Dieser Beitrag ist „mit Bedingungen verbunden:aus gutem Grund. Wir werden uns tief mit SQL VARCHAR befassen, dem Datentyp, der sich mit Strings befasst.
Außerdem ist dies „nur für Ihre Augen“, denn ohne Schnüre gibt es keine Blogposts, Webseiten, Spielanleitungen, mit Lesezeichen versehenen Rezepte und vieles mehr, das unsere Augen lesen und genießen können. Wir haben es jeden Tag mit einer Unmenge Saiten zu tun. Als Entwickler sind Sie und ich dafür verantwortlich, diese Art von Daten effizient zu speichern und darauf zuzugreifen.
In diesem Sinne werden wir behandeln, was für die Speicherung und Leistung am besten ist. Geben Sie die Gebote und Verbote für diesen Datentyp ein.
Aber vorher ist VARCHAR nur einer der Zeichenfolgentypen in SQL. Was macht es anders?
Was ist VARCHAR in SQL? (Mit Beispielen)
VARCHAR ist ein Zeichenfolgen- oder Zeichendatentyp unterschiedlicher Größe. Sie können damit Buchstaben, Zahlen und Symbole speichern. Ab SQL Server 2019 können Sie die gesamte Bandbreite an Unicode-Zeichen verwenden, wenn Sie eine Sortierung mit UTF-8-Unterstützung verwenden.
Sie können VARCHAR-Spalten oder -Variablen mit VARCHAR[(n)] deklarieren, wobei n steht für die Stringgröße in Byte. Der Wertebereich für n ist 1 bis 8000. Das sind viele Zeichendaten. Aber noch mehr, Sie können es mit VARCHAR(MAX) deklarieren, wenn Sie eine gigantische Zeichenfolge von bis zu 2 GB benötigen. Das ist groß genug für deine Liste mit Geheimnissen und privaten Dingen in deinem Tagebuch! Beachten Sie jedoch, dass Sie es auch ohne die Größe deklarieren können und es standardmäßig auf 1 gesetzt wird, wenn Sie dies tun.
Lassen Sie uns ein Beispiel haben.
DECLARE @actor VARCHAR(20) = 'Robert Downey Jr.';
DECLARE @movieCharacter VARCHAR(10) = 'Iron Man';
DECLARE @movie VARCHAR = 'Avengers';
SELECT @actor, @movieCharacter, @movie
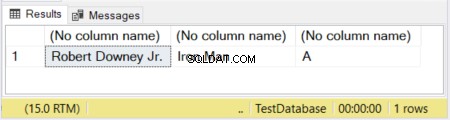
In Abbildung 1 sind die Größen der ersten beiden Spalten definiert. Die dritte Spalte bleibt ohne Größe. Das Wort „Avengers“ wird also abgeschnitten, weil ein VARCHAR ohne deklarierte Größe standardmäßig 1 Zeichen lang ist.
Lassen Sie uns jetzt etwas Großes versuchen. Beachten Sie jedoch, dass diese Abfrage eine Weile dauern wird – 23 Sekunden auf meinem Laptop.
-- This will take a while
DECLARE @giganticString VARCHAR(MAX);
SET @giganticString = REPLICATE(CAST('kage bunshin no jutsu' AS VARCHAR(MAX)),100000000)
SELECT DATALENGTH(@giganticString)
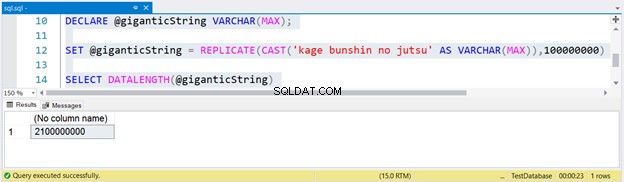
Um eine riesige Kette zu erzeugen, haben wir Kage Bunshin no Jutsu 100 Millionen Mal repliziert. Beachten Sie den CAST in REPLICATE. Wenn Sie den Zeichenfolgenausdruck nicht in VARCHAR(MAX) umwandeln, wird das Ergebnis auf nur bis zu 8000 Zeichen gekürzt.
