Gastautor:Michael J Swart (@MJSwart)
Ich verbringe viel Zeit damit, Softwareanforderungen in Schemas und Abfragen zu übersetzen. Diese Anforderungen sind manchmal einfach umzusetzen, aber oft schwierig. Ich möchte über UI-Designentscheidungen sprechen, die zu Datenzugriffsmustern führen, die mit SQL Server umständlich zu implementieren sind.
Nach Spalte sortieren
Sort-By-Column ist ein so vertrautes Muster, dass wir es als selbstverständlich ansehen können. Jedes Mal, wenn wir mit Software interagieren, die eine Tabelle anzeigt, können wir erwarten, dass die Spalten wie folgt sortierbar sind:
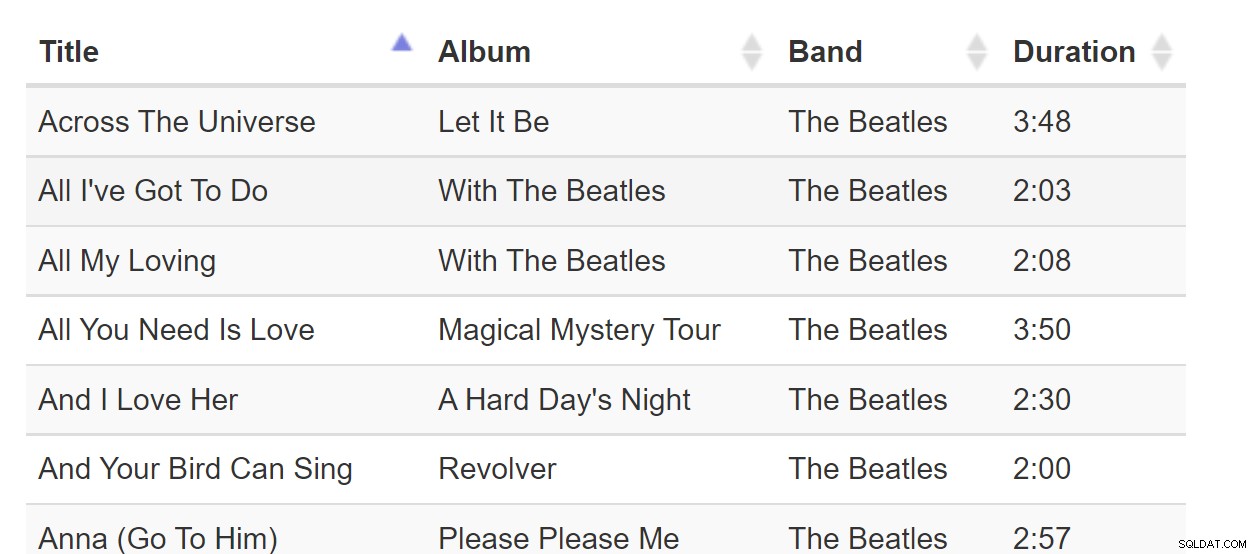
Sort-By-Colunn ist ein großartiges Muster, wenn alle Daten in den Browser passen. Wenn der Datensatz jedoch Milliarden von Zeilen groß ist, kann dies unangenehm werden, selbst wenn die Webseite nur eine Datenseite benötigt. Betrachten Sie diese Liedertabelle:
CREATE TABLE Songs
(
Title NVARCHAR(300) NOT NULL,
Album NVARCHAR(300) NOT NULL,
Band NVARCHAR(300) NOT NULL,
DurationInSeconds INT NOT NULL,
CONSTRAINT PK_Songs PRIMARY KEY CLUSTERED (Title),
);
CREATE NONCLUSTERED INDEX IX_Songs_Album
ON dbo.Songs(Album)
INCLUDE (Band, DurationInSeconds);
CREATE NONCLUSTERED INDEX IX_Songs_Band
ON dbo.Songs(Band); Und betrachten Sie diese vier Abfragen sortiert nach jeder Spalte:
SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Title; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Album; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY Band; SELECT TOP (20) Title, Album, Band, DurationInSeconds FROM dbo.Songs ORDER BY DurationInSeconds;
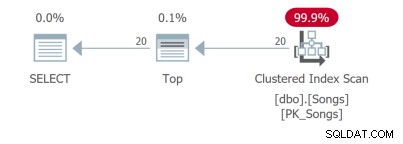
Selbst für eine so einfache Abfrage gibt es verschiedene Abfragepläne. Die ersten beiden Abfragen verwenden abdeckende Indizes:
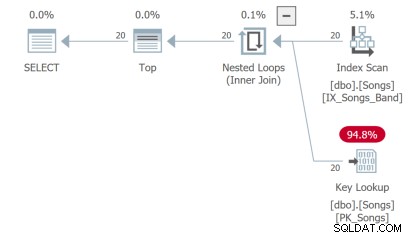
Die dritte Abfrage muss eine Schlüsselsuche durchführen, was nicht ideal ist:
