welche Art von Rauschen die Standardablaufverfolgung in unserer Umgebung füllt. Dies ist wahrscheinlich komplizierter als nötig und nicht einmal so komplex wie die letzte Abfrage, die ich verwendet habe, aber es ist ein guter Ausgangspunkt, um die Aufschlüsselung der Ereignistypen auf hoher Ebene zu analysieren, die derzeit erfasst werden:
;WITH filesrc ([path]) AS
(
SELECT REVERSE(SUBSTRING(p, CHARINDEX(N'\', p), 260)) + N'log.trc'
FROM (SELECT REVERSE([path]) FROM sys.traces WHERE is_default = 1) s(p)
),
tracedata AS
(
SELECT Context = CASE
WHEN DDL = 1 THEN
CASE WHEN LEFT(ObjectName,8) = N'_WA_SYS_'
THEN 'AutoStat: ' + DBType
WHEN LEFT(ObjectName,2) IN (N'PK', N'UQ', N'IX') AND ObjectName LIKE N'%[_#]%'
THEN UPPER(LEFT(ObjectName,2)) + ': tempdb'
WHEN ObjectType = 17747 AND ObjectName LIKE N'TELEMETRY%'
THEN 'Telemetry'
ELSE 'Other DDL in ' + DBType END
WHEN EventClass = 116 THEN
CASE WHEN TextData LIKE N'%checkdb%' THEN 'DBCC CHECKDB'
-- several more of these ...
ELSE UPPER(CONVERT(nchar(32), TextData)) END
ELSE DBType END,
EventName = CASE WHEN DDL = 1 THEN 'DDL' ELSE EventName END,
EventSubClass,
EventClass,
StartTime
FROM
(
SELECT DDL = CASE WHEN t.EventClass IN (46,47,164) THEN 1 ELSE 0 END,
TextData = LOWER(CONVERT(nvarchar(512), t.TextData)),
EventName = e.[name],
t.EventClass,
t.EventSubClass,
ObjectName = UPPER(t.ObjectName),
t.ObjectType,
t.StartTime,
DBType = CASE WHEN t.DatabaseID = 2 OR t.ObjectName LIKE N'#%' THEN 'tempdb'
WHEN t.DatabaseID IN (1,3,4) THEN 'System database'
WHEN t.DatabaseID IS NOT NULL THEN 'User database' ELSE '?' END
FROM filesrc CROSS APPLY sys.fn_trace_gettable(filesrc.[path], DEFAULT) AS t
LEFT OUTER JOIN sys.trace_events AS e ON t.EventClass = e.trace_event_id
) AS src WHERE (EventSubClass IS NULL)
OR (EventSubClass = CASE WHEN DDL = 1 THEN 1 ELSE EventSubClass END) -- ddl_phase
)
SELECT [Instance] = @@SERVERNAME,
EventName,
Context,
EventCount = COUNT(*),
FirstSeen = MIN(StartTime),
LastSeen = MAX(StartTime)
INTO #t FROM tracedata
GROUP BY GROUPING SETS ((), (EventName, Context)); (Das Prädikat EventSubClass dient dazu, eine doppelte Zählung von DDL-Ereignissen zu verhindern.Eine Zuordnung von EventClass-Werten habe ich in dieser Antwort auf Stack Exchange aufgelistet.)
