Dies ist der zweite Teil einer fünfteiligen Serie, die einen tiefen Einblick in die Art und Weise gibt, wie parallele Pläne im Zeilenmodus von SQL Server gestartet werden. Am Ende des ersten Teils hatten wir Ausführungskontext Null erstellt für die übergeordnete Aufgabe. Dieser Kontext enthält den gesamten Baum ausführbarer Operatoren, aber sie sind noch nicht bereit für das iterative Ausführungsmodell der Abfrageverarbeitungs-Engine.
Iterative Ausführung
SQL Server führt eine Abfrage durch einen Prozess aus, der als Abfragescan bezeichnet wird . Die Initialisierung des Plans beginnt an der Wurzel durch den Abfrageprozessor, der Open aufruft auf dem Wurzelknoten. Open Aufrufe durchlaufen den Baum der Iteratoren, indem sie rekursiv Open aufrufen auf jedes untergeordnete Element, bis der gesamte Baum geöffnet ist.
Der Prozess der Rückgabe von Ergebniszeilen ist ebenfalls rekursiv und wird durch den Abfrageprozessor ausgelöst, der GetRow aufruft an der Wurzel. Jeder Root-Aufruf gibt jeweils eine Zeile zurück. Der Abfrageprozessor ruft weiterhin GetRow auf auf dem Stammknoten, bis keine Zeilen mehr verfügbar sind. Die Ausführung wird mit einem abschließenden rekursiven Close beendet Forderung. Diese Anordnung ermöglicht es dem Abfrageprozessor, jeden beliebigen Plan zu initialisieren, auszuführen und zu beenden, indem er dieselben Schnittstellenmethoden nur an der Wurzel aufruft.
Um den Baum der ausführbaren Operatoren in einen Baum umzuwandeln, der für die zeilenweise Verarbeitung geeignet ist, fügt SQL Server einen Abfragescan hinzu Wrapper für jeden Operator. Der Abfrage-Scan Objekt stellt den Open bereit , GetRow , und Close Methoden, die für die iterative Ausführung benötigt werden.
Das Abfrage-Scan-Objekt verwaltet auch Zustandsinformationen und legt andere bedienerspezifische Verfahren offen, die während der Ausführung benötigt werden. Beispielsweise das Abfrage-Scan-Objekt für einen Startfilter-Operator (CQScanStartupFilterNew ) macht die folgenden Methoden verfügbar:
OpenGetRowClosePrepRecomputeGetScrollLockSetMarkerGotoMarkerGotoLocationReverseDirectionDormant
Die zusätzlichen Methoden für diesen Iterator werden hauptsächlich in Cursorplänen verwendet.
Initialisieren des Abfragescans
Der Wrapping-Prozess wird als Initialisieren des Abfrage-Scans bezeichnet . Es wird durch einen Aufruf vom Abfrageprozessor an CQueryScan::InitQScanRoot durchgeführt . Die übergeordnete Aufgabe führt diesen Prozess für den gesamten Plan durch (im Ausführungskontext Null enthalten). Der Übersetzungsprozess selbst ist seiner Natur nach rekursiv, er beginnt an der Wurzel und arbeitet sich den Baum hinunter.
Während dieses Vorgangs ist jeder Operator dafür verantwortlich, seine eigenen Daten zu initialisieren und alle Laufzeitressourcen zu erstellen es braucht. Dies kann das Erstellen zusätzlicher Objekte außerhalb des Abfrageprozessors umfassen, beispielsweise die Strukturen, die für die Kommunikation mit der Speicher-Engine erforderlich sind, um Daten aus dem persistenten Speicher abzurufen.
