In einem früheren Artikel haben wir das Star-Schema-Modell besprochen. Das Snowflake-Schema steht in Bezug auf seine Bedeutung in der Data-Warehouse-Modellierung neben dem Star-Schema. Es wurde aus dem Sternschema heraus entwickelt und bietet einige Vorteile gegenüber seinem Vorgänger. Aber diese Vorteile haben ihren Preis. In diesem Artikel besprechen wir, wann und wie das Snowflake-Schema verwendet wird.
Das Schneeflockenschema
Der Name des Schneeflockenschemas kommt von der Tatsache, dass Dimensionstabellen sich verzweigen und in etwa wie eine Schneeflocke aussehen. Wenn wir uns das obige Modell ansehen, werden wir feststellen, dass es sich um eine Faktentabelle handelt, die von einigen Dimensionstabellen umgeben ist, von denen einige die oben erwähnte Verzweigung ausführen. Im Gegensatz zum Sternschema können Dimensionstabellen im Schneeflockenschema ihre eigenen Kategorien haben.
Die Grundidee hinter dem Schneeflockenschema ist, dass Dimensionstabellen vollständig normalisiert sind. Jede Dimensionstabelle kann durch eine oder mehrere Nachschlagetabellen beschrieben werden. Jede Nachschlagetabelle kann durch eine oder mehrere zusätzliche Nachschlagetabellen beschrieben werden. Dies wird wiederholt, bis das Modell vollständig normalisiert ist. Der Prozess der Normalisierung von Star-Schema-Dimensionstabellen wird als Snowflaking bezeichnet.
In diesem Artikel werden Sie viel über Normalisierung hören. Was ist Normalisierung? Im Grunde bedeutet es, eine Datenbank so zu organisieren, dass Redundanzen minimiert und die Datenintegrität geschützt werden. Sehen Sie sich diesen Beitrag an, um mehr über Normalisierung und Denormalisierung zu erfahren.
Schneeflockenschema-Beispiel:Verkaufsmodell
Zuvor haben wir ein Sternschema verwendet, um eine fiktive Verkaufsabteilung zu modellieren – dies wäre vergleichbar mit einem Data Mart, der verwendet wird, um Verkaufsaktivitäten und -ergebnisse zu verfolgen. Das Modell hat fünf Dimensionen:Produkt , Zeit , speichern , Verkäufe Typ und Mitarbeiter . Im fact_sales Tisch, Preis und Menge werden basierend auf Werten in Dimensionstabellen gespeichert und gruppiert. Werfen Sie zur Auffrischung einen Blick auf das folgende Star-Schema-Verkaufsmodell:
Hier ist dasselbe Modell als Schneeflockenschema organisiert:
Der dim_employee und dim_sales_type Dimensionstabellen sind genau die gleichen wie im Sternschemamodell, da sie bereits normalisiert sind.
Andererseits haben wir Normalisierungsregeln auf die restlichen Dimensionstabellen angewendet.


Das dim_product Die Dimensionstabelle aus dem Sternschema wird im Snowflake-Modell in zwei Tabellen aufgeteilt. Der dim_product_type Tabelle wurde hinzugefügt, um den übereinstimmenden Typ in dim_product Tisch. Dadurch haben wir einige Datenintegritätsprobleme vermieden.
Es ist logisch anzunehmen, dass wir bereits alle Produktnamen und ihre zugehörigen Typen als Teil des ETL-Prozesses eingefügt haben, aber angenommen, wir müssen weitere Produktnamen und Typen hinzufügen. In einem Sternschema könnten wir fälschlicherweise den falschen Produkttyp in die Tabelle eintragen. Im Schneeflockenschema:
- Wenn wir auf einen neuen Produkttypnamen stoßen, können wir einen neuen Produkttyp hinzufügen und diesen Typ dann einem neu hinzugefügten Datensatz zuordnen. Dies könnte jedoch dazu führen, dass der Benutzer falsche Informationen eingibt, genau wie beim Sternschema.