Und die Ergebnisse sind nicht schön (typische Ergebnisse von einem zufälligen Server). Das Folgende stellt nicht die genaue Ausgabe dieser Abfrage dar, aber ich verbrachte einige Zeit damit, die Ergebnisse in einem besser verdaulichen Format zusammenzufassen, um zu sehen, wie viele der Daten nützlich und wie viel Rauschen waren (zum Vergrößern klicken):
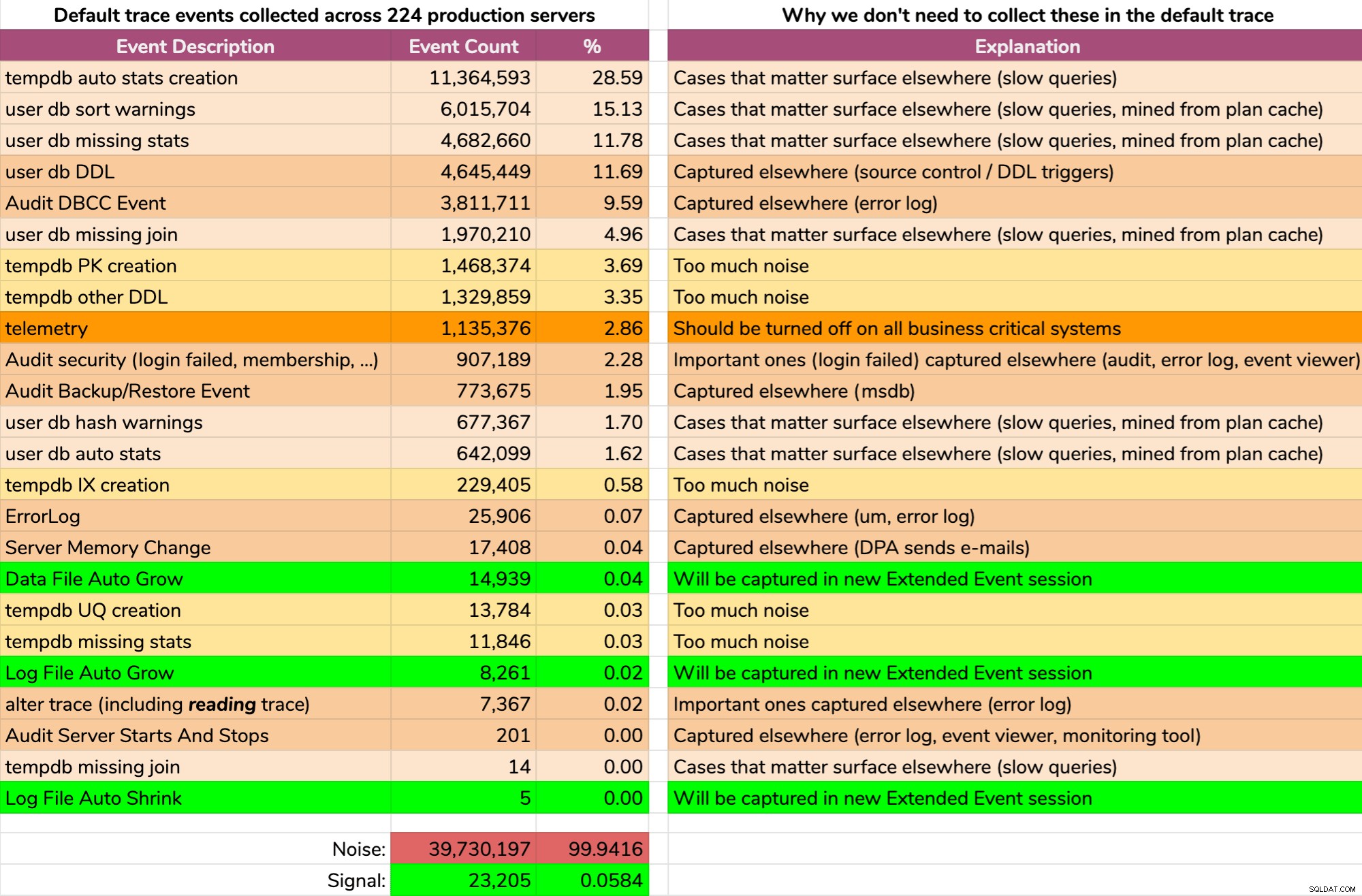
Fast alles Rauschen (99,94 %). Das einzig Nützliche, was wir jemals aus dem Standard-Trace brauchten, waren Dateiwachstums- und -verkleinerungsereignisse, da sie das einzige waren, was wir nicht an anderer Stelle auf die eine oder andere Weise erfassten. Aber auch darauf können wir uns nicht immer verlassen, weil die Daten so schnell wegrollen.
