Dieser Artikel ist der achte Teil einer Reihe über Tabellenausdrücke. Bisher habe ich einen Hintergrund zu Tabellenausdrücken geliefert, sowohl die logischen als auch die Optimierungsaspekte von abgeleiteten Tabellen, die logischen Aspekte von CTEs und einige der Optimierungsaspekte von CTEs behandelt. In diesem Monat setze ich die Berichterstattung über Optimierungsaspekte von CTEs fort und gehe insbesondere darauf ein, wie mehrere CTE-Referenzen gehandhabt werden.
Dieser Artikel ist der achte Teil einer Reihe über Tabellenausdrücke. Bisher habe ich einen Hintergrund zu Tabellenausdrücken geliefert, sowohl die logischen als auch die Optimierungsaspekte von abgeleiteten Tabellen, die logischen Aspekte von CTEs und einige der Optimierungsaspekte von CTEs behandelt. In diesem Monat setze ich die Berichterstattung über Optimierungsaspekte von CTEs fort und gehe insbesondere darauf ein, wie mehrere CTE-Referenzen gehandhabt werden.
In meinen Beispielen verwende ich weiterhin die Beispieldatenbank TSQLV5. Das Skript, das TSQLV5 erstellt und füllt, finden Sie hier und sein ER-Diagramm hier.
Mehrere Referenzen und Nichtdeterminismus
Letzten Monat habe ich erklärt und demonstriert, dass CTEs entschachtelt werden, während temporäre Tabellen und Tabellenvariablen tatsächlich Daten beibehalten. Ich habe Empfehlungen gegeben, wann es sinnvoll ist, CTEs zu verwenden, und wann es aus Sicht der Abfrageleistung sinnvoll ist, temporäre Objekte zu verwenden. Aber es gibt noch einen weiteren wichtigen Aspekt der CTE-Optimierung oder physischen Verarbeitung, der über die Leistung der Lösung hinaus zu berücksichtigen ist – wie mehrere Verweise auf den CTE von einer äußeren Abfrage behandelt werden. Es ist wichtig zu wissen, dass bei einer äußeren Abfrage mit mehreren Verweisen auf denselben CTE jede separat entschachtelt wird. Wenn Sie nicht deterministische Berechnungen in der inneren Abfrage des CTE haben, können diese Berechnungen in den verschiedenen Referenzen unterschiedliche Ergebnisse haben.
Angenommen, Sie rufen die Funktion SYSDATETIME in der inneren Abfrage eines CTE auf und erstellen eine Ergebnisspalte namens dt. Unter der Annahme, dass sich die Eingaben nicht ändern, wird eine integrierte Funktion im Allgemeinen einmal pro Abfrage und Referenz ausgewertet, unabhängig von der Anzahl der betroffenen Zeilen. Wenn Sie von einer äußeren Abfrage nur einmal auf den CTE verweisen, aber mehrmals mit der dt-Spalte interagieren, sollten alle Verweise dieselbe Funktionsauswertung darstellen und dieselben Werte zurückgeben. Wenn Sie jedoch in der äußeren Abfrage mehrmals auf den CTE verweisen, sei es mit mehreren Unterabfragen, die sich auf den CTE beziehen, oder einem Join zwischen mehreren Instanzen desselben CTE (z C2.dt stellen unterschiedliche Auswertungen des zugrunde liegenden Ausdrucks dar und können zu unterschiedlichen Werten führen.