Aber das Schlimmste ist die vierte Abfrage, die die gesamte Tabelle scannen und eine Sortierung durchführen muss, um die ersten 20 Zeilen zurückzugeben:
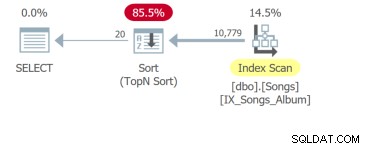
Der Punkt ist, dass, obwohl der einzige Unterschied die ORDER BY-Klausel ist, diese Abfragen separat analysiert werden müssen. Die Grundeinheit der SQL-Optimierung ist die Abfrage. Wenn Sie mir also UI-Anforderungen mit zehn sortierbaren Spalten zeigen, zeige ich Ihnen zehn zu analysierende Abfragen.
Wann wird das unangenehm?
Die Sort-By-Column-Funktion ist ein großartiges UI-Muster, aber es kann unangenehm werden, wenn die Daten aus einer riesigen, wachsenden Tabelle mit vielen, vielen Spalten stammen. Es mag verlockend sein, abdeckende Indizes für jede Spalte zu erstellen, aber das hat andere Kompromisse. Columnstore-Indizes können unter bestimmten Umständen hilfreich sein, aber das führt zu einer weiteren Ebene von Unannehmlichkeiten. Es gibt nicht immer eine einfache Alternative.
Ausgelagerte Ergebnisse
Die Verwendung von Seitenergebnissen ist eine gute Möglichkeit, den Benutzer nicht mit zu vielen Informationen auf einmal zu überfordern. Es ist auch eine gute Möglichkeit, die Datenbankserver nicht zu überlasten … normalerweise.
Betrachten Sie dieses Design:

Die Daten hinter diesem Beispiel erfordern das Zählen und Verarbeiten des gesamten Datensatzes, um die Anzahl der Ergebnisse zu melden. Die Abfrage für dieses Beispiel könnte folgende Syntax verwenden:
... ORDER BY LastModifiedTime OFFSET @N ROWS FETCH NEXT 25 ROWS ONLY;
Es ist eine praktische Syntax, und die Abfrage erzeugt nur 25 Zeilen. Aber nur weil die Ergebnismenge klein ist, bedeutet das nicht unbedingt, dass sie billig ist. Genau wie wir beim Sort-By-Column-Muster gesehen haben, ist ein TOP-Operator nur billig, wenn er nicht viele Daten zuerst sortieren muss.