Eine Erinnerung an den Ausführungsplan mit hinzugefügten Knotennummern (zum Vergrößern anklicken):
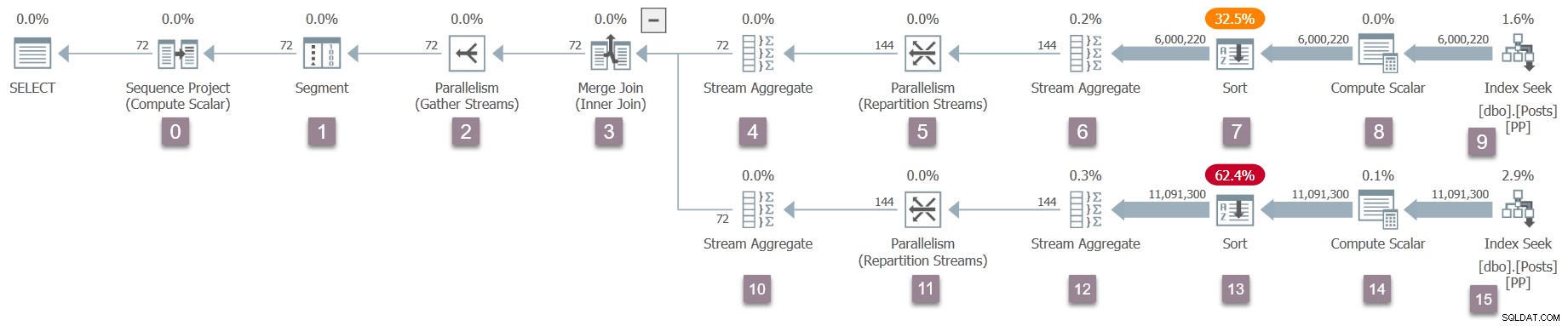
Der Operator am Stamm (Knoten 0) des ausführbaren Planbaums ist ein Sequenzprojekt . Es wird durch eine Klasse namens CXteSeqProject repräsentiert . Wie üblich beginnt hier die rekursive Transformation.
Scan-Wrapper für Abfragen
Wie bereits erwähnt, das CXteSeqProject Objekt ist nicht für die Teilnahme am iterativen Abfrage-Scan ausgestattet Prozess — es hat nicht das erforderliche Open , GetRow , und Close Methoden. Der Abfrageprozessor benötigt einen Wrapper um den ausführbaren Operator, um diese Schnittstelle bereitzustellen.
Um diesen Abfrage-Scan-Wrapper zu erhalten, ruft die übergeordnete Aufgabe CXteSeqProject::QScanGet auf um ein Objekt vom Typ CQScanSeqProjectNew zurückzugeben . Die verlinkte Karte der zuvor erstellten Operatoren wird aktualisiert, um auf das neue Abfragescanobjekt zu verweisen, und seine Iteratormethoden sind mit dem Stamm des Plans verbunden.
Das Kind des Sequenzprojekts ist ein Segment Betreiber (Knoten 1). Aufruf von CXteSegment::QScanGet gibt ein Abfrage-Scan-Wrapper-Objekt des Typs CQScanSegmentNew zurück . Die verknüpfte Karte wird erneut aktualisiert, und Iterator-Funktionszeiger, die mit dem Projektabfrage-Scan der übergeordneten Sequenz verbunden sind.
Ein halber Austausch
Der nächste Operator ist ein Sammelstrom-Austausch (Knoten 2). Aufruf von CXteExchange::QScanGet gibt ein CQScanExchangeNew zurück wie Sie vielleicht schon erwarten.
Dies ist der erste Operator im Baum, der eine signifikante zusätzliche Initialisierung durchführen muss. Es bildet die Verbraucherseite des Austauschs über CXTransport::CreateConsumerPart . Dadurch wird der Port (CXPort ) – eine Datenstruktur im gemeinsam genutzten Speicher, die für die Synchronisation und den Datenaustausch verwendet wird – und eine Pipe (CXPipe ) für den Pakettransport. Beachten Sie, dass der Produzent Seite der Börse ist nicht erstellt in diesem Moment. Wir haben nur einen halben Austausch!
Mehr Verpackung
Der Vorgang zum Einrichten des Abfrageprozessor-Scans wird dann mit dem Merge-Join fortgesetzt (Knoten 3). Ich werde QScanGet nicht immer wiederholen und CQScan* Anrufe von diesem Zeitpunkt an, aber sie folgen dem etablierten Muster.
Der Merge-Join hat zwei Kinder. Die Abfrage-Scan-Einrichtung wird wie zuvor mit der äußeren (oberen) Eingabe fortgesetzt – einem Stream-Aggregat (Knoten 4), dann streamt eine Repartition Austausch (Knoten 5). Die Repartition-Streams erzeugen wieder nur die Verbraucherseite des Austauschs, aber dieses Mal werden zwei Pipes erzeugt, weil DOP zwei ist. Die Verbraucherseite dieser Art von Austausch hat DOP-Verbindungen zu ihrem übergeordneten Betreiber (eine pro Thread).
Als nächstes haben wir ein weiteres Stream-Aggregat (Knoten 6) und eine Sortierung (Knoten 7). Die Sortierung hat ein untergeordnetes Element, das in Ausführungsplänen nicht sichtbar ist – ein Speicher-Engine-Rowset, das zum Implementieren des Überlaufs in tempdb verwendet wird . Der erwartete CQScanSortNew wird daher von einem untergeordneten CQScanRowsetNew begleitet im inneren Baum. Es ist in der Showplan-Ausgabe nicht sichtbar.