Auf andere Weise habe ich die Daten aufgeteilt:ältestes Ereignis pro Instanz. Einige Instanzen hatten so viel Rauschen, dass sie die Standard-Trace-Daten nicht länger als ein paar Minuten halten konnten! Ich habe die Servernamen unkenntlich gemacht, aber das sind echte Daten (dies sind die 20 Server mit der kürzesten Historie – zum Vergrößern anklicken):
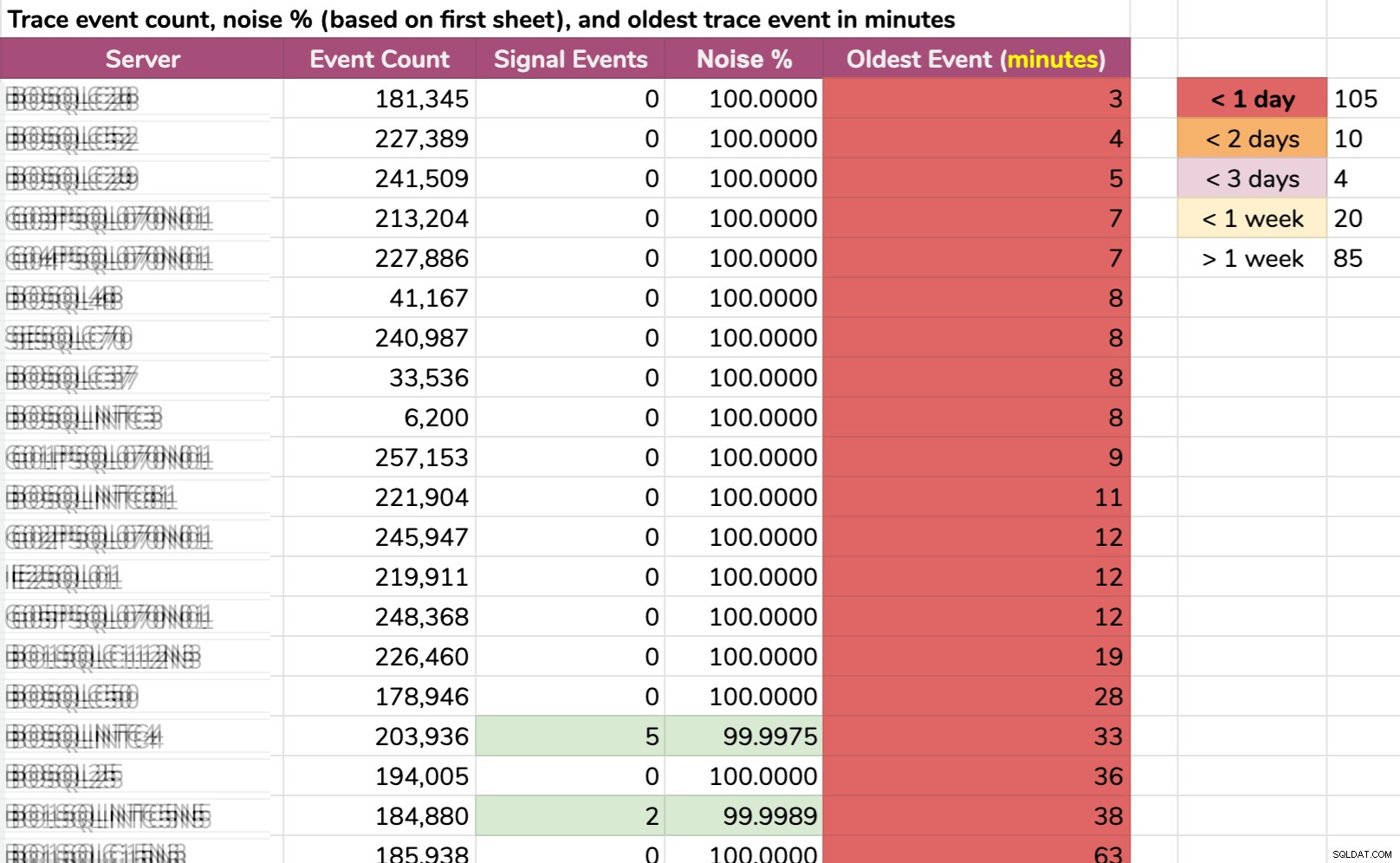
Selbst wenn der Trace nur sammeln würde relevante Informationen, und etwas Interessantes passierte, mussten wir je nach Server schnell handeln, um es abzufangen. Wenn es passiert ist:
- Vor 20 Minuten , dann wäre es schon bei 15 Instanzen weg .
- Gestern um diese Zeit , wäre es bei 105 Instanzen verschwunden .
- vor zwei Tagen , wäre es bei 115 Instanzen verschwunden .
- vor mehr als einer Woche , wäre es bei 139 Instanzen verschwunden .
Wir hatten auch eine Handvoll Server am anderen Ende, aber die sind in diesem Zusammenhang uninteressant; Diese Server sind einfach so, weil dort nichts Interessantes passiert (z. B. sind sie nicht beschäftigt oder Teil einer kritischen Arbeitslast).