Asynchrone Seitenanforderungen
Wenn ein Benutzer von einer Ergebnisseite zur nächsten navigiert, können die beteiligten Webanfragen durch Sekunden oder Minuten getrennt werden. Dies führt zu Problemen, die den Fallstricken sehr ähneln, die bei der Verwendung von NOLOCK auftreten. Zum Beispiel:
SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 0 ROWS FETCH NEXT 25 ROWS ONLY; -- wait a little bit SELECT [Some Columns] FROM [Some Table] ORDER BY [Sort Value] OFFSET 25 ROWS FETCH NEXT 25 ROWS ONLY;
Wenn zwischen den beiden Anforderungen eine Zeile hinzugefügt wird, sieht der Benutzer dieselbe Zeile möglicherweise zweimal. Und wenn eine Zeile entfernt wird, verpasst der Benutzer möglicherweise eine Zeile, wenn er durch die Seiten navigiert. Dieses Muster für ausgelagerte Ergebnisse entspricht „Geben Sie mir die Zeilen 26–50“. Wenn die eigentliche Frage lauten sollte „Gib mir die nächsten 25 Zeilen“. Der Unterschied ist subtil.
Bessere Muster
Bei ausgelagerten Ergebnissen kann dieses „OFFSET @N ROWS“ immer länger dauern, wenn @N wächst. Ziehen Sie stattdessen Load-More-Buttons oder Infinite-Scrolling in Betracht. Mit Load-More-Paging besteht zumindest die Möglichkeit, einen Index effizient zu nutzen. Die Abfrage würde in etwa so aussehen:
SELECT [Some Columns] FROM [Some Table] WHERE [Sort Value] > @Bookmark ORDER BY [Sort Value] FETCH NEXT 25 ROWS ONLY;
Es leidet immer noch unter einigen Fallstricken asynchroner Seitenanforderungen, aber aufgrund des Lesezeichens macht der Benutzer dort weiter, wo er aufgehört hat.
Text nach Teilzeichenfolge suchen
Gesucht wird überall im Internet. Doch welche Lösung soll im Backend zum Einsatz kommen? Ich möchte davor warnen, mit dem LIKE-Filter von SQL Server mit Platzhaltern wie diesen nach einer Teilzeichenfolge zu suchen:
SELECT Title, Category FROM MyContent WHERE Title LIKE '%' + @SearchTerm + '%';