I/O-Profiling und verzögerte Operationen
Die Sortierung operator ist auch der erste, den wir bisher initialisiert haben und der für I/O verantwortlich sein könnte . Unter der Annahme, dass die Ausführung E/A-Profildaten angefordert hat (z. B. durch Anfordern eines „eigentlichen“ Plans), erstellt die Sortierung ein Objekt, um diese Laufzeit-Profildaten aufzuzeichnen über CProfileInfo::AllocProfileIO .
Der nächste Operator ist ein Rechenskalar (Knoten 8), ein sogenanntes Projekt im Inneren. Der Abfrage-Scan-Setup-Aufruf an CXteProject::QScanGet tut nicht gibt ein Abfrage-Scan-Objekt zurück, da die Berechnungen, die von diesem Rechenskalar ausgeführt werden, verzögert sind an den ersten übergeordneten Operator, der das Ergebnis benötigt. In diesem Plan ist dieser Operator die Sorte. Die Sortierung erledigt die gesamte dem Compute-Skalar zugewiesene Arbeit, sodass das Projekt am Knoten 8 keinen Teil des Abfrage-Scan-Baums bildet. Der Compute-Skalar wird wirklich nicht zur Laufzeit ausgeführt. Weitere Einzelheiten zu verzögerten Compute-Skalaren finden Sie unter Compute-Skalare, Ausdrücke und Ausführungsplanleistung.
Parallelscan
Der letzte Operator nach dem Compute-Skalar in diesem Zweig des Plans ist eine Indexsuche (CXteRange ) an Knoten 9. Dies erzeugt den erwarteten Abfrage-Scan-Operator (CQScanRangeNew). ), erfordert aber auch eine komplexe Abfolge von Initialisierungen, um eine Verbindung mit der Speicher-Engine herzustellen und einen parallelen Scan des Indexes zu ermöglichen.
Nur die Highlights abdecken, die Indexsuche initialisieren:
- Erstellt ein Profiling-Objekt für E/A (
CProfileInfo::AllocProfileIO). - Erstellt ein paralleles Rowset Abfragescan (
CQScanRowsetNew::ParallelGetRowset). - Richtet eine Synchronisierung ein Objekt, um den parallelen Bereichsscan zur Laufzeit zu koordinieren (
CQScanRangeNew::GetSyncInfo). - Erstellt den Tabellen-Cursor der Speicher-Engine und einen schreibgeschützten Transaktionsdeskriptor .
- Öffnet das Eltern-Rowset zum Lesen (Zugriff auf das HoBt und Nehmen der benötigten Latches).
- Legt das Zeitlimit für die Sperre fest.
- richtet den Vorabruf ein (einschließlich zugehöriger Speicherpuffer).
Hinzufügen von Zeilenmodus-Profilerstellungsoperatoren
Wir haben jetzt die Blattebene dieses Zweigs des Plans erreicht (die Indexsuche hat kein untergeordnetes Element). Nachdem Sie gerade das Abfrage-Scan-Objekt für die Indexsuche erstellt haben, besteht der nächste Schritt darin, den Abfrage-Scan zu umschließen mit einem Profiling-Kurs (vorausgesetzt, wir haben einen tatsächlichen Plan angefordert). Dies erfolgt durch einen Aufruf von sqlmin!PqsWrapQScan . Beachten Sie, dass Profiler hinzugefügt werden, nachdem der Abfragescan erstellt wurde, wenn wir beginnen, den Iteratorbaum aufzusteigen.
PqsWrapQScan erstellt einen neuen Profiling-Operator als übergeordneten Operator der Indexsuche über einen Aufruf von CProfileInfo::GetOrCreateProfileInfo . Der Profiling-Operator (CQScanProfileNew ) verfügt über die üblichen Abfrage-Scan-Schnittstellenmethoden. Neben dem Sammeln der für die eigentlichen Pläne erforderlichen Daten werden die Profildaten auch über die DMV sys.dm_exec_query_profiles bereitgestellt .
Die Abfrage dieses DMV zu diesem genauen Zeitpunkt für die aktuelle Sitzung zeigt, dass nur ein einziger Planoperator (Knoten 9) existiert (was bedeutet, dass er der einzige ist, der von einem Profiler umschlossen wird):

Dieser Screenshot zeigt den vollständigen Ergebnissatz aus dem DMV im aktuellen Moment (es wurde nicht bearbeitet).