Auf der positiven Seite…
Die Untersuchung des Standard-Trace hat einige Fehlkonfigurationen auf einigen unserer Server ergeben:
- Auf mehreren Servern war noch Telemetrie aktiviert . Ich bin dafür, Microsoft in bestimmten Umgebungen zu helfen, aber nicht um irgendwelche Gemeinkosten für geschäftskritische Systeme.
- Bei einigen Hintergrund-Synchronisierungsaufgaben wurden Mitglieder blind zu Rollen hinzugefügt , immer und immer wieder, ohne zu überprüfen, ob sie diese Rollen bereits inne hatten. Dies ist an sich nicht schädlich, insbesondere da diese Ereignisse die Standardablaufverfolgung nicht mehr füllen, aber sie füllen wahrscheinlich auch Audits mit Rauschen, und es gibt wahrscheinlich andere Blind-Re-Apply-Operationen, die nach demselben Muster ablaufen.
- Jemand hatte Autoshrink aktiviert irgendwo (meine Güte!), also wollte ich das aufspüren und verhindern, dass es wieder passiert (der neue XE wird diese Ereignisse auch erfassen).
Dies führte zu Folgeaufgaben, um diese Probleme zu beheben und/oder Bedingungen zu bereits vorhandener Automatisierung hinzuzufügen. So können wir ein erneutes Auftreten verhindern, ohne uns darauf verlassen zu müssen, dass wir das Glück haben, ihnen bei einer zukünftigen Standard-Trace-Überprüfung zu begegnen, bevor sie eingeführt werden.
… aber das Problem bleibt bestehen
Ansonsten sind alles entweder Informationen, auf die wir unmöglich reagieren können, oder, wie in der obigen Grafik beschrieben, Ereignisse, die wir bereits an anderer Stelle erfassen. Und noch einmal, die einzigen Daten, die mich aus dem Standard-Trace interessieren, die wir nicht bereits auf andere Weise erfassen, sind Ereignisse im Zusammenhang mit Dateiwachstum und -schrumpfung (obwohl der Standard-Trace nur die automatische Variante erfasst).
Aber das größere Problem ist nicht wirklich die Lautstärke. Ich kann mit großen, massiven Trace-Dateien mit viel Müll umgehen, da WHERE-Klauseln genau für diesen Zweck erfunden wurden. Das eigentliche Problem ist, dass wichtige Ereignisse zu schnell verschwanden.
Die Antwort
Die Antwort war zumindest in unserem Szenario einfach:Deaktivieren Sie den Standard-Trace, da es sich nicht lohnt, ihn auszuführen, wenn Sie sich nicht darauf verlassen können.
Aber angesichts der oben genannten Menge an Lärm, was sollte es ersetzen? Irgendwas?
Vielleicht möchten Sie eine erweiterte Veranstaltungssitzung, die alles erfasst der Standard-Trace erfasst. Dann sind Sie bei Jonathan Kehayias genau richtig. Dadurch erhalten Sie die gleichen Informationen, aber mit Kontrolle über Dinge wie Aufbewahrung, wo die Daten gespeichert werden, und, wenn Sie sich wohler fühlen, die Möglichkeit, einige der lauteren oder weniger nützlichen Ereignisse nach und nach im Laufe der Zeit zu entfernen.
Mein Plan war etwas aggressiver und wurde schnell zu einem "einfachen" Prozess, um Folgendes auf allen Servern in der Umgebung (über CMS) auszuführen:
- eine Sitzung für erweiterte Ereignisse entwickeln, die nur Dateiänderungsereignisse erfasst (sowohl manuell als auch automatisch)
- Deaktivieren Sie den Standard-Trace
- Erstellen Sie eine Ansicht, um unseren Teams die Verwendung von Zieldaten zu erleichtern
Beachten Sie, dass ich nicht vorschlage, dass Sie den Standard-Trace blind deaktivieren , um nur zu erklären, warum ich mich in unserer Umgebung dafür entschieden habe. In den kommenden Beiträgen dieser Serie zeige ich die neue Sitzung für erweiterte Ereignisse, die Ansicht, die die zugrunde liegenden Daten offenlegt, den Code, den ich verwendet habe, um diese Änderungen auf allen Servern bereitzustellen, und mögliche Nebenwirkungen, die Sie im Hinterkopf behalten sollten.
[ Teil 1 | Teil 2 | Teil 3 ]



