Ein Oracle-Entwickler, der häufig reguläre Ausdrücke im Code verwendet, kann früher oder später mit einem in der Tat mystischen Phänomen konfrontiert werden. Langfristiges Suchen nach der Ursache des Problems kann zu Gewichtsverlust, Appetitlosigkeit und verschiedenen Arten von psychosomatischen Störungen führen – all dies kann mit Hilfe der Funktion regexp_replace verhindert werden. Es kann bis zu 6 Argumente haben:
REGEXP_REPLACE (
- Quellenzeichenfolge,
- Vorlage,
- ersetzende Zeichenfolge,
- die Startposition der Übereinstimmungssuche mit einer Vorlage (Standard 1),
- eine Position des Vorkommens der Vorlage in einer Quellzeichenfolge (standardmäßig entspricht 0 allen Vorkommen),
- Modifier (bisher ist es ein dunkles Pferd)
)
Gibt die geänderte source_string zurück, in der alle Vorkommen der Vorlage durch den im Parameter substituting_string übergebenen Wert ersetzt werden. Oft wird eine Kurzversion der Funktion verwendet, bei der die ersten 3 Argumente angegeben sind, was ausreicht, um viele Probleme zu lösen. Ich werde dasselbe tun. Angenommen, wir müssen alle Zeichenfolgenzeichen mit Sternchen in der Zeichenfolge „MASK:Kleinbuchstaben“ maskieren. Um den Bereich der Kleinbuchstaben festzulegen, sollte das Muster ‚[a-z]‘ passen.
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual Erwartung
+------------------+ | RESULT | +------------------+ | MASK: ***** **** | +------------------+
Realität
+------------------+ | RESULT | +------------------+ | *A**: ***** **** | +------------------+
Wenn dieses Ereignis nicht in Ihrer Datenbank reproduziert wurde, dann haben Sie bisher Glück gehabt. Aber öfter fängst du an, in Code zu graben, Zeichenfolgen von einem Zeichensatz in einen anderen umzuwandeln und irgendwann kommt die Verzweiflung.
Ein Problem definieren
Es stellt sich die Frage – was ist so besonders am Buchstaben „A“, dass er nicht ersetzt wurde, weil die restlichen Großbuchstaben nicht auch ersetzt werden sollten. Vielleicht gibt es außer diesem einen anderen richtigen Buchstaben. Es ist notwendig, das gesamte Alphabet der Großbuchstaben zu betrachten.
select regexp_replace('ABCDEFJHIGKLMNOPQRSTUVWXYZ', '[a-z]', '*') as alphabet from dual
+----------------------------+
| ALPHABET |
+----------------------------+
| A************************* |
+----------------------------+ Allerdings
Wenn das 6. Argument der Funktion nicht explizit angegeben wird, z. B. bei 'i' die Groß-/Kleinschreibung oder bei 'c' die Groß-/Kleinschreibung beim Vergleich einer Quellzeichenfolge mit einer Vorlage, wird die Der reguläre Ausdruck verwendet standardmäßig den NLS_SORT-Parameter der Sitzung/Datenbank. Zum Beispiel:
select value from sys.nls_session_parameters where parameter = 'NLS_SORT' +---------+ | VALUE | +---------+ | ENGLISH | +---------+
Dieser Parameter gibt die Sortiermethode in ORDER BY an. Wenn es um das Sortieren einfacher Einzelzeichen geht, dann entspricht jedem eine bestimmte Binärzahl (NLSSORT-Code) und die Sortierung erfolgt tatsächlich nach dem Wert dieser Zahlen.
Um dies zu veranschaulichen, nehmen wir die ersten und letzten Buchstaben des Alphabets, sowohl Klein- als auch Großbuchstaben, und fügen sie in einen bedingt ungeordneten Tabellensatz ein und nennen ihn ABC. Dann sortieren wir diesen Satz nach dem SYMBOL-Feld und zeigen seinen NLSSORT-Code im HEX-Format neben jedem Symbol an.
with ABC as (
select column_value as symbol
from table(sys.odcivarchar2list('A','B','C','X','Y','Z','a','b','c','x','y','z'))
)
select symbol,
nlssort(symbol) nls_code_hex
from ABC
order by symbol
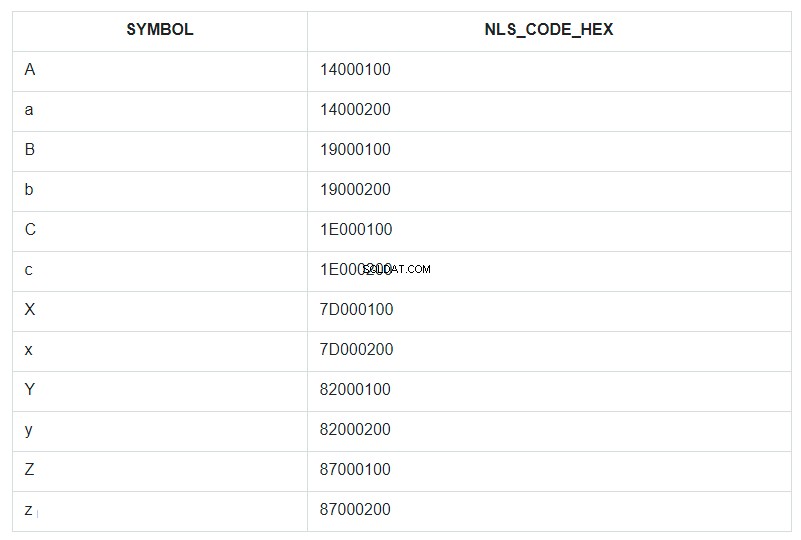
In der Abfrage ist ORDER BY für das Feld SYMBOL angegeben, aber tatsächlich wurde in der Datenbank nach den Werten aus dem Feld NLS_CODE_HEX sortiert.
Gehen Sie jetzt zurück zum Bereich aus der Vorlage und sehen Sie sich die Tabelle an – was ist vertikal zwischen dem Symbol „a“ (Code 14000200) und „z“ (Code 87000200)? Alles außer dem Großbuchstaben „A“. Das ist alles, was durch ein Sternchen ersetzt wurde. Und der Code 14000100 des Buchstabens „A“ ist nicht im Ersetzungsbereich von 14000200 bis 87000200 enthalten.
Heilung
Geben Sie explizit den Modifikator für die Unterscheidung zwischen Groß- und Kleinschreibung an
select regexp_replace('MASK: lower case', '[a-z]', '*', 1, 0, 'c') from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+
Einige Quellen sagen, dass der Modifikator „c“ standardmäßig gesetzt ist, aber wir haben gerade gesehen, dass dies nicht ganz stimmt. Und wenn jemand es nicht gesehen hat, dann ist der NLS_SORT-Parameter seiner Sitzung/Datenbank höchstwahrscheinlich auf BINARY gesetzt und die Sortierung wird in Übereinstimmung mit echten Zeichencodes durchgeführt. Wenn Sie den Sitzungsparameter ändern, wird das Problem tatsächlich gelöst.
ALTER SESSION SET NLS_SORT=BINARY;
select regexp_replace('MASK: lower case', '[a-z]', '*') as result from dual
+------------------+
| RESULT |
+------------------+
| MASK: ***** **** |
+------------------+ Tests wurden in Oracle 12c durchgeführt.
Fühlen Sie sich frei, Ihre Kommentare zu hinterlassen und passen Sie auf sich auf.