Als nächstes CQScanProfileNew ruft die Abfrageleistungszähler-API auf (KERNEL32!QueryPerformanceCounterStub ), die vom Betriebssystem bereitgestellt werden, um die erste und letzte aktive Zeit aufzuzeichnen des profilierten Betreibers:

Die letzte aktive Zeit wird mithilfe der Abfrageleistungszähler-API jedes Mal aktualisiert, wenn Code für diesen Iterator ausgeführt wird.
Der Profiler legt dann die geschätzte Anzahl von Zeilen fest an diesem Punkt im Plan (CProfileInfo::SetCardExpectedRows ), wobei jedes Zeilenziel berücksichtigt wird (CXte::CardGetRowGoal). ). Da es sich um einen parallelen Plan handelt, wird das Ergebnis durch die Anzahl der Threads dividiert (CXte::FGetRowGoalDefinedForOneThread ) und speichert das Ergebnis im Ausführungskontext.
Die geschätzte Zeilenanzahl ist nicht sichtbar über die DMV an dieser Stelle, da die Elterntask diesen Operator nicht ausführen wird. Stattdessen wird die Schätzung pro Thread später in parallelen Ausführungskontexten (die noch nicht erstellt wurden) verfügbar gemacht. Trotzdem wird die Anzahl pro Thread im Profiler der übergeordneten Aufgabe gespeichert – sie ist nur nicht über die DMV sichtbar.
Der Anzeigename des Planoperators („Index Seek“) wird dann über einen Aufruf von CXteRange::GetPhysicalOp gesetzt :

Zuvor ist Ihnen vielleicht aufgefallen, dass bei der Abfrage des DMV der Name als „???“ angezeigt wurde. Dies ist der permanente Name, der für unsichtbare Operatoren angezeigt wird (z. B. Prefetch mit verschachtelten Schleifen, Stapelsortierung), für die kein Anzeigename definiert ist.
Schließlich indexieren Sie Metadaten und aktuelle E/A-Statistiken für die umschlossene Indexsuche werden über einen Aufruf von CQScanRowsetNew::GetIoCounters hinzugefügt :

Die Zähler sind im Moment null, werden aber aktualisiert, wenn die Indexsuche während der Ausführung des abgeschlossenen Plans E/A ausführt.
Mehr Abfrage-Scan-Verarbeitung
Mit dem für die Indexsuche erstellten Profiling-Operator bewegt sich die Abfrage-Scan-Verarbeitung im Baum nach oben zur übergeordneten Sortierung (Knoten 7).
Die Sortierung führt die folgenden Initialisierungsaufgaben aus:
- Registriert seine Speichernutzung mit der Abfrage Speichermanager (
CQryMemManager::RegisterMemUsage) - Berechnet den Speicherbedarf für die Sortiereingabe (
CQScanIndexSortNew::CbufInputMemory) und Ausgabe (CQScanSortNew::CbufOutputMemory). - Die Sortiertabelle zusammen mit dem zugehörigen Speicher-Engine-Rowset (
sqlmin!RowsetSorted). - Eine eigenständige Systemtransaktion (nicht durch die Benutzertransaktion begrenzt) wird zusammen mit einer gefälschten Arbeitstabelle (
sqlmin!CreateFakeWorkTable) für Sortierüberlauf-Festplattenzuweisungen erstellt ). - Der Ausdrucksdienst wird initialisiert (
sqlTsEs!CEsRuntime::Startup) für den Sortieroperator, um die Berechnungen verzögert auszuführen vom Compute-Skalar. - Vorabruf für alle Sortierläufe, die an tempdb verschüttet wurden wird dann über (
CPrefetchMgr::SetupPrefetch) erstellt ).
Schließlich wird der Scan der Sortierabfrage von einem Profiling-Operator (einschließlich I/O) umschlossen, genau wie wir es bei der Indexsuche gesehen haben:

Beachten Sie, dass der Compute-Skalar (Knoten 8) fehlt vom DMV. Das liegt daran, dass seine Arbeit auf die Sortierung verschoben wird, nicht Teil der Abfrage-Scan-Struktur ist und daher kein Wrapping-Profiler-Objekt hat.
