Dies ist der dritte Teil einer fünfteiligen Reihe, die einen tiefen Einblick in die Art und Weise gibt, wie parallele Pläne im SQL Server-Zeilenmodus ausgeführt werden. Teil 1 initialisierte den Ausführungskontext Null für die übergeordnete Aufgabe, und Teil 2 erstellte den Abfrage-Scan-Baum. Wir sind jetzt bereit, den Abfrage-Scan zu starten, eine frühe Phase durchzuführen Verarbeitung und starten Sie die ersten zusätzlichen parallelen Tasks.
Abfragescan starten
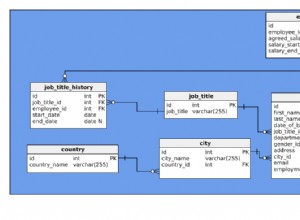
Denken Sie daran, dass nur die übergeordnete Aufgabe existiert derzeit, und die Börsen (Parallelitätsbetreiber) haben nur eine Verbraucherseite. Dies reicht jedoch aus, damit die Abfrageausführung im Worker-Thread der übergeordneten Aufgabe beginnen kann. Der Abfrageprozessor beginnt mit der Ausführung, indem er den Abfragescanprozess über einen Aufruf von CQueryScan::StartupQuery startet . Eine Erinnerung an den Plan (zum Vergrößern anklicken):
Dies ist der erste Punkt im bisherigen Prozess, der einen In-Flight-Ausführungsplan enthält ist verfügbar (ab SQL Server 2016 SP1) in sys.dm_exec_query_statistics_xml . In einem solchen Plan ist an dieser Stelle nichts besonders Interessantes zu sehen, da alle Transientenzähler Null sind, aber der Plan ist zumindest verfügbar . Es gibt keinen Hinweis darauf, dass noch keine parallelen Tasks erstellt wurden oder dass den Börsen eine Produzentenseite fehlt. Der Plan sieht in jeder Hinsicht „normal“ aus.
Parallele Planzweige
Da es sich um einen parallelen Plan handelt, ist es hilfreich, ihn in Zweige aufzuteilen. Diese sind unten schattiert und als Zweige A bis D gekennzeichnet:
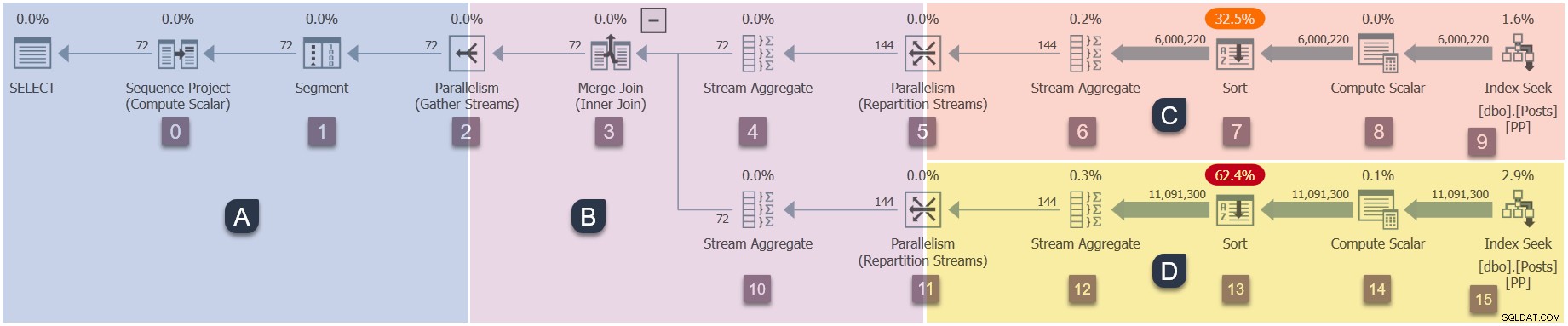
Zweig A ist der übergeordneten Aufgabe zugeordnet, die auf dem von der Sitzung bereitgestellten Worker-Thread ausgeführt wird. Zusätzliche parallele Worker werden gestartet, um die zusätzlichen parallelen Aufgaben auszuführen in den Zweigen B, C und D enthalten. Diese Zweige sind parallel, daher gibt es in jedem zusätzliche DOP-Aufgaben und -Arbeiter.
Unsere Beispielabfrage wird bei DOP 2 ausgeführt, sodass Zweig B zwei zusätzliche Aufgaben erhält. Dasselbe gilt für Zweig C und Zweig D, was insgesamt sechs ergibt zusätzliche Aufgaben. Jede Aufgabe wird auf ihrem eigenen Worker-Thread in ihrem eigenen Ausführungskontext ausgeführt.
Zwei Scheduler (S1 und S2 ) werden dieser Abfrage zugewiesen, um zusätzliche parallele Worker auszuführen. Jeder zusätzliche Worker wird auf einem dieser beiden Scheduler ausgeführt. Der übergeordnete Worker wird möglicherweise auf einem anderen Planer ausgeführt, sodass unsere DOP 2-Abfrage maximal drei verwenden kann Prozessorkerne zu einem beliebigen Zeitpunkt.
Zusammenfassend wird unser Plan schließlich folgendes haben:
- Zweig A (Elternteil)
- Übergeordnete Aufgabe.
- Übergeordneter Worker-Thread.
- Ausführungskontext null.
- Jeder einzelne Planer, der für die Abfrage verfügbar ist.
- Zweig B (zusätzlich)
- Zwei zusätzliche Aufgaben.
- Ein zusätzlicher Worker-Thread, der an jede neue Aufgabe gebunden ist.
- Zwei neue Ausführungskontexte, einer für jede neue Aufgabe.
- Ein Worker-Thread läuft auf Scheduler S1 . Der andere läuft auf dem Scheduler S2 .
- Zweig C (zusätzlich)
- Zwei zusätzliche Aufgaben.
- Ein zusätzlicher Worker-Thread, der an jede neue Aufgabe gebunden ist.
- Zwei neue Ausführungskontexte, einer für jede neue Aufgabe.
- Ein Worker-Thread läuft auf Scheduler S1 . Der andere läuft auf dem Scheduler S2 .
- Zweig D (zusätzlich)
- Zwei zusätzliche Aufgaben.
- Ein zusätzlicher Worker-Thread, der an jede neue Aufgabe gebunden ist.
- Zwei neue Ausführungskontexte, einer für jede neue Aufgabe.
- Ein Worker-Thread läuft auf Scheduler S1 . Der andere läuft auf dem Scheduler S2 .
Die Frage ist, wie all diese zusätzlichen Tasks, Worker und Ausführungskontexte erstellt werden und wann sie ausgeführt werden.
Startsequenz
Die Reihenfolge, in der zusätzliche Aufgaben Starten Sie die Ausführung für diesen bestimmten Plan ist:
- Zweig A (übergeordnete Aufgabe).
- Zweig C (zusätzliche parallele Aufgaben).
- Zweig D (zusätzliche parallele Aufgaben).
- Zweig B (zusätzliche parallele Aufgaben).
Das ist vielleicht nicht die Startreihenfolge, die Sie erwartet haben.
Es kann zu einer erheblichen Verzögerung kommen zwischen jedem dieser Schritte, aus Gründen, die wir in Kürze untersuchen werden. Der entscheidende Punkt in dieser Phase ist, dass die zusätzlichen Aufgaben, Worker und Ausführungskontexte nicht sind alle auf einmal erstellt, und das tun sie nicht alle beginnen gleichzeitig mit der Ausführung.
SQL Server hätte so konzipiert werden können, dass alle zusätzlichen parallelen Bits auf einmal gestartet werden. Das mag leicht nachzuvollziehen sein, wäre aber im Allgemeinen nicht sehr effizient. Es würde die Anzahl zusätzlicher Threads und anderer Ressourcen, die von der Abfrage verwendet werden, maximieren und zu einer Menge unnötiger paralleler Wartezeiten führen.
Mit dem von SQL Server verwendeten Design verwenden parallele Pläne häufig insgesamt weniger Worker-Threads als (DOP multipliziert mit der Gesamtzahl der Branches). Dies wird erreicht, indem erkannt wird, dass einige Zweige vollständig ausgeführt werden können, bevor ein anderer Zweig gestartet werden muss. Dies kann die Wiederverwendung von Threads innerhalb derselben Abfrage ermöglichen und allgemein den Ressourcenverbrauch insgesamt reduzieren.
Wenden wir uns nun den Details zu, wie unser paralleler Plan beginnt.
Eröffnung von Filiale A
Der Abfrage-Scan beginnt mit der Ausführung der übergeordneten Aufgabe, die Open() aufruft auf dem Iterator an der Wurzel des Baums. Dies ist der Beginn der Ausführungssequenz:
- Zweig A (übergeordnete Aufgabe).
- Zweig C (zusätzliche parallele Aufgaben).
- Zweig D (zusätzliche parallele Aufgaben).
- Zweig B (zusätzliche parallele Aufgaben).
Wir führen diese Abfrage mit einem angeforderten „tatsächlichen“ Plan aus, also ist der Root-Iterator nicht der Sequenzprojektoperator am Knoten 0. Vielmehr ist es der unsichtbare Profiling-Iterator das Laufzeitmetriken in Zeilenmodusplänen aufzeichnet.
Die folgende Abbildung zeigt die Abfrage-Scan-Iteratoren in Zweig A des Plans, wobei die Position der unsichtbaren Profiling-Iteratoren durch die „Brillen“-Symbole dargestellt wird.
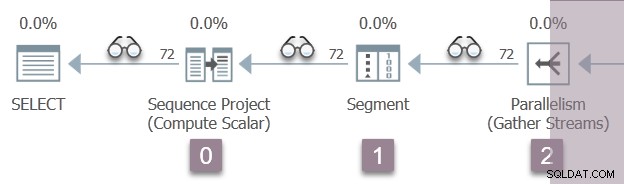
Die Ausführung beginnt mit einem Aufruf zum Öffnen des ersten Profilers, CQScanProfileNew::Open . Hiermit wird die offene Zeit festgelegt für den untergeordneten Sequenzprojektoperator über die Abfrageleistungszähler-API des Betriebssystems.
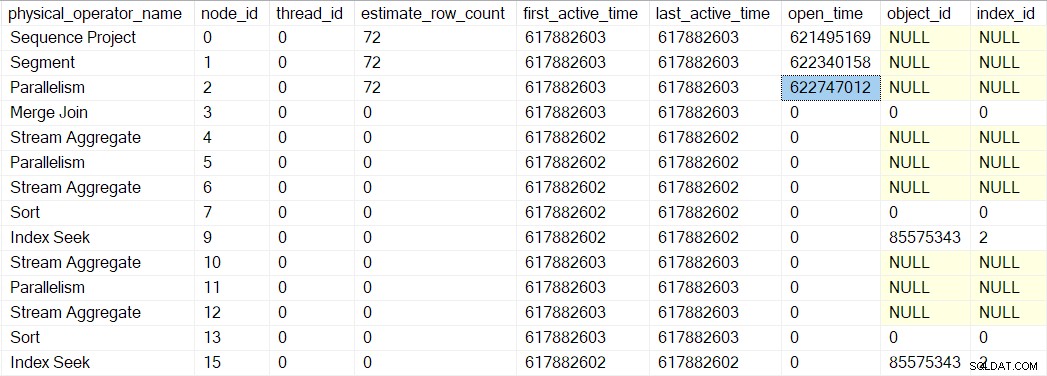
Wir können diese Nummer in sys.dm_exec_query_profiles sehen :
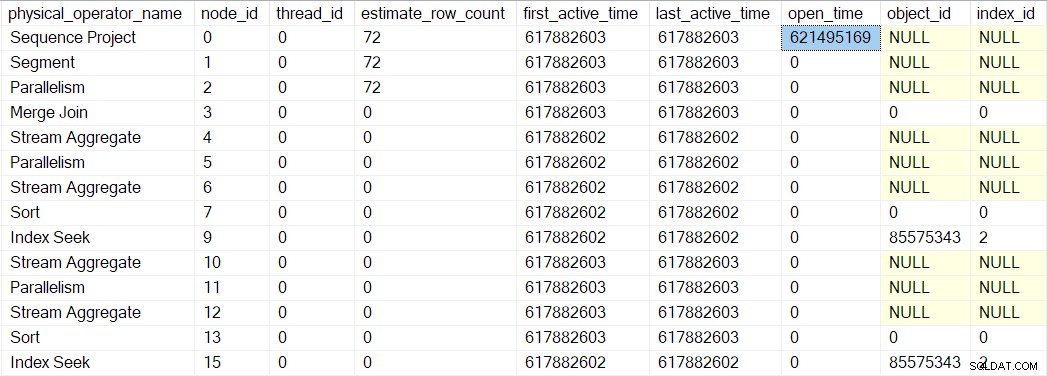
Die Einträge dort enthalten möglicherweise die Namen der Betreiber, aber die Daten stammen vom Profiler über dem Operator, nicht der Operator selbst.
Zufälligerweise ein Sequenzprojekt (CQScanSeqProjectNew ) muss beim Öffnen nichts tun , also hat es eigentlich kein Open() Methode. Der Profiler über dem Sequenzprojekt ist aufgerufen, sodass eine offene Zeit für das Sequenzprojekt in der DMV aufgezeichnet wird.
Das Open des Profilers Methode ruft Open nicht auf auf das Sequenzprojekt (da es keins hat). Stattdessen ruft es Open auf auf dem Profiler für den nächsten Iterator in Folge. Dies ist das Segment Iterator am Knoten 1. Dadurch wird die Öffnungszeit für das Segment festgelegt, so wie es der vorherige Profiler für das Sequenzprojekt getan hat:
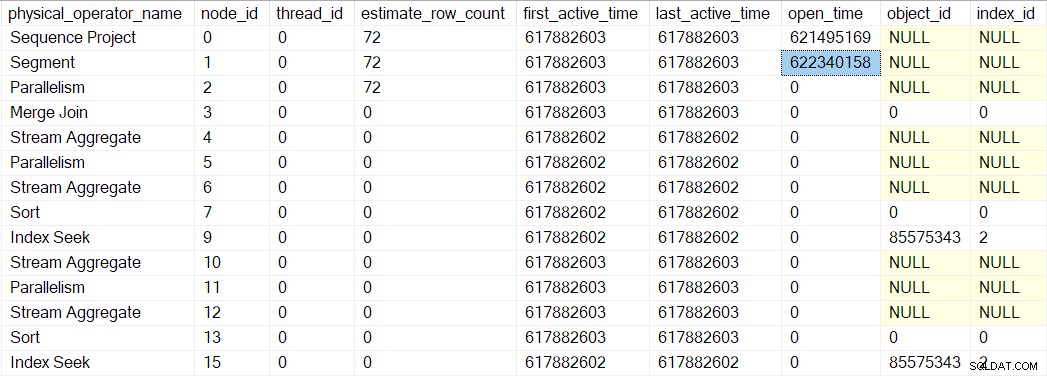
Ein Segment-Iterator macht es Dinge zu tun haben, wenn sie geöffnet sind, also ist der nächste Aufruf CQScanSegmentNew::Open . Sobald das Segment getan hat, was es tun muss, ruft es den Profiler für den nächsten Iterator in der Reihe auf – den Verbraucher Seite der Gather Streams Exchange bei Knoten 2:
Der nächste Aufruf der Abfrage-Scan-Struktur im Öffnungsprozess ist CQScanExchangeNew::Open , wo die Dinge beginnen, interessanter zu werden.
Öffnen des Gather-Streams-Austauschs
Bitten Sie die Verbraucherseite der Börse, sich zu öffnen:
- Öffnet eine lokale (parallel verschachtelte) Transaktion (
CXTransLocal::Open). Jeder Prozess benötigt eine umgebende Transaktion, und zusätzliche parallele Aufgaben sind keine Ausnahme. Sie können die übergeordnete (Basis-)Transaktion nicht direkt teilen, daher werden verschachtelte Transaktionen verwendet. Wenn eine parallele Aufgabe auf die Basistransaktion zugreifen muss, synchronisiert sie sich auf einem Latch und trifft möglicherweise aufNESTING_TRANSACTION_READONLYoderNESTING_TRANSACTION_FULLwartet. - Registriert den aktuellen Worker-Thread beim Austauschport (
CXPort::Register). - Synchronisiert mit anderen Threads auf der Verbraucherseite des Austauschs (
sqlmin!CXTransLocal::Synchronize). Es gibt keine anderen Threads auf der Consumer-Seite eines Gather-Streams, daher ist dies bei dieser Gelegenheit im Wesentlichen ein No-Op.
„Frühphasen“-Verarbeitung
Die übergeordnete Aufgabe hat nun den Rand von Zweig A erreicht. Der nächste Schritt ist besonders zu parallelen Plänen im Zeilenmodus:Die übergeordnete Aufgabe setzt die Ausführung fort, indem sie CQScanExchangeNew::EarlyPhases aufruft auf den Gather-Streams Austausch-Iterator an Knoten 2. Dies ist eine zusätzliche Iterator-Methode neben dem üblichen Open , GetRow , und Close Methoden, mit denen viele von Ihnen vertraut sein werden. EarlyPhases wird nur im Zeilenmodus parallele Pläne aufgerufen.
Ich möchte an dieser Stelle etwas klarstellen:Die Erzeugerseite des Gather-Streams-Austauschs an Knoten 2 hat nicht wurde noch erstellt und nein zusätzliche parallele Aufgaben wurden erstellt. Wir führen immer noch Code für die übergeordnete Aufgabe aus und verwenden dabei den einzigen Thread, der gerade läuft.
Nicht alle Iteratoren implementieren EarlyPhases , da nicht alle an dieser Stelle im Zeilenmodus parallele Pläne etwas Besonderes zu tun haben. Dies ist analog zum Sequenzprojekt, das den Open nicht implementiert Methode, weil es zu diesem Zeitpunkt nichts zu tun hat. Die wichtigsten Iteratoren mit EarlyPhases Methoden sind:
CQScanConcatNew(Verkettung).CQScanMergeJoinNew(zusammenführen verbinden).CQScanSwitchNew(Schalter).CQScanExchangeNew(Parallelität).CQScanNew(Rowset-Zugriff, z. B. Scans und Suchen).CQScanProfileNew(unsichtbare Profiler).CQScanLightProfileNew(unsichtbare leichte Profiler).
Zweig B frühe Phasen
Die übergeordnete Aufgabe fährt fort, indem EarlyPhases aufgerufen wird auf untergeordneten Operatoren jenseits des Gather-Streams-Austauschs an Knoten 2. Eine Aufgabe, die sich über eine Verzweigungsgrenze bewegt, mag ungewöhnlich erscheinen, aber denken Sie daran, dass der Ausführungskontext Null den gesamten seriellen Plan enthält, einschließlich der Austauschvorgänge. Bei der Verarbeitung in der frühen Phase geht es darum, Parallelität zu initialisieren, also zählt nicht als Hinrichtung per se .
Damit Sie den Überblick behalten, zeigt das Bild unten die Iteratoren im Zweig B des Plans:
Denken Sie daran, dass wir uns immer noch im Ausführungskontext Null befinden, also beziehe ich mich hier nur der Einfachheit halber auf Zweig B. Wir haben noch nicht begonnen noch keine parallele Ausführung.
Die Sequenz der Codeaufrufe der frühen Phase in Zweig B ist:
CQScanProfileNew::EarlyPhasesfür den Profiler über Knoten 3.CQScanMergeJoinNew::EarlyPhasesam Knoten 3 merge join .CQScanProfileNew::EarlyPhasesfür den Profiler über Knoten 4. Das Stream-Aggregat von Knoten 4 selbst hat keine Frühphasenmethode.CQScanProfileNew::EarlyPhasesauf dem Profiler über Knoten 5.CQScanExchangeNew::EarlyPhasesfür die Repartition-Streams Austausch an Knoten 5.
Beachten Sie, dass wir in dieser Phase nur die äußere (obere) Eingabe für den Merge-Join verarbeiten. Dies ist nur die normale iterative Ausführungssequenz im Zeilenmodus. Es ist nicht spezifisch für parallele Pläne.
Zweig C frühe Phasen
Die Verarbeitung der frühen Phase wird mit den Iteratoren in Zweig C fortgesetzt:

Die Reihenfolge der Aufrufe ist hier:
CQScanProfileNew::EarlyPhasesfür den Profiler über Knoten 6.CQScanProfileNew::EarlyPhasesfür den Profiler über Knoten 7.CQScanProfileNew::EarlyPhasesauf dem Profiler über Knoten 9.CQScanNew::EarlyPhasesfür den Index suchen Sie bei Knoten 9.
Es gibt keine EarlyPhases Methode auf dem Stream aggregieren oder sortieren. Die vom Compute-Skalar am Knoten 8 ausgeführte Arbeit wird verzögert (zum Sortieren), sodass es nicht in der Abfrage-Scan-Struktur erscheint und keinen zugeordneten Profiler hat.
Über Profiler-Timings
Übergeordnete Aufgabe Verarbeitung in der frühen Phase begann beim Streams-Sammeln-Austausch bei Knoten 2. Es stieg den Abfrage-Scan-Baum abwärts, folgte der äußeren (oberen) Eingabe zum Zusammenführungs-Join, bis hinunter zur Indexsuche bei Knoten 9. Unterwegs wurde die übergeordnete Aufgabe aufgerufen die EarlyPhases -Methode auf jedem Iterator, der sie unterstützt.
Keine der Aktivitäten in der frühen Phase wurde bisher aktualisiert jederzeit in der Profilerstellungs-DMV. Insbesondere wurde für keinen der Iteratoren, die von der Verarbeitung in frühen Phasen betroffen sind, eine „offene Zeit“ festgelegt. Dies ist sinnvoll, da die Verarbeitung in der frühen Phase nur die parallele Ausführung einrichtet – diese Operatoren werden geöffnet zur späteren Ausführung.
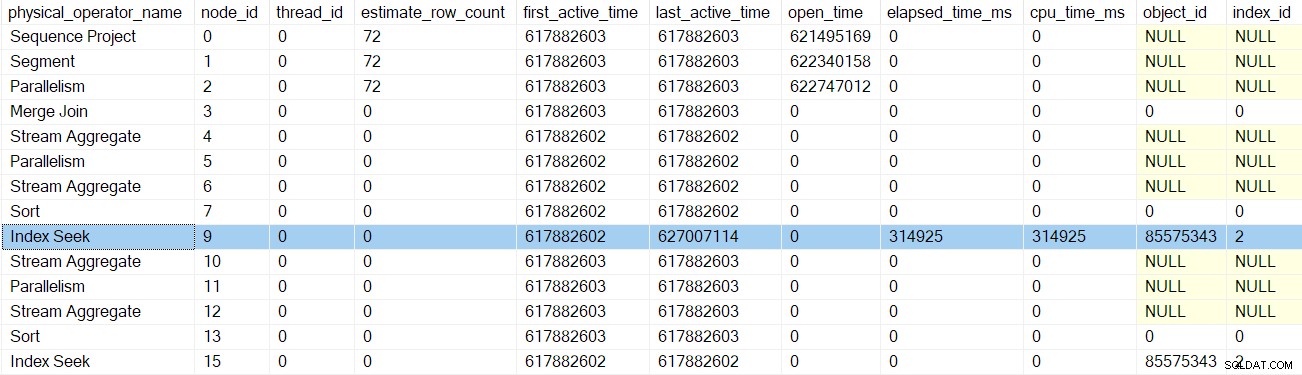
Die Indexsuche bei Knoten 9 ist ein Blattknoten – er hat keine Kinder. Die übergeordnete Aufgabe beginnt nun mit der Rückkehr aus den verschachtelten EarlyPhases Anrufe, aufsteigend der Abfrage-Scan-Baum zurück zum Gather-Streams-Austausch.
Jeder der Profiler ruft den Query Performance Counter auf API beim Eintritt in ihre EarlyPhases Methode, und sie rufen sie auf dem Weg nach draußen erneut auf. Die Differenz zwischen den beiden Zahlen stellt die verstrichene Zeit dar für den Iterator und alle seine Kinder (da die Methodenaufrufe verschachtelt sind).
Nachdem der Profiler für die Indexsuche zurückgekehrt ist, zeigt die Profiler-DMV die verstrichene Zeit und die CPU-Zeit für die Indexsuche an nur, sowie eine aktualisierte zuletzt aktiv Zeit. Beachten Sie auch, dass diese Informationen für die übergeordnete Aufgabe aufgezeichnet werden (im Moment die einzige Option):
Keiner der früheren Iteratoren, die von den Aufrufen der frühen Phase berührt wurden, hat verstrichene Zeiten oder aktualisierte letzte aktive Zeiten. Diese Nummern werden nur aktualisiert, wenn wir den Baum erklimmen.
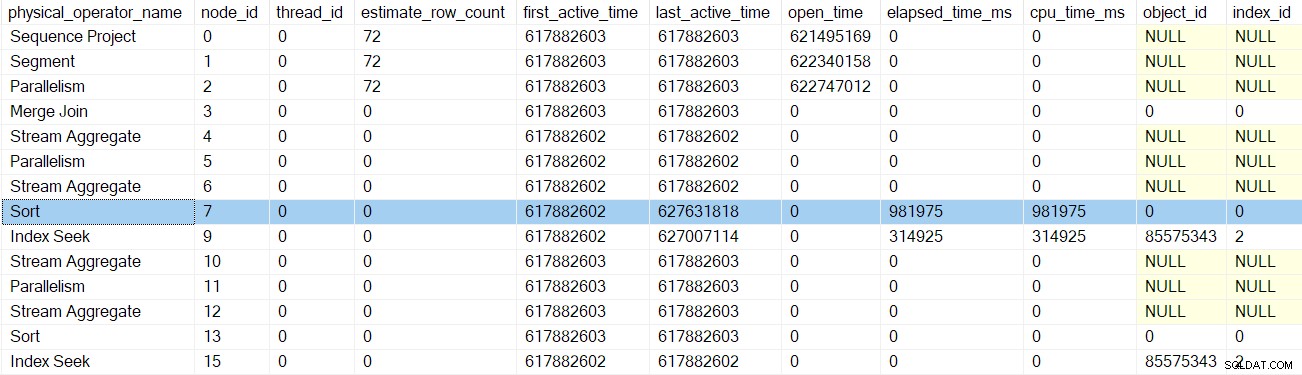
Nach dem nächsten Profiler Early Phases Call Return, dem sort Zeiten werden aktualisiert:
Die nächste Rückkehr führt uns am Profiler für das Stream-Aggregat vorbei bei Knoten 6:
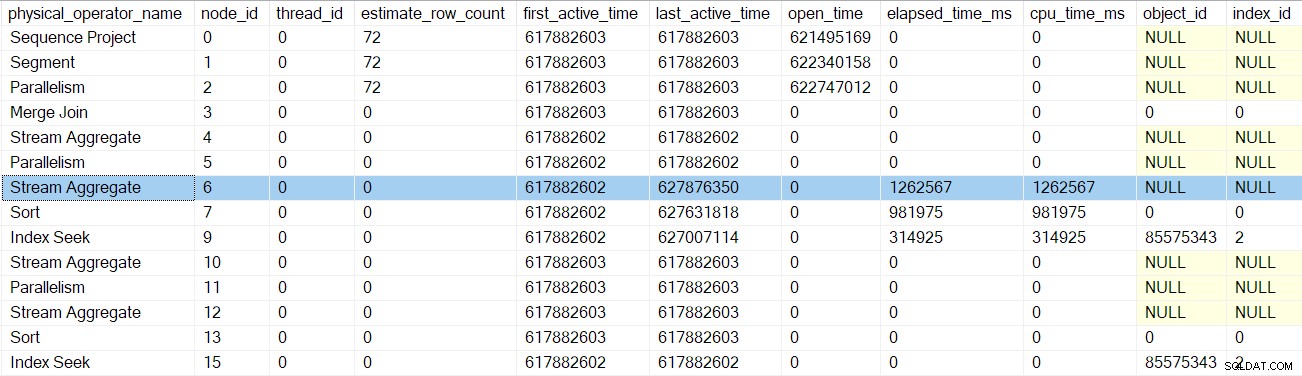
Die Rückkehr von diesem Profiler bringt uns zurück zu den EarlyPhases Rufen Sie die repartition streams auf Austausch an Knoten 5 . Denken Sie daran, dass hier die Sequenz der Aufrufe der frühen Phasen nicht begonnen hat – das war der Austausch der Sammelströme an Knoten 2.
Zweig C parallele Aufgaben in die Warteschlange eingereiht
Abgesehen von der Aktualisierung der Profildaten schienen die früheren Anrufe in der frühen Phase nicht viel zu bewirken. Das ändert sich mit den repartition streams Austausch an Knoten 5.
Ich werde Zweig C ziemlich detailliert beschreiben, um eine Reihe wichtiger Konzepte vorzustellen, die auch für die anderen parallelen Zweige gelten. Wenn Sie diesen Bereich jetzt einmal abdecken, können spätere Branchendiskussionen prägnanter sein.
Nachdem die verschachtelte Frühphasenverarbeitung für ihren Unterbaum abgeschlossen ist (bis hinab zur Indexsuche am Knoten 9), kann die Vermittlungsstelle mit ihrer eigenen Frühphasenarbeit beginnen. Dies beginnt genauso wie Öffnen die Gather-Streams tauschen sich am Knoten 2 aus:
CXTransLocal::Open(Öffnen der lokalen parallelen Teiltransaktion).CXPort::Register(Registrierung beim Austauschport).
Die nächsten Schritte sind anders, da Zweig C eine vollständige Blockierung enthält Iterator (die Sortierung bei Knoten 7). Die Frühphasenverarbeitung an den Neupartitionierungsströmen des Knotens 5 führt Folgendes aus:
- Ruft
CQScanExchangeNew::StartAllProducersauf . Dies ist das erste Mal, dass wir auf etwas stoßen, das auf die Herstellerseite verweist des Austauschs. Node 5 ist die erste Börse in diesem Plan, die ihre Produzentenseite erstellt. - Erwirbt einen Mutex daher kann kein anderer Thread gleichzeitig Aufgaben in die Warteschlange stellen.
- Startet parallel verschachtelte Transaktionen für die Producer-Tasks (
CXPort::StartNestedTransactionsundReadOnlyXactImp::BeginParallelNestedXact). - Registriert die Untertransaktionen mit dem Scan-Objekt der übergeordneten Abfrage (
CQueryScan::AddSubXact). - Erzeugt Erzeugerdeskriptoren (
CQScanExchangeNew::PxproddescCreate). - Erzeugt neue Erzeugerausführungskontexte (
CExecContext) abgeleitet vom Ausführungskontext Null. - Aktualisiert die verknüpfte Karte der Plan-Iteratoren.
- Setzt DOP für den neuen Kontext (
CQueryExecContext::SetDop), sodass alle Tasks wissen, was die allgemeine DOP-Einstellung ist. - Initialisiert den Parametercache (
CQueryExecContext::InitParamCache). - Verknüpft die parallel verschachtelten Transaktionen mit der Basistransaktion (
CExecContext::SetBaseXact). - Stellt die neuen Unterprozesse zur Ausführung in die Warteschlange (
SubprocessMgr::EnqueueMultipleSubprocesses). - Erstellt neue parallele Aufgaben Aufgaben über
sqldk!SOS_Node::EnqueueMultipleTasksDirect.
Die Aufrufliste der übergeordneten Aufgabe (für diejenigen unter Ihnen, die diese Dinge mögen) zu diesem Zeitpunkt ist:
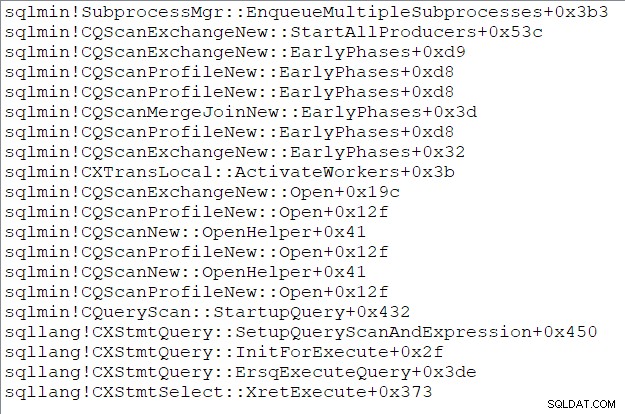
Ende von Teil drei
Wir haben jetzt die Produzentenseite erstellt des Repartition-Streams-Austauschs an Knoten 5, erstellte zusätzliche parallele Tasks zum Ausführen von Zweig C und verknüpfte alles zurück mit Eltern Strukturen nach Bedarf. Zweig C ist der erste verzweigen, um parallele Tasks zu starten. Der letzte Teil dieser Serie wird sich detailliert mit der Eröffnung von Zweig C befassen und mit den verbleibenden parallelen Aufgaben beginnen.