Es kann zu unangenehmen Ergebnissen wie diesen führen:
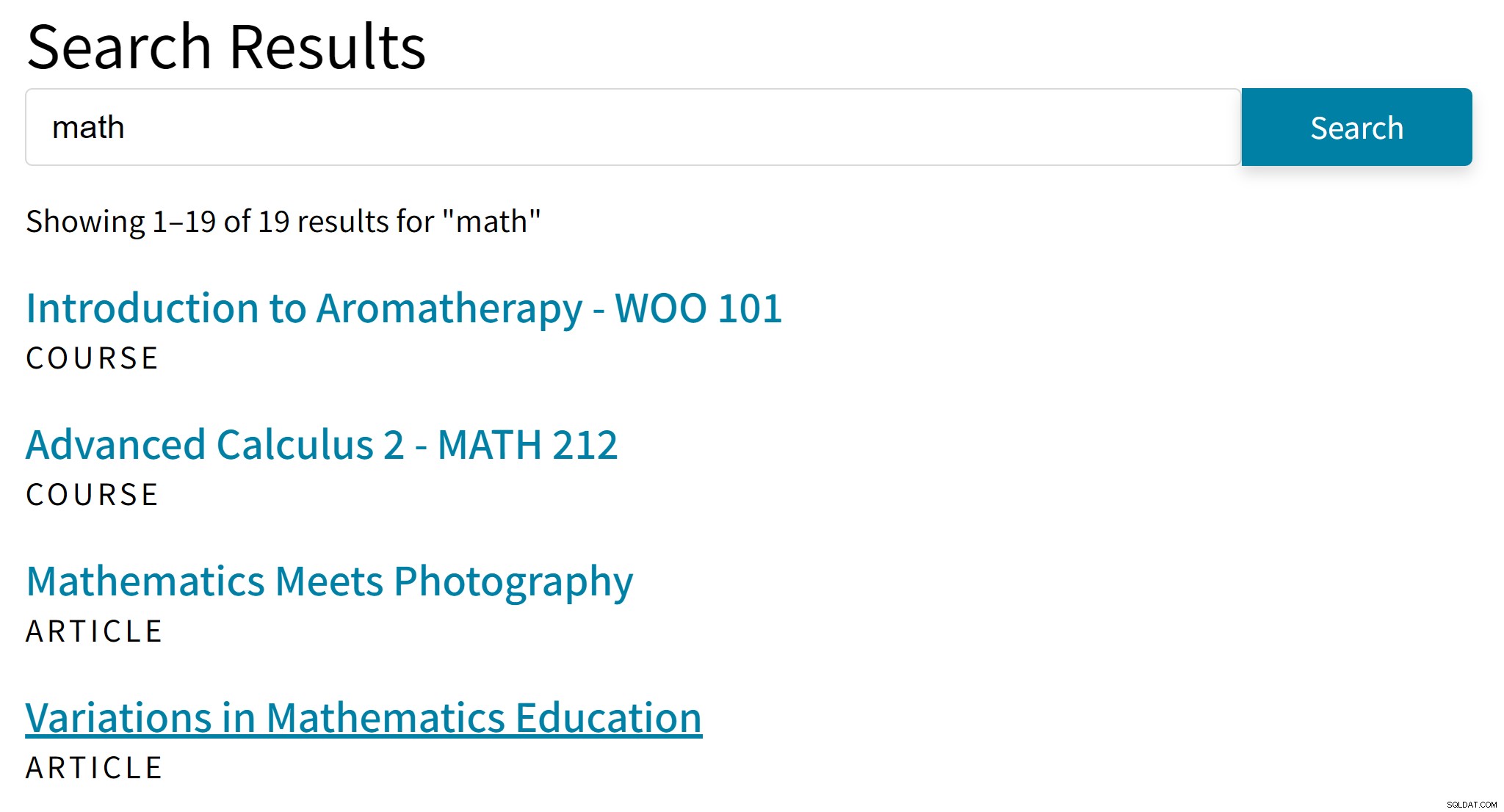
„Aromatherapie“ ist wahrscheinlich kein guter Treffer für den Suchbegriff „Mathematik“. Inzwischen fehlen in den Suchergebnissen Artikel, die nur Algebra oder Trigonometrie erwähnen.
Es kann auch sehr schwierig sein, SQL Server effizient zu nutzen. Es gibt keinen einfachen Index, der diese Art der Suche unterstützt. Paul White gab eine knifflige Lösung mit Trigram Wildcard String Search in SQL Server. Auch bei Sortierungen und Unicode können Schwierigkeiten auftreten. Es kann eine teure Lösung für eine nicht so gute Benutzererfahrung werden.
Was stattdessen verwendet werden sollte
Die Volltextsuche von SQL Server scheint hilfreich zu sein, aber ich persönlich habe sie nie verwendet. In der Praxis habe ich nur bei Lösungen außerhalb von SQL Server (z. B. Elasticsearch) Erfolge gesehen.
Schlussfolgerung
Meiner Erfahrung nach sind Softwaredesigner oft sehr empfänglich für Feedback, dass ihre Designs manchmal umständlich umzusetzen sind. Wenn dies nicht der Fall ist, fand ich es nützlich, die Fallstricke, die Kosten und die Zeit bis zur Lieferung hervorzuheben. Diese Art von Feedback ist notwendig, um wartbare, skalierbare Lösungen zu entwickeln.
Über den Autor
 Michael J Swart ist ein leidenschaftlicher Datenbankexperte und Blogger, der sich auf Datenbankentwicklung und Softwarearchitektur konzentriert. Er spricht gerne über alles, was mit Daten zu tun hat, und trägt zu Gemeinschaftsprojekten bei. Michael bloggt als „Database Whisperer“ auf michaeljswart.com.
Michael J Swart ist ein leidenschaftlicher Datenbankexperte und Blogger, der sich auf Datenbankentwicklung und Softwarearchitektur konzentriert. Er spricht gerne über alles, was mit Daten zu tun hat, und trägt zu Gemeinschaftsprojekten bei. Michael bloggt als „Database Whisperer“ auf michaeljswart.com.