- Wir könnten prüfen, ob der Produktname, den wir hinzufügen möchten, bereits existiert. Wenn ja, können wir seine ID bekommen; Wenn nicht, erscheint eine Warnung, in der wir gefragt werden, ob wir ein neues Produkt und einen verwandten Typ hinzufügen möchten.

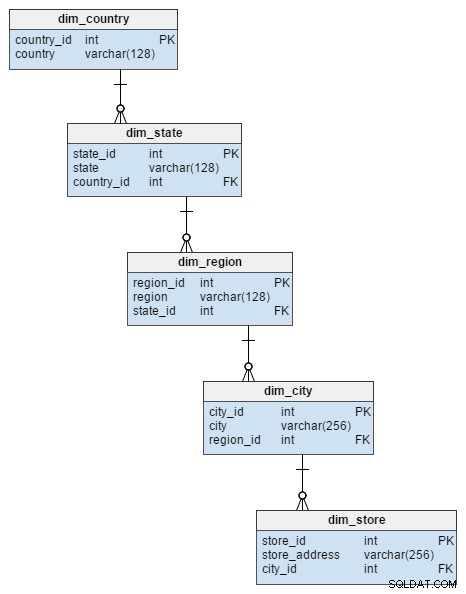
Der dim_store Dimensionstabelle aus dem Sternschema wird durch 5 Tabellen im Schneeflockenschema dargestellt. Diese teilen die Attribute Stadt, Region, Staat und Land auf, die im dim_store Tisch. Die Normalisierung dieser Tabelle vermied nicht nur das Risiko der Datenintegrität, sondern sparte auch Speicherplatz.
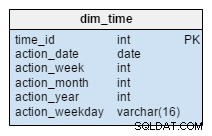
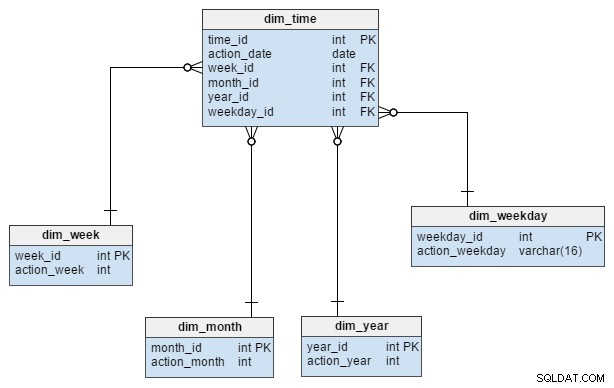
Die dim_time Dimension wird mit fünf Tabellen dargestellt. Wir können an dim_week denken , dim_month , dim_year und der dim_weekday Tabellen als Wörterbücher, die die dim_time Tisch.
Die dim_week , dim_month , dim_year und dim_weekday Tabellen sind vier verschiedene Hierarchien, die verwendet werden, um unsere Zeitdimension zu beschreiben. Wir könnten weitere Dimensionen wie Quartale oder andere verwandte Tabellen hinzufügen, wenn wir sie brauchen. In diesem Beispiel dim_month ist ein Wörterbuch mit 12 Monaten; allein aus dieser Dimension wissen wir nicht, zu welchem Jahr dieser Monat gehört; das ist die Funktion von dim_year Tisch.
Schneeflockenschema-Beispiel:Lieferauftragsmodell
Der andere Data Mart, den wir besprochen haben, war für Lieferaufträge. Die Idee besteht darin, alle Lieferauftragsdaten für die folgenden vier Dimensionen zu speichern und zu aggregieren:Produkt , Zeit , Lieferant und Mitarbeiter . Wir werfen noch einmal einen Blick auf das relevante Sternschema:
Konvertieren wir dies in das Schneeflockenschema, erhalten wir das folgende Modell:
Für dim_product , dim_time und dim_supplier Maßtabellen.
Vor- und Nachteile des Snowflake-Schemas
Es gibt zwei Hauptvorteile zum Schneeflockenschema:
- Bessere Datenqualität (Daten sind besser strukturiert, sodass Datenintegritätsprobleme reduziert werden)
- Weniger Speicherplatz wird dann in einem denormalisierten Modell verwendet
Der bemerkenswerteste Nachteil für das Schneeflockenmodell ist, dass es komplexere Abfragen erfordert. Diese Abfragen mit ihrer erhöhten Anzahl von Verknüpfungen können die Leistung erheblich beeinträchtigen.