Um dies zu demonstrieren, betrachten Sie die folgenden drei Batches:
– Stapel 1 DECLARE @i AS INT =1; WHILE @@ROWCOUNT =1 SELECT @i +=1 WHERE SYSDATETIME() =SYSDATETIME(); PRINT @i;GO -- Stapel 2 DECLARE @i AS INT =1; WHILE @@ROWCOUNT =1 WITH C AS ( SELECT SYSDATETIME() AS dt ) SELECT @i +=1 FROM C WHERE dt =dt; PRINT @i;GO -- Stapel 3 DECLARE @i AS INT =1; WHILE @@ROWCOUNT =1 WITH C AS ( SELECT SYSDATETIME() AS dt ) SELECT @i +=1 WHERE (SELECT dt FROM C) =(SELECT dt FROM C); DRUCKE @i;GO
Können Sie basierend auf dem, was ich gerade erklärt habe, erkennen, welche der Stapel eine Endlosschleife haben und welche irgendwann aufhören, weil die beiden Komparanden des Prädikats unterschiedliche Werte ergeben?
Denken Sie daran, dass ich gesagt habe, dass ein Aufruf einer integrierten nichtdeterministischen Funktion wie SYSDATETIME einmal pro Abfrage und Referenz ausgewertet wird. Das bedeutet, dass Sie in Batch 1 zwei verschiedene Auswertungen haben und nach genügend Iterationen der Schleife zu unterschiedlichen Werten führen. Versuch es. Wie viele Iterationen hat der Code gemeldet?
Wie bei Batch 2 hat der Code zwei Verweise auf die dt-Spalte aus derselben CTE-Instanz, was bedeutet, dass beide dieselbe Funktionsauswertung darstellen und denselben Wert darstellen sollten. Folglich hat Batch 2 eine Endlosschleife. Führen Sie es so lange aus, wie Sie möchten, aber schließlich müssen Sie die Codeausführung stoppen.
Wie bei Batch 3 hat die äußere Abfrage zwei verschiedene Unterabfragen, die mit dem CTE C interagieren, wobei jede eine andere Instanz darstellt, die separat einen Entschachtelungsprozess durchläuft. Der Code weist den verschiedenen Instanzen des CTE nicht explizit unterschiedliche Aliase zu, da die beiden Unterabfragen in unabhängigen Bereichen erscheinen, aber um das Verständnis zu erleichtern, können Sie sich die beiden so vorstellen, dass sie unterschiedliche Aliase wie C1 in einer Unterabfrage und verwenden C2 im anderen. Es ist also so, als würde eine Unterabfrage mit C1.dt und die andere mit C2.dt interagieren. Die unterschiedlichen Referenzen stellen unterschiedliche Bewertungen des zugrunde liegenden Ausdrucks dar und können daher zu unterschiedlichen Werten führen. Versuchen Sie, den Code auszuführen, und sehen Sie, dass er irgendwann stoppt. Wie viele Iterationen hat es gedauert, bis es aufgehört hat?
Es ist interessant zu versuchen, die Fälle zu identifizieren, in denen Sie eine einzelne oder mehrere Auswertungen des zugrunde liegenden Ausdrucks im Abfrageausführungsplan haben. Abbildung 1 zeigt die grafischen Ausführungspläne für die drei Chargen (zum Vergrößern anklicken).
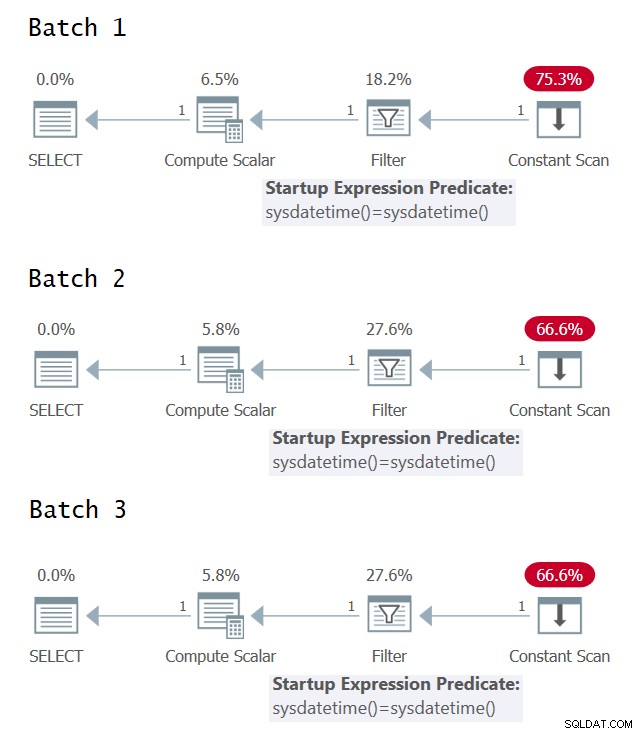 Abbildung 1:Grafische Ausführungspläne für Batch 1, Batch 2 und Batch 3
Abbildung 1:Grafische Ausführungspläne für Batch 1, Batch 2 und Batch 3
Leider keine Freude an den grafischen Ausführungsplänen; Sie scheinen alle identisch zu sein, obwohl die drei Stapel semantisch keine identische Bedeutung haben. Dank @CodeRecce und Forrest (@tsqladdict) haben wir es als Community geschafft, dem mit anderen Mitteln auf den Grund zu gehen.