Bewegen Sie sich zum übergeordneten Element der Sortierung, dem Stream-Aggregat Der Abfrage-Scan-Operator (Knoten 6) initialisiert seine Ausdrücke und Laufzeitzähler (z. B. aktuelle Gruppenzeilenanzahl). Das Stream-Aggregat wird mit einem Profiling-Operator umschlossen, der seine Anfangszeiten aufzeichnet:

Die übergeordneten Repartitionsströme tauschen aus (Knoten 5) wird von einem Profiler umschlossen (denken Sie daran, dass an dieser Stelle nur die Verbraucherseite dieses Austauschs existiert):

Dasselbe wird für das übergeordnete Stream-Aggregat gemacht (Knoten 4), der ebenfalls wie zuvor beschrieben initialisiert wird:

Die Abfrage-Scan-Verarbeitung kehrt zum übergeordneten Merge-Join zurück (Knoten 3), initialisiert ihn aber noch nicht. Stattdessen bewegen wir uns auf der inneren (unteren) Seite des Merge-Joins nach unten und führen für diese Operatoren (Knoten 10 bis 15) dieselben detaillierten Aufgaben aus wie für den oberen (äußeren) Zweig:
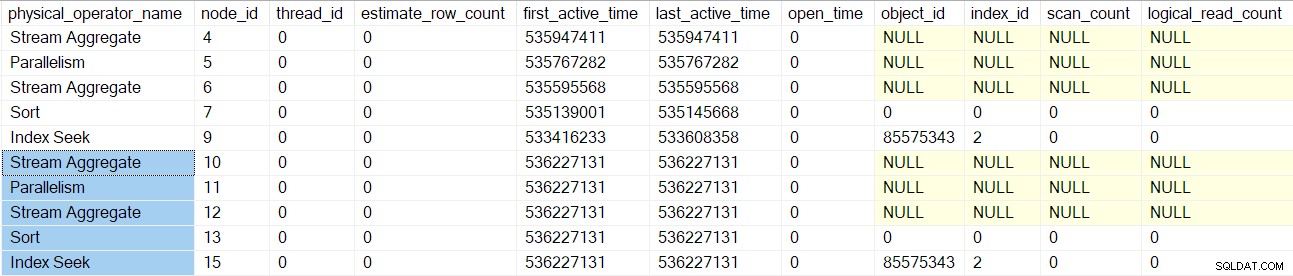
Sobald diese Operatoren verarbeitet sind, wird der Merge Join Der Abfragescan wird erstellt, initialisiert und mit einem Profilerstellungsobjekt umschlossen. Dies schließt E/A-Zähler ein, da ein Many-Man-Merge-Join eine Arbeitstabelle verwendet (obwohl der aktuelle Merge-Join One-Many ist):
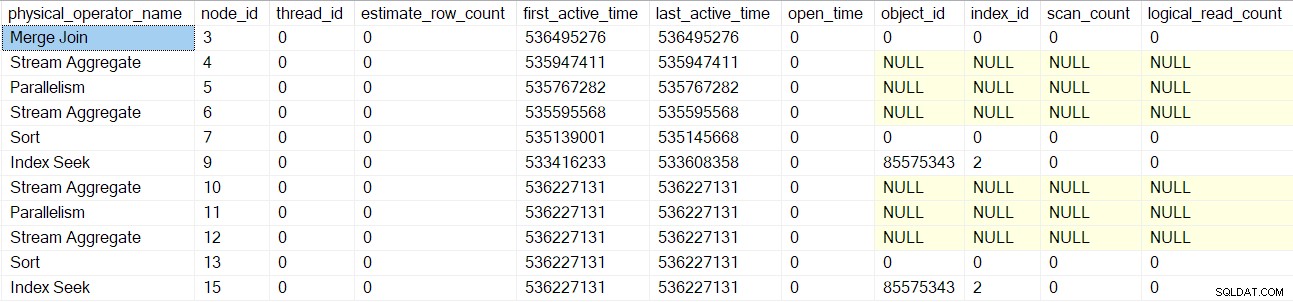
Derselbe Vorgang wird für den Austausch der übergeordneten Gather-Streams befolgt (Knoten 2) Nur Verbraucherseite, Segment (Knoten 1) und Sequenzprojekt (Knoten 0) Operatoren. Ich werde sie nicht im Detail beschreiben.