Wir werden dieselbe Abfrage, die im Star-Schema-Artikel verwendet wird, für das Schneeflocken-Schema-Verkaufsmodell umschreiben. Hier ist die Abfrage, die erforderlich ist, um die Menge aller telefonartigen Produkttypen zurückzugeben, die 2016 in Berliner Geschäften verkauft wurden:
SELECT dim_store.store_address, SUM(fact_sales.quantity) AS quantity_sold FROM fact_sales INNER JOIN dim_product ON fact_sales.product_id = dim_product.product_id INNER JOIN dim_product_type ON dim_product.product_type_id = dim_product_type.product_type_id INNER JOIN dim_time ON fact_sales.time_id = dim_time.time_id INNER JOIN dim_year ON dim_time.year_id = dim_year.year_id INNER JOIN dim_store ON fact_sales.store_id = dim_store.store_id INNER JOIN dim_city ON dim_store.city_id = dim_city.city_id WHERE dim_year.action_year = 2016 AND dim_city.city = 'Berlin' AND dim_product_type.product_type_name = 'phone' GROUP BY dim_store.store_id, dim_store.store_address
Das Starflake-Schema
Ein Starflake-Schema ist eine Kombination aus dem Snowflake- und dem Star-Schema. Wir können es als Schneeflockenschema betrachten, in dem einige Dimensionstabellen denormalisiert sind. Bei richtiger Verwendung kann das Starflake-Schema einen Ansatz bieten, der das Beste aus beiden Welten bietet. Offensichtlich sollte der Snowflake-Teil des Modells Speicherplatz sparen, während der Star-Teil die Leistung verbessern sollte.
Das obige Modell ist im Grunde ein Schneeflockenmodell mit einer denormalisierten dim_time Tisch. Da dieses Schema die Anzahl der erforderlichen Abfrageverknüpfungen reduziert, könnte es die Leistung verbessern. Andererseits verlieren wir keinen nennenswerten Speicherplatz, da die meisten Tabellenattribute und Fremdschlüsselattribute den int gemeinsam nutzen Typ.
Das Galaxieschema
Beim Data Warehousing liegt ein Galaxienschema vor, wenn zwei oder mehr Faktentabellen eine oder mehrere Dimensionstabellen gemeinsam nutzen. Ein Grund für die Verwendung dieses Schemas besteht darin, Speicherplatz zu sparen. Wir haben unten ein Beispiel für ein Galaxienschema erstellt:
Hier haben wir zwei Faktentabellen, fact_sales und fact_supply_order , die drei Dimensionstabellen direkt gemeinsam nutzen:dim_product , dim_employee und dim_time . Beachten Sie, dass sogar dim_store und dim_supplier dieselbe Nachschlagetabelle teilen, dim_city .
Auf diese Weise sparen wir Platz, aber wir müssen ein paar Dinge beachten, bevor wir zwei Data Marts (in diesem Fall Verkaufs- und Lieferaufträge) in einem Galaxienschema zusammenführen:
- Gibt es irgendeine Logik, sich ihnen anzuschließen? Zum Beispiel Würden beide Data Marts von derselben Abteilung verwendet werden?
- Sind wir sicher, dass wir genau dieselbe Abmessung und Körnung benötigen? für beide Datamarts?
Das Schneeflockenschema wird häufig in der Datenmodellierung verwendet. Es kann die richtige Wahl in Situationen sein, in denen Speicherplatz wichtiger ist als Leistung. Wenn wir ein Gleichgewicht zwischen Platzersparnis und Leistung wünschen, können wir das Starflake-Schema verwenden. Dennoch hängt die richtige Passform für ein bestimmtes Problem von vielen Parametern ab. Dies ist einer der Bereiche in der IT, in denen wir mit Faktoren „spielen“ können, um die beste Lösung zu finden.