Aber wie unterscheidet sich SQL VARCHAR von anderen String-Datentypen?
Unterschied zwischen CHAR und VARCHAR in SQL
Im Vergleich zu VARCHAR ist CHAR ein Datentyp für Zeichen mit fester Länge. Ganz gleich, wie klein oder groß der Wert einer CHAR-Variablen ist, die endgültige Größe ist die Größe der Variablen. Sehen Sie sich die Vergleiche unten an.
DECLARE @tvSeriesTitle1 VARCHAR(20) = 'The Mandalorian';
DECLARE @tvSeriesTitle2 CHAR(20) = 'The Mandalorian';
SELECT DATALENGTH(@tvSeriesTitle1) AS VarcharValue,
DATALENGTH(@tvSeriesTitle2) AS CharValue
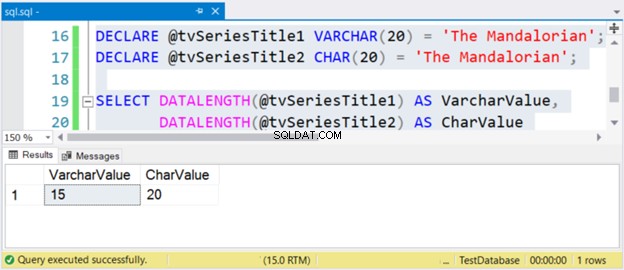
Die Länge der Zeichenfolge „The Mandalorian“ beträgt 15 Zeichen. Also der VarcharValue Spalte gibt es korrekt wieder. Allerdings CharValue behält die Größe von 20 – es wird rechts mit 5 Leerzeichen aufgefüllt.
SQL-VARCHAR vs. NVARCHAR
Beim Vergleich dieser Datentypen fallen mir zwei grundlegende Dinge ein.
Erstens ist es die Größe in Bytes. Jedes Zeichen in NVARCHAR hat die doppelte Größe von VARCHAR. NVARCHAR(n) liegt nur zwischen 1 und 4000.
Dann die Zeichen, die es speichern kann. NVARCHAR kann mehrsprachige Zeichen wie Koreanisch, Japanisch, Arabisch usw. speichern. Wenn Sie vorhaben, koreanische K-Pop-Texte in Ihrer Datenbank zu speichern, ist dieser Datentyp eine Ihrer Optionen.
Lassen Sie uns ein Beispiel haben. Wir verwenden die K-Pop-Gruppe 세븐틴 oder Seventeen auf Englisch.
DECLARE @kpopGroupKorean NVARCHAR(5) = N'세븐틴';
SELECT @kpopGroupKorean AS KPopGroup,
DATALENGTH(@kpopGroupKorean) AS SizeInBytes,
LEN(@kpopGroupKorean) AS [NoOfChars]
Der obige Code gibt den Zeichenfolgenwert, seine Größe in Bytes und die Anzahl der Zeichen aus. Wenn es sich um Nicht-Unicode-Zeichen handelt, entspricht die Anzahl der Zeichen der Größe in Bytes. Dies ist jedoch nicht der Fall. Sehen Sie sich Abbildung 4 unten an.
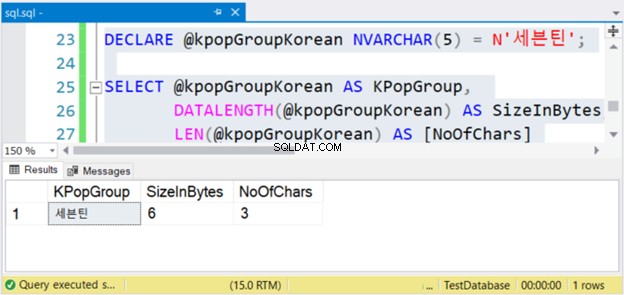
Sehen? Wenn NVARCHAR 3 Zeichen hat, ist die Größe in Byte doppelt so groß. Aber nicht mit VARCHAR. Dasselbe gilt auch, wenn Sie englische Zeichen verwenden.
Aber wie sieht es mit NCHAR aus? NCHAR ist das Gegenstück zu CHAR für Unicode-Zeichen.
SQL Server VARCHAR mit UTF-8-Unterstützung
VARCHAR mit UTF-8-Unterstützung ist auf Serverebene, Datenbankebene oder Tabellenspaltenebene möglich, indem die Sortierungsinformationen geändert werden. Die zu verwendende Sortierung sollte UTF-8 unterstützen.
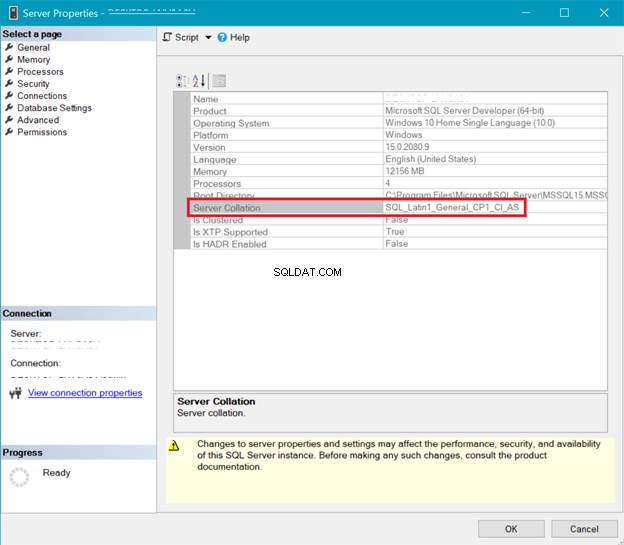
SQL SERVER COLLATION
Abbildung 5 zeigt das Fenster in SQL Server Management Studio, das die Serversortierung anzeigt.
DATENBANKVERGLEICH
In der Zwischenzeit zeigt Abbildung 6 die Sortierung der AdventureWorks Datenbank.
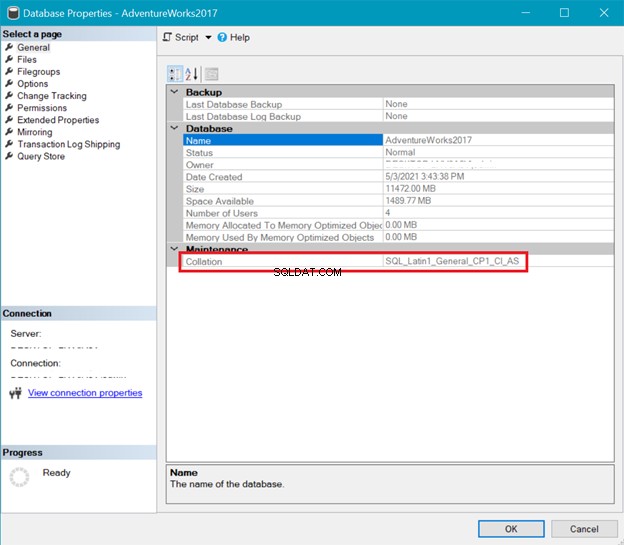
TABLE COLUMN COLLATION
Sowohl die obige Server- als auch die Datenbanksortierung zeigen, dass UTF-8 nicht unterstützt wird. Die Sortierzeichenfolge sollte für die UTF-8-Unterstützung ein _UTF8 enthalten. Sie können die UTF-8-Unterstützung jedoch weiterhin auf Spaltenebene einer Tabelle verwenden. Siehe Beispiel.
CREATE TABLE SeventeenMemberList
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
KoreanName VARCHAR(20) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL,
EnglishName VARCHAR(20) NOT NULL
)
Der obige Code hat Latin1_General_100_BIN2_UTF8 Sortierung für KoreanName Säule. Obwohl VARCHAR und nicht NVARCHAR, akzeptiert diese Spalte koreanische Zeichen. Lassen Sie uns einige Datensätze einfügen und sie dann anzeigen.