Die Abfrageprofil-DMV meldet jetzt einen vollständigen Satz von Profiler-verpackten Abfrage-Scan-Knoten:
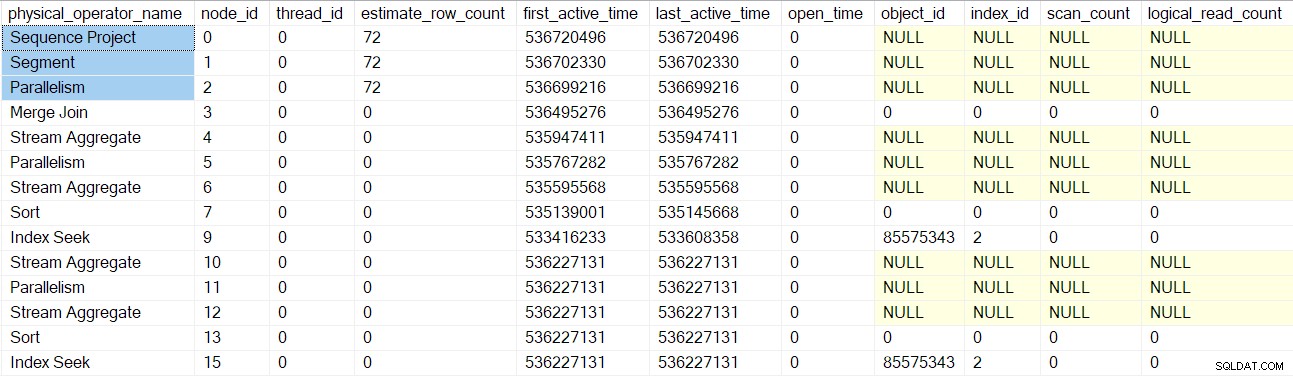
Beachten Sie, dass die Verbraucher der Streams „sequence project“, „segment“ und „gather“ eine geschätzte Zeilenanzahl haben, da diese Operatoren von der übergeordneten Aufgabe ausgeführt werden , nicht durch zusätzliche parallele Tasks (siehe CXte::FGetRowGoalDefinedForOneThread vorhin). Die übergeordnete Aufgabe hat in parallelen Zweigen keine Arbeit zu erledigen, daher ist das Konzept der geschätzten Zeilenanzahl nur für zusätzliche Aufgaben sinnvoll.
Die oben gezeigten aktiven Zeitwerte sind etwas verzerrt, weil ich die Ausführung stoppen und bei jedem Schritt DMV-Screenshots machen musste. Eine separate Ausführung (ohne die künstlichen Verzögerungen, die durch die Verwendung eines Debuggers eingeführt wurden) erzeugte die folgenden Zeiten:
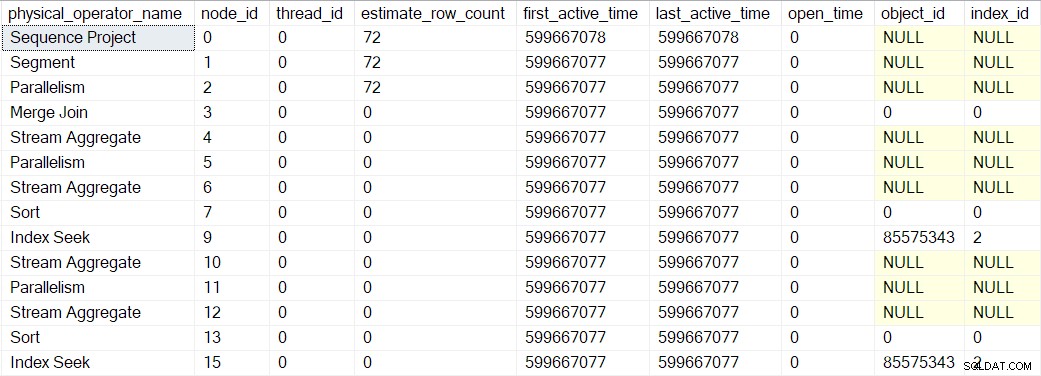
Der Baum wird in der gleichen, zuvor beschriebenen Reihenfolge erstellt, aber der Vorgang ist so schnell, dass nur eine Mikrosekunde benötigt wird Unterschied zwischen der aktiven Zeit des ersten umschlossenen Operators (die Indexsuche bei Knoten 9) und der letzten (Sequenzprojekt bei Knoten 0).
Ende von Teil 2
Es mag so klingen, als hätten wir viel Arbeit geleistet, aber denken Sie daran, dass wir nur einen Abfrage-Scan-Baum für die übergeordnete Aufgabe erstellt haben , und die Börsen haben nur eine Verbraucherseite (noch kein Produzent). Unser paralleler Plan hat auch nur einen Thread (wie im letzten Screenshot gezeigt). In Teil 3 werden unsere ersten zusätzlichen parallelen Aufgaben erstellt.