In meinem vorherigen Artikel habe ich eine neue Serie über Latches gestartet, indem ich erklärt habe, was sie sind, warum sie benötigt werden und wie sie funktionieren, und ich empfehle Ihnen dringend, diesen Artikel vor diesem zu lesen. In diesem Artikel werde ich den FGCB_ADD_REMOVE-Latch besprechen und zeigen, wie er ein Engpass sein kann.
Was ist der FGCB_ADD_REMOVE-Latch?
Die meisten Latch-Klassennamen sind direkt an die Datenstruktur gebunden, die sie schützen. Der FGCB_ADD_REMOVE-Latch schützt eine Datenstruktur namens FGCB oder File Group Control Block, und es gibt einen dieser Latches für jede Online-Dateigruppe jeder Online-Datenbank in einer SQL Server-Instanz. Immer wenn eine Datei in einer Dateigruppe hinzugefügt, gelöscht, vergrößert oder verkleinert wird, muss der Latch im EX-Modus abgerufen werden, und beim Ermitteln der nächsten zuzuweisenden Datei muss der Latch im SH-Modus abgerufen werden, um Änderungen an der Dateigruppe zu verhindern. (Denken Sie daran, dass Extent-Zuordnungen für eine Dateigruppe auf Round-Robin-Basis durch die Dateien in der Dateigruppe durchgeführt werden und auch die proportionale Füllung berücksichtigen , die ich hier erkläre.)
Wie wird der Latch zum Flaschenhals?
Das häufigste Szenario, wenn dieser Latch zu einem Engpass wird, ist wie folgt:
- Es gibt eine Datenbank mit nur einer Datei, daher müssen alle Zuweisungen aus dieser einen Datendatei stammen
- Die Einstellung für die automatische Vergrößerung für die Datei ist sehr klein (denken Sie daran, dass vor SQL Server 2016 die Standardeinstellung für die automatische Vergrößerung für Datendateien 1 MB betrug!)
- Es gibt viele gleichzeitige Vorgänge, die die Zuweisung von Speicherplatz erfordern (z. B. eine konstante Einfüge-Arbeitslast von vielen Client-Verbindungen)
In diesem Fall muss ein Thread, der eine Zuordnung benötigt, immer noch den FGCB_ADD_REMOVE-Latch im SH-Modus erwerben, obwohl es nur eine Datei gibt. Es versucht dann, aus der einzelnen Datendatei zuzuordnen, stellt fest, dass kein Speicherplatz vorhanden ist, und erfasst dann den Latch im EX-Modus, damit es die Datei vergrößern kann.
Stellen wir uns vor, dass acht Threads, die auf acht separaten Planern laufen, alle versuchen, gleichzeitig zuzuordnen, und alle erkennen, dass die Datei keinen Platz hat, also müssen sie sie vergrößern. Sie werden alle versuchen, das Latch im EX-Modus zu erwerben. Nur einer von ihnen wird in der Lage sein, es zu erwerben, und er wird fortfahren, die Datei zu vergrößern, und die anderen müssen warten, mit einem Wartetyp von LATCH_EX und einer Ressourcenbeschreibung von FGCB_ADD_REMOVE plus der Speicheradresse des Latch.
Die sieben wartenden Threads befinden sich in der FIFO-Warteschlange (First-In-First-Out) des Latch. Wenn der Thread, der das Dateiwachstum durchführt, fertig ist, gibt er den Latch frei und gewährt ihn dem ersten wartenden Thread. Dieser neue Besitzer des Riegels geht, um die Datei zu erweitern, und stellt fest, dass sie bereits erweitert wurde und nichts zu tun ist. Also gibt es den Latch frei und gewährt es dem nächsten wartenden Thread. Und so weiter.
Die sieben wartenden Threads warteten alle auf den Latch im EX-Modus, taten aber nichts, sobald ihnen der Latch gewährt wurde, sodass alle sieben Threads im Wesentlichen verstrichene Zeit verschwendeten, wobei die Menge der verschwendeten Zeit für jeden Thread weiter unten ein wenig zunahm die FIFO-Warteschlange war es.
Aufzeigen des Engpasses
Jetzt zeige ich Ihnen genau das obige Szenario anhand von erweiterten Ereignissen. Ich habe eine Einzeldatei-Datenbank mit einer winzigen Autogrow-Einstellung und Hunderten von gleichzeitigen Verbindungen erstellt, die einfach Daten in eine Tabelle einfügen.
Ich kann die folgende erweiterte Ereignissitzung verwenden, um zu sehen, was vor sich geht:
-- Drop the session if it exists.
IF EXISTS
(
SELECT * FROM sys.server_event_sessions
WHERE [name] = N'FGCB_ADDREMOVE'
)
BEGIN
DROP EVENT SESSION [FGCB_ADDREMOVE] ON SERVER;
END
GO
CREATE EVENT SESSION [FGCB_ADDREMOVE] ON SERVER
ADD EVENT [sqlserver].[database_file_size_change]
(WHERE [file_type] = 0), -- data files only
ADD EVENT [sqlserver].[latch_suspend_begin]
(WHERE [class] = 48 AND [mode] = 4), -- EX mode
ADD EVENT [sqlserver].[latch_suspend_end]
(WHERE [class] = 48 AND [mode] = 4) -- EX mode
ADD TARGET [package0].[ring_buffer]
WITH (TRACK_CAUSALITY = ON);
GO
-- Start the event session
ALTER EVENT SESSION [FGCB_ADDREMOVE]
ON SERVER STATE = START;
GO Die Sitzung verfolgt, wann ein Thread in die Warteschlange des Latches eintritt, wann er die Warteschlange verlässt (d. h. wenn ihm der Latch gewährt wird) und wenn ein Datendateiwachstum auftritt. Die Verwendung von Kausalitätsverfolgung bedeutet, dass wir eine Zeitleiste der Aktionen jedes Threads sehen können.