Wie @CodeRecce feststellte, enthalten die XML-Pläne die Antwort. Hier sind die relevanten Teile des XML für die drei Stapel:
−− Charge 1
…
…
−− Charge 2
…
…
−− Charge 3
…
…
Sie können im XML-Plan für Batch 1 deutlich sehen, dass das Filterprädikat die Ergebnisse von zwei separaten direkten Aufrufen der intrinsischen SYSDATETIME-Funktion vergleicht.
Im XML-Plan für Batch 2 vergleicht das Filterprädikat den konstanten Ausdruck ConstExpr1002, der einen Aufruf der SYSDATETIME-Funktion darstellt, mit sich selbst.
Im XML-Plan für Batch 3 vergleicht das Filterprädikat zwei verschiedene konstante Ausdrücke namens ConstExpr1005 und ConstExpr1006, die jeweils einen separaten Aufruf der SYSDATETIME-Funktion darstellen.
Als weitere Option schlug Forrest (@tsqladdict) vor, das Ablaufverfolgungsflag 8605 zu verwenden, das die von SQL Server erstellte anfängliche Abfragebaumdarstellung zeigt, nachdem das Ablaufverfolgungsflag 3604 aktiviert wurde, wodurch die Ausgabe von TF 8605 an den SSMS-Client geleitet wird. Verwenden Sie den folgenden Code, um beide Trace-Flags zu aktivieren:
DBCC TRACEON(3604); -- direkte Ausgabe an clientGO DBCC TRACEON(8605); -- anfänglichen Abfragebaum anzeigenGO
Als Nächstes führen Sie den Code aus, für den Sie die Abfragestruktur abrufen möchten. Hier sind die relevanten Teile der Ausgabe, die ich von TF 8605 für die drei Stapel erhalten habe:
−− Charge 1
*** Umgewandelter Baum:***
LogOp_Project COL:Ausdr1000
LogOp_Select
LogOp_ConstTableGet (1) [leer]
ScaOp_Comp x_cmpEq
ScaOp_Intrinsic sysdatetime
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Ausdr1000
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=1)
− Charge 2
*** Umgewandelter Baum:***
LogOp_Project COL:Ausdr1001
LogOp_Select
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [leer]
AncOp_PrjList
AncOp_PrjEl COL:Ausdr1000
ScaOp_Intrinsic sysdatetime
ScaOp_Comp x_cmpEq
ScaOp_Identifier COL:Ausdr1000
ScaOp_Identifier COL:Ausdr1000
AncOp_PrjList
AncOp_PrjEl COL:Ausdr1001
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=1)
−− Charge 3
*** Umgewandelter Baum:***
LogOp_Project COL:Ausdr1004
LogOp_Select
LogOp_ConstTableGet (1) [leer]
ScaOp_Comp x_cmpEq
ScaOp_Subquery COL:Ausdr1001
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [leer]
AncOp_PrjList
AncOp_PrjEl COL:Ausdr1000
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Ausdr1001
ScaOp_Identifier COL:Ausdr1000
ScaOp_Subquery COL:Ausdr1003
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet (1) [leer]
AncOp_PrjList
AncOp_PrjEl COL:Ausdr1002
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Ausdr1003
ScaOp_Identifier COL:Ausdr1002
AncOp_PrjList
AncOp_PrjEl COL:Ausdr1004
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int,ML=4) XVAR(int,nicht im Besitz,Wert=1)
In Batch 1 sehen Sie einen Vergleich zwischen den Ergebnissen zweier separater Auswertungen der intrinsischen Funktion SYSDATETIME.
In Batch 2 sehen Sie eine Auswertung der Funktion, die zu einer Spalte namens Ausdr1000 führt, und dann einen Vergleich zwischen dieser Spalte und sich selbst.
In Batch 3 sehen Sie zwei getrennte Auswertungen der Funktion. Einer in der Spalte mit dem Namen Ausdr1000 (später projiziert durch die Unterabfragespalte mit dem Namen Ausdr1001). Eine weitere in der Spalte mit dem Namen Ausdr1002 (später projiziert durch die Unterabfragespalte mit dem Namen Ausdr1003). Sie haben dann einen Vergleich zwischen Expr1001 und Expr1003.
Wenn Sie also ein wenig mehr über das hinausgehen, was der grafische Ausführungsplan offenlegt, können Sie tatsächlich herausfinden, wann ein zugrunde liegender Ausdruck nur einmal oder mehrmals ausgewertet wird. Jetzt, da Sie die verschiedenen Fälle verstehen, können Sie Ihre Lösungen basierend auf dem gewünschten Verhalten entwickeln, das Sie suchen.
Fensterfunktionen mit nichtdeterministischer Ordnung
Es gibt eine andere Klasse von Berechnungen, die Sie in Schwierigkeiten bringen können, wenn sie in Lösungen mit mehreren Verweisen auf denselben CTE verwendet werden. Das sind Fensterfunktionen, die auf einer nichtdeterministischen Ordnung beruhen. Nehmen Sie als Beispiel die Fensterfunktion ROW_NUMBER. Bei Verwendung mit partieller Bestellung (Ordnung nach Elementen, die die Zeile nicht eindeutig identifizieren) könnte jede Auswertung der zugrunde liegenden Abfrage zu einer anderen Zuordnung der Zeilennummern führen, auch wenn sich die zugrunde liegenden Daten nicht geändert haben. Denken Sie bei mehreren CTE-Referenzen daran, dass jede separat entschachtelt wird und Sie unterschiedliche Resultsets erhalten können. Je nachdem, was die äußere Abfrage mit jeder Referenz macht, z. Mit welchen Spalten aus jeder Referenz er interagiert und wie, kann der Optimierer entscheiden, auf die Daten für jede der Instanzen zuzugreifen, indem er verschiedene Indizes mit unterschiedlichen Sortieranforderungen verwendet.
Betrachten Sie den folgenden Code als Beispiel:
TSQLV5 VERWENDEN; WITH C AS( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1.rownum =C2. rownumWHERE C1.orderid <> C2.orderid;
Kann diese Abfrage jemals eine nicht leere Ergebnismenge zurückgeben? Vielleicht ist Ihre erste Reaktion, dass dies nicht möglich ist. Aber denken Sie etwas genauer über das nach, was ich gerade erklärt habe, und Sie werden feststellen, dass dies zumindest theoretisch aufgrund der zwei separaten CTE-Entschachtelungsprozesse, die hier stattfinden werden – einer von C1 und einer von C2 – möglich ist. Es ist jedoch eine Sache, zu theoretisieren, dass etwas passieren kann, und eine andere, es zu demonstrieren. Als ich beispielsweise diesen Code ausführte, ohne neue Indizes zu erstellen, erhielt ich immer wieder eine leere Ergebnismenge:
orderid shipcountry orderid---------- --------------- -----------(0 Zeilen betroffen)Ich habe den in Abbildung 23 gezeigten Plan für diese Abfrage erhalten.
Abbildung 2:Erster Plan für eine Abfrage mit zwei CTE-Referenzen
Interessant ist hier, dass der Optimierer sich entschieden hat, verschiedene Indizes zu verwenden, um die verschiedenen CTE-Referenzen zu handhaben, weil er dies als optimal erachtete. Schließlich betrifft jede Referenz in der äußeren Abfrage eine andere Teilmenge der CTE-Spalten. Eine Referenz führte zu einem geordneten Vorwärtsscan des Indexes idx_nc_orderedate und der andere zu einem ungeordneten Scan des Clustered-Index, gefolgt von einer Sortieroperation nach aufsteigendem Bestelldatum. Obwohl der Index idx_nc_orderedate explizit nur für die Spalte orderdate als Schlüssel definiert ist, ist er in der Praxis für (orderdate, orderid) als Schlüssel definiert, da orderid der Clustered-Index-Schlüssel ist und als letzter Schlüssel in allen Nonclustered-Indizes enthalten ist. Ein geordneter Scan des Index gibt also tatsächlich die nach Bestelldatum, Bestell-ID geordneten Zeilen aus. Was den ungeordneten Scan des Clustered-Index betrifft, so werden die Daten auf Speicher-Engine-Ebene in der Reihenfolge der Indexschlüssel (basierend auf orderid) gescannt, um minimale Konsistenzerwartungen an die standardmäßige Isolationsstufe Read Committed zu erfüllen. Der Sort-Operator nimmt daher die nach orderid geordneten Daten auf, sortiert die Zeilen nach orderdate und gibt in der Praxis die nach orderdate, orderid geordneten Zeilen aus.
Auch hier gibt es theoretisch keine Garantie dafür, dass die beiden Referenzen immer dieselbe Ergebnismenge darstellen, selbst wenn sich die zugrunde liegenden Daten nicht ändern. Eine einfache Möglichkeit, dies zu demonstrieren, besteht darin, zwei verschiedene optimale Indizes für die beiden Referenzen anzuordnen, aber einen die Daten nach Bestelldatum ASC, Bestell-ID ASC und der andere die Daten nach Bestelldatum DESC, Bestell-ID ASC (oder genau das Gegenteil) ordnen zu lassen. Wir haben bereits den früheren Index an Ort und Stelle. Hier ist der Code, um letzteres zu erstellen:
CREATE INDEX idx_nc_odD_oid_I_sc ON Sales.Orders(orderdate DESC, orderid) INCLUDE(shipcountry);Führen Sie den Code ein zweites Mal aus, nachdem Sie den Index erstellt haben:
WITH C AS( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1.rownum =C2.rownumWHERE C1.orderid <> C2.orderid;Ich habe die folgende Ausgabe erhalten, als ich diesen Code nach dem Erstellen des neuen Index ausgeführt habe:
orderid shipcountry orderid---------- ---------- -----------10251 Frankreich 1025010250 Brasilien 1025110261 Brasilien 1026010260 Deutschland 1026110271 USA 10270...11070 Deutschland 1107311077 USA 1107411076 Frankreich 1107511075 Schweiz 1107611074 Dänemark 11077 (546 Zeilen betroffen)Hoppla.
Untersuchen Sie den Abfrageplan für diese Ausführung wie in Abbildung 3 gezeigt:
Abbildung 3:Zweiter Abfrageplan mit zwei CTE-Referenzen
Beachten Sie, dass der oberste Zweig des Plans den Index idx_nc_orderdate in einer geordneten Vorwärtsweise scannt, was dazu führt, dass der Sequence Project-Operator, der die Zeilennummern berechnet, die Daten in der Praxis geordnet nach orderdate ASC, orderid ASC aufnimmt. Der untere Zweig des Plans scannt den neuen Index idx_nc_odD_oid_I_sc in einer geordneten Rückwärtsweise, wodurch der Sequence Project-Operator veranlasst wird, die Daten in der Praxis geordnet nach Bestelldatum ASC, Bestell-ID DESC aufzunehmen. Dies führt zu einer unterschiedlichen Anordnung der Zeilennummern für die beiden CTE-Referenzen, wenn der gleiche Wert für das Bestelldatum mehr als einmal vorkommt. Folglich generiert die Abfrage eine nicht leere Ergebnismenge.
Wenn Sie solche Fehler vermeiden möchten, besteht eine offensichtliche Option darin, das innere Abfrageergebnis in einem temporären Objekt wie einer temporären Tabelle oder Tabellenvariablen zu speichern. Wenn Sie jedoch eine Situation haben, in der Sie lieber CTEs verwenden möchten, besteht eine einfache Lösung darin, die Gesamtreihenfolge in der Fensterfunktion zu verwenden, indem Sie einen Tiebreaker hinzufügen. Stellen Sie mit anderen Worten sicher, dass Sie nach einer Kombination von Ausdrücken sortieren, die eine Zeile eindeutig identifiziert. In unserem Fall können Sie einfach orderid explizit als Tiebreaker hinzufügen, etwa so:
WITH C AS( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate, orderid) AS rownum FROM Sales.Orders)SELECT C1.orderid, C1.shipcountry, C2.orderidFROM C AS C1 INNER JOIN C AS C2 ON C1 .rownum =C2.rownumWHERE C1.orderid <> C2.orderid;Sie erhalten wie erwartet eine leere Ergebnismenge:
orderid shipcountry orderid---------- --------------- -----------(0 Zeilen betroffen)Ohne weitere Indizes hinzuzufügen, erhalten Sie den in Abbildung 4 gezeigten Plan:
Abbildung 4:Dritter Plan für Abfrage mit zwei CTE-Referenzen
Der obere Zweig des Plans ist derselbe wie beim vorherigen Plan in Abbildung 3. Der untere Zweig ist jedoch etwas anders. Der zuvor erstellte neue Index ist nicht wirklich ideal für die neue Abfrage, da er nicht die Daten enthält, die wie von der ROW_NUMBER-Funktion benötigt werden (orderdate, orderid). Es ist immer noch der engste abdeckende Index, den der Optimierer für seine jeweilige CTE-Referenz finden konnte, also wird er ausgewählt; Es wird jedoch in der Reihenfolge Ordered:False gescannt. Ein expliziter Sort-Operator sortiert dann die Daten nach Bestelldatum, Bestell-ID, wie es die ROW_NUMBER-Berechnung benötigt. Natürlich können Sie die Indexdefinition so ändern, dass sowohl orderdate als auch orderid die gleiche Richtung verwenden und auf diese Weise die explizite Sortierung aus dem Plan eliminiert wird. Der Hauptpunkt ist jedoch, dass Sie durch die Verwendung der Gesamtreihenfolge vermeiden, aufgrund dieses speziellen Fehlers in Schwierigkeiten zu geraten.
Wenn Sie fertig sind, führen Sie den folgenden Code zur Bereinigung aus:
INDEX DROP IF EXISTS idx_nc_odD_oid_I_sc ON Sales.Orders;Schlussfolgerung
Es ist wichtig zu verstehen, dass mehrere Verweise auf denselben CTE von einer äußeren Abfrage zu separaten Auswertungen der inneren Abfrage des CTE führen. Seien Sie besonders vorsichtig bei nichtdeterministischen Berechnungen, da die unterschiedlichen Auswertungen zu unterschiedlichen Werten führen können.
Wenn Sie Fensterfunktionen wie ROW_NUMBER und Aggregate mit einem Rahmen verwenden, stellen Sie sicher, dass Sie die Gesamtreihenfolge verwenden, um zu vermeiden, dass Sie unterschiedliche Ergebnisse für dieselbe Zeile in den verschiedenen CTE-Referenzen erhalten.