Dies ist der vierte Teil einer fünfteiligen Reihe, die einen tiefen Einblick in die Art und Weise gibt, wie parallele Pläne im SQL Server-Zeilenmodus ausgeführt werden. Teil 1 initialisierte den Ausführungskontext Null für die übergeordnete Aufgabe, und Teil 2 erstellte den Abfrage-Scan-Baum. Teil 3 startete den Abfrage-Scan, führte eine frühe Phase durch Verarbeitung und startete die ersten zusätzlichen parallelen Tasks im Zweig C.
Details zur Ausführung von Zweig C
Dies ist der zweite Schritt der Ausführungssequenz:
- Zweig A (übergeordnete Aufgabe).
- Zweig C (zusätzliche parallele Aufgaben).
- Zweig D (zusätzliche parallele Aufgaben).
- Zweig B (zusätzliche parallele Aufgaben).
Eine Erinnerung an die Filialen in unserem parallelen Plan (zum Vergrößern anklicken)
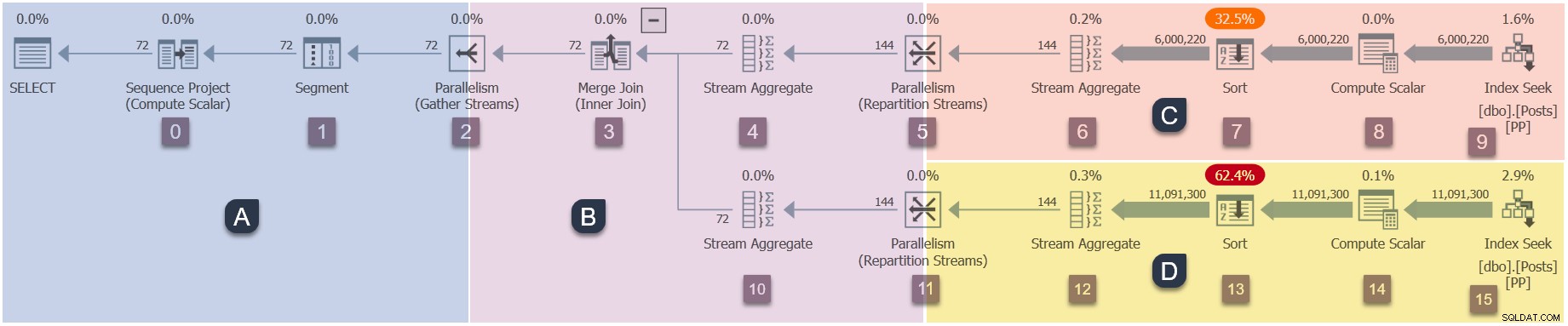
Kurze Zeit nach den neuen Aufgaben für Zweig C in die Warteschlange gestellt werden, hängt SQL Server einen Worker an zu jeder Aufgabe und setzt den Arbeiter in einen Scheduler zur Ausführung bereit. Jede neue Aufgabe wird in einem neuen Ausführungskontext ausgeführt. Bei DOP 2 gibt es zwei neue Tasks, zwei Worker-Threads und zwei Ausführungskontexte für Zweig C. Jeder Task führt seine eigene Kopie der Iteratoren in Zweig C auf seinem eigenen Worker-Thread aus:

Die beiden neuen parallelen Aufgaben beginnen bei einer Unterprozedur zu laufen Einstiegspunkt, der zunächst zu einem Open führt Aufruf auf der Produzentenseite des Austauschs (CQScanXProducerNew::Open ). Beide Aufgaben haben zu Beginn ihres Lebens identische Aufruflisten:
Exchange-Synchronisierung
In der Zwischenzeit die übergeordnete Aufgabe (der auf seinem eigenen Worker-Thread läuft) registriert die neuen Unterprozesse beim Unterprozess-Manager und wartet auf der Verbraucherseite der Repartitionsströme tauschen sich am Knoten 5 aus. Die übergeordnete Aufgabe wartet auf CXPACKET * bis alle der parallelen Tasks von Zweig C schließen ihr Open ab Anrufe und kehren zur Produzentenseite der Börse zurück. Die parallelen Aufgaben öffnen jeden Iterator in ihrem Unterbaum (d. h. bis hinunter zur Indexsuche bei Knoten 9 und zurück), bevor sie zum Austausch der Repartitionsströme bei Knoten 5 zurückkehrt. Die Elternaufgabe wartet auf CXPACKET während dies geschieht. Denken Sie daran, dass die übergeordnete Aufgabe Aufrufe in frühen Phasen ausführt.
Wir können dieses Warten in den wartenden Aufgaben DMV sehen:

Der Ausführungskontext Null (die übergeordnete Aufgabe) wird von beiden neuen Ausführungskontexten blockiert. Diese Ausführungskontexte sind die ersten zusätzlichen, die nach dem Kontext Null erstellt werden, daher werden ihnen die Nummern eins und zwei zugewiesen. Zur Betonung:Beide neuen Ausführungskontexte müssen ihre Teilbäume öffnen und zum Austausch für das CXPACKET der übergeordneten Aufgabe zurückkehren auf Ende warten.
Vielleicht haben Sie erwartet, CXCONSUMER zu sehen wartet hier, aber dieses Warten ist für das Warten auf Zeilendaten reserviert ankommen. Die aktuelle Wartezeit gilt nicht für Zeilen — es ist für die Herstellerseite zu öffnen , also erhalten wir ein generisches CXPACKET * warte.
* Azure SQL-Datenbank und verwaltete Instanzen verwenden den neuen CXSYNC_PORT warten statt CXPACKET hier, aber diese Verbesserung ist noch nicht in SQL Server angekommen (Stand 2019 CU9).
Inspizieren der neuen parallelen Aufgaben
Wir können die neuen Aufgaben in den Abfrageprofilen sehen DMV. Profilinformationen für die neuen Aufgaben erscheinen in der DMV, da ihre Ausführungskontexte vom übergeordneten Element (Ausführungskontext Null) abgeleitet (geklont und dann aktualisiert) wurden:
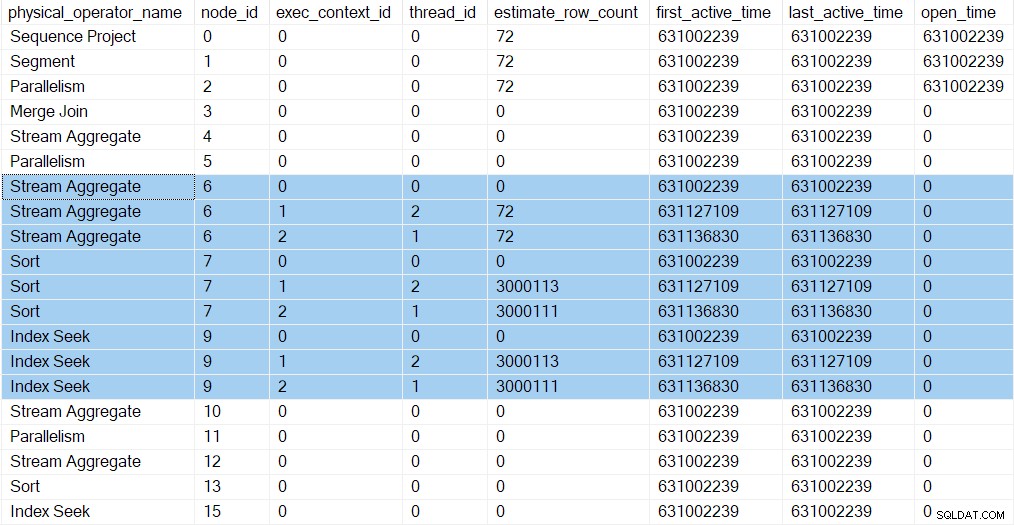
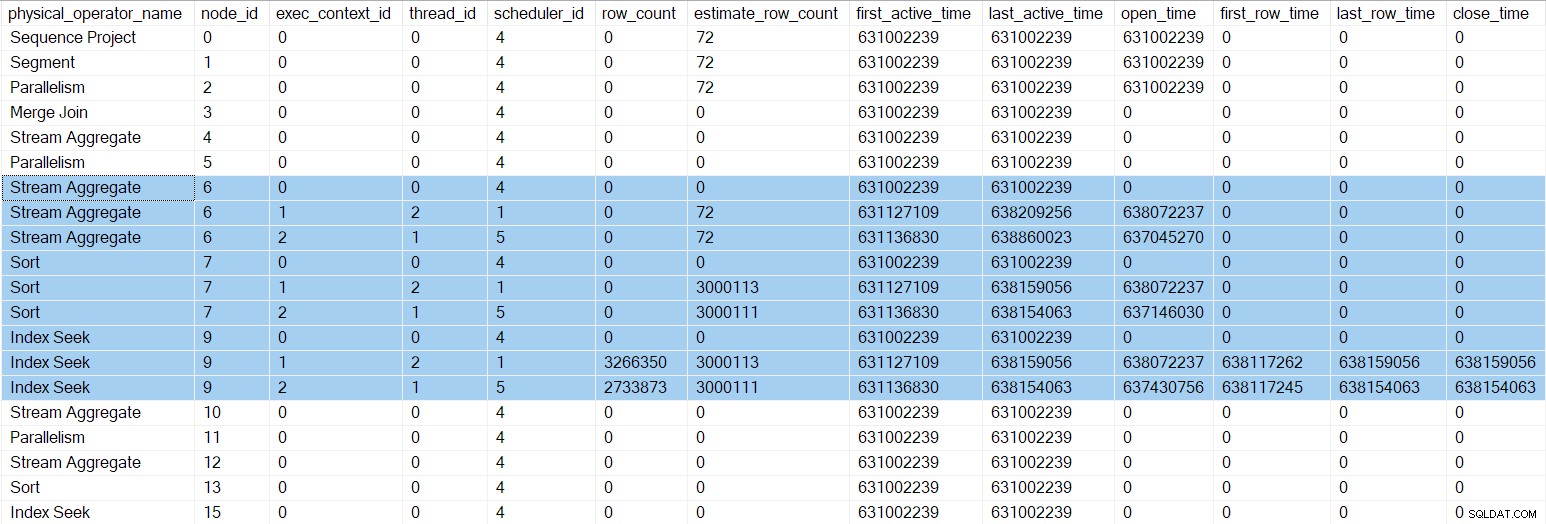
Es gibt jetzt drei Einträge für jeden Iterator in Zweig C (hervorgehoben). Eine für die übergeordnete Aufgabe (Ausführungskontext Null) und eine für jede neue zusätzliche parallele Aufgabe (Kontexte 1 und 2). Beachten Sie, dass die geschätzte Zeilenanzahl pro Thread gilt (siehe Teil 1) sind jetzt eingetroffen und werden nur für die parallelen Aufgaben angezeigt. Die erste und letzte aktive Zeit für die parallelen Aufgaben stellen die Zeit dar, zu der ihre Ausführungskontexte erstellt wurden. Keine der neuen Aufgaben wurde geöffnet noch keine Iteratoren.
Die Repartition-Streams Austausch an Knoten 5 hat immer noch nur einen einzigen Eintrag in der DMV-Ausgabe. Dies liegt daran, dass der zugehörige unsichtbare Profiler den Verbraucher überwacht Seite der Börse. Die zusätzlichen parallelen Tasks befinden sich auf dem Produzenten Seite der Börse. Die Verbraucherseite von Knoten 5 wird irgendwann haben parallele Aufgaben, aber so weit sind wir noch nicht.
Kontrollpunkt
Dies scheint ein guter Punkt zu sein, um eine Atempause einzulegen und zusammenzufassen, wo sich alles im Moment befindet. Im Laufe der Zeit wird es weitere dieser Haltepunkte geben.
- Die übergeordnete Aufgabe ist auf der Verbraucherseite des Austauschs der Repartition-Streams am Knoten 5 , warten auf
CXPACKET. Es befindet sich mitten in der Ausführung von Anrufen in der Frühphase. Es wurde angehalten, um Zweig C zu starten, da dieser Zweig eine blockierende Sortierung enthält. Das Warten der übergeordneten Aufgabe wird fortgesetzt, bis beide parallelen Aufgaben das Öffnen ihrer Teilbäume abgeschlossen haben. - Zwei neue parallele Aufgaben auf der Produzentenseite des Knotens 5 sind bereit, die Iteratoren in Zweig C zu öffnen.
Nichts außerhalb von Zweig C dieses parallelen Ausführungsplans kann Fortschritte machen, bis die übergeordnete Aufgabe von ihrem CXPACKET freigegeben wird warte ab. Denken Sie daran, dass wir bisher nur einen Satz zusätzlicher paralleler Worker für Zweig C erstellt haben. Der einzige andere Thread ist die übergeordnete Aufgabe, und die ist blockiert.
Parallele Ausführung von Zweig C
Die beiden parallelen Aufgaben beginnen auf der Erzeugerseite der Repartition-Streams, die am Knoten 5 ausgetauscht werden. Jeder hat einen separaten (seriellen) Plan mit seiner eigenen Stream-Aggregation, -Sortierung und -Indexsuche. Der Compute-Skalar erscheint nicht im Laufzeitplan, da seine Berechnungen auf die Sortierung verschoben werden.
Jede Instanz der Indexsuche ist parallelbewusst und arbeitet mit disjunkten Mengen von Zeilen. Diese Sätze werden bei Bedarf aus dem übergeordneten Rowset generiert, das zuvor von der übergeordneten Aufgabe (in Teil 1 behandelt) erstellt wurde. Wenn eine der Suchinstanzen einen neuen Teilbereich von Zeilen benötigt, wird sie mit den anderen Worker-Threads synchronisiert, sodass nur einer gleichzeitig einen neuen Teilbereich zuweist. Das verwendete Synchronisationsobjekt wurde ebenfalls zuvor von der übergeordneten Aufgabe erstellt. Wenn eine Aufgabe auf exklusiven Zugriff auf das übergeordnete Rowset wartet, um einen neuen Teilbereich zu erwerben, wartet sie auf CXROWSET_SYNC .
Zweig-C-Aufgaben offen
Die Sequenz von Open Aufrufe für jede Aufgabe in Zweig C ist:
CQScanXProducerNew::Open. Beachten Sie, dass es auf der Produzentenseite einer Börse keinen vorangehenden Profiler gibt. Das ist bedauerlich für Abfragetuner.CXTransLocal::OpenCXPort::RegisterCXTransLocal::ActivateWorkersCQScanProfileNew::Open. Der Profiler über Knoten 6.CQScanStreamAggregateNew::Open(Knoten 6)CQScanProfileNew::Open. Der Profiler über Knoten 7.CQScanSortNew::Open(Knoten 7)
Die Sortierung ist ein vollständig blockierender Operator . Es verbraucht seine gesamte Eingabe während seines Open Forderung. Es gibt hier eine große Anzahl interessanter interner Details zu erkunden, aber der Platz ist knapp, daher werde ich nur die Highlights behandeln:
Die Sortierung baut seine Sortiertabelle auf, indem es seinen Teilbaum öffnet und alle Zeilen verbraucht, die seine Kinder bereitstellen können. Sobald die Sortierung abgeschlossen ist, ist die Sortierung bereit, in den Ausgabemodus überzugehen, und sie gibt die Kontrolle an ihre Eltern zurück. Die Sortierung antwortet später auf GetRow() Aufrufe und gibt jedes Mal die nächste sortierte Zeile zurück. Eine beispielhafte Aufrufliste während der Sortiereingabe ist:
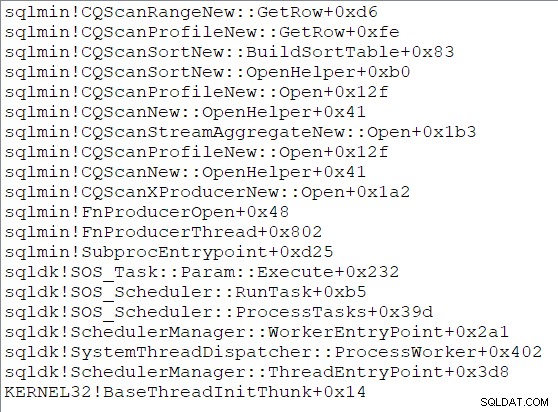
Die Ausführung wird fortgesetzt, bis jede Sortierung alle (nicht zusammenhängenden Bereiche von) Zeilen verbraucht hat, die von ihrer untergeordneten Indexsuche verfügbar sind . Die Sortierung ruft dann Close auf auf den Indexsuchen und geben die Kontrolle an ihr übergeordnetes Stream-Aggregat zurück . Die Stream-Aggregate initialisieren ihre Zähler und geben die Kontrolle an den Produzenten zurück Seite des Partitionsaustauschs bei Knoten 5. Die Sequenz von Open Anrufe sind nun in dieser Branche abgeschlossen.
Die Profilerstellungs-DMV zeigt an dieser Stelle aktualisierte Timing-Zahlen und Schließzeiten für die parallelen Indexsuchen:
Mehr Exchange-Synchronisation
Denken Sie daran, dass die übergeordnete Aufgabe auf den Verbraucher wartet Seite von Knoten 5 für alle Produzenten zu öffnen. Ein ähnlicher Synchronisationsprozess findet nun zwischen den parallelen Tasks auf dem Producer statt Seite derselben Börse:
Jede Producer-Task synchronisiert sich mit den anderen über CXTransLocal::Synchronize . Die Hersteller nennen CXPort::Open , dann auf CXPACKET warten für alle Verbraucherseite parallele Aufgaben zu öffnen. Wenn die erste parallele Aufgabe von Zweig C zurück auf der Erzeugerseite der Vermittlungsstelle ankommt und wartet, sieht die wartende Aufgaben-DMV so aus:

Wir haben immer noch die verbraucherseitigen Wartezeiten der übergeordneten Aufgabe. Das neue CXPACKET Hervorgehoben ist unsere erste produzentenseitige parallele Aufgabe, die auf alle consumer-seitigen parallelen Aufgaben wartet um den Exchange-Port zu öffnen.
Die verbraucherseitigen parallelen Tasks (in Zweig B) existieren noch nicht einmal, sodass die Producer-Task NULL für den Ausführungskontext anzeigt, von dem sie blockiert wird. Die Aufgabe, die derzeit auf der Verbraucherseite des Austauschs der Verteilungsströme wartet, ist die übergeordnete Aufgabe (keine parallele Aufgabe!), die EarlyPhases ausführt Code, also zählt es nicht.
Das Warten auf CXPACKET der übergeordneten Aufgabe endet
Wenn die zweite Die parallele Aufgabe in Zweig C kommt von ihrem Open zurück auf die Erzeugerseite des Austauschs Aufrufe, alle Produzenten haben den Austauschport geöffnet, also die Elternaufgabe auf der Verbraucherseite des Austauschs freigegeben aus seinem CXPACKET warten.
Die Worker auf der Producer-Seite warten weiterhin darauf, dass die parallelen Tasks auf der Consumer-Seite erstellt werden, und öffnen den Exchange-Port:

Kontrollpunkt
Zu diesem Zeitpunkt:
- Es gibt insgesamt drei Aufgaben:Zwei in Zweig C, plus die übergeordnete Aufgabe.
- Beide Produzenten am Knoten 5 haben die Vermittlung geöffnet und warten auf
CXPACKETfür die Verbraucherseite parallele Tasks zu öffnen. Ein Großteil der Austauschmaschinerie (einschließlich Zeilenpuffer) wird von der Verbraucherseite erstellt, daher gibt es für die Produzenten noch keinen Ort, an dem Zeilen platziert werden können. - Die Sorten in Zweig C haben ihre gesamte Eingabe verbraucht und sind bereit, eine sortierte Ausgabe bereitzustellen.
- Der Index sucht in Filiale C haben ihre Arbeit abgeschlossen und geschlossen.
- Die übergeordnete Aufgabe wurde gerade vom Warten auf
CXPACKETbefreit auf der Verbraucherseite des Knotens 5 tauschen die Verteilungsströme aus. Es ist noch Ausführen von verschachteltenEarlyPhasesAnrufe.
Zweig D parallele Aufgaben starten
Dies ist der dritte Schritt in der Ausführungssequenz:
- Zweig A (übergeordnete Aufgabe).
- Zweig C (zusätzliche parallele Aufgaben).
- Zweig D (zusätzliche parallele Aufgaben).
- Zweig B (zusätzliche parallele Aufgaben).
Freigegeben von seinem CXPACKET Warten Sie auf der Verbraucherseite des Verteilungsstromaustauschs an Knoten 5, der Elternaufgabe steigt auf die Zweig-B-Abfrage-Scan-Baumstruktur. Es kehrt von verschachtelten EarlyPhases zurück Aufrufe an die verschiedenen Iteratoren und Profiler an der äußeren (oberen) Eingabe des Merge-Joins.
Wie gesagt, aufsteigend Der Baum aktualisiert die verstrichene Zeit und die CPU-Zeit, die von den unsichtbaren Profiling-Iteratoren aufgezeichnet wurden. Wir führen Code mit der übergeordneten Aufgabe aus, daher werden diese Zahlen im Ausführungskontext Null aufgezeichnet. Dies ist die ultimative Quelle für die „Thread 0“-Timing-Nummern, auf die ich in meinem vorherigen Artikel „Understanding Execution Plan Operator Timings“ verwiesen habe.
Zurück am Zusammenführungsjoin ruft die übergeordnete Aufgabe EarlyPhases auf für die Iteratoren und Profiler auf der inneren (unteren) Eingabe für den Merge-Join. Dies sind Knoten 10 bis 15 (mit Ausnahme von 14, das zurückgestellt wird):
Sobald die Frühphasenaufrufe der übergeordneten Aufgabe die Indexsuche bei Knoten 15 erreichen, beginnt sie erneut, den Baum aufzusteigen (Einstellung der Profilerstellungszeiten), bis sie den Repartition-Streams-Austausch bei Knoten 11 erreicht.
Dann wird, genau wie bei der äußeren (oberen) Eingabe für den Merge-Join, die Producer-Seite gestartet des Austauschs bei Knoten 11 , wodurch zwei neue parallele Aufgaben erstellt werden .
Dies setzt Zweig D in Bewegung (siehe unten). Zweig D wird genau so ausgeführt, wie es bereits im Detail für Zweig C beschrieben wurde.
Unmittelbar nach dem Starten von Aufgaben für Zweig D wartet die übergeordnete Aufgabe auf CXPACKET am Knoten 11 für die neuen Produzenten, um den Austauschport zu öffnen:

Das neue CXPACKET Wartezeiten sind hervorgehoben. Beachten Sie, dass die gemeldete Knoten-ID möglicherweise etwas irreführend ist. Die übergeordnete Aufgabe wartet wirklich auf der Verbraucherseite von Knoten 11 (Streams neu verteilen), nicht auf Knoten 2 (Streams sammeln). Dies ist eine Eigenart der Frühphasenverarbeitung.
Währenddessen warten die Producer-Threads in Zweig C weiterhin auf CXPACKET für die Verbraucherseite des Knotens 5 repartition streams exchange to open.
Eröffnung von Zweig D
Unmittelbar nach der übergeordneten Aufgabe starten die Produzenten für Zweig D, das Abfrageprofil DMV zeigt die neuen Ausführungskontexte (3 und 4):
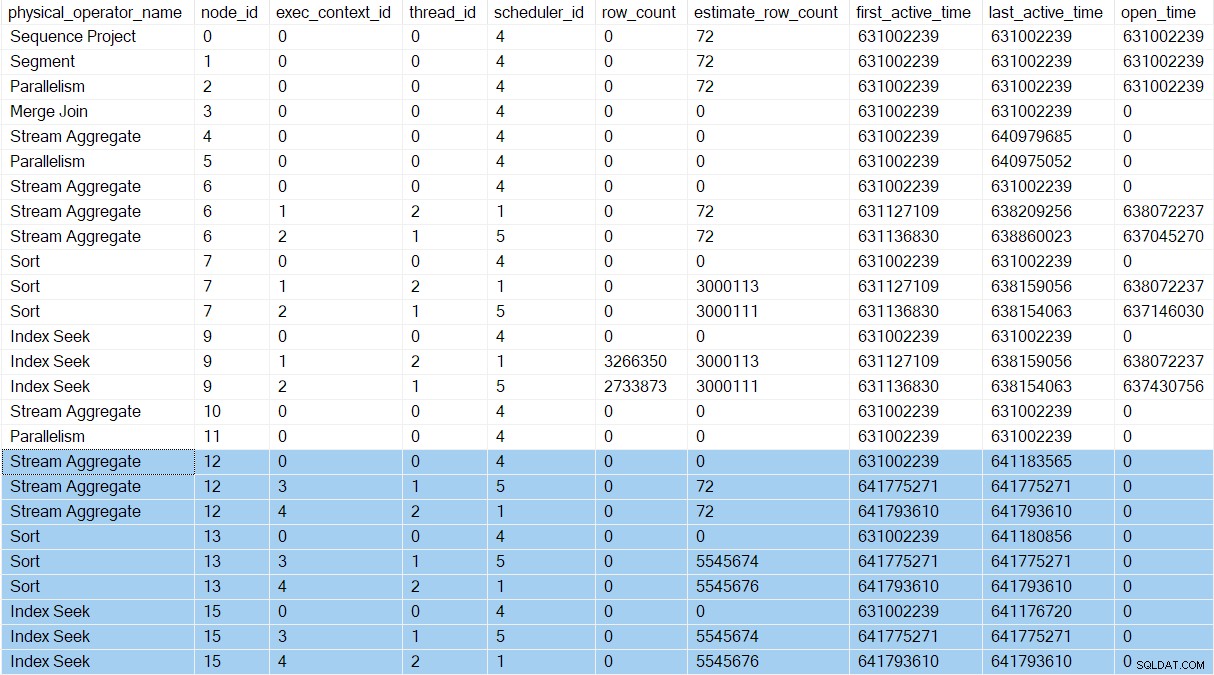
Die zwei neuen parallelen Aufgaben in Zweig D genauso vorgehen wie diejenigen in Zweig C. Die Sortierungen verbrauchen ihre gesamte Eingabe, und die Zweig-D-Aufgaben kehren zum Austausch zurück. Dadurch wird die übergeordnete Aufgabe von ihrem CXPACKET befreit warte ab. Die Arbeiter von Zweig D warten dann auf CXPACKET auf der Erzeugerseite des Knotens 11, damit die Verbraucherseite parallele Tasks öffnet. Diese parallelen Arbeiter (in Zweig B) existieren noch nicht.
Kontrollpunkt
Die an dieser Stelle wartenden Aufgaben werden unten angezeigt:

Beide Sätze paralleler Tasks in den Zweigen C und D warten auf CXPACKET damit sich ihre parallelen Task-Konsumenten öffnen, tauschen die Streams an den Repartition-Strömen die Knoten 5 bzw. 11 aus. Die einzig ausführbare Aufgabe in der gesamten Abfrage ist jetzt die übergeordnete Aufgabe .
Der Abfrage-Profiler DMV an diesem Punkt ist unten dargestellt, wobei die Operatoren in den Zweigen C und D hervorgehoben sind:
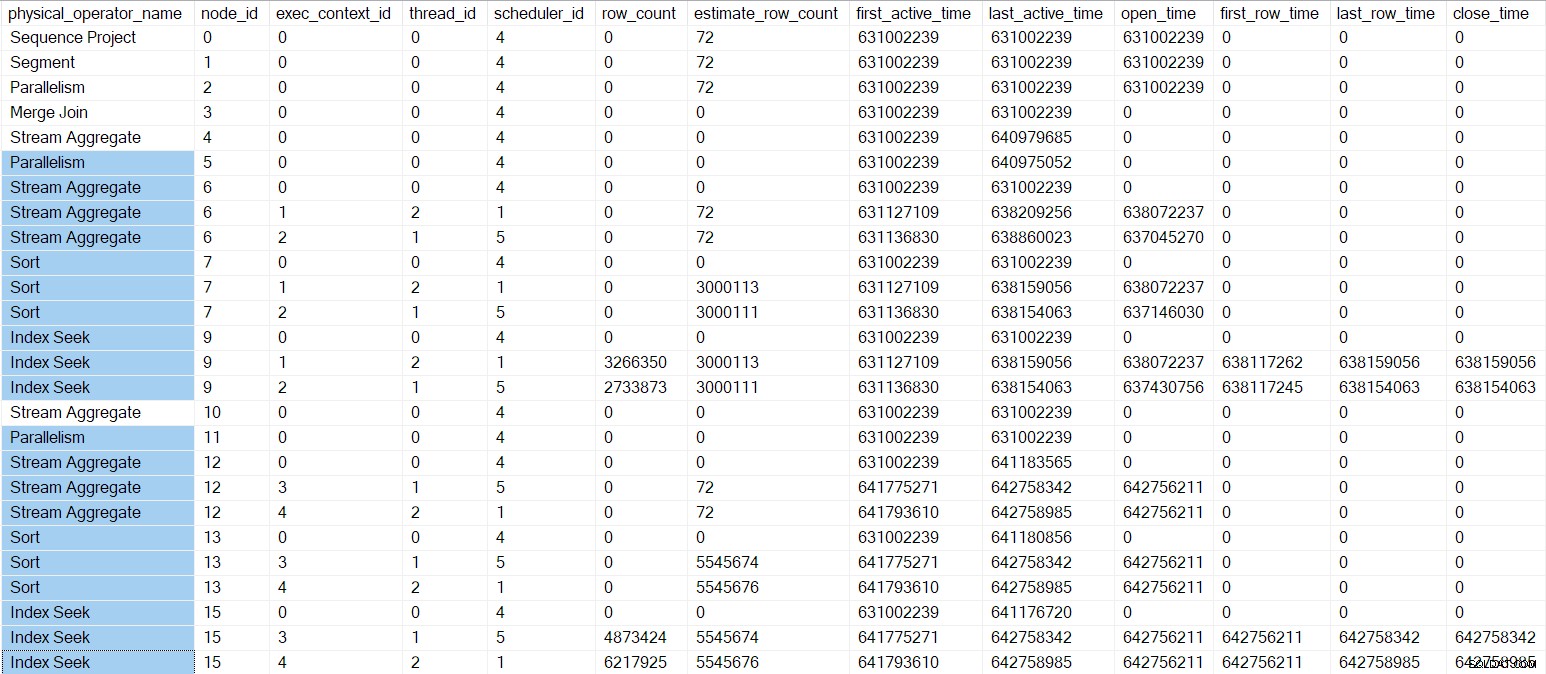
Die einzigen parallelen Aufgaben, die wir noch nicht begonnen haben, befinden sich in Zweig B. Die gesamte Arbeit in Zweig B war bisher frühe Phasen Aufrufe, die von der übergeordneten Aufgabe ausgeführt werden .
Ende von Teil 4
Im letzten Teil dieser Serie werde ich beschreiben, wie der Rest dieses speziellen parallelen Ausführungsplans beginnt, und kurz erläutern, wie der Plan Ergebnisse zurückgibt. Ich schließe mit einer allgemeineren Beschreibung, die für parallele Pläne beliebiger Komplexität gilt.