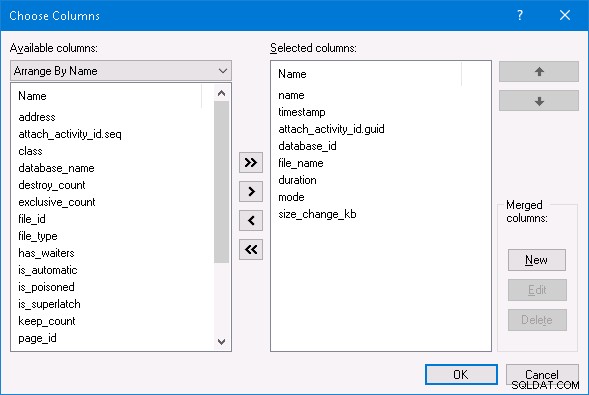
Mit SQL Server Management Studio kann ich die Option „Live-Daten beobachten“ für die erweiterte Ereignissitzung auswählen und alle erweiterten Ereignisaktivitäten anzeigen. Wenn Sie dasselbe tun möchten, klicken Sie im Live-Datenfenster mit der rechten Maustaste auf einen der Spaltennamen oben und ändern Sie die ausgewählten Spalten wie folgt:
Ich ließ die Arbeitslast einige Minuten lang laufen, um einen stabilen Zustand zu erreichen, und sah dann ein perfektes Beispiel für das oben beschriebene Szenario:
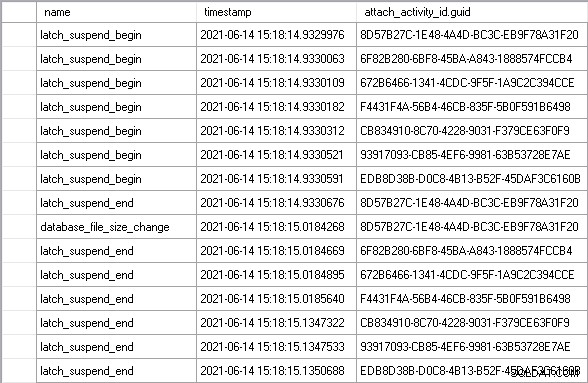
Verwenden der attach_activity_id.guid -Werte, um verschiedene Threads zu identifizieren, können wir sehen, dass sieben Threads beginnen, innerhalb von 61,5 Mikrosekunden auf den Latch zu warten. Der Thread mit dem GUID-Wert, der 8D57 beginnt, ruft den Latch im EX-Modus ab (das latch_suspend_end Ereignis) und vergrößert dann sofort die Datei (die Datei database_file_size_change Veranstaltung). Der 8D57-Thread gibt dann den Latch frei und übergibt ihn im EX-Modus an den 6F82-Thread, der 85 Millisekunden gewartet hat. Es hat nichts damit zu tun, es gewährt den Latch für den 672B-Thread. Und so weiter, bis dem EDB8-Thread der Latch gewährt wird, nachdem er 202 Millisekunden gewartet hat.
Insgesamt warteten die sechs Threads, die ohne Grund warteten, fast 1 Sekunde. Ein Teil dieser Zeit ist Signalwartezeit, bei der der Thread, obwohl ihm der Latch gewährt wurde, immer noch an die Spitze der ausführbaren Warteschlange des Schedulers gelangen muss, bevor er auf den Prozessor gelangen und Code ausführen kann. Man könnte sagen, dass dies kein faires Maß für die Zeit ist, die mit dem Warten auf den Latch verbracht wird, aber das ist es absolut, weil die Signalwartezeit nicht angefallen wäre, wenn der Thread nicht überhaupt hätte warten müssen.
Außerdem denken Sie vielleicht, dass eine Verzögerung von 200 Millisekunden nicht so viel ist, aber alles hängt von den Service-Level-Vereinbarungen für die betreffende Workload ab. Wir haben mehrere Kunden mit hohem Volumen, bei denen die Ausführung eines Stapels mehr als 200 Millisekunden dauert und auf dem Produktionssystem nicht zulässig ist!
Zusammenfassung
Wenn Sie Wartezeiten auf Ihrem Server überwachen und feststellen, dass LATCH_EX eine der häufigsten Wartezeiten ist, können Sie den Code in diesem Beitrag verwenden, um zu sehen, ob FGCB_ADD_REMOVE einer der Übeltäter ist.
Der einfachste Weg, um sicherzustellen, dass Ihre Workload nicht auf einen FGCB_ADD_REMOVE-Engpass trifft, besteht darin, sicherzustellen, dass keine Einstellungen für die automatische Vergrößerung von Datendateien mit den Standardwerten vor SQL Server 2016 konfiguriert sind. In den sys.master_files anzeigen, würde der Standardwert von 1 MB als Datendatei (type_desc Spalte auf ROWS gesetzt) mit is_percent_growth Spalte auf 0 und die Wachstumsspalte auf 128 gesetzt.
Eine Empfehlung zu geben, wie die automatische Vergrößerung eingestellt werden sollte, ist eine ganz andere Diskussion, aber jetzt wissen Sie um eine potenzielle Auswirkung auf die Leistung, wenn die Standardeinstellungen in früheren Versionen nicht geändert werden.