INSERT INTO SeventeenMemberList
(KoreanName, EnglishName)
VALUES
(N'에스쿱스','S.Coups')
,(N'원우','Wonwoo')
,(N'민규','Mingyu')
,(N'버논','Vernon')
,(N'우지','Woozi')
,(N'정한','Jeonghan')
,(N'조슈아','Joshua')
,(N'도겸','DK')
,(N'승관','Seungkwan')
,(N'호시','Hoshi')
,(N'준','Jun')
,(N'디에잇','The8')
,(N'디노','Dino')
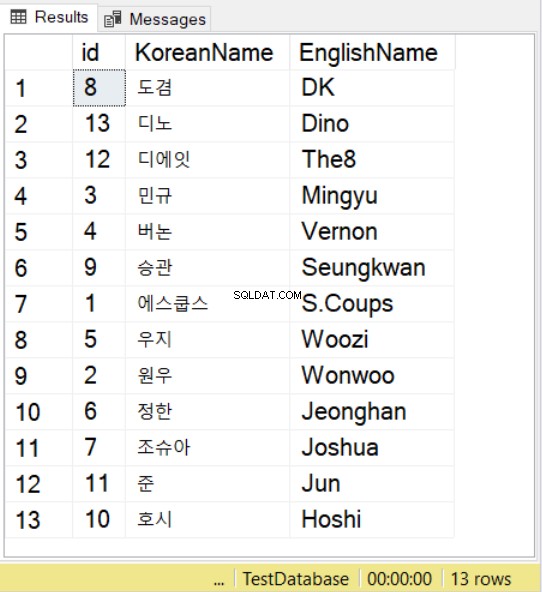
SELECT * FROM SeventeenMemberList
ORDER BY KoreanName
COLLATE Latin1_General_100_BIN2_UTF8
Wir verwenden Namen der Seventeen K-Pop-Gruppe mit koreanischen und englischen Gegenstücken. Beachten Sie bei koreanischen Zeichen, dass Sie dem Wert trotzdem N voranstellen müssen , genau wie bei NVARCHAR-Werten.
Wenn Sie dann SELECT mit ORDER BY verwenden, können Sie auch die Sortierung verwenden. Sie können dies im obigen Beispiel beobachten. Dies folgt den Sortierregeln für die angegebene Sortierung.
SPEICHERUNG VON VARCHAR MIT UTF-8-UNTERSTÜTZUNG
Aber wie ist die Speicherung dieser Zeichen? Wenn Sie 2 Bytes pro Zeichen erwarten, werden Sie überrascht sein. Sehen Sie sich Abbildung 8 an.
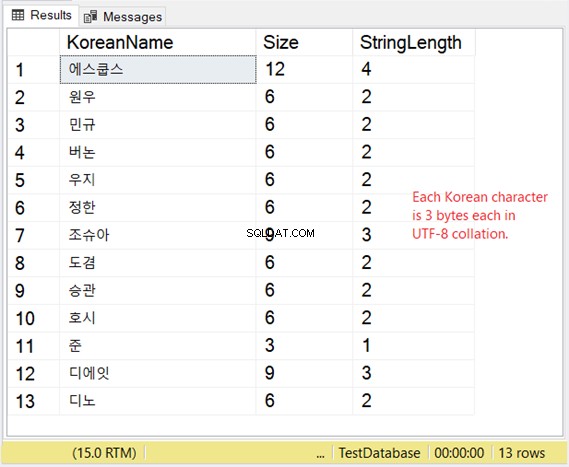
Wenn Ihnen Speicherplatz also sehr wichtig ist, sehen Sie sich die folgende Tabelle an, wenn Sie VARCHAR mit UTF-8-Unterstützung verwenden.
| Zeichen | Größe in Byte |
| ASCII 0 – 127 | 1 |
| Die lateinische Schrift und Griechisch, Kyrillisch, Koptisch, Armenisch, Hebräisch, Arabisch, Syrisch, Tāna und N’Ko | 2 |
| Ostasiatische Schrift wie Chinesisch, Koreanisch und Japanisch | 3 |
| Zeichen im Bereich 010000–10FFFF | 4 |
Unser koreanisches Beispiel ist eine ostasiatische Schrift, also sind es 3 Bytes pro Zeichen.
Nachdem wir nun mit der Beschreibung und dem Vergleich von VARCHAR mit anderen Zeichenfolgentypen fertig sind, wollen wir nun die Do’s and Don’ts behandeln
Do’s in Using VARCHAR in SQL Server
1. Geben Sie die Größe an
Was könnte schief gehen, ohne die Größe anzugeben?
STRING-KÜRZUNG
Wenn Sie bei der Angabe der Größe faul werden, wird die Zeichenfolge abgeschnitten. Ein Beispiel dafür haben Sie bereits gesehen.
AUSWIRKUNGEN AUF SPEICHERUNG UND LEISTUNG
Eine weitere Überlegung betrifft Speicher und Leistung. Sie müssen nur die richtige Größe für Ihre Daten festlegen, nicht mehr. Aber wie konntest du das wissen? Um eine Kürzung in Zukunft zu vermeiden, können Sie es einfach auf die größte Größe einstellen. Das ist VARCHAR(8000) oder sogar VARCHAR(MAX). Und 2 Bytes werden unverändert gespeichert. Bei 2 GB das gleiche. Spielt es eine Rolle?
Die Beantwortung dieser Frage bringt uns zum Konzept, wie SQL Server Daten speichert. Ich habe einen anderen Artikel, der dies ausführlich mit Beispielen und Illustrationen erklärt.
Kurz gesagt, Daten werden in 8-KB-Seiten gespeichert. Wenn eine Datenzeile diese Größe überschreitet, verschiebt SQL Server sie in eine andere Seitenzuordnungseinheit namens ROW_OVERFLOW_DATA.
Angenommen, Sie haben 2-Byte-VARCHAR-Daten, die möglicherweise in die ursprüngliche Seitenzuordnungseinheit passen. Wenn Sie eine Zeichenfolge speichern, die größer als 8000 Byte ist, werden die Daten auf die Zeilenüberlaufseite verschoben. Verkleinern Sie es dann wieder auf eine niedrigere Größe, und es wird wieder auf die ursprüngliche Seite verschoben. Die Hin- und Herbewegung verursacht viel I/O und einen Performance-Engpass. Das Abrufen von 2 Seiten anstelle von 1 erfordert auch zusätzliche E/A.
Ein weiterer Grund ist die Indizierung. VARCHAR(MAX) ist ein großes NEIN als Indexschlüssel. In der Zwischenzeit überschreitet VARCHAR(8000) die maximale Indexschlüsselgröße. Das sind 1700 Byte für Non-Clustered-Indizes und 900 Byte für Clustered-Indizes.
AUSWIRKUNGEN AUF DIE DATENKONVERTIERUNG
Es gibt jedoch noch eine weitere Überlegung:Datenkonvertierung. Probieren Sie es mit einem CAST ohne die Größe wie im Code unten aus.
SELECT
SYSDATETIMEOFFSET() AS DateTimeInput
,CAST(SYSDATETIMEOFFSET() AS VARCHAR) AS ConvertedDateTime
,DATALENGTH(CAST(SYSDATETIMEOFFSET() AS VARCHAR)) AS ConvertedLength
Dieser Code konvertiert Datum/Uhrzeit mit Zeitzoneninformationen in VARCHAR.
Wenn wir also beim Angeben der Größe während CAST oder CONVERT faul werden, ist das Ergebnis auf nur 30 Zeichen begrenzt.
Wie wäre es mit der Konvertierung von NVARCHAR in VARCHAR mit UTF-8-Unterstützung? Dazu gibt es später eine ausführliche Erklärung, also lies weiter.
2. Verwenden Sie VARCHAR, wenn die Zeichenfolgengröße erheblich variiert
Namen aus den AdventureWorks Datenbank unterschiedlich groß. Einer der kürzesten Namen ist Min Su, während der längste Name Osarumwense Uwaifiokun Agbonile ist. Das sind zwischen 6 und 31 Zeichen einschließlich der Leerzeichen. Lassen Sie uns diese Namen in 2 Tabellen importieren und zwischen VARCHAR und CHAR vergleichen.
-- Table using VARCHAR
CREATE TABLE VarcharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
varcharName VARCHAR(50) NOT NULL
)
GO
CREATE INDEX IX_VarcharAsIndexKey_varcharName ON VarcharAsIndexKey(varcharName)
GO
-- Table using CHAR
CREATE TABLE CharAsIndexKey
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
charName CHAR(50) NOT NULL
)
GO
CREATE INDEX IX_CharAsIndexKey_charName ON CharAsIndexKey(charName)
GO
INSERT INTO VarcharAsIndexKey (varcharName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
INSERT INTO CharAsIndexKey (charName)
SELECT DISTINCT
LastName + ', ' + FirstName + ' ' + ISNULL(MiddleName,'')
FROM AdventureWorks.Person.Person
GO
Welche der 2 sind besser? Lassen Sie uns die logischen Lesevorgänge überprüfen, indem Sie den folgenden Code verwenden und die Ausgabe von STATISTICS IO überprüfen.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT id, varcharName
FROM VarcharAsIndexKey
SELECT id, charName
FROM CharAsIndexKey
SET STATISTICS IO OFF
Logische Lesevorgänge:
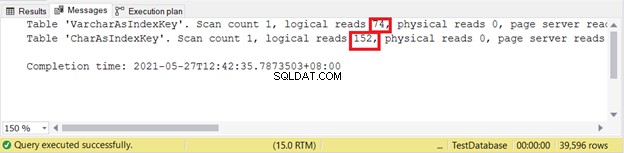
Je weniger logisch liest, desto besser. Hier verwendete die CHAR-Spalte mehr als das Doppelte des VARCHAR-Gegenstücks. Somit gewinnt VARCHAR in diesem Beispiel.
3. Verwenden Sie VARCHAR als Indexschlüssel anstelle von CHAR, wenn Werte in der Größe variieren
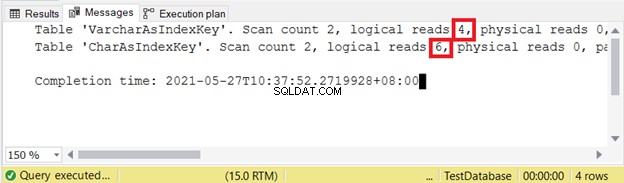
Was passiert, wenn sie als Indexschlüssel verwendet werden? Wird CHAR besser abschneiden als VARCHAR? Lassen Sie uns dieselben Daten aus dem vorherigen Abschnitt verwenden und diese Frage beantworten.
Wir werden einige Daten abfragen und die logischen Lesevorgänge überprüfen. In diesem Beispiel verwendet der Filter den Indexschlüssel.
SET NOCOUNT ON
SET STATISTICS IO ON
SELECT varcharName FROM VarcharAsIndexKey
WHERE varcharName = 'Sai, Adriana A'
OR varcharName = 'Rogers, Caitlin D'
SELECT charName FROM CharAsIndexKey
WHERE charName = 'Sai, Adriana A'
OR charName = 'Rogers, Caitlin D'
SET STATISTICS IO OFF
Logische Lesevorgänge:
Daher sind VARCHAR-Indexschlüssel besser als CHAR-Indexschlüssel, wenn der Schlüssel unterschiedliche Größen hat. Aber wie wäre es mit INSERT und UPDATE, die die Indexeinträge ändern?
BEI VERWENDUNG VON EINFÜGEN UND AKTUALISIEREN
Lassen Sie uns 2 Fälle testen und dann die logischen Lesevorgänge überprüfen, wie wir es normalerweise tun.
SET STATISTICS IO ON
INSERT INTO VarcharAsIndexKey (varcharName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
INSERT INTO CharAsIndexKey (charName)
VALUES ('Ruffalo, Mark'), ('Johansson, Scarlett')
SET STATISTICS IO OFF
Logische Lesevorgänge:
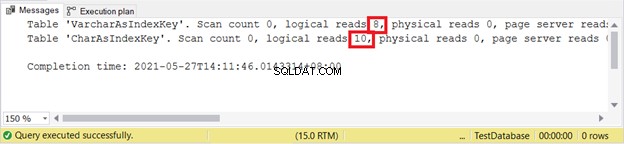
VARCHAR ist immer noch besser beim Einfügen von Datensätzen. Wie wäre es mit UPDATE?
SET STATISTICS IO ON
UPDATE VarcharAsIndexKey
SET varcharName = 'Hulk'
WHERE varcharName = 'Ruffalo, Mark'
UPDATE CharAsIndexKey
SET charName = 'Hulk'
WHERE charName = 'Ruffalo, Mark'
SET STATISTICS IO OFF
Logische Lesevorgänge:
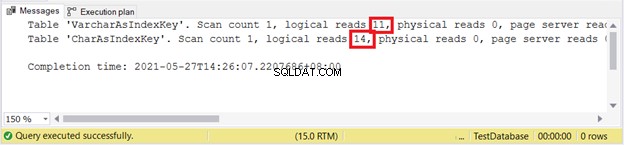
Sieht so aus, als würde VARCHAR erneut gewinnen.
Schließlich gewinnt es unseren Test, obwohl es vielleicht klein ist. Haben Sie einen größeren Testfall, der das Gegenteil beweist?
4. Betrachten Sie VARCHAR mit UTF-8-Unterstützung für mehrsprachige Daten (SQL Server 2019+)
Wenn Ihre Tabelle eine Mischung aus Unicode- und Nicht-Unicode-Zeichen enthält, können Sie VARCHAR mit UTF-8-Unterstützung gegenüber NVARCHAR in Betracht ziehen. Wenn die meisten Zeichen im Bereich von ASCII 0 bis 127 liegen, kann es im Vergleich zu NVARCHAR zu Platzeinsparungen führen.
Um zu sehen, was ich meine, lassen Sie uns einen Vergleich anstellen.
NVARCHAR ZU VARCHAR MIT UTF-8-UNTERSTÜTZUNG
Haben Sie Ihre Datenbanken bereits auf SQL Server 2019 migriert? Planen Sie, Ihre Zeichenfolgendaten in die UTF-8-Sortierung zu migrieren? Wir haben ein Beispiel für einen gemischten Wert aus japanischen und nicht japanischen Zeichen, um Ihnen eine Vorstellung zu geben.
CREATE TABLE NVarcharToVarcharUTF8
(
NVarcharValue NVARCHAR(20) NOT NULL,
VarcharUTF8 VARCHAR(45) COLLATE Latin1_General_100_BIN2_UTF8 NOT NULL
)
GO
INSERT INTO NVarcharToVarcharUTF8
(NVarcharValue, VarcharUTF8)
VALUES
(N'NARUTO-ナルト- 疾風伝',N'NARUTO-ナルト- 疾風伝'); -- NARUTO Shippûden
SELECT
NVarcharValue
,LEN(NVarcharValue) AS nvarcharNoOfChars
,DATALENGTH(NVarcharValue) AS nvarcharSizeInBytes
,VarcharUTF8
,LEN(VarcharUTF8) AS varcharNoOfChars
,DATALENGTH(VarcharUTF8) AS varcharSizeInBytes
FROM NVarcharToVarcharUTF8
Nachdem die Daten nun festgelegt sind, prüfen wir die Größe der beiden Werte in Byte:

Überraschung! Bei NVARCHAR beträgt die Größe 30 Bytes. Das sind 15 mal mehr als 2 Zeichen. Bei der Konvertierung in VARCHAR mit UTF-8-Unterstützung beträgt die Größe jedoch nur 27 Bytes. Warum 27? Überprüfen Sie, wie dies berechnet wird.

Somit sind 9 der Zeichen jeweils 1 Byte. Das ist interessant, denn mit NVARCHAR sind englische Buchstaben auch 2 Bytes groß. Die restlichen japanischen Zeichen umfassen jeweils 3 Byte.
Wenn dies alles japanische Zeichen gewesen wären, wäre die 15-stellige Zeichenfolge 45 Bytes groß und würde auch die maximale Größe von VarcharUTF8 verbrauchen Säule. Beachten Sie, dass die Größe von NVarcharValue Spalte ist kleiner als VarcharUTF8 .
Die Größen können beim Konvertieren von NVARCHAR nicht gleich sein, oder die Daten passen möglicherweise nicht. Sie können sich auf die vorherige Tabelle 1 beziehen.
Berücksichtigen Sie die Auswirkungen auf die Größe, wenn Sie NVARCHAR in VARCHAR mit UTF-8-Unterstützung konvertieren.
Don’ts bei der Verwendung von VARCHAR in SQL Server
1. Wenn die Zeichenfolgengröße fest und nicht nullbar ist, verwenden Sie stattdessen CHAR.
Die allgemeine Faustregel, wenn eine Zeichenfolge mit fester Größe erforderlich ist, ist die Verwendung von CHAR. Ich befolge dies, wenn ich eine Datenanforderung habe, die rechts aufgefüllte Leerzeichen benötigt. Andernfalls verwende ich VARCHAR. Ich hatte ein paar Anwendungsfälle, in denen ich Zeichenfolgen mit fester Länge ohne Trennzeichen in eine Textdatei für einen Client kopieren musste.
Außerdem verwende ich CHAR-Spalten nur, wenn die Spalten nicht nullfähig sind. Wieso den? Weil die Größe in Bytes von CHAR-Spalten bei NULL gleich der definierten Größe der Spalte ist. Doch VARCHAR, wenn NULL eine Größe von 1 hat, egal wie groß die definierte Größe ist. Führen Sie den folgenden Code aus und überzeugen Sie sich selbst.
DECLARE @charValue CHAR(50) = NULL;
DECLARE @varcharValue VARCHAR(1000) = NULL;
SELECT
DATALENGTH(ISNULL(@charvalue,0)) AS CharSize
,DATALENGTH(ISNULL(@varcharvalue,0)) AS VarcharSize
2. Verwenden Sie VARCHAR(n) nicht, wenn n Wird 8000 Bytes überschreiten. Verwenden Sie stattdessen VARCHAR(MAX).
Haben Sie eine Zeichenfolge, die 8000 Byte überschreitet? Dies ist die Zeit, um VARCHAR(MAX) zu verwenden. Aber für die gängigsten Datenformen wie Namen und Adressen ist VARCHAR(MAX) zu viel des Guten und wirkt sich auf die Leistung aus. Nach meiner persönlichen Erfahrung erinnere ich mich nicht an eine Anforderung, dass ich VARCHAR(MAX) verwendet habe.
3. Bei Verwendung mehrsprachiger Zeichen mit SQL Server 2017 und niedriger. Verwenden Sie stattdessen NVARCHAR.
Dies ist eine naheliegende Wahl, wenn Sie noch SQL Server 2017 und niedriger verwenden.
Das Endergebnis
Der Datentyp VARCHAR hat uns in so vielen Aspekten gute Dienste geleistet. Bei mir war das seit SQL Server 7 der Fall. Trotzdem treffen wir manchmal immer noch schlechte Entscheidungen. In diesem Beitrag wird SQL VARCHAR definiert und anhand von Beispielen mit anderen String-Datentypen verglichen. Und noch einmal, hier sind die Gebote und Verbote für eine schnellere Datenbank:
Do’s:
- Geben Sie die Größe n an in VARCHAR[(n)], auch wenn es optional ist.
- Verwenden Sie es, wenn die Zeichenfolgengröße erheblich variiert.
- Betrachten Sie VARCHAR-Spalten als Indexschlüssel anstelle von CHAR.
- Und wenn Sie jetzt SQL Server 2019 verwenden, ziehen Sie VARCHAR für mehrsprachige Zeichenfolgen mit UTF-8-Unterstützung in Betracht.
Don'ts:
- Verwenden Sie VARCHAR nicht, wenn die Zeichenfolgengröße fest und nicht nullfähig ist.
- Verwenden Sie VARCHAR(n) nicht, wenn die Zeichenfolgengröße 8000 Byte überschreitet.
- Und verwenden Sie VARCHAR nicht für mehrsprachige Daten, wenn Sie SQL Server 2017 und früher verwenden.
Haben Sie noch etwas hinzuzufügen? Lassen Sie es uns im Kommentarbereich wissen. Wenn Sie der Meinung sind, dass dies Ihren Entwicklerfreunden helfen wird, teilen Sie dies bitte auf Ihren bevorzugten Social-Media-